







 本文通过Apriori模型和Carma算法对超市顾客购买数据进行关联规则挖掘,揭示了商品间的潜在关联。实验结果显示,牛奶、意大利面、水等商品关联度高,建议超市调整布局以促进销售。Carma算法相较于Apriori更精准,推荐商家根据分析结果调整库存策略。
本文通过Apriori模型和Carma算法对超市顾客购买数据进行关联规则挖掘,揭示了商品间的潜在关联。实验结果显示,牛奶、意大利面、水等商品关联度高,建议超市调整布局以促进销售。Carma算法相较于Apriori更精准,推荐商家根据分析结果调整库存策略。
全文链接:http://tecdat.cn/?p=27606
作为数据挖掘的一个重要研究方向—关联规则用于发现数据项之间隐含的深层次的关联,如Apriori模型可以通过对客户需求进行深入的分析来发现数据之间的潜在联系,为我们提供自动决策支持。
相关视频
Apriori模型
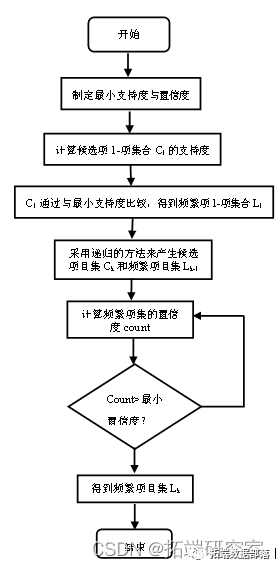
关联规则是数据挖掘算法中主要技术之一,是在无指导学习系统中挖掘本地模式的最普便形式。在数据挖掘中,常见的关联规则挖掘模型有AIS、SETM、Apriori、DHP、MLT2L1、ML-TML1等。其中,Apriori算法是一种最有影响的挖掘关联规则频繁项集的模型。
Apriori模型原理
Apriori算法通过多次扫描事务数据库来产生频繁项目集,我们称这种方法为逐层搜索迭代法。具体地说,该算法的基本思想是通过对数据库的多次扫描来发现所有的频繁项集。首先第1遍扫描事务数据库生成频繁1项集,记为L1;然后基于L1第2遍扫描事务数据库生成频繁2项集,记为L2;依此迭代,基于L(k-1)第k遍扫描事务数据库生成频繁k项集,记为Lk。在后续的扫描中,首先以前一次所发现的所有频繁项集为基础,生成所有新的候选项集(Candidate Item sets),然后扫描数据库,计算这些候选项集的支持度,最后确定候选项集中哪些可成为频繁项集。重复上述过程直到再也产生不出新的频繁项集。
由此可见,Apriori算法是一种通过多次扫描事务数据库统计不同项的发生次数,以此来抽取频繁模式的过程。由于Apriori算法需要大量扫描事务数据库,因此利用Apriori算法的相关性质对其进行搜索空间压缩。
Apriori算法的性质如下:频繁项集中的所有非空子集也是频繁的。该属性可以通过如下方式证明:若A是非频繁的,那么集合A∪B也是非频繁的,即构成集合的子集是非频繁的,则该集合也是非频繁项集。Apriori算法的这一属性为反单调性,在实际挖掘过程中,如果一个集合不能通过测试,那么它的所有超集也都不能通过相同的测试。基于此,我们通过“连接”操作由现有频繁项集构造超集,通过“剪枝”操作过滤掉不能通过测试的超集,从而压缩下一次迭代的系统开销。
点击标题查阅往期内容

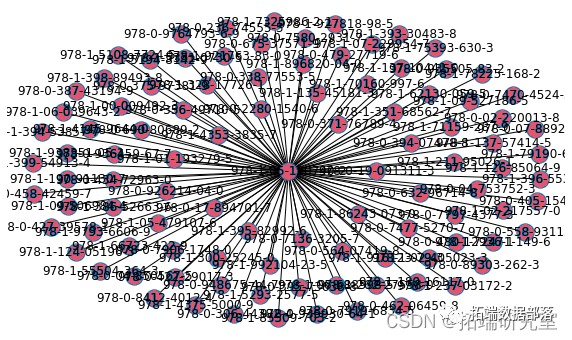
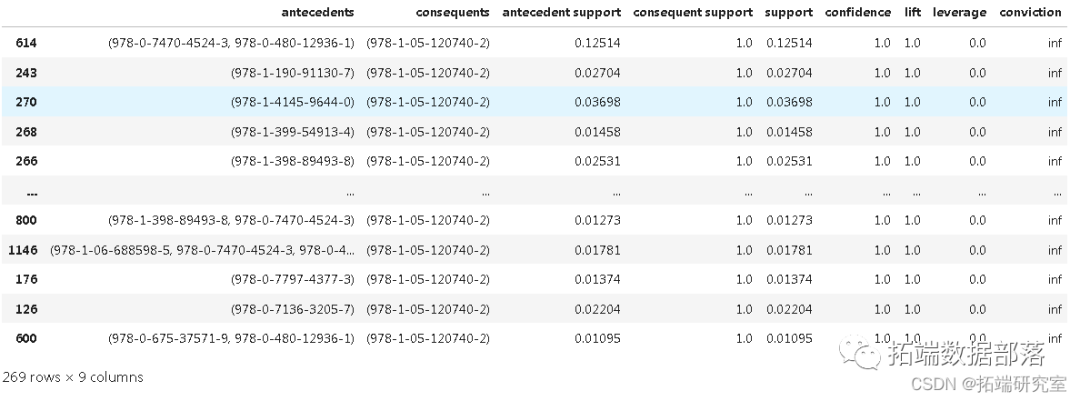
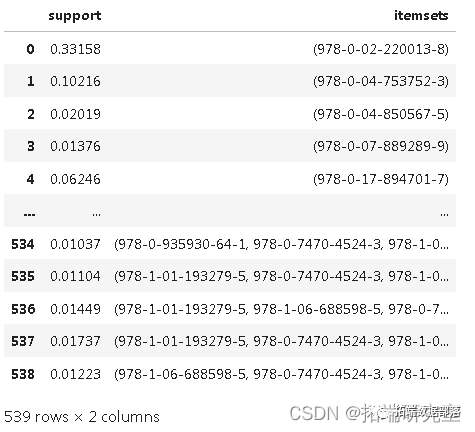
数据分享|Python用Apriori算法关联规则分析亚马逊购买书籍关联推荐客户和网络图可视化

左右滑动查看更多
01
02
03

04
仿真
实验平台及数据
为了验证Apriori模型在DSS数据挖掘中应用的可行性,本文在Spss Modeler软件平台上对Apriori模型进行仿真。实验数据为某超市的DSS系统中的顾客及购买商品数据(查看文末了解数据获取方式)。数据包括1000条购买事务记录,每条购买事务记录
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 37
37

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









