







全文链接:http://tecdat.cn/?p=22458
本文提供了一个经济案例。着重于原油市场的例子。简要地提供了在经济学中使用模型平均和贝叶斯方法的论据,使用了动态模型平均法(DMA),并与ARIMA、TVP等方法进行比较(点击文末“阅读原文”获取完整代码数据)。
简介
希望对经济和金融领域的从业人员和研究人员有用。
相关视频
动机
事实上,DMA将计量经济学建模的几个特点结合在一起。首先,最终预测是通过模型平均化从几个回归模型中产生的。其次,该方法是贝叶斯方法,也就是说,概率是以相信程度的方式解释的。例如,对时间t的DMA预测只基于截至时间t-1的数据。此外,新数据的获得直接导致参数的更新。因此,在DMA中,回归系数和赋予模型的权重都随时间变化。
贝叶斯方法不是现代计量经济学的主流。然而,这些方法最近正获得越来越多的关注。这其中有各种原因。首先,我们可以将其与研究中日益增多的数据量联系起来。由于技术进步,人们通常面临着许多潜在的解释变量的情况。尽管大多数变量可能并不重要,但研究者通常不知道哪些变量应该被剔除。
当然,到某种程度上仍然可以使用常规方法。但由于缺乏足够的信息,通常无法对参数进行精确估计。最简单的例子是当解释变量的数量大于时间序列中的观察值的数量时。例如,即使在线性回归的情况下,标准的普通最小二乘法估计也会出现一个奇异矩阵,导致不可能取其倒数。在贝叶斯框架下,仍然可以得出一个有意义的公式。贝叶斯方法似乎也能更好地处理过度参数化和过度拟合问题。
在最近的预测趋势中可以发现各种方法。以原油价格为例,预测方法通常可以分为时间序列模型、结构模型和其他一些方法,如机器学习、神经网络等。一般来说,时间序列模型的重点是对波动的建模,而不是对现货价格的建模。结构模型顾名思义包括因果关系,但它们通常在某些时期有很好的预测能力,而在其他时期则很差。另外,基于小波分解、神经网络等的其他方法通常忽略了其他因素的影响,只关注单一时间序列。这些使得DMA成为从业者的一个有趣的方法。
DMA的下一个方面是,它允许回归系数是随时间变化的。事实上,在经济出现缓慢和快速(结构性中断)变化的情况下,计量经济学模型的这种属性是非常可取的。当然,这样的方法也存在于传统的方法论中,例如,递归或滚动窗口回归。
理论框架
我们将简短地描述fDMA的理论框架。特别是,动态模型平均化(DMA)、动态模型选择(DMS)、中位概率模型。
动态模型平均(DMA)
DMA在[1]的原始论文中得到了非常详细的介绍。然而,下面是一个简短的论述,对于理解fDMA中每个函数的作用是必要的。
假设yt是预测的时间序列(因变量),让x(k)t是第k个回归模型中独立变量的列向量。例如,有10个潜在的原油价格驱动因素。如果它们中的每一个都由一个合适的时间序列来表示,那么就可以构建2^10个可能的线性回归模型。每个变量都可以包括或不包括在一个模型中。因此,每个变量有两种选择,构成了2^10种可能性。这包括一个只有常数的模型。因此,一般来说,有潜在的有用的m个独立变量,最多可以构建K=2^m个模型。换句话说,状态空间模型是由以下几个部分组成的
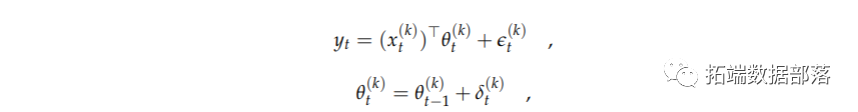
其中k = 1, ... . ,K,θt是回归系数的列向量。假设误差遵循正态分布,即e(k)t∼N(0,V(k)t)和δ(k)t∼N(0,W(k)t)。
在此请注意,有m个潜在的解释变量,2m是构建模型的上限。然而,本文描述的所有方法(如果没有特别说明的话)都适用于这些2m模型的任何子集,即K≤2m。
动态模型选择(DMS)
动态模型选择(DMS)是基于相同的理念,与DMA的理念相同。唯一的区别是,在DMA中进行的是模型平均化,而在DMS中是模型选择。换句话说,对于每个时期t,选择具有最高后验概率的模型。这意味着,只需将公式修改为
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 41
41

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









