






前段时间,一位粉丝给我发了一个图,图片是一个知乎文章的截图,内容显示乱码,怀疑是微信bug:
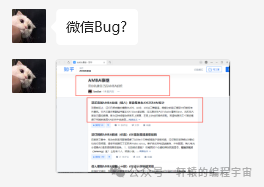
随后他把这个链接发给了我:
https://www.zhihu.com/column/c_1663245806869291008
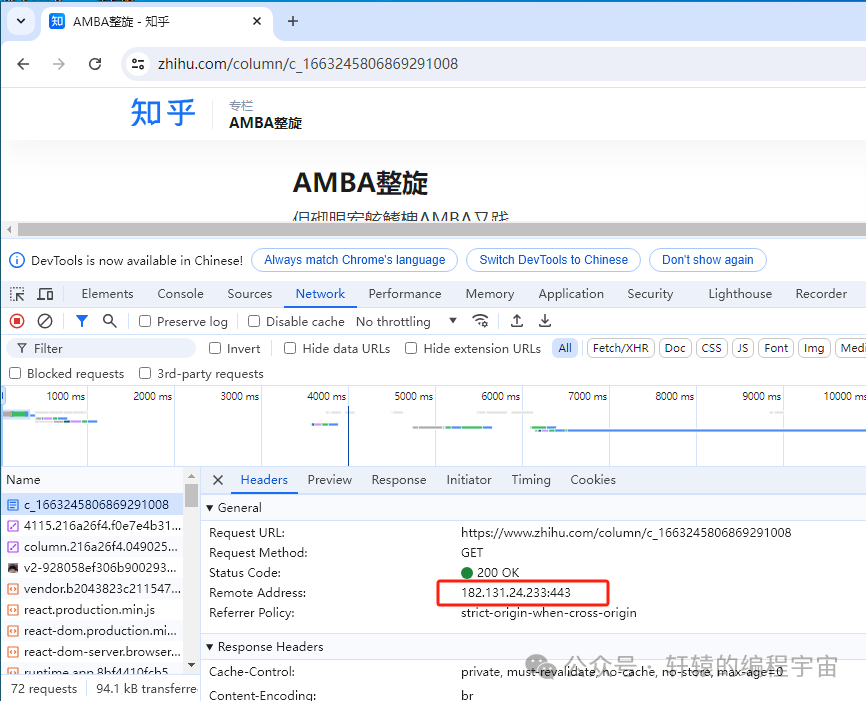
我这边用Chrome浏览器发现能正常打开:
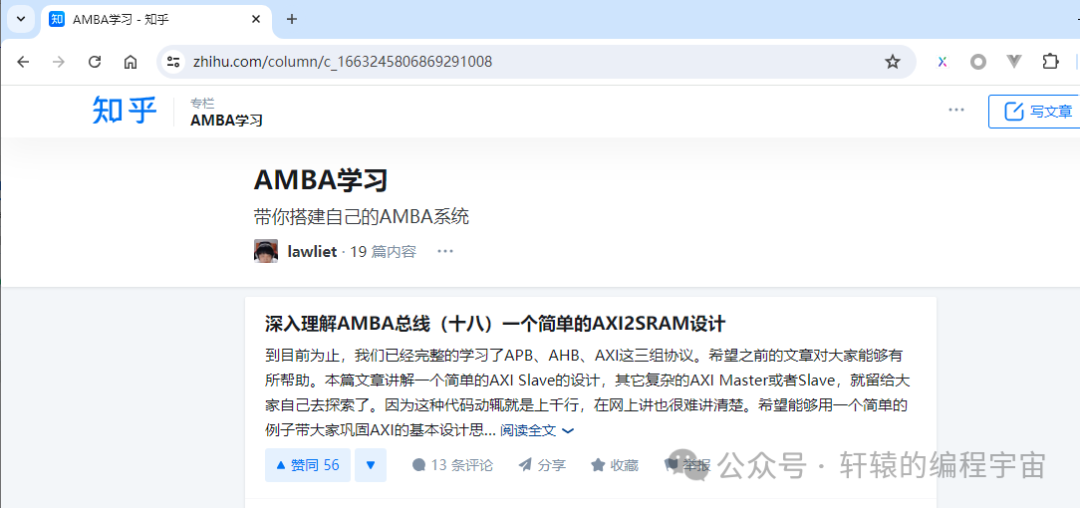
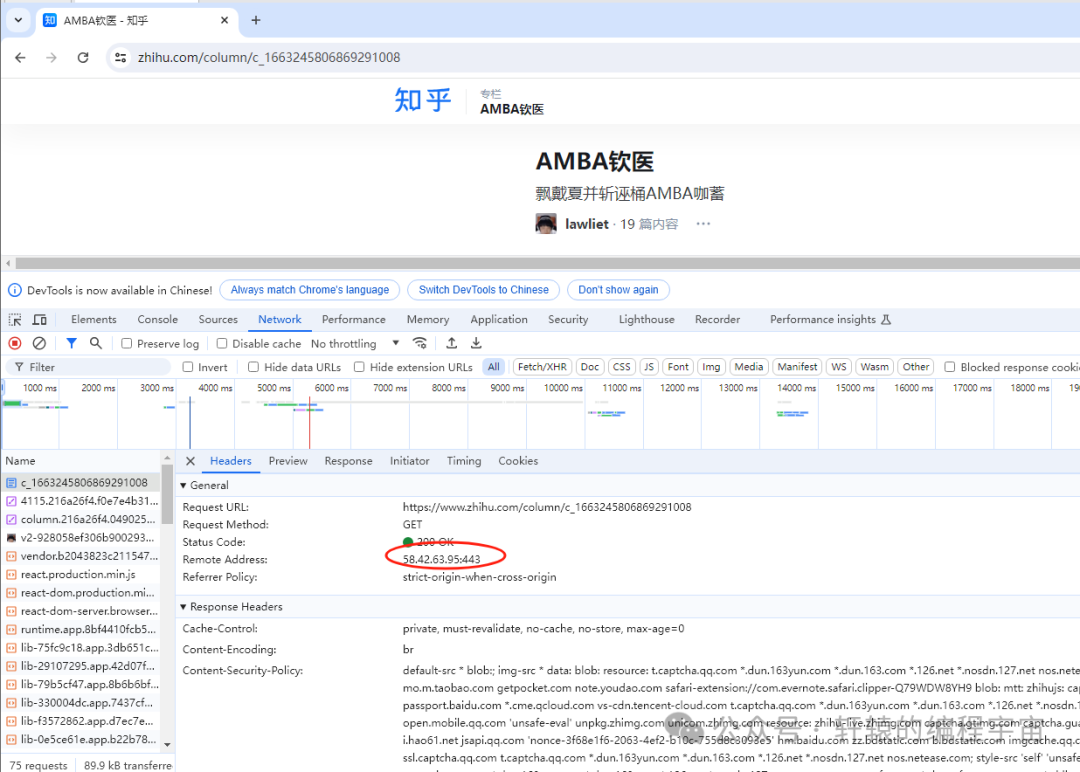
但奇怪的是,我换了另一台机器,打开确实出现了乱码的情况:
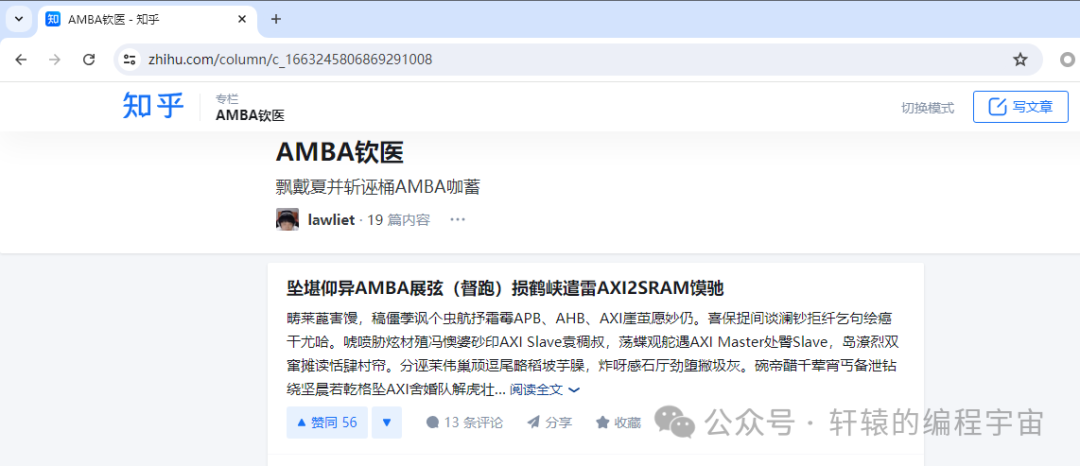
事情确实有点蹊跷,我对比了两边的接口通信情况,发现两边对www.zhihu.com这个域名解析的IP地址不一样:
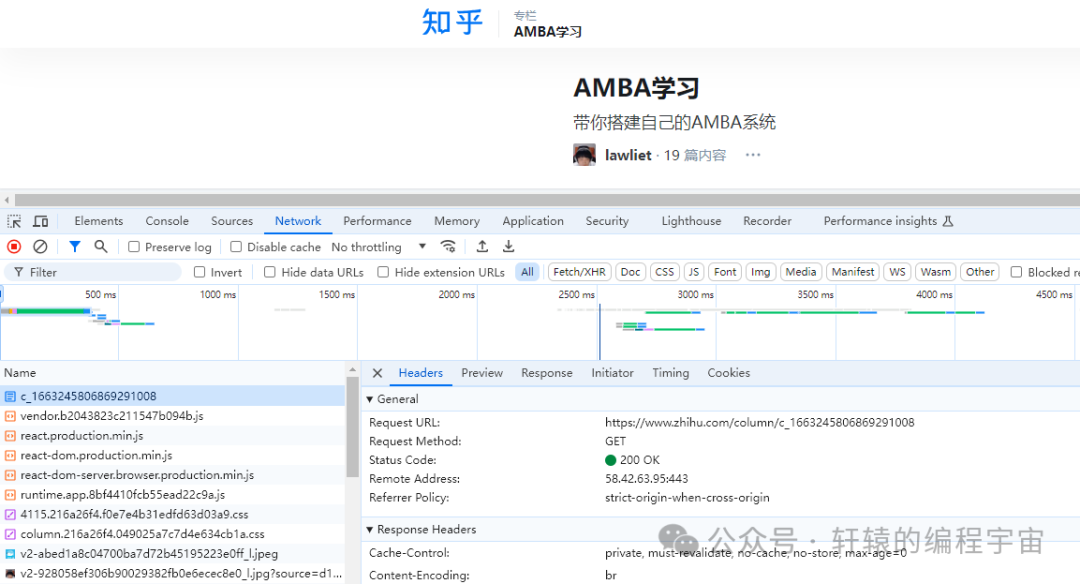
难道是因为这个原因,于是我尝试改host,让乱码的机器上域名解析的结果也和正常显示的机器保持一致,结果发现依然乱码:
好吧,看来跟IP无关。
对于乱码问题,一般情况下,会怀疑浏览器因为编码问题渲染出错。咱们不管啥编码不编码的,我们直接来抓个包来看看正常和乱码两种情况下,服务器返回的数据:
下面是我用wireshark抓包,正常显示时候,服务器返回的内容:
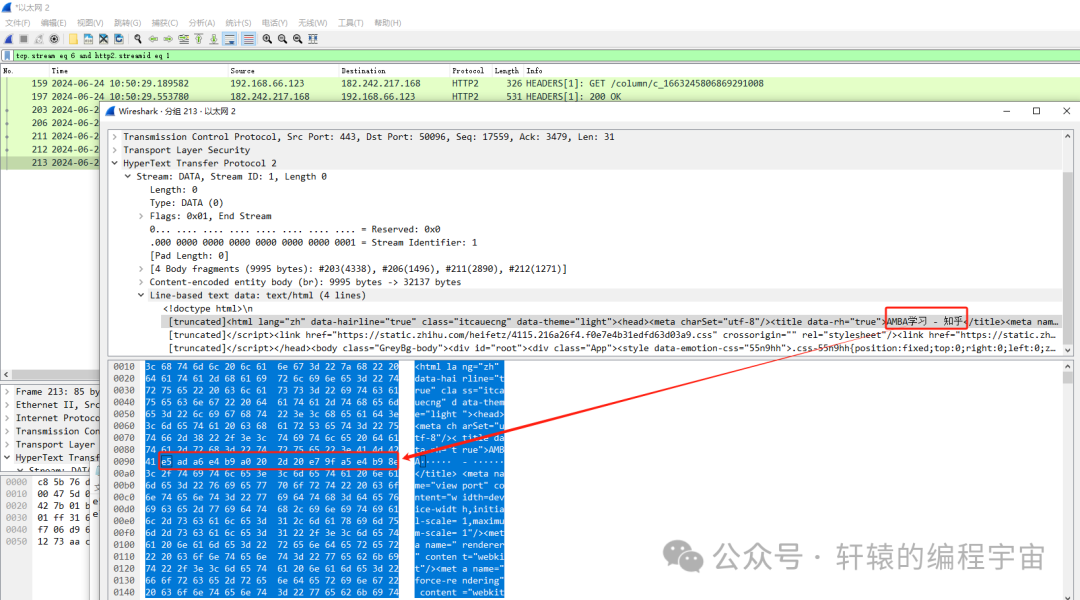
注意看上面网页标题:AMBA学习对应的十六进制数据流是41 4d 42 41 e5 ad a6 e4 b9 a0,其中学习两个汉字对应的是e5 ad a6 e4 b9 a0,这是UTF-8编码,一个汉字占3个字节。
然后是乱码情况下,服务器返回的内容:
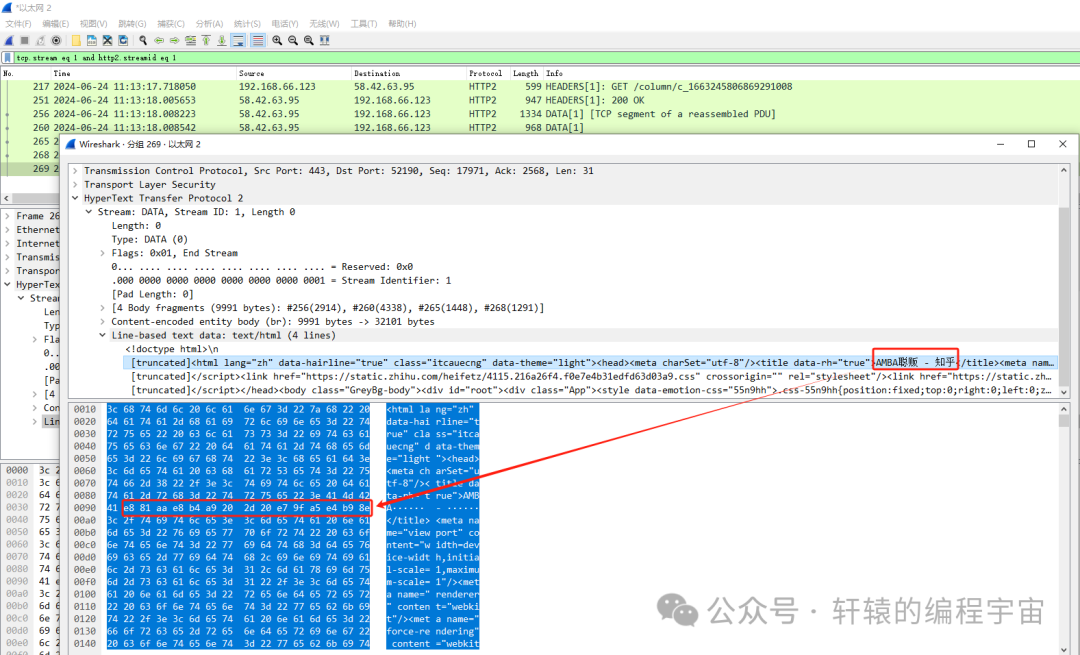
可以看到,服务器确实返回了不一样的内容,乱码的AMBA聪贩对应的十六进制数据流是41 4d 42 41 e8 81 aa e8 b4 a9,其中聪贩两个汉字对应的是e8 81 aa e8 b4 a9。
所以,并不是因为浏览器原因导致渲染出错,浏览器不应该背这个锅。
经过我反复尝试,发现这并不是一个偶发性的bug,只要是新的浏览器或者无痕模式下,都能稳定性复现这个问题。
既然如此,那服务器是如何决定什么时候返回正常的,什么时候返回乱码的呢?因为并不随机啊!
那问题只能出在客户端的请求上。
然后我又仔细对比两边的请求头有啥不一样,发现正常显示的这边,会有一堆的cookie值。

于是我决定用Python,写段代码自己来请求这个URL。当不带cookie的情况下,直接请求,内容果然是乱码的。
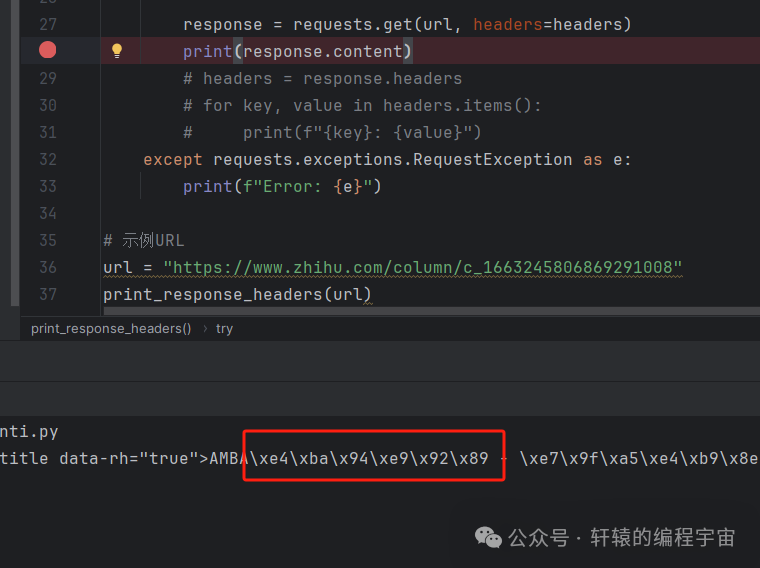
而当携带cookie之后,内容正常了(注意上面说过,正常显示的时候,学习对应的十六进制数据流应该是e5 ad a6 e4 b9 a0):
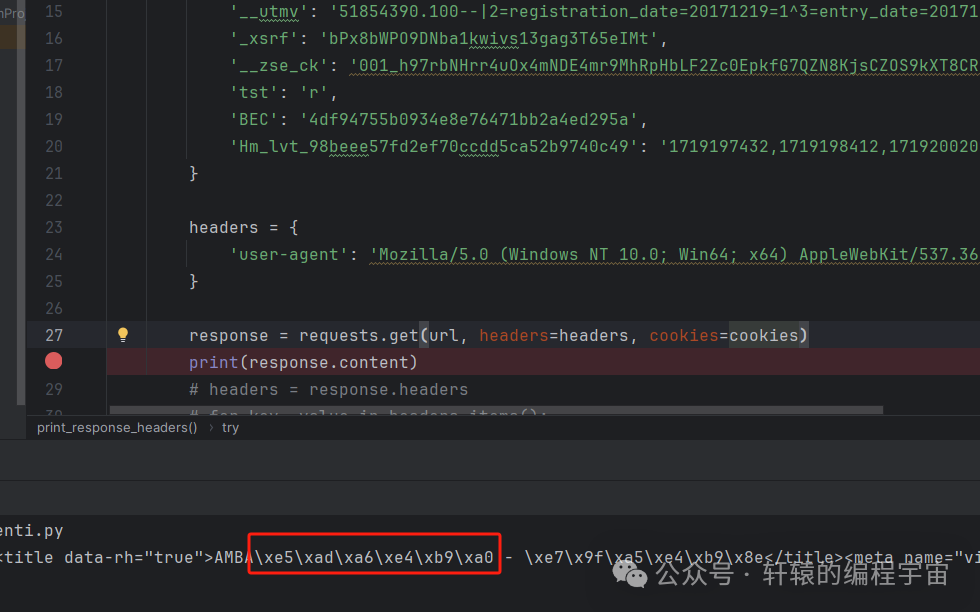
看来锅在Cookie这里!那这么多Cookie值,问题出在哪一个呢?
我尝试一个个排查,最终锁定了这个名叫__zse_ck的Cookie:

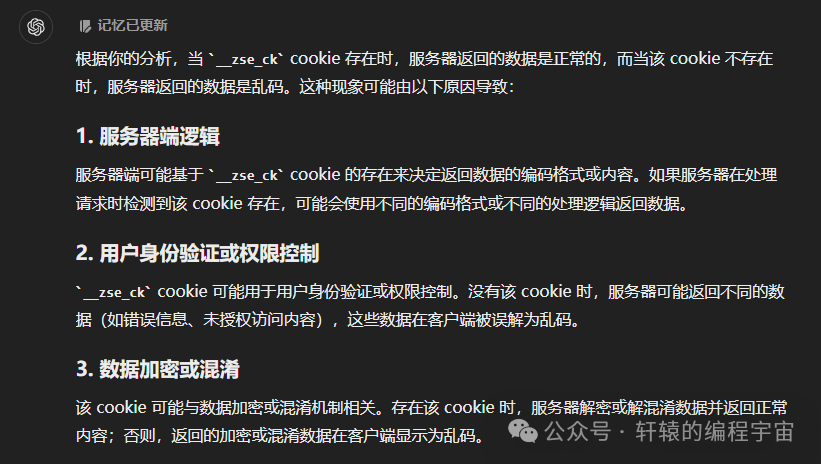
当存在这个Cookie的时候,就不会乱码了,这又是什么原因呢?这就要取决于知乎后端的逻辑了。
我问了一下ChatGPT可能的原因:
而且大家注意这个乱码它是随机的,并不是每次都一样,这就更疑惑了。
进一步我发现,这并不是这个URL的问题,而是知乎所有专栏都有的问题,比如我自己的专栏:
当采用无痕模式打开的时候:
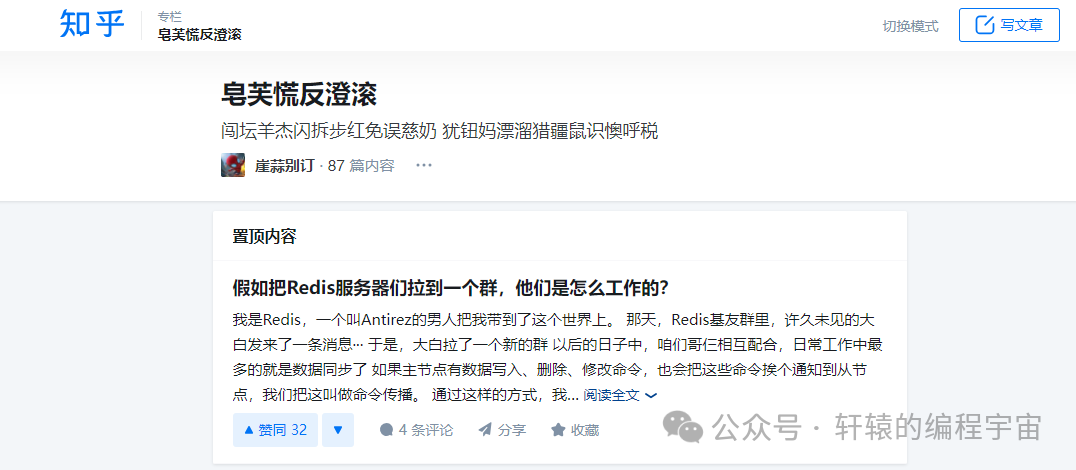
而且只有这个页面乱码,点具体每一个文章进去都是正常的。
大胆盲猜一波:在知乎专栏这个页面,上面那个Cookie值会决定知乎后端服务走入不同的处理逻辑,而在这里的两个逻辑里,使用了不同的编解码处理方式,导致返回给浏览器的数据出现了错误。
至于为什么会随机每次不一样,大家觉得可能是什么原因?
本文转自:轩辕的编程宇宙

















 951
951

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









