






导读:本文深入探讨了树形结构在实际应用中的广泛使用及其重要性,并提出了一套通用且高效的工具类TreeUtil来处理与树形数据相关的操作。
前言
树形结构在我们生活和工作中随处可见,如文件夹文档、商品分类、审批流程、层级架构等。其数据结构是通过某种映射来组织对象的上下级关系,使这些对象形成树形层级,常见的应用场景包括:
-
电商分类:根据不同的类型划分商品,便于用户快速查找需要的产品。
-
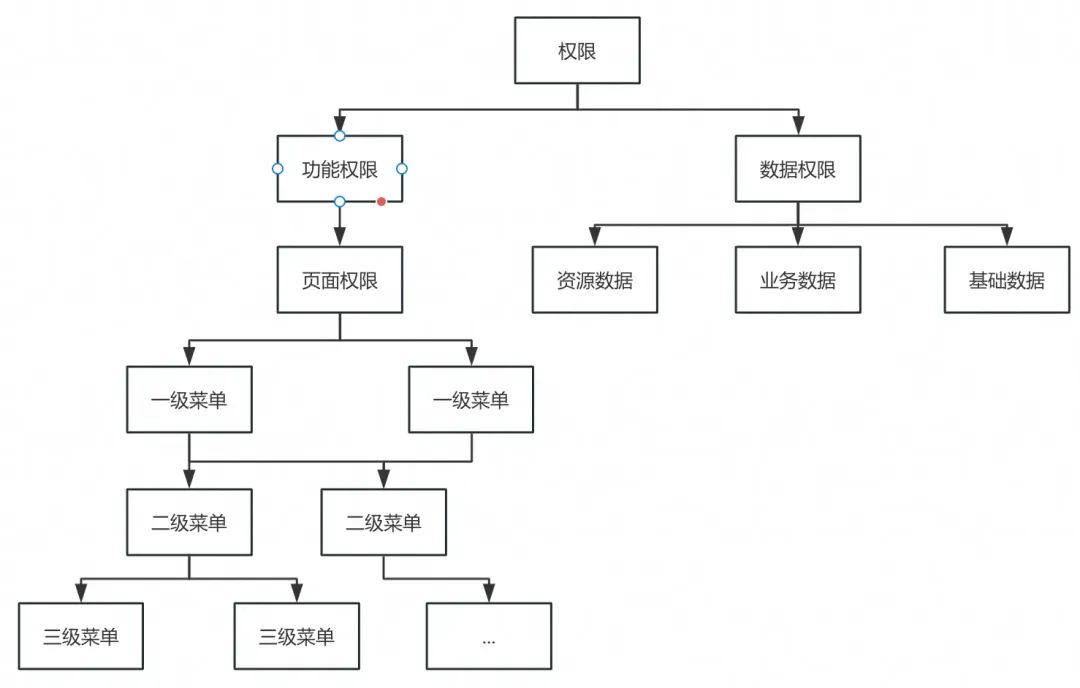
系统菜单和权限多级分类: 后台系统菜单、功能、权限一般是层级化的,通过树形结构便于呈现和管理各个菜单项。
-
评论回复: 树形结构可以用来显示帖子回复的关系,这有助于查看讨论的脉络。
-
文件夹目录:操作系统中的文件夹和文件通过树形层级结构进行组织和显示,以便用户操作。
-
业务审批流程:在职级架构中,树形结构有助于展示和管理各个流程节点及其展示上下级层级关系。
树形结构其本质是根据某种层级关系对数据列表进行抽象展示。此应用可显著提升数据的组织和展示效率,使用户更直观地理解和高效获取信息。

电商分类中的应用
操作系统文件夹结构
权限管控(RBAC)模型树
背景:同一段代码写N遍?每个项目都要写?
-
在最近在业务开发中,用户和后台管理端界面内需要展示本地生活架构下各个BU的全部项目、产品、业务、权限、投入分类多个域的树信息,它们虽然存储于数据库独立底表但是都有极其相似的属性(如名称,id,父级id映射值等)。在根据业务场景构建不同的查询条件从各自数据库中查询后,封装成树结构返回。如果是单独为每一个域写一个封装树的方法,那么会有多个几乎一模一样的方法散落在不同的地方,为此构建一个通用的树工具类是十分必要的。
-
每个业务项目中都在重复的写这些操纵树的方法,造成冗余和重复“造轮子”。因此一些常用的健壮的对树的操纵,包括树构建、排序、搜索、遍历等,可以抽取出来封装到公共组件供其他业务项目使用。
方案选择
使用Map
Map构建树demo
public List<Menu> buildTree(List<Menu> list) {ArrayList<Menu> res = new ArrayList<>();// 创建一个Map,以id为键Map<Integer, Menu> dtoMap = new HashMap<>();for (Menu dto : list) {dto.setSubMenus(new ArrayList<>()); // 初始化每个节点的children列表dtoMap.put(dto.getId(), dto);}// 遍历列表,将每个节点添加到其父节点的children列表中for (Menu menu : list) {Menu parent = dtoMap.get(menu.getParentId());if (parent != null) {parent.getSubMenus().add(menu);}// 从根节点开始构建树,假设根节点的parentId为0if (NumberUtils.INTEGER_ZERO.equals(menu.getParentId())) {res.add(menu);}}return res;}
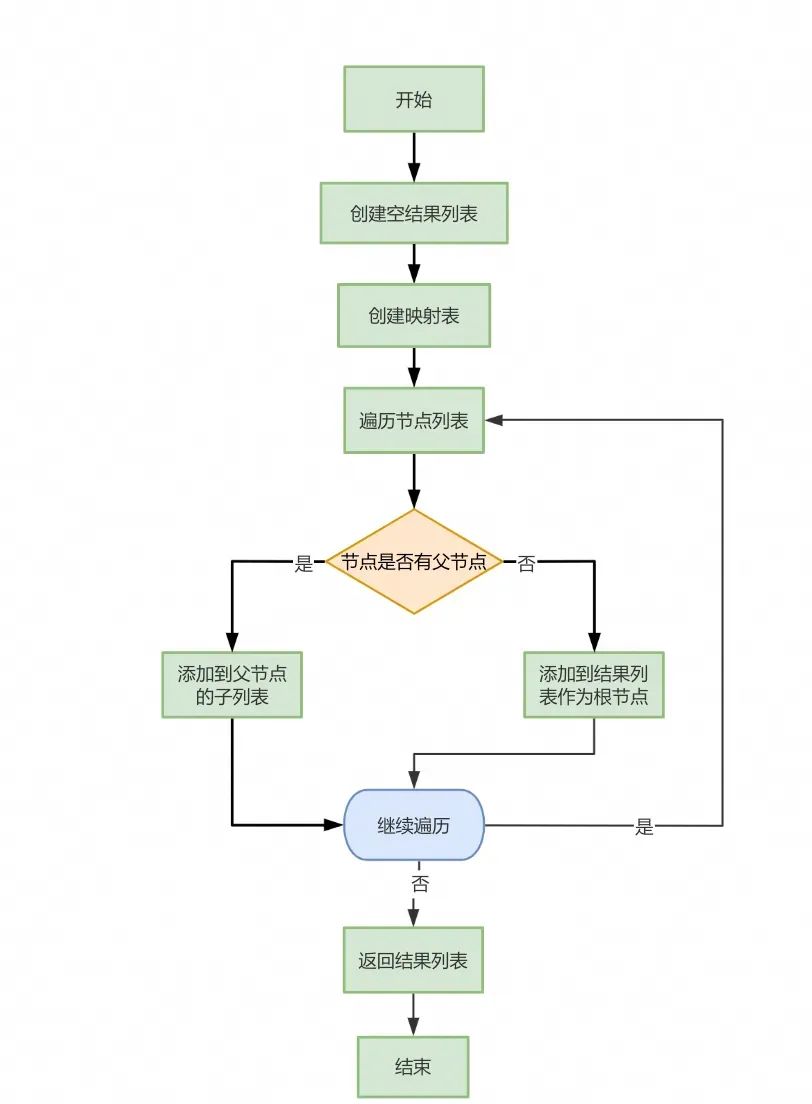
使用Map空间换时间的思路其实并不复杂,主要有三步:
1.每一个节点以id为key,对象为value构建Map
2.遍历原List,找到父节点时将自身添加到父节点的subMenus里面去
3.如果此节点是根节点,添加到返回列表中
该方法虽对单一表实体类列表转树结构简单高效,但针对不同实体类需复制相同代码,仅替换特定类名如将 Menu 改为 Menu1。此外,若另一表实体类根节点的 parentId 是 null、-1 或其他非零值,或父级 ID 属性及子集合属性命名不同,则现有方法缺乏通用性和灵活性。
因此,为了使得封装树的方法更通用,工具类下的方法都需要使用简单健壮的泛型+函数式接口来接收入参和出参。
使用递归
递归构建树demo
public static List<Menu> recursiveTree(List<Menu> menus, int parentId) {List<Menu> result = new ArrayList<>();for (Menu menu : menus) {if (menu.getParentId().equals(parentId)) {// 递归查找子菜单menu.setSubMenus(recursiveTree(menus, menu.getId()));result.add(menu);}}return result;}
使用递归行数虽然较少,但是我们会发现大量无效的循环被使用和可读性差的问题,不推荐。
性能对比测试
常用的列表转树我们一般采用Map构建树或者递归构建树(较少使用)的算法来实现,前者用空间来换时间后者则相反,那么哪种效果会更好一点呢,我们分别对1万、2万、3万、4万、5万、6万个节点进行构建树耗时测试对比:
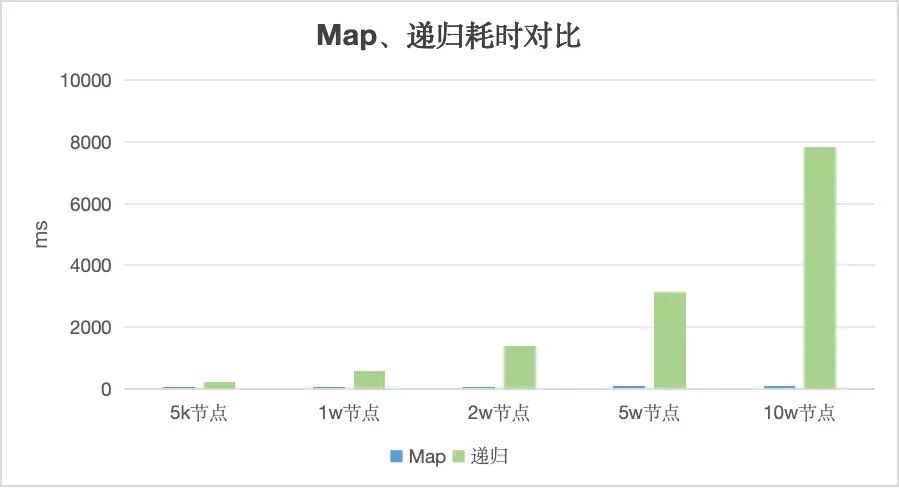
本地测试取平均值,不同机器、不同环境下可能会有不同的耗时时间(仅供参考)
通过对比可以看出递归实现耗时会随着节点增长呈指数增长,使用Map构建树的耗时就小的多了。显而易见,性能不在一个数量级而且使用递归时极有可能因为数据或者代码原因出现死循环,所以非特殊情况尽量选择Map构建树的策略。
TreeUtil工具包方法
如上文所说,为了使得所有方法更通用,工具类下的方法都需要使用简单健壮的泛型+函数式接口来接收入参和出参。
常见的函数式接口
Java 8自带了一些常用的函数式接口,位于java.util.function包中:
-
Function<T, R>:接受一个参数,返回一个结果。
-
Consumer<T>:接受一个参数,没有返回值。
-
Supplier<T>:不接受参数,返回一个结果。
-
Predicate<T>:接受一个参数,返回一个boolean值。
-
UnaryOperator<T>:接受和返回同类型的对象。
-
BinaryOperator<T>:接受两个相同类型的参数并返回相同类型的结果。
1.标准化接口减少了开发者自己定义类似接口的需要,并且提高了代码的可移植性和复用性。
2.提高代码的功能扩展性,通过组合不同的函数式接口,可以轻松地扩展和修改功能,而无需对现有的代码进行大量改动。
3.函数式接口为API设计提供了更灵活的选项。API用户可以通过传递Lambda表达式或方法引用来自定义行为,使API更加通用和实用。
构建树makeTree()方法
通用构建树方法
/*** 构建树** @param menuList 需要合成树的List* @param pIdGetter 对象中获取父级ID方法,如:Menu:getParentId* @param idGetter 对象中获取主键ID方法 ,如:Menu:getId* @param rootCheck 判断对象是否根节点的方法,如: x->x.getParentId()==null,x->x.getParentMenuId()==0* @param setSubChildren 对象中设置下级数据列表方法,如: Menu::setSubMenus*/public static <T, E> List<E> makeTree(List<E> menuList, Function<E, T> pIdGetter, Function<E, T> idGetter, Predicate<E> rootCheck, BiConsumer<E, List<E>> setSubChildren) {Map<T, List<E>> parentMenuMap = new HashMap<>();for (E node : menuList) {//获取父节点idT parentId = pIdGetter.apply(node);//节点放入父节点的value内parentMenuMap.computeIfAbsent(parentId, k -> new ArrayList<>()).add(node);}List<E> result = new ArrayList<>();for (E node : menuList) {//添加到下级数据中setSubChildren.accept(node, parentMenuMap.getOrDefault(idGetter.apply(node), new ArrayList<>()));//如里是根节点,加入结构if (rootCheck.test(node)) {result.add(node);}}return result;}
我们将设定获取父级字段方法,根节点的判定,获取子列表方法都通过入参来指定,类实体通过泛型来集成,这样不管面对任意属性名称或是特殊根级的值,都有很好的普适性。即拆即用,随处可用,经过测试后泛型+函数式接口对性能几乎没有影响。
使用demo
public static void main(String[] args) {// 生成10万个测试数据List<Menu> testMenus = generateTestMenus(100000);// 构建树List<Menu> tree = makeTree(testMenus,Menu::getParentId,Menu::getId,x -> x.getParentId() == 0,Menu::setSubMenus);}
查找树search()方法
树中查找(当前节点不匹配predicate,只要其子节点列表匹配到即保留)
/**
* 树中查找(当前节点不匹配predicate,只要其子节点列表匹配到即保留)
* @param tree 需要查找的树
* @param predicate 过滤条件,根据业务场景自行修改
* @param getSubChildren 获取下级数据方法,如:MenuVo::getSubMenus
* @return List<E> 过滤后的树
* @param <E> 泛型实体对象
*/
public static <E> List<E> search(List<E> tree, Predicate<E> predicate, Function<E, List<E>> getSubChildren) {
List<E> result = new ArrayList<>();
for (E item : tree) {
List<E> childList = getSubChildren.apply(item);
List<E> filteredChildren = new ArrayList<>();
if (childList != null && !childList.isEmpty()) {
filteredChildren = search(childList, predicate, getSubChildren);
}
// 如果当前节点匹配,或者至少有一个子节点保留,就保留当前节点
if (predicate.test(item) || !filteredChildren.isEmpty()) {
result.add(item);
// 还原下一级子节点如果有
if (!filteredChildren.isEmpty()) {
getSubChildren.apply(item).clear();
getSubChildren.apply(item).addAll(filteredChildren);
}
}
}
return result;
}如果当前节点未命中匹配条件,那么继续向下寻找,直到末级。
过滤树filter()方法
filter()方法和Stream的filter()方法一样,过滤满足条件的数据节点,如里当前节点不满足其所有子节点都会过滤掉。
过滤树
/*** 树中过滤* @param tree 需要进行过滤的树* @param predicate 过滤条件判断* @param getChildren 获取下级数据方法,如:Menu::getSubMenus* @return List<E> 过滤后的树* @param <E> 泛型实体对象*/public static <E> List<E> filter(List<E> tree, Predicate<E> predicate, Function<E, List<E>> getChildren) {return tree.stream().filter(item -> {if (predicate.test(item)) {List<E> children = getChildren.apply(item);if (children != null && !children.isEmpty()) {filter(children, predicate, getChildren);}return true;}return false;}).collect(Collectors.toList());}
使用demo
//查找包含“ATA”菜单的树List<MenuVo> filterMenus =TreeUtil.filter(tree,x->x.getName()!=null&&x.contains("ATA");,MenuVo::getSubMenus);
排序 sort()方法
树形结构进行排序
/*** 对树形结构进行排序** @param tree 要排序的树形结构,表示为节点列表。* @param comparator 用于节点比较的比较器。* @param getChildren 提供一种方法来获取每个节点的子节点列表。* @param <E> 元素的类型。* @return 排序后的节点列表。*/public static <E> List<E> sort(List<E> tree, Comparator<? super E> comparator, Function<E, List<E>> getChildren) {// 对树的每个节点进行迭代处理for (E item : tree) {// 获取当前节点的子节点列表List<E> childList = getChildren.apply(item);// 如果子节点列表不为空,则递归调用 sort 方法对其进行排序if (childList != null && !childList.isEmpty()) {sort(childList, comparator, getChildren);}}// 对当前层级的节点列表进行排序// 这一步确保了所有直接子节点在递归返回后都已排序,然后对当前列表进行排序tree.sort(comparator);// 返回排序后的节点列表return tree;}
使用demo
// 定义比较器(比如按 ID 排序)Comparator<Menu> nodeComparator = Comparator.comparingInt(Menu::getId);List<Menu> sort = sort(tree, nodeComparator, Menu::getSubMenus);
过滤并处理 filterAndHandler()方法
横向拓展,加入过滤或查找条件,即可完成一个通用树形过滤方法。再延伸,查找到匹配的节点后对此节点进行特殊业务需求处理也是使用频率极高的。
过滤并处理
/*** 树中过滤并进行节点处理(此处是将节点的choose字段置为false,那么就在页面上可以展示但无法被勾选)* @param tree 需要过滤的树* @param predicate 过滤条件* @param getChildren 获取下级数据方法,如:MenuVo::getSubMenus* @param setChoose 要被处理的字段,如:MenuVo::getChoose,可根据业务场景自行修改* @param <E> 泛型实体对象* @return List<E> 过滤后的树*/public static <E> List<E> filterAndHandler(List<E> tree, Predicate<E> predicate, Function<E, List<E>> getChildren, BiConsumer<E, Boolean> setChoose) {return tree.stream().filter(item -> {//如果命中条件,则可以被勾选。(可根据业务场景自行修改)if (predicate.test(item)) {setChoose.accept(item, true);} else {setChoose.accept(item, false);}List<E> children = getChildren.apply(item);if (children != null && !children.isEmpty()) {filterAndHandler(children, predicate, getChildren, setChoose);}return true;}).collect(Collectors.toList());}
上面展示的列表转树和查找、搜索、过滤、树中过滤可任意合并为通用方法,以适配更多业务场景,减少重复代码,便于在其他系统中快速接入和使用。此外,该工具包还可扩展实现排序、前中后序遍历等功能。
拓展:Traverser
Google 的开源库 Guava[1] 提供了一些便捷的方法来处理树形结构。事实上,其主要提供了对于图结构的相关处理方法,同时可以兼容树、森林的处理。
Guava 的 Traverser 类是一个非常有用的工具,它可以处理树形结构、图的遍历。通过使用这个类,你可以轻松实现各种树的深度优先搜索(DFS)、广度优先搜索(BFS)操作。虽然 Traverser 本身并不直接提供如修改、增删节点等操作,因为其设计概念是基于不可变的结构遍历,但可以通过合理的设计将这些功能集成在上层业务逻辑中。如果需要对结构本身进行修改、变形等操作,则需要编写额外的逻辑来执行这些操作。
遍历主要功能
1.不同方式的遍历:
-
Pre-order Traversal(前序遍历):首先访问节点本身,然后递归地访问其子节点。
-
Post-order Traversal(后序遍历):递归地访问节点的子节点,然后访问节点本身。
-
Breadth-first Traversal(广度优先遍历):按层级顺序访问节点,即从根节点开始逐层向下。
2.支持循环和图形结构:
-
无向图遍历:Traverser 可以用于处理图形结构的遍历,通过配置可以避免重新访问已访问过的节点,从而避免在有循环的图中陷入无限循环。
-
限定遍历深度:在需要限制图或树遍历的深度时,可以通过某些技巧来限制深度,这虽然需要一些DIY的实现,但Guava的构造提供了基础支持。
拓展方法:遍历树
实际上,需要遍历树时,只需要指定 父节点 => 子节点集合 的映射方法即可。
遍历树demo
import com.alibaba.schedulerx.shade.com.google.common.collect.TreeTraverser;import com.fasterxml.jackson.core.JsonProcessingException;import com.fasterxml.jackson.databind.ObjectMapper;import java.util.ArrayList;import java.util.List;import java.util.function.Function;public class TreeUtilPro {private static final ObjectMapper objectMapper = new ObjectMapper();//遍历策略(可根据用户自己的使用场景设置)public enum TraversalType {PRE_ORDER,POST_ORDER,BREADTH_FIRST}public static <T> String traverseTree(T root, Function<T, Iterable<T>> childrenFunction, TraversalType traversalType) throws JsonProcessingException {TreeTraverser<T> traverser = new TreeTraverser<T>() {@Overridepublic Iterable<T> children(T node) {return childrenFunction.apply(node);}};List<T> nodes;// 根据遍历类型选择不同的遍历策略switch (traversalType) {case PRE_ORDER:nodes = traverser.preOrderTraversal(root).toList();break;case POST_ORDER:nodes = traverser.postOrderTraversal(root).toList();break;case BREADTH_FIRST:nodes = traverser.breadthFirstTraversal(root).toList();break;default:throw new IllegalArgumentException("Unsupported traversal type");}// Convert list of nodes to JSONreturn objectMapper.writeValueAsString(nodes);}}
使用demo
public static void main(String[] args) throws JsonProcessingException {// Example setup: Create a simple tree with menuMenu leaf1 = new Menu(1, "leaf1", 3, new ArrayList<>());Menu leaf2 = new Menu(2, "leaf2", 3, new ArrayList<>());Menu root = new Menu(3, "root", 4, Arrays.asList(leaf1, leaf2));// Example: Pre-order traversalString json = traverseTree(root, Menu::getSubMenus, TraversalType.PRE_ORDER);}
当然,也可以不用Guava里面的方法,自己写一个前中后序、深度或者广度优先的方法,效果也是一样的,这里就不再赘述了。
执行效率
工具类中这些泛型和函数式接口的使用在对较深的树封装时会不会拖慢执行速度呢,我们还是使用5k,1w,5w和10w个节点来测试,并循环多次取平均值。
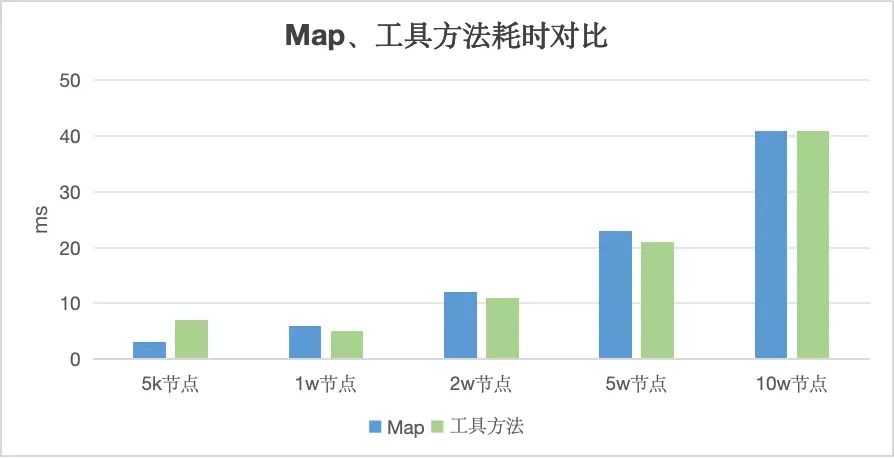
本地测试取平均值,不同机器、不同环境下可能会有不同的耗时时间(仅供参考)
我们可以从上图看到,排除机器性能、软件版本、时间计算方式等微小影响,两者几乎没有性能上的差异。
总结
本文上述方法主要封装了基础的树操作,工具类下的方法都使用了简单健壮的泛型+函数式接口来接收入参和出参,不仅可以为单一项目中多个DO使用同时也能横向对其他项目进行一样的封装并返回。工具类聚焦于构建和改造树形的展示,而非直接对原始树结构进行修改,例如节点的增删或更新。这种设计源自不可变数据结构的遍历思路,确保了操作的稳定性和减少副作用。
目前手头的项目更多的涉及树的子分支转移或者更新、删除。为了适应这些需要直接修改树结构的需求,能够实现动态变化节点或重构树形的业务场景,正在考虑要不要实现封装一些涉及数据库变更的公共方法,能够将指定的节点在数据层面实现变更,为系统提供更大的灵活性和功能扩展性,让对树结构处理的公共方法扩展到更多场景。
参考资料:
1、https://guava.dev/releases/31.1-jre/api/docs/com/google/common/graph/Traverser.html
2、使用Guava轻松搞定树结构!无需使用其他工具类!:https://juejin.cn/post/7418378848402653194
3、我是如何给阿里大神Tree工具类做CodeReview并优化的:https://juejin.cn/post/7398047016183889935

















 2105
2105

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









