






本内容是对知名性能评测博主 Anton Putra Zap (Zig) vs Actix (Rust): Performance (Latency - Throughput - Saturation - Availability) 内容的翻译与整理, 有适当删减, 相关指标和结论以原作为准
在本篇内容中,我们将对比 Rust 和 Zig 编程语言的表现。具体来说,我们将使用 Actix 作为 Rust 的 HTTP 框架,而 Zap 作为 Zig 语言编写的 HTTP 框架。为了运行这个基准测试,我会将两款应用程序部署到 Kubernetes,然后测量它们的 CPU 使用率、内存使用率 和 客户端延迟(重点关注 p99 百分位数)。此外,我们还会测量每个应用可以处理的 请求数量。
另外,我们还会评估 服务的可用性,即成功请求数与总请求数的比率。由于这两个应用都部署在 Kubernetes 上,我们还需要测量 CPU 限流情况。
实际上,这是我第一次成功生成足够的流量,导致 Zig 和 Rust 这两个应用都出现过载情况。
作为一名 DevOps 工程师,我们现在几乎将所有应用部署到 Kubernetes。因此,我在 AWS 上搭建了一个生产级的 EKS 集群,并使用了 最新推出的 m7a EC2 实例类型。
测试架构
为了运行这次测试,我配置了 两个 Kubernetes 节点组:
- 第一个节点组 专门用于运行应用程序;
- 第二个节点组 负责运行客户端,以便生成模拟流量。
在 应用节点组 中,我使用了 xlarge 实例类型(4 核 CPU,16GB 内存)。在生产环境中,我们通常会为每个应用 设置 CPU 和内存的请求值及限制值。在本次测试中,我仅分配了 2 核 CPU 和 256MB 内存。如果你的应用支持 水平扩展,通常你会限制它使用 4 到 6 核 CPU,但不会超过这个范围。因此,这次测试的配置对很多人来说应该是很熟悉的。
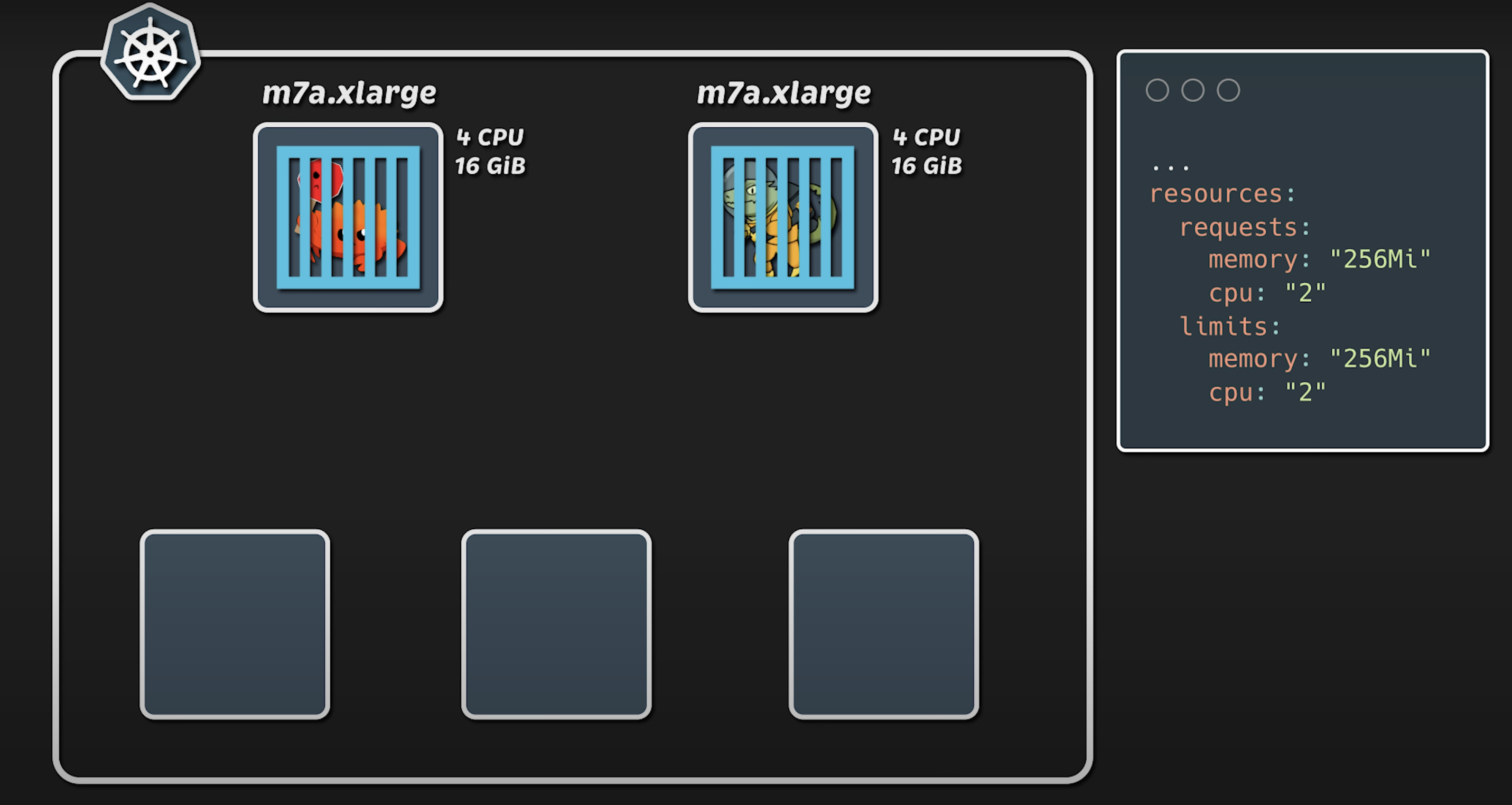
在 客户端节点组 方面,我使用了 4xlarge 实例类型(16 核 CPU,64GB 内存)。为了生成负载,我使用了 Kubernetes Jobs,并为每个应用程序 启动 20 个 Pod,总计 40 个 Pod 用于流量生成。此外,我使用了 ClusterIP 类型的 Service 进行服务发现。随后,我们逐步增加负载,直到两个应用都出现故障。最后,我们会回顾整个测试期间的 数据图表。
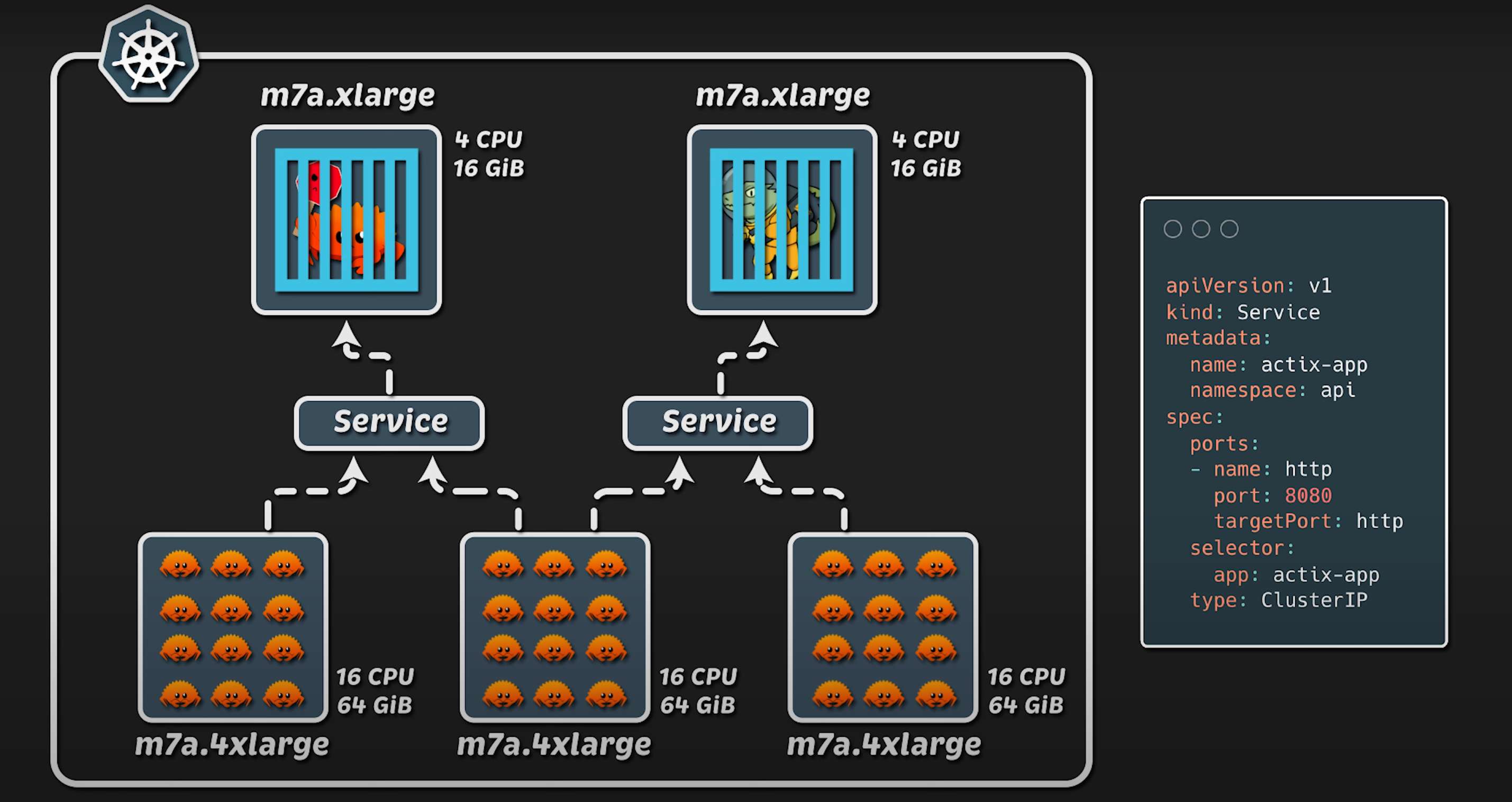
有趣的是,我曾经使用 Golang 编写客户端,当时需要 8xlarge 实例类型 才能生成足够的流量,使测试应用程序过载。就在录制本视频之前,我用 Rust 重写了这个客户端,现在只需要 4xlarge 实例类型 就可以达到同样的效果。这是因为 Rust 的 CPU 效率更高。我并不是特别偏爱 Rust,但它确实让我 节省了 50% 的基础设施成本 来运行这些测试。
Rust Actix 框架概述
我选择 Actix 作为 Rust 的 HTTP 框架,因为在我之前的基准测试视频中,它是 最快的框架(当时对比了 Actix、Axum 和 Rocket)。如果你感兴趣,可以去查看那个基准测试,欢迎查看。
Zig Zap 框架概述
另一方面,我选择 Zap 框架,它本质上是 一个基于 C 库的封装,使用 Zig 语言编写。
根据该项目官方提供的 基准测试,Zap 似乎比 Rust 更高效。不过,我不会直接复现他们的基准测试,而是会在 真实的生产环境 中,采用相同的 部署策略和运行环境 来测试这两个应用。
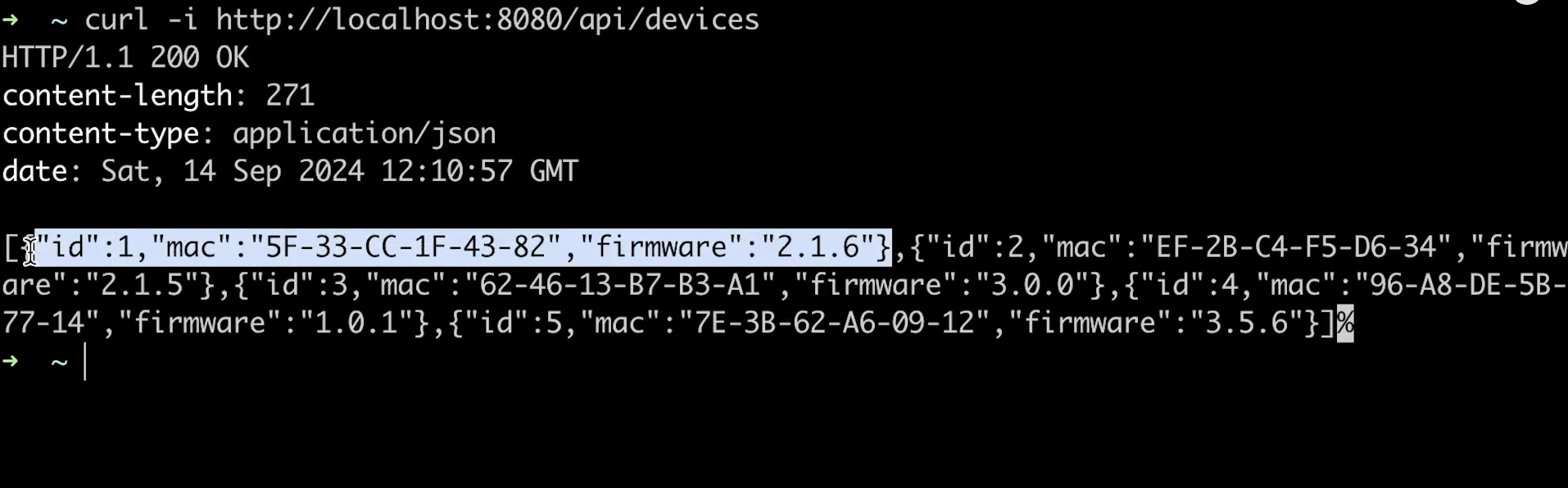
在这类测试中,我通常会创建 一个结构体数组 并返回给客户端。然而,我发现 Zap 框架的响应缓冲区非常小,导致我 只能发送单个设备的数据。如果你知道如何让它支持更大的负载,请告诉我;否则,我认为这个框架在实际应用中 并不实用。
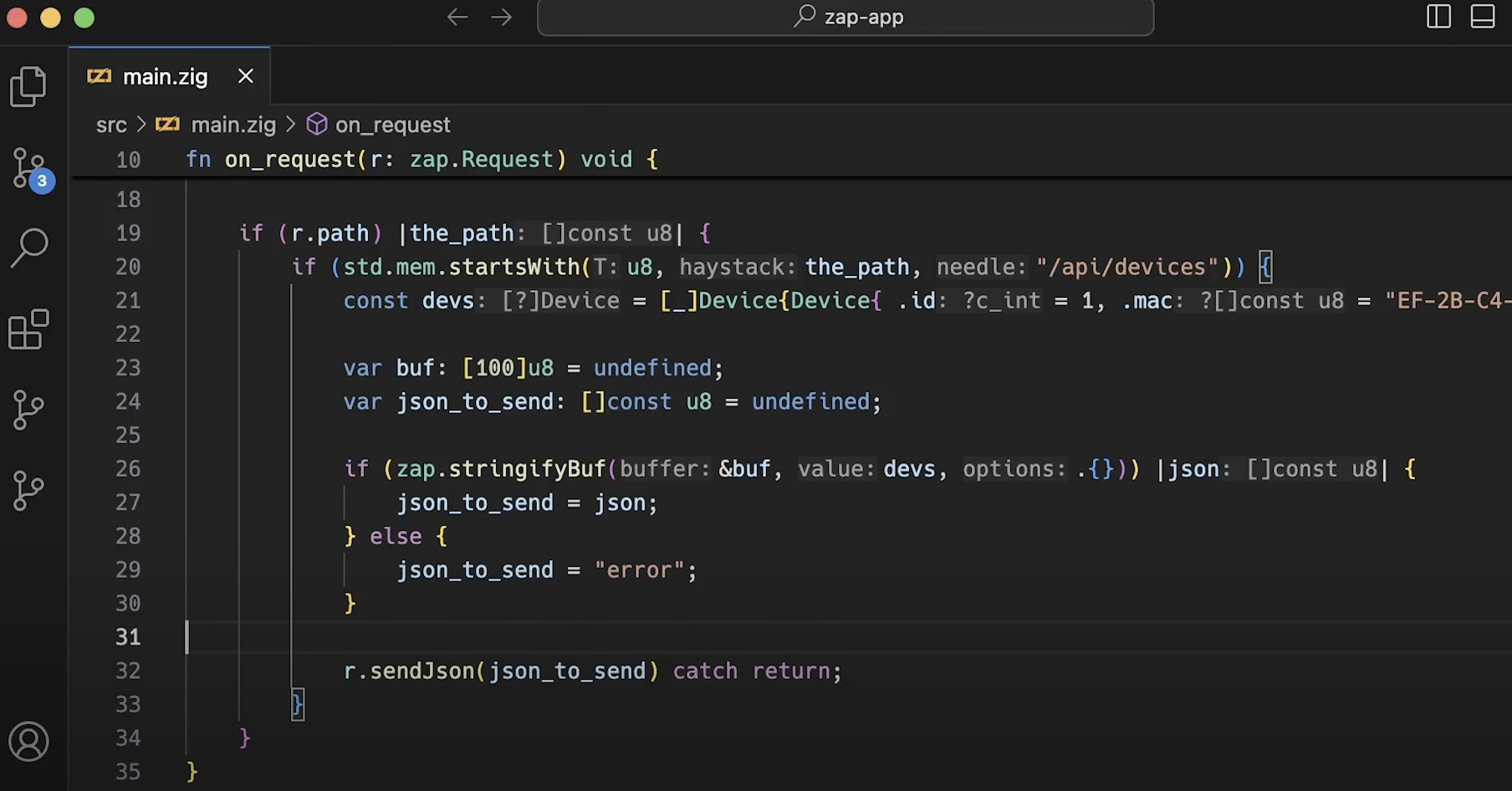
此外,我一般都会使用 默认的配置。我注意到,在很多情况下,Zap 仅使用 两个线程和一到两个工作进程。由于这些应用都运行在 容器 中,没有必要在容器内部运行多个进程。如果你需要扩展应用,你应该 增加部署的副本数量,而不是 增加容器内部的进程数。
测试过程
好了,现在我要把两个应用 部署到 Kubernetes,并让它们 在空闲状态下运行 10 到 15 分钟,以获取基准数据。
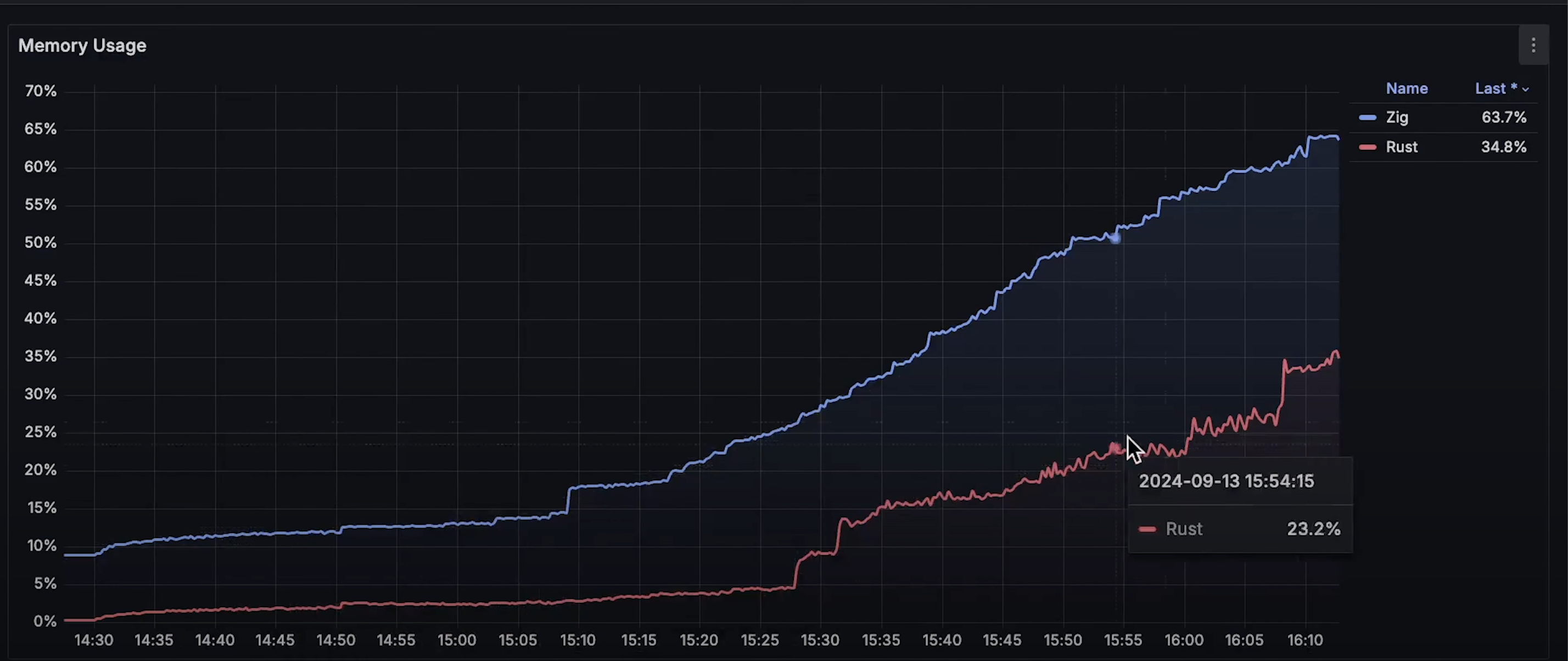
从 CPU 使用情况 来看,Rust 稍高一些,但令人惊讶的是,Zap 的内存使用量远远高于 Rust。Zap 有垃圾回收机制吗?我觉得没有。

让我们来看一下 实际的内存占用:
- Rust 仅使用 760KB,几乎可以忽略不计。
- Zap 使用了 22MB,虽然也不算大,但相比 Rust 还是高出不少。
如果你知道 Zap 为什么占用更多内存,请告诉我。此外,Rust 和 Zap 在 Kubernetes 中的 资源请求和限制 是相同的。
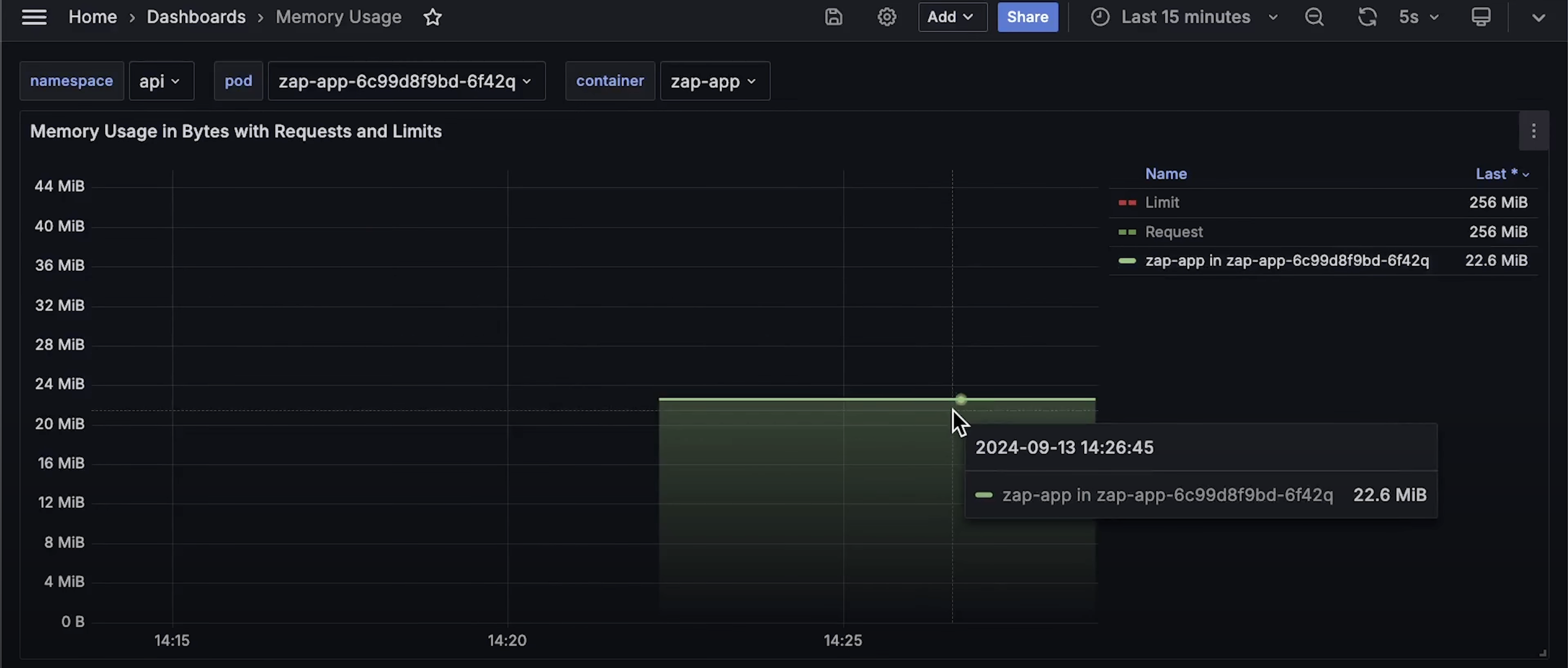
对于 CPU 使用情况,我们不仅可以测量 相对于限制值的百分比,还可以测量 实际的 CPU 使用量,并绘制出 请求值和限制值的曲线。
负载测试
接下来,我将部署 测试任务 来 生成负载。正如之前提到的,我使用的是 Rust 编写的客户端,它会:
- 先启动一个虚拟客户端;
- 每 30 秒增加一个新的客户端(每个客户端在自己的线程中运行)。
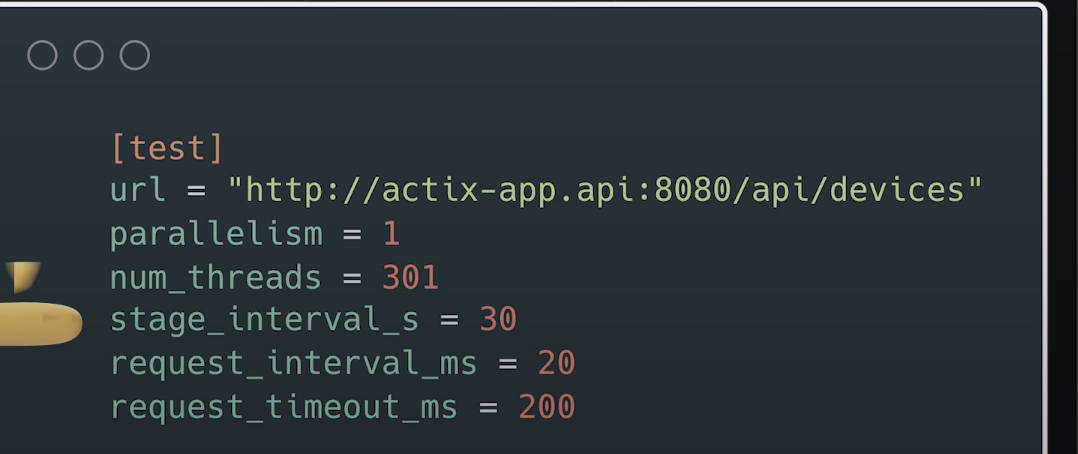
我使用 Tokio 运行时 来并发执行这些客户端。虽然这 不是最有效的方式,但它能够 逐步增加负载,满足我测试的需求。
同时,我设置了 200 毫秒超时时间,因为 正常请求一般只需 1 毫秒左右。如果请求时间超过 200 毫秒,就意味着 应用已经开始变慢并进入过载状态。
整个测试 持续了大约 2 小时,但我会把它 压缩成几分钟 供大家观看。
测试结果
即使在 测试初期,我们就能看到一个明显的趋势:
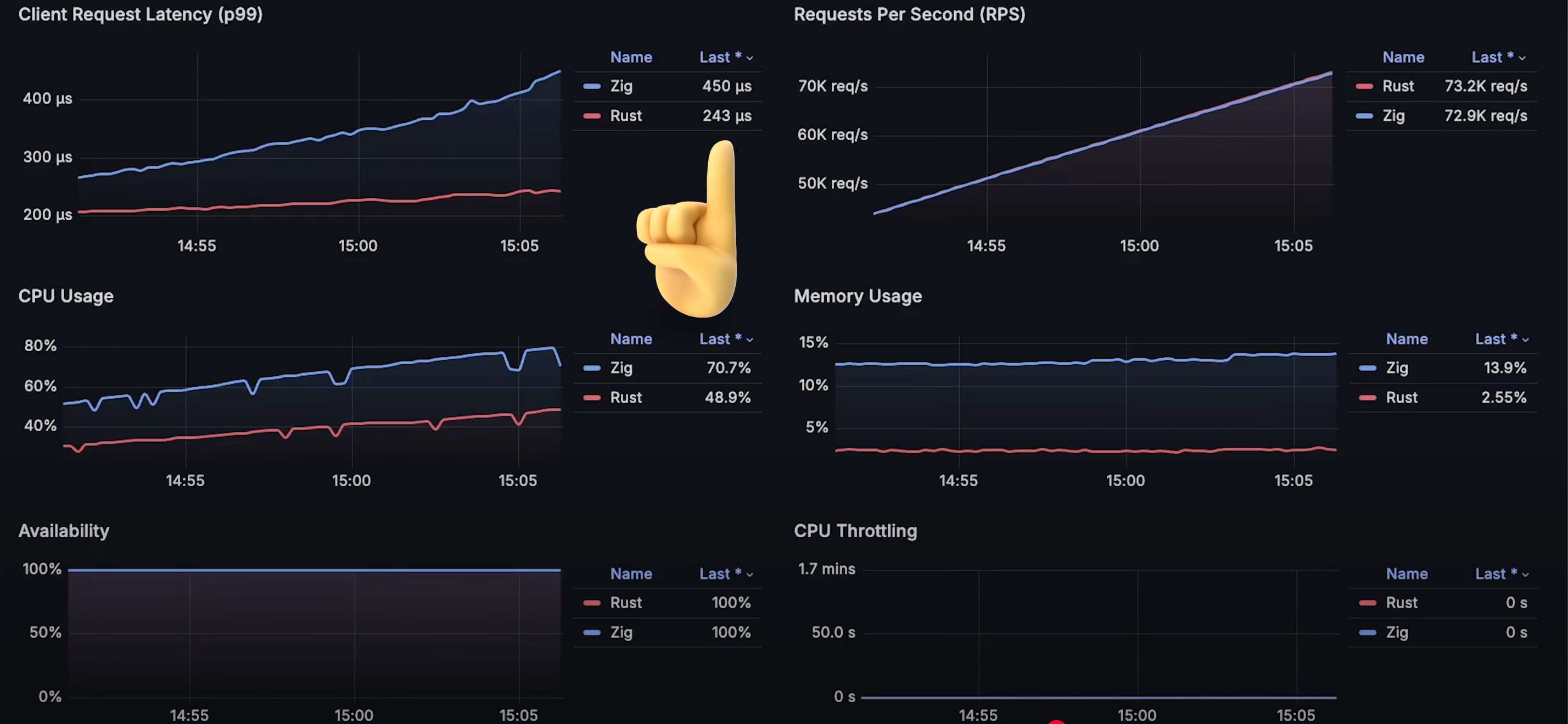
- Rust 的 CPU 使用率更低;
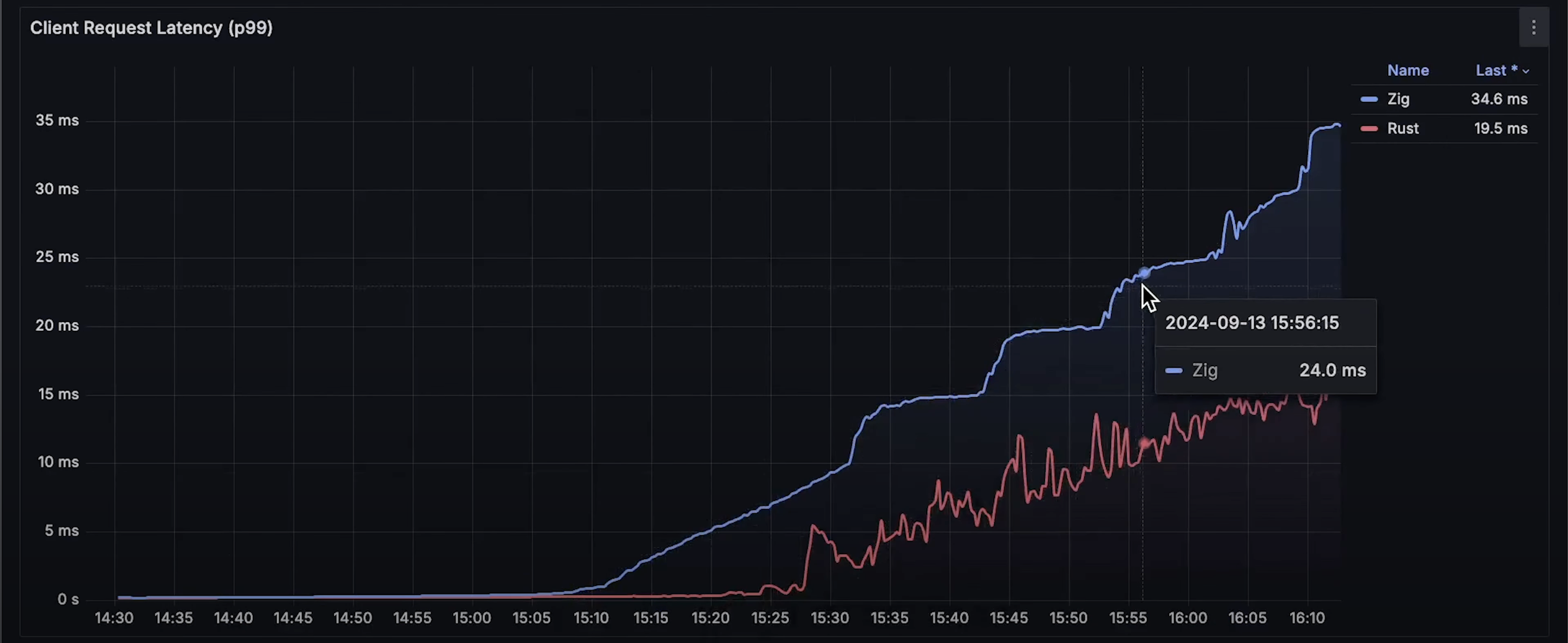
- Rust 的延迟也更低;
- 随着测试进行,这种差距变得越来越大。
当 Zap 应用的 CPU 使用率达到 80% 时,应用开始 性能下降,延迟增加,并且由于大量 未完成的请求,内存占用出现 剧烈波动。
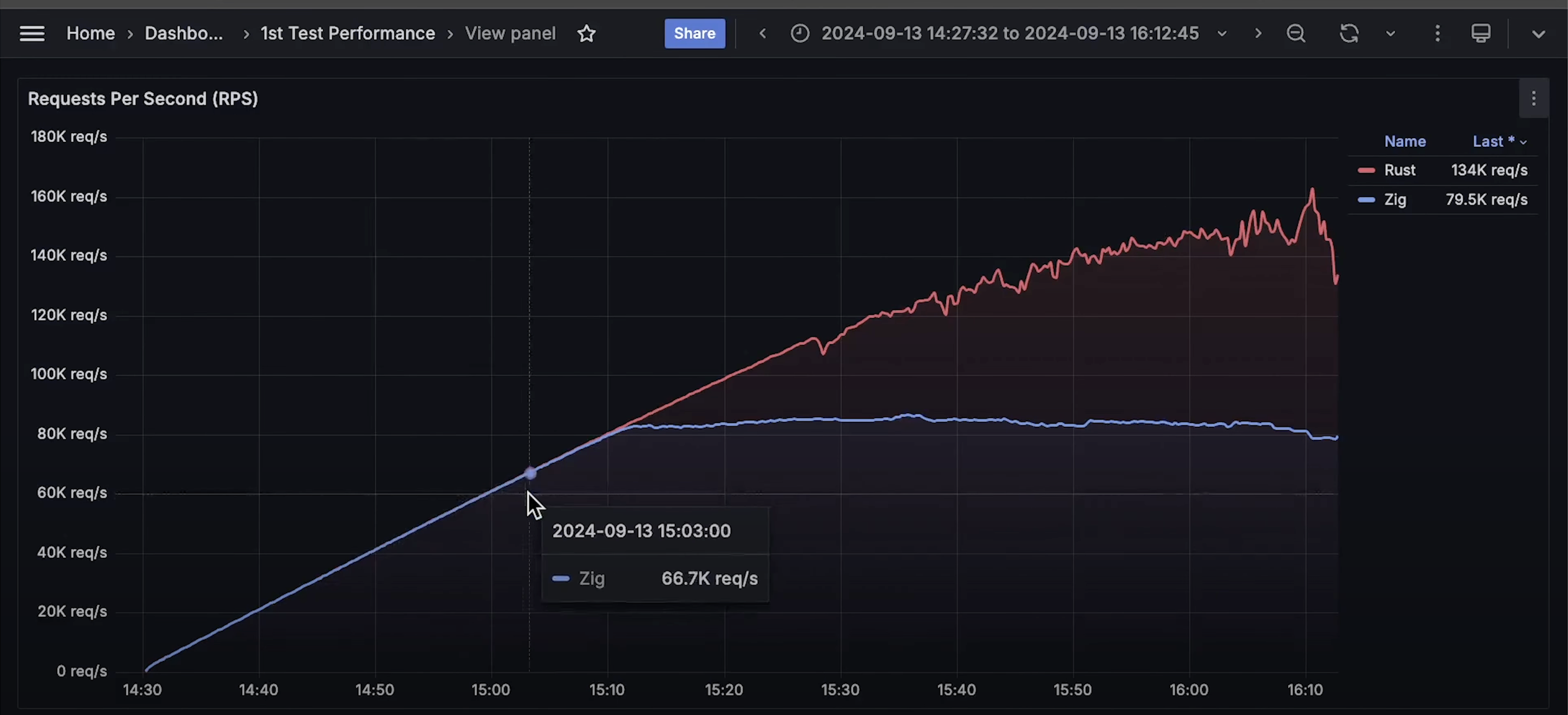
大约在 8 万请求/秒 时,Zap 达到了极限,无法处理更多请求,CPU 使用率飙升至 100%。
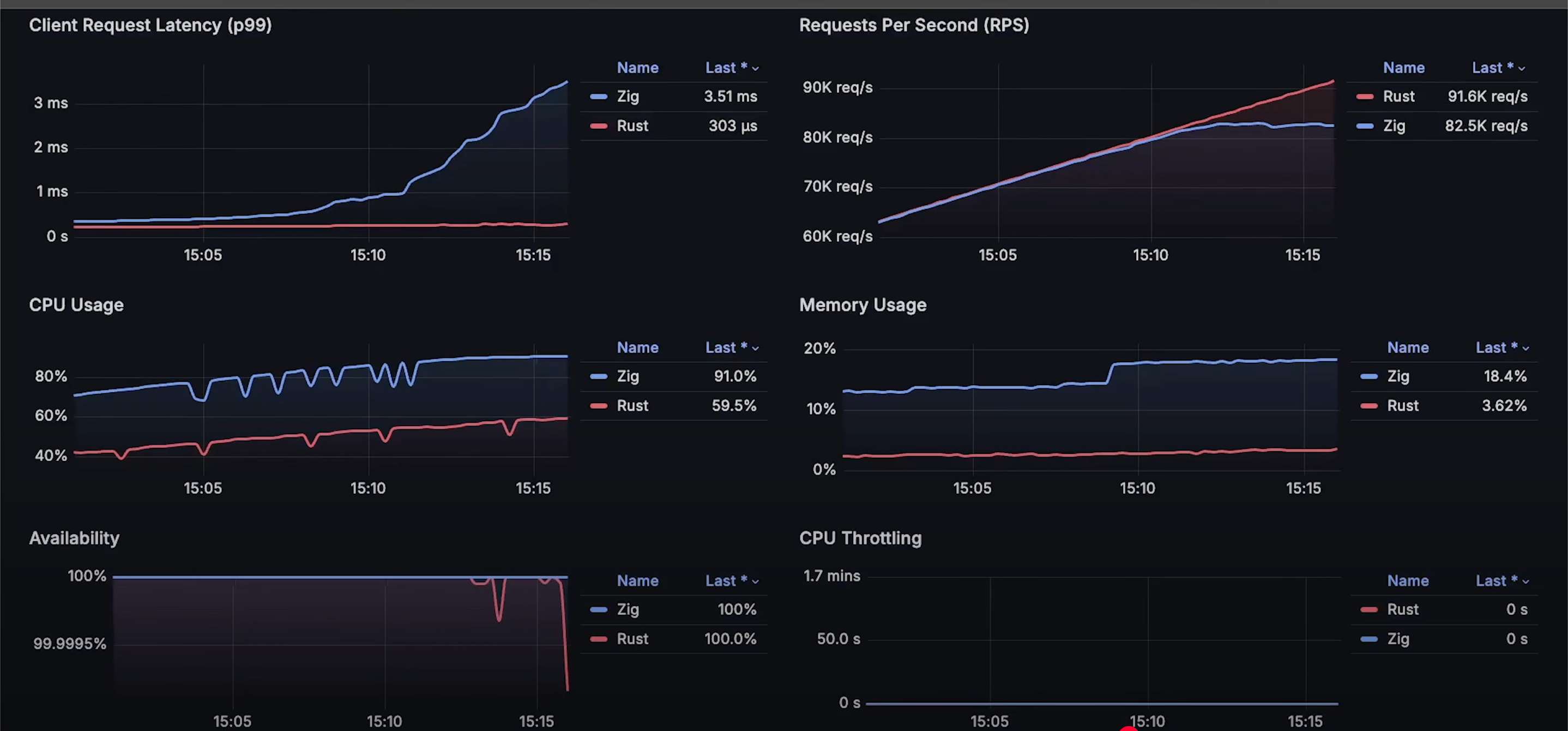
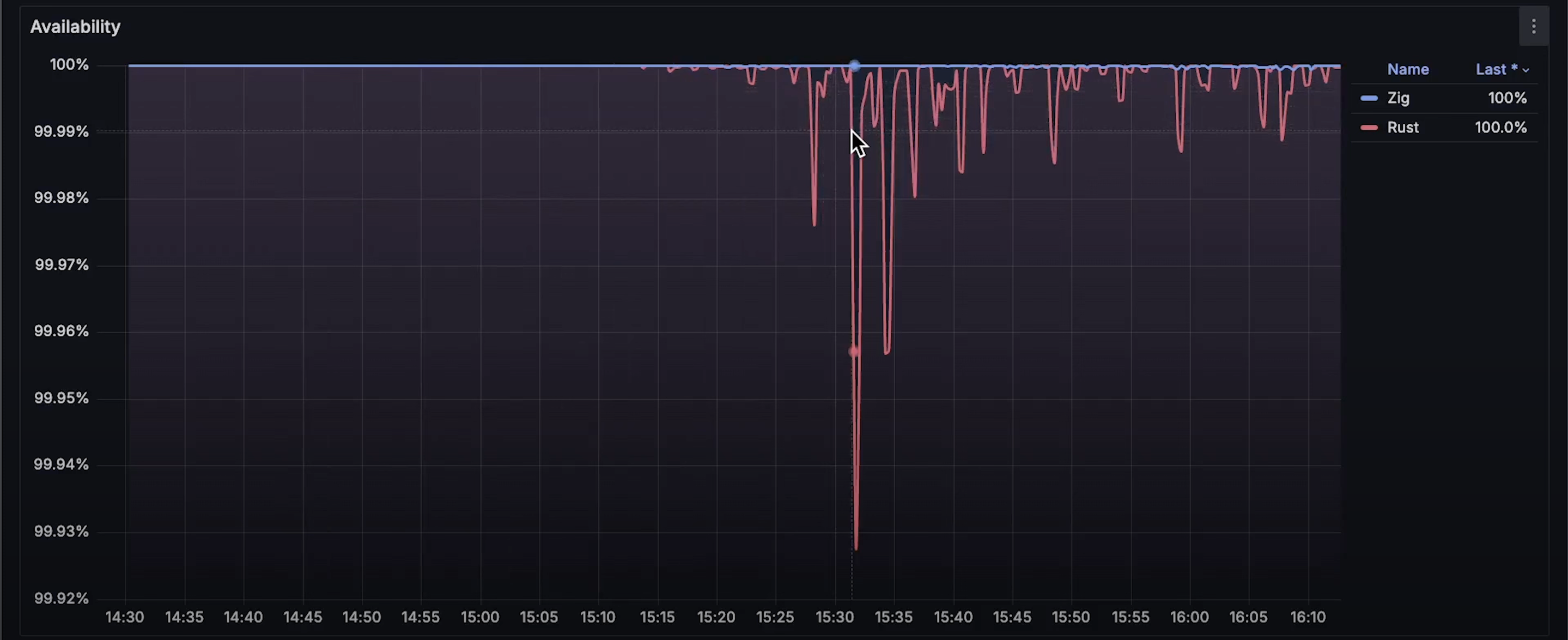
随着测试的继续,Zap 的延迟持续上升,并且偶尔会出现 Rust 的请求超时。不过 Rust 的超时数量极少,基本 不会影响可用性,仍然 维持在 99% 以上。
在大约 10 万请求/秒 时,Rust 的延迟也开始上升,并且 可用性有所下降。
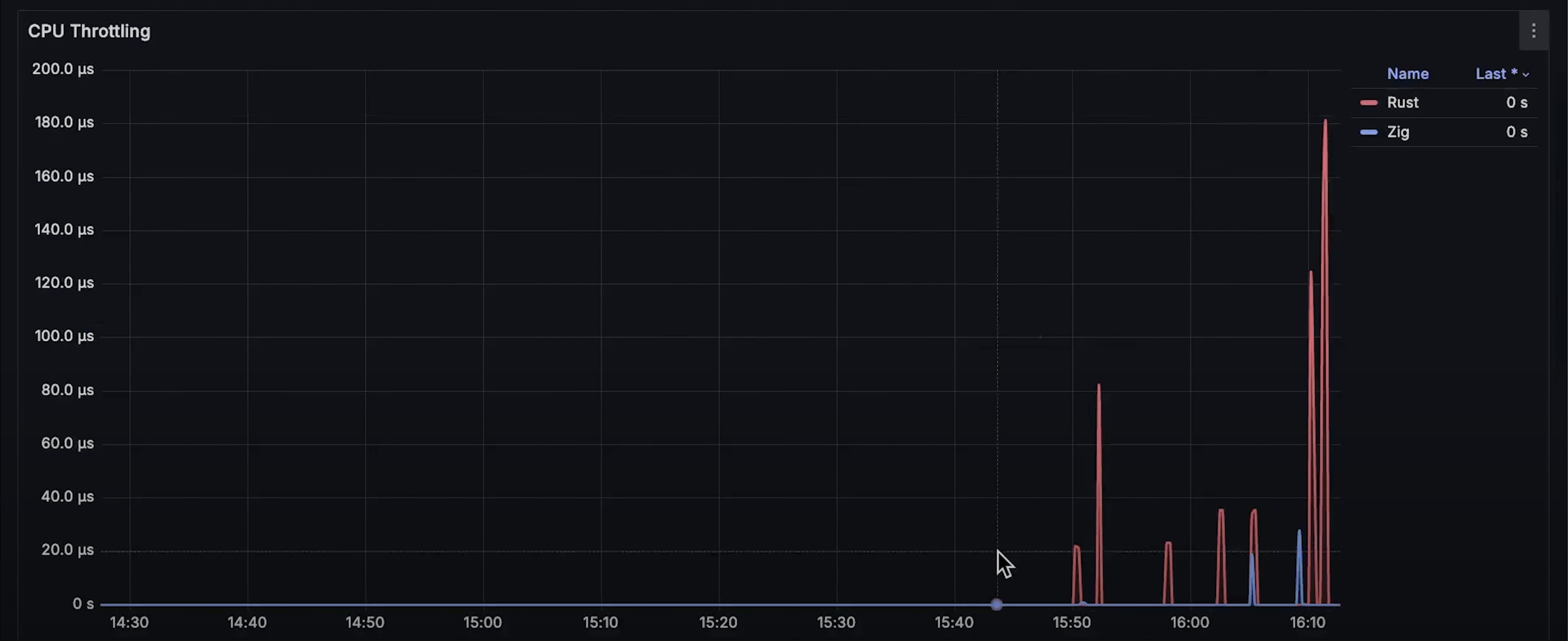
继续增加负载后,Kubernetes 开始对 Rust 和 Zap 进行 CPU 限流,最终我们达到了 Rust 能处理的最大请求数---16 万请求/秒。
最终数据分析
让我们查看整个测试期间的 数据图表:
- 请求数曲线:Rust 处理的请求数量远高于 Zap,即使它们线程数相同。
- 内存使用曲线:Zap 的内存使用量远高于 Rust。
- CPU 限流曲线:测试后期,Kubernetes 对两个应用都进行了 CPU 限流。
- 请求延迟曲线:Rust 的延迟明显低于 Zap。
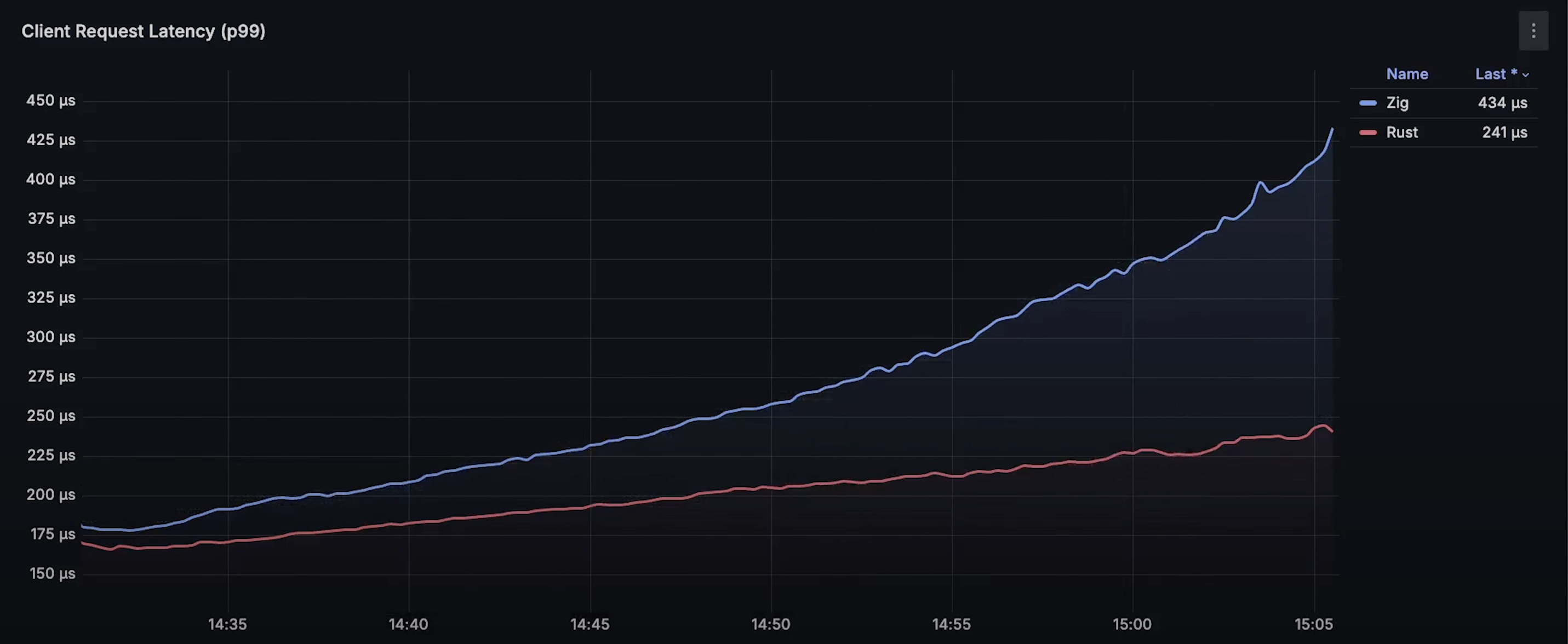
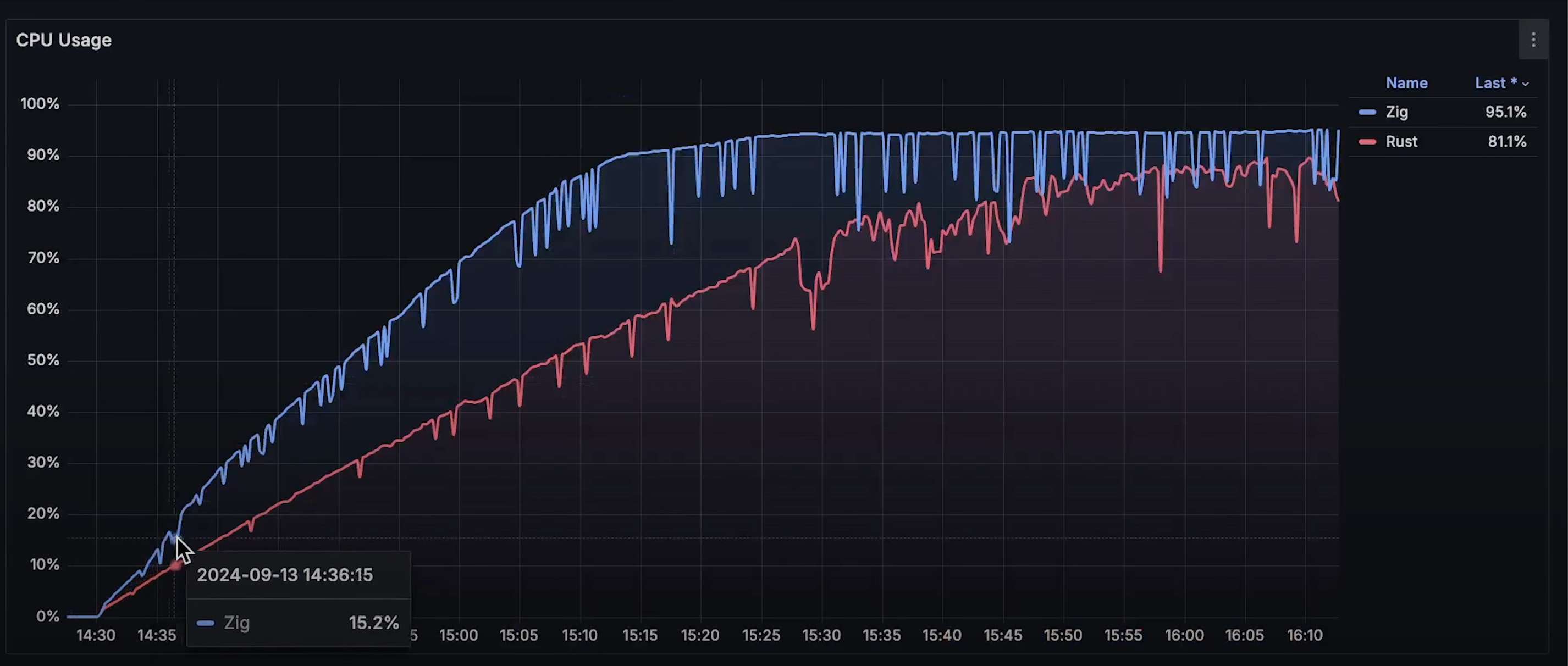
- CPU 使用曲线:Zap 占用的 CPU 远高于 Rust。
- 可用性曲线:Rust 的可用性始终保持在 99% 以上,而 Zap 下降得更快。
总结
如果你有任何优化建议,欢迎提交 Pull Request,我会进行测试。如果改进显著,我会发布 更新视频。此外,欢迎查看我的 基准测试视频合集,相信你会感兴趣。感谢观看,我们下期再见!

















 2447
2447

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









