








既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
用户画像又称用户角色,作为一种描述目标用户,联系用户诉求与设计方向的有效工具,用户画像在各领域得到了广泛的应用。
我们在实际操作的过程中往往会以最为浅显和贴近生活的话语将用户的属性、行为与期待的数据转化联结起来,就是给用户打标签,取各种别名。作为实际用户的虚拟代表,用户画像所形成的用户角色并不是脱离产品和市场之外所构建出来的。
大数据杀熟
对大数据来说这是一个不好的概念,就是对不同消费水平的人,给出不同的商品价格,往往消费水平高的人,对应商品的标价也可能越高。
不同消费者对价格敏感度不同,支付意愿有差异,相比起统一定价,差异化的定价行为更能提高商家利润。因此互联网入口出现垄断,杀熟便会成为一种“自然反应”。
大数据杀熟本身就是利用各种消费数据,把消费数据形成标签,这种杀熟做法非常糟糕。其实在我们交易过程里面很容易识别,但在网络商品交易里面可能比较难识别,而且会破坏交易的公平性,破坏了社会的公平。
即席查询
即席查询(Ad Hoc)是用户根据自己的需求,灵活的选择查询条件,系统能够根据用户的选择生成相应的统计报表。
即席查询与普通应用查询最大的不同是普通的应用查询是定制开发的,而即席查询是由用户自定义查询条件的。
数据湖
数据湖(Data Lake)是一个存储企业的各种各样原始数据的大型仓库,其中的数据可供存取、处理、分析及传输。
hudi 目前,Hadoop是最常用的部署数据湖的技术,所以很多人会觉得数据湖就是Hadoop集群。数据湖是一个概念,而Hadoop是用于实现这个概念的技术。
数据湖能处理所有类型的数据,如结构化数据,非结构化数据,半结构化数据等,数据的类型依赖于数据源系统的原始数据格式。非结构化数据(语音、图片、视频等) 根据海量的数据,挖掘出规律,反应给运营部门。拥有非常强的计算能力用于处理数据。
而不同与数据仓库的是:
数据仓库主要处理历史的、结构化的数据,而且这些数据必须与数据仓库事先定义的模型符合。数据仓库分析的指标都是产品经理提前规定好的。按需分析数据。(日活、新增、留存、转化率等等)。
数据中台
数据中台是对信息化系统业务与数据的沉淀,是实现数据赋能新业务、新应用的中间、支撑性平台,就是为上游应用提供数据支持的平台。
在数据开发中,核心数据模型的变化是相对缓慢的,同时,对数据进行维护的工作量也非常大;但业务创新的速度、对数据提出的需求的变化,是非常快速的。
数据中台的出现,就是为了弥补数据开发和应用开发之间,由于开发速度不匹配,出现的响应力跟不上的问题。
数据集市
数据集市(Data Mart),也叫数据市场,数据集市就是满足特定的部门或者用户的需求,按照多维的方式进行存储,包括定义维度、需要计算的指标、维度的层次等,生成面向决策分析需求的数据立方体。
数据集市就是企业级数据仓库的一个子集,它主要面向部门级业务,并且只面向某个特定的主题。为了解决灵活性与性能之间的矛盾,数据集市就是数据仓库体系结构中增加的一种小型的部门或工作组级别的数据仓库。数据集市存储为特定用户预先计算好的数据,从而满足用户对性能的需求。数据集市可以在一定程度上缓解访问数据仓库的瓶颈。
ETL
ETL代表提取(Extract )、转换(Transform )、加载(Load)。它指的是这一个过程:「提取」原始数据,通过清洗/丰富的手段,把数据「转换」为「适合使用」的形式,并且将其「加载」到合适的库中供系统使用。即使 ETL 源自数据仓库,但是这个过程在获取数据的时候也在被使用,例如,在大数据系统中从外部源获得数据。
雪花模型、星型模型、星座模型
星型模型:是一种多维的数据关系,它由一个事实表(Fact Table)和一组维表(Dimension Table)组成。每个维表都有一个维作为主键,所有这些维的主键组合成事实表的主键。

雪花型模型:当有一个或多个维表没有直接连接到事实表上,而是通过其他维表连接到事实表上时,其图解就像多个雪花连接在一起,故称雪花模型。
雪花模型是对星型模型的扩展。它对星型模型的维表进一步层次化,原有的各维表可能被扩展为小的事实表,形成一些局部的 "层次 " 区域,这些被分解的表都连接到主维度表而不是事实表。
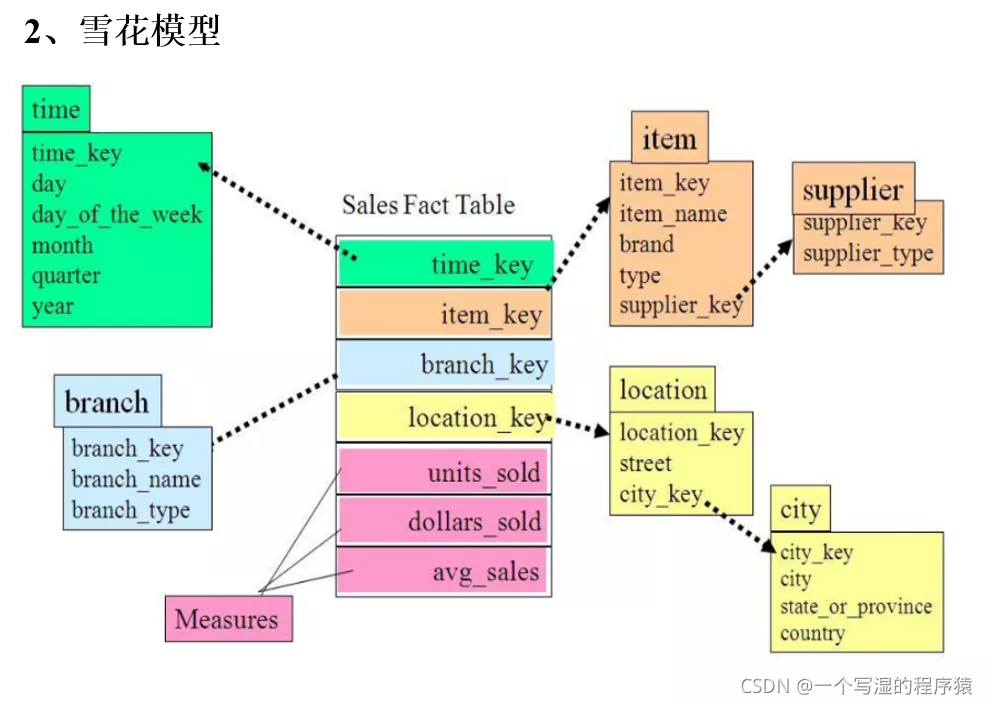
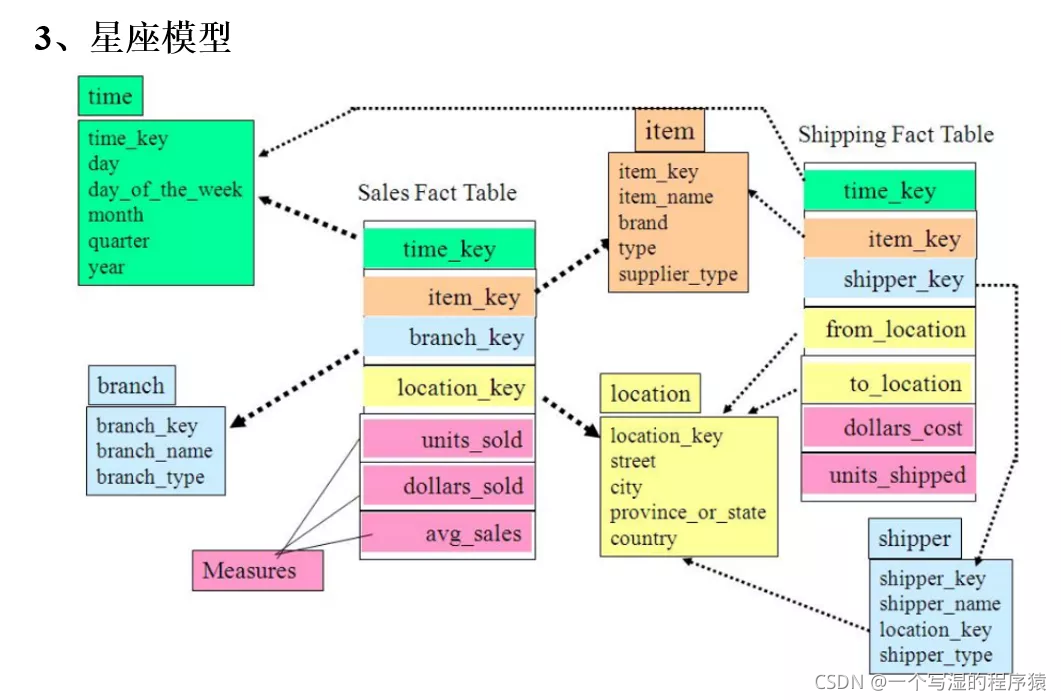
星座模型:由多个事实表组合,维表是公共的,可以被多个事实表共享。
事实表
事实表(Fact Table)中的每行数据代表一个业务事件。“事实”这个术语表示的是业务事件的度量值,例如,订单事件中的下单金额。
(1)事务性事实表:以每个事务或事件为单位,例如一个销售订单记录,一笔支付记录等,作为事实表里的一行数据。
(2)周期性快照事实表:周期性快照事实表中不会保留所有数据,只保留固定时间间隔的数据,例如每天或者每月的销售额,或每月的账户余额等。
(3)累积性快照事实表:累计快照事实表用于跟踪业务事实的变化。例如,数据仓库中可能需要累积或者存储订单从下订单开始,到订单商品被打包、运输、和签收的各个业务阶段的时间点数据来跟踪订单声明周期的进展情况。当这个业务过程进行时,事实表的记录也要不断跟新。
维度表
维度表(Dimension Table)或维表,有时也称查找表(Lookup Table),是与事实表相对应的一种表;它保存了维度的属性值,可以跟事实表做关联;
相当于将事实表上经常重复出现的属性抽取、规范出来用一张表进行管理。常见的维度表有:日期表(存储与日期对应的周、月、季度等的属性)、地点表(包含国家、省/州、城市等属性)等。维度是维度建模的基础和灵魂,
使用维度表有诸多好处,具体如下:
(1)缩小了事实表的大小。
(2)便于维度的管理和维护,增加、删除和修改维度的属性,不必对事实表的大量记录进行改动。
(3)维度表可以为多个事实表重用,以减少重复工作。
上钻与下钻
上钻:自下而上,从当前数据回归到上层数据,细粒度-->粗粒度。
下钻:自上而下, 从当前数据继续向下获取下层数据,粗粒度<--细粒度。
钻取是在数据分析中不可缺少的功能之一,通过改变展现数据维度的层次、变换分析的粒度从而关注数据中更详尽的信息。它包括向上钻取( roll up )和向下钻取( drill down )。
上钻是沿着维度的层次向上聚集汇总数据,下钻是在分析时加深维度,对数据进行层层深入的查看。通过逐层下钻,数据更加一目了然,更能充分挖掘数据背后的价值,及时做出更加正确的决策。
维度退化
维度退化的维度表可以被剔除,从而简化维度数据仓库的模式。因为简单的模式比复杂的更容易理解,也有更好的查询性能。
当一个维度没有数据仓库需要的任何数据时就可以退化此维度。需要把维度退化的相关数据迁移到事实表中,然后删除退化的维度。
维度属性也可以存储到事实表中,这种存储到事实表中的维度列被称为“维度退化”。与其他存储在维表中的维度一样 , 维度退化也可以用来进行事实表的过滤查询、实现聚合操作等。
UV与PV
PV(访问量):即Page View, 具体是指网站的是页面浏览量或者点击量;
UV(独立访客):即Unique Visitor,访问网站的一台电脑客户端为一个访客。根据IP地址来区分访客数,在一段时间内重复访问,也算是一个UV;
UV价值=销售额/访客数。意思是每位访客带来多少销售额;UV价值越大,产品越迎合消费者需求,只有一定的推广投入才会带来相对应的UV;

既有适合小白学习的零基础资料,也有适合3年以上经验的小伙伴深入学习提升的进阶课程,涵盖了95%以上大数据知识点,真正体系化!
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新
5%以上大数据知识点,真正体系化!**
由于文件比较多,这里只是将部分目录截图出来,全套包含大厂面经、学习笔记、源码讲义、实战项目、大纲路线、讲解视频,并且后续会持续更新


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









