






 本文介绍了如何通过市场调查、数据分析,尤其是R语言中的聚类分析(如LDA)和消费者行为模型,精准定位目标客户并预测新产品的市场份额。通过特征转换和竞品分析,提出针对在校大学生和年轻白领的助眠灯产品策略。
本文介绍了如何通过市场调查、数据分析,尤其是R语言中的聚类分析(如LDA)和消费者行为模型,精准定位目标客户并预测新产品的市场份额。通过特征转换和竞品分析,提出针对在校大学生和年轻白领的助眠灯产品策略。
全文链接:https://tecdat.cn/?p=34532
分析师:Yue Yu
如何精准定位目标客户,准确量化客户需求来开发新的产品组合,并预测其可能的市场份额(点击文末“阅读原文”了解更多)。
相关视频
解决方案
任务/目标
根据零售业务营销要求,运用多种数据源分析对客户给出产品性能组合的建议。
数据源准备
搜集除已有销量数据之外的额外信息包括对潜在消费者进行市场调查,收集其基本信息(地点、年龄、可支配收入等)及其对产品的购买欲望,对产品各维度性能的重视程度以及对产品功能的重要性排序,再在搜集的数据基础上进行预处理。收集现有的产品功能以及市面上相同种类竞品拥有的产品功能。
有了数据,但是有一部分特征是算法不能直接处理的,还有一部分数据是算法不能直接利用的。
特征转换
潜在消费者地区。需要把地区转变成到一线、新一线、二线、三四线伪变量。
产品特征。从产品信息表里面可以得到款式,颜色,质地以及这款产品是否是限量版等。然而并没有这些变量。这就需要我们从产品名字抽取这款产品的上述特征。
清洗存在NA以及非目标市场的客户信息(如退休人员)
建模
对通过消费需求调查得到的消费者对产品功能的选择行为做出分层聚类分析,得到四类人群。再根据其中主要的两类人群进行了联合分析,得到各产品性能的价值,最后通过分析竞品已有特征和我们预计给出的新功能组合产品进行模拟预测得到预计的市场份额,给出合理性的建议。
在此案例中,通过碎石图得到聚类种类为4,其可视化图形如下:
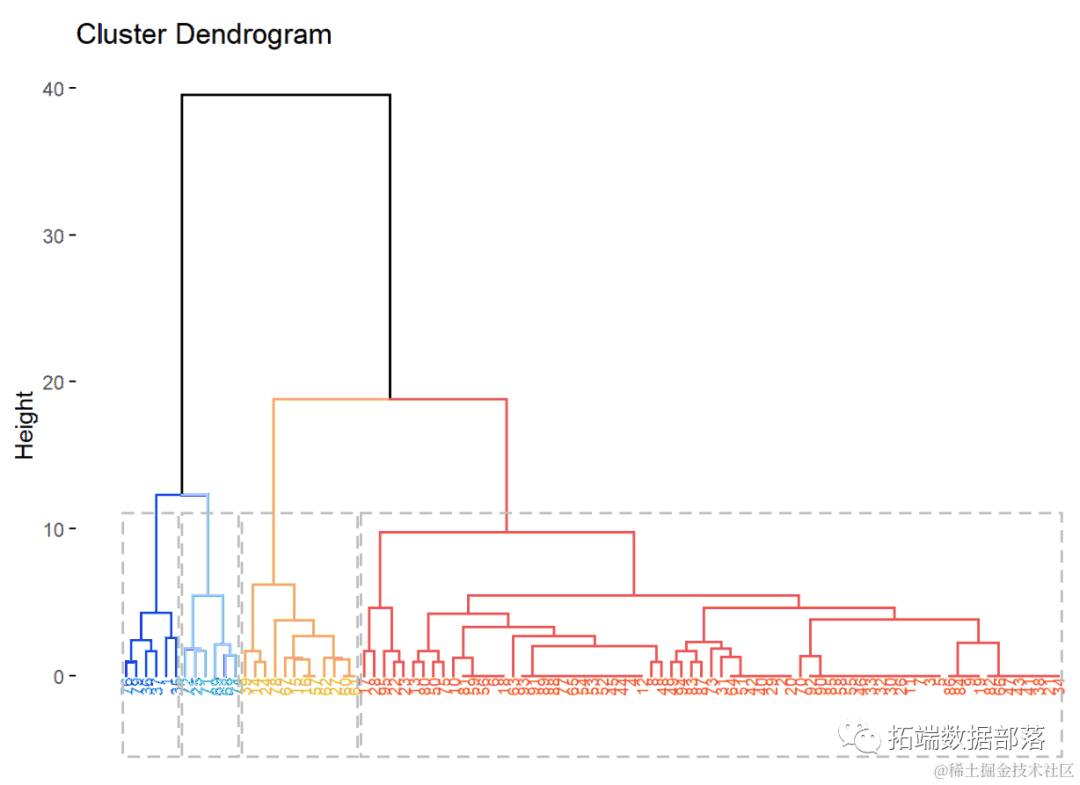
可以看出,我们的目标消费者主要面向在校大学生以及工作3年以内的白领。对于功能需求的四个重要的标签分布为助眠灯光,助眠香薰,蓝牙连接,睡眠智能预测,舒压呼吸。
点击标题查阅往期内容

数据分享|R语言聚类、文本挖掘分析虚假电商评论数据:K-MEANS(K-均值)、层次聚类、词云可视化

左右滑动查看更多
01

02

03
04

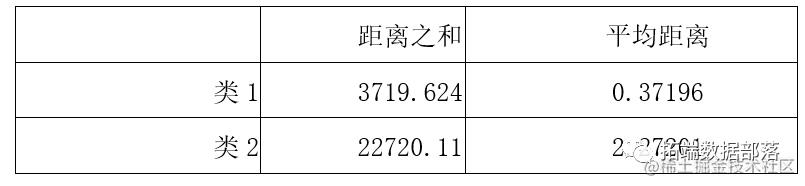
随后进行的conjoint分析结果如下:
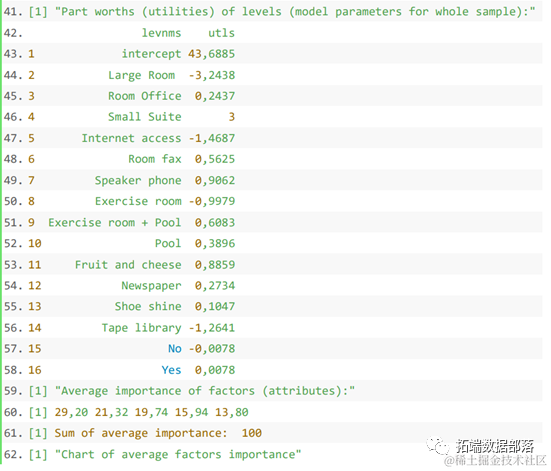
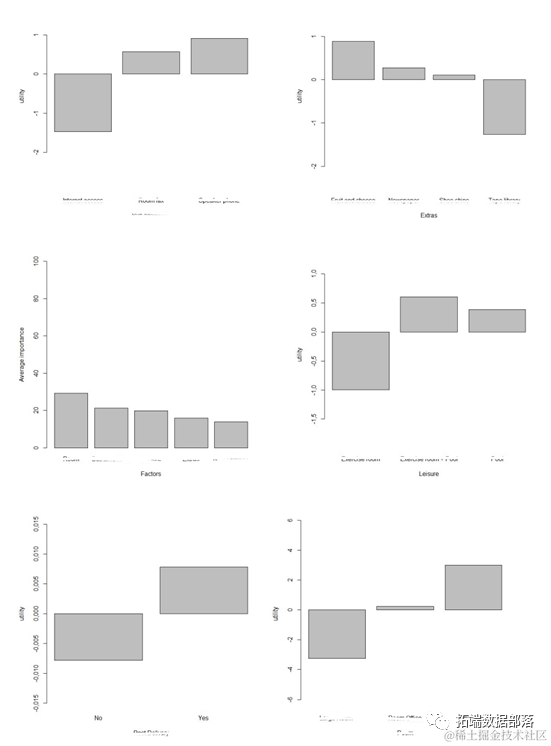
最后预测得到的市场份额如下:

因新的产品组合预测可以12.5%的同类产品市场份额,因此建议推出拥有助眠灯光,睡眠智能预测,舒压呼吸功能组合的新产品。
关于分析师

在此对Yue Yu对本文所作的贡献表示诚挚感谢,她专注数理金融、数据建模等领域。擅长R语言。

点击文末“阅读原文”
了解更多。
本文选自《聚类建模对智能助眠灯市场营销分析》。


点击标题查阅往期内容
【视频】文本挖掘:主题模型(LDA)及R语言实现分析游记数据
NLP自然语言处理—主题模型LDA案例:挖掘人民网留言板文本数据
Python主题建模LDA模型、t-SNE 降维聚类、词云可视化文本挖掘新闻组数据集
自然语言处理NLP:主题LDA、情感分析疫情下的新闻文本数据
用于NLP的Python:使用Keras进行深度学习文本生成
R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
R语言中的LDA模型:对文本数据进行主题模型topic modeling分析
R语言文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation)
用于NLP的Python:使用Keras进行深度学习文本生成
R语言文本挖掘tf-idf,主题建模,情感分析,n-gram建模研究
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类
R语言中的LDA模型:对文本数据进行主题模型topic modeling分析
R语言文本主题模型之潜在语义分析(LDA:Latent Dirichlet Allocation)

![]()



















 569
569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









