








项目简介
生成高质量的3D内容对于视频游戏、电影制作、VR/AR等领域至关重要。当前3D-AIGC领域主要关注固定空间范围的3D内容生成,例如单个物体。 今天介绍我们团队最近被SIGGRAPH 2024 journal track接收的论文。 本文提出了一种可以生成可扩展(即无限)的3D场景的方法,这对于开放世界游戏尤其有价值。 论文标题为“BlockFusion: Expandable 3D Scene Generation using Latent Tri-plane Extrapolation”。BlockFusion算法基于3D扩散生成模型(Diffusion Model)。BlockFusion以立方体块的形式生成 3D 场景,并以简单的滑动窗口方式扩展场景。 顾名思义,它以以块(Block)的形式进行扩散(Diffusion)与融合(Fusion)。
利用BlockFusion构建的开放世界游戏Demo。玩家可以不受限地在世界里探索
BlockFusion的核心在于它的潜在三平面外推(Latent Tri-plane Extrapolation)机制,这一机制允许模型在保持场景语义和几何一致性的同时,生成无限大的3D场景。
项目地址:https://yang-l1.github.io/blockfusion/
代码:https://github.com/Tencent/BlockFusion

扩散生成模型训练过程
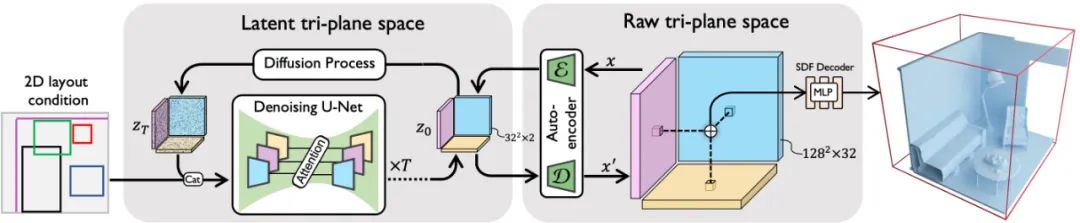
图1. BlockFusion的训练pipeline
如图1.所示,Blockfusion使用从完整3D场景Mesh中随机裁剪的3D块作为训练数据。这些3D块被转换成水密Mesh,以确保在训练过程中有明确的内部和外部定义(这一步对拟合Tri-plane很重要)。
训练过程分为三个阶段:
1. 原始Tri-plane面拟合:
通过每个块的拟合过程,将3D块转换为Neural Field。这里的Neural Field包括一个三平面(Tri-plane)和一个多层感知器(MLP)。三平面是一个张量,用于分解密集的3D体积网格,它基于三个轴对齐的2D平面(XY、YZ和XZ面)。MLP用于解码有符号距离场(SDF),从而重建3D形状。
2. 压缩到潜在Tri-plane空间:
参照 Stable Diffusion [1],为了提高训练效率和模型的泛化能力,我们使用自编码器(autoencoder)将原始三平面压缩到一个更紧凑的潜在三平面空间。这个潜在空间在保持相似几何形状表示能力的同时,显著减少了参数数量。这一步至关重要,我们发现在原始Tri-plane空间跑Diffusion无法生成有意义的形状。
3. 潜在三平面扩散(Latent Tri-plane Diffusion)和布局控制:
在潜在三平面空间上训练扩散模型(DDPM),这个过程中,模型学习如何从噪声中逐步恢复出有意义的潜在三平面表示。同时我们引入了2D布局控制机制,允许用户通过操作2D对象的Bounding Box来精确控制场景内物体的放置和排列。
图2. 受布局控制的Block生成。带有布局控制的潜在三平面扩散可以准确地确定场景中物体的位置。它还允许生成的形状具有一定的多样性。
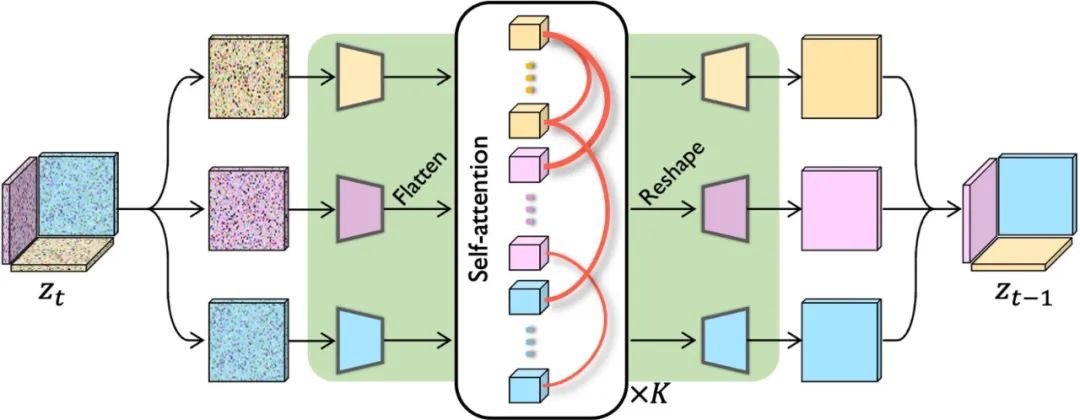
图3. Tri-plane Diffusion的去噪Backbone
使用Tri-plane来表达3D的优势在于我们可以把它们看作是二维张量,因此可以应用高效的二维卷积。然而,在Tri-plane上简单地运行卷积并不能得到满意的结果,因为它忽略了平面特征之间的三维联系。我们利用Self-attention关联三个平面的特征,从而实现具有三维感知能力的去噪Backbone。

场景扩展
潜在三平面外推(Latent Tri-plane Extrapolation)
Repaint [2] 使用预训练的扩散模型展示了令人印象深刻的图像补全和外推结果。它的关键思想是使用已知像素的噪声版本来同步未知像素的去噪过程。受到Repaint的启发,我们利用预训练去噪Backbone来外推Tri-plane。形式上,给定已知的块P和未知的块Q。二者有部分重叠。目标是生成可以表示新块Q的潜在Tri-plane。我们使用P的潜在Tri-plane作为condtion,来推断与P部分重叠的Q的潜在Tri-plane。如图4所示,我们将Tri-plane外推分解为三个独立的2D平面外推任务,然后利用具有三维感知能力的去噪Backbone(见图3)来同步这些平面的信息。
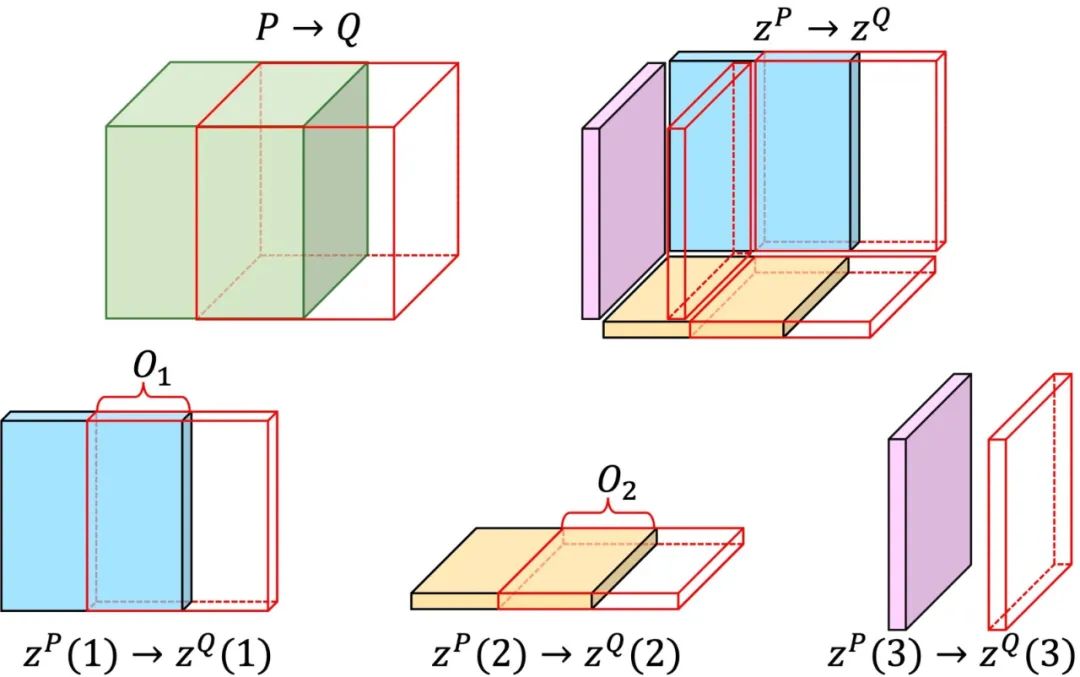
图4. 潜在三平面外推(Latent Tri-plane Extrapolation)
图5. 三平面外推的迭代过程
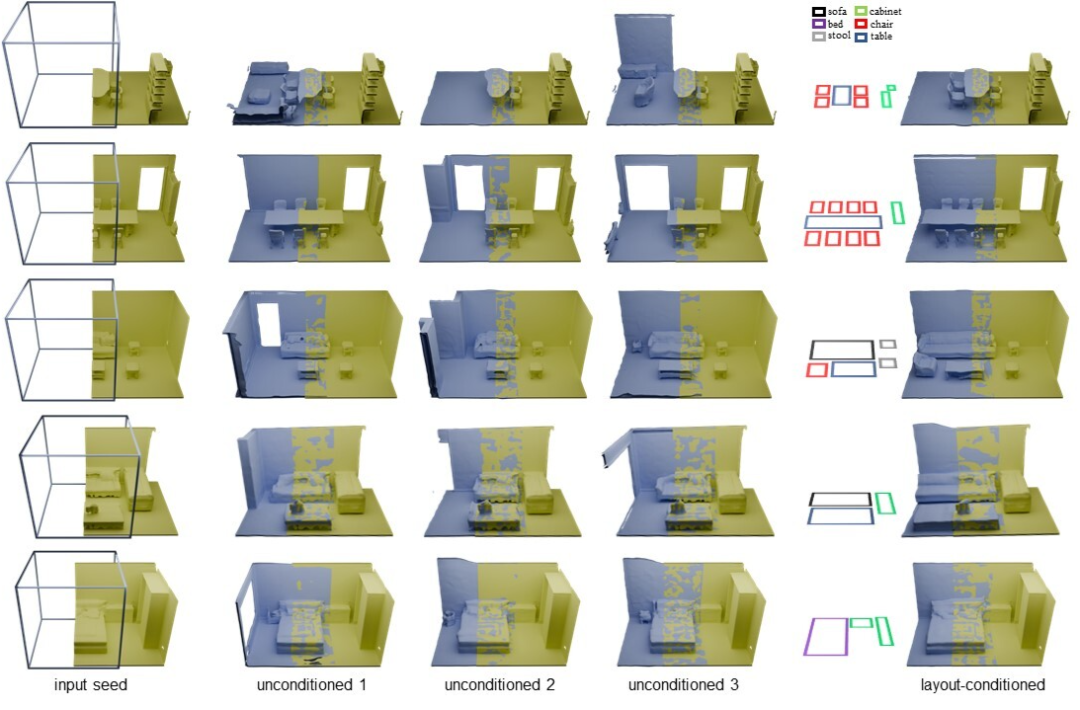
图6. 三平面外推的定性结果。3D框显示了要外推的块的位置。中间三列展示了三种随机外推的结果,最右边列展示了受布局控制的外推结果。对于顶部三行,重叠比例为25%,对于底部三行,重叠比例为50%

大场景生成结果
利用三平面外推,我们可以构建任意规模的大型、无边界的场景。为此目的的简单策略最初是创建一个块,然后通过以滑动窗口方式逐块外推来扩展场景。图7展示滑动窗口生成的一个例子。图8展示了和现有方法Text2Room[3]的对比结果。
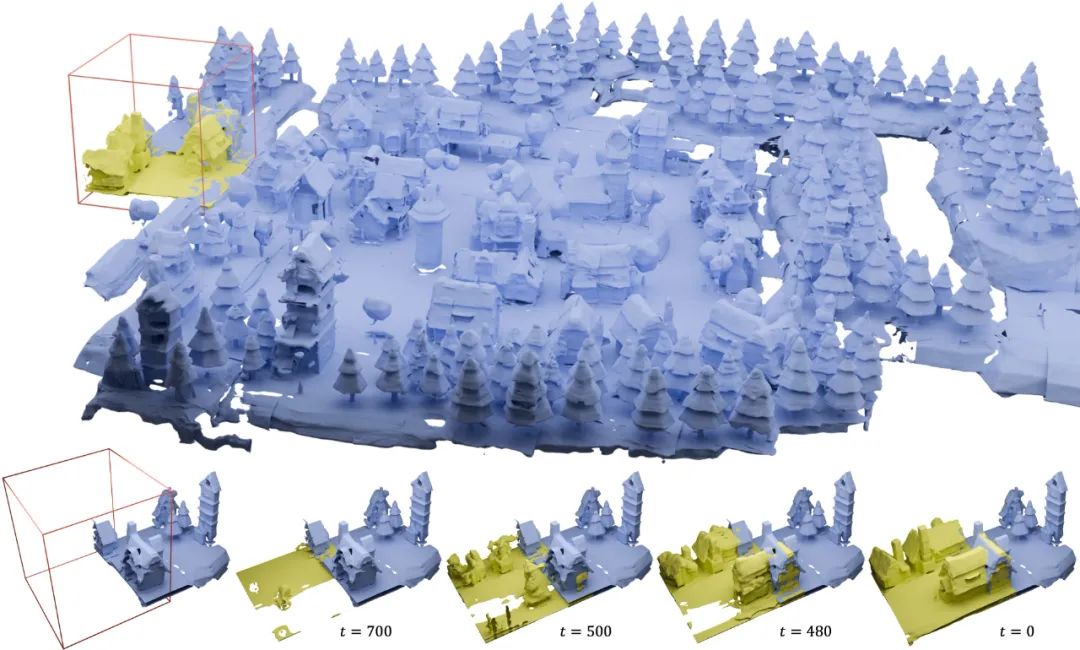
图7.利用滑动窗口生成一个大的村庄场景
图8.与现有方法TextRoom对比房间生成的定性结果。Text2Room 生成了扭曲的形状,无法准确响应场景中的物体数量。例如,当给出提示“一张床”时,它会生成多张床。相比之下,BlockFusion生成了更高质量的形状,并正确响应了数量Prompt
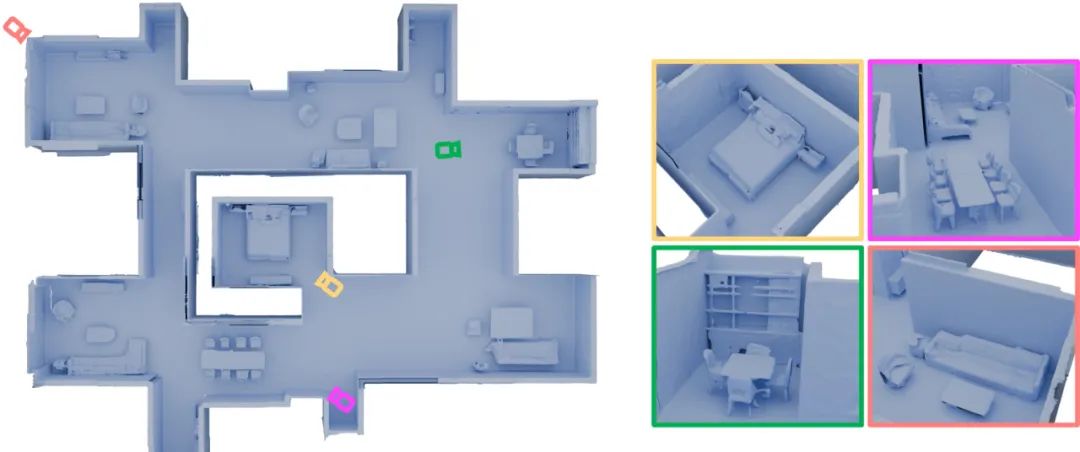
图9.大房间生成结果
附参考文献:
1. Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, and Björn Ommer. 2022a. High-resolution image synthesis with latent diffusion models. In Proceedings of the IEEE/CVF conference on computer vision and pattern recognition. 10684–10695.
2.Andreas Lugmayr, Martin Danelljan, Andres Romero, Fisher Yu, Radu Timofte, and Luc Van Gool. 2022. Repaint: Inpainting using denoising diffusion probabilistic models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition. 11461–11471.
3.Lukas Höllein, Ang Cao, Andrew Owens, Justin Johnson, and Matthias Nießner. 2023. Text2room: Extracting textured 3d meshes from 2d text-to-image models. arXiv preprint arXiv:2303.11989 (2023).
请给项目 一个 Star !
欢迎提出你的 issue 和 PR!
关注腾讯开源公众号
获取更多最新腾讯官方开源信息!
















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









