







这是我在b站看到的一条关于word2vec 代码实战的视频的笔记~
b站链接在这Word2Vec的PyTorch实现_哔哩哔哩_bilibili
下面是我自己写的一个简单的语料库,大家可以自己加上一些句子,或者自己写一个简单的语料库
sentences = [
"i am a student ",
"i am a boy ",
"studying is not a easy work ",
"japanese are bad guys ",
"we need peace ",
"computer version is increasingly popular ",
"the word will get better and better "
]我们需要对原始语料库的句子进行分割,得到一个个单词
sentence_list = "".join(sentences).split() # 语料库---有重复单词这样我们就得到了分割后的单词语料库,但是需要注意的是,这样的得到的列表含有很多重复的单词,因此我们需要用集合set进行去重处理
vocab = list(set(sentence_list)) # 词汇表---没有重复单词我们将去重的单词库命名为词汇表vocab,我们还需要单词和索引的对应关系,所以我们定义一个字典变量word2idx
word2idx = {w: i for i, w in enumerate(vocab)} # 词汇表生成的字典,包含了单词和索引的键值对我们定义一个列表变量将中心词和上下文的索引都保存进去
skip_grams = []
for word_idx in range(w_size, len(sentence_list)-w_size): # word_idx---是原语料库中的词索引
center_word_vocab_idx = word2idx[sentence_list[word_idx]] # 中心词在词汇表里的索引
context_word_idx = list(range(word_idx-w_size, word_idx)) + list(range(word_idx+1, word_idx+w_size+1)) # 上下文词在语料库里的索引
context_word_vocab_idx = [word2idx[sentence_list[i]] for i in context_word_idx] # 上下文词在词汇表里的索引
for idx in context_word_vocab_idx:
skip_grams.append([center_word_vocab_idx, idx]) # 加入进来的都是索引值w_size是上下文的窗口大小
好了,中心词和上下文的索引都有了,接下来就是取出对应的单词作为输入了
def make_data(skip_grams):
input_data = []
output_data = []
for center, context in skip_grams:
input_data.append(np.eye(vocab_size)[center])
output_data.append(context)
return input_data, output_data个人认为这里的”输入“”输出“没有实际意义,只是因为我们要做的是skip_gram,根据中心词预测上下文
加载数据
input_data, output_data = make_data(skip_grams)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)建立模型
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
self.W = nn.Parameter(torch.randn(vocab_size, w_size).type(dtype))
self.V = nn.Parameter(torch.randn(w_size, vocab_size).type(dtype))
def forward(self, X):
hidden = torch.mm(X, self.W)
output = torch.mm(hidden, self.V)
return output开始训练
model = Word2Vec().to(device)
loss_fn = nn.CrossEntropyLoss().to(device)
optim = optimizer.Adam(model.parameters(), lr=1e-3)
for epoch in range(2000):
for i, (batch_x, batch_y) in enumerate(loader):
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print(epoch + 1, i, loss.item())
optim.zero_grad()
loss.backward()
optim.step()
以下是全部代码
import matplotlib.pyplot as plt
import torch
import numpy as np
import torch.nn as nn
import torch.optim as optimizer
import torch.utils.data as Data
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
dtype = torch.FloatTensor
sentences = [
"i am a student ",
"i am a boy ",
"studying is not a easy work ",
"japanese are bad guys ",
"we need peace ",
"computer version is increasingly popular ",
"the word will get better and better "
]
sentence_list = "".join(sentences).split() # 语料库---有重复单词
vocab = list(set(sentence_list)) # 词汇表---没有重复单词
word2idx = {w: i for i, w in enumerate(vocab)} # 词汇表生成的字典,包含了单词和索引的键值对
vocab_size = len(vocab)
w_size = 2 # 上下文单词窗口大小
batch_size = 8
word_dim = 2 # 词向量维度
skip_grams = []
for word_idx in range(w_size, len(sentence_list)-w_size): # word_idx---是原语料库中的词索引
center_word_vocab_idx = word2idx[sentence_list[word_idx]] # 中心词在词汇表里的索引
context_word_idx = list(range(word_idx-w_size, word_idx)) + list(range(word_idx+1, word_idx+w_size+1)) # 上下文词在语料库里的索引
context_word_vocab_idx = [word2idx[sentence_list[i]] for i in context_word_idx] # 上下文词在词汇表里的索引
for idx in context_word_vocab_idx:
skip_grams.append([center_word_vocab_idx, idx]) # 加入进来的都是索引值
def make_data(skip_grams):
input_data = []
output_data = []
for center, context in skip_grams:
input_data.append(np.eye(vocab_size)[center])
output_data.append(context)
return input_data, output_data
input_data, output_data = make_data(skip_grams)
input_data, output_data = torch.Tensor(input_data), torch.LongTensor(output_data)
dataset = Data.TensorDataset(input_data, output_data)
loader = Data.DataLoader(dataset=dataset, batch_size=batch_size, shuffle=True)
class Word2Vec(nn.Module):
def __init__(self):
super(Word2Vec, self).__init__()
self.W = nn.Parameter(torch.randn(vocab_size, w_size).type(dtype))
self.V = nn.Parameter(torch.randn(w_size, vocab_size).type(dtype))
def forward(self, X):
hidden = torch.mm(X, self.W)
output = torch.mm(hidden, self.V)
return output
model = Word2Vec().to(device)
loss_fn = nn.CrossEntropyLoss().to(device)
optim = optimizer.Adam(model.parameters(), lr=1e-3)
for epoch in range(2000):
for i, (batch_x, batch_y) in enumerate(loader):
batch_x = batch_x.to(device)
batch_y = batch_y.to(device)
pred = model(batch_x)
loss = loss_fn(pred, batch_y)
if (epoch + 1) % 1000 == 0:
print(epoch + 1, i, loss.item())
optim.zero_grad()
loss.backward()
optim.step()
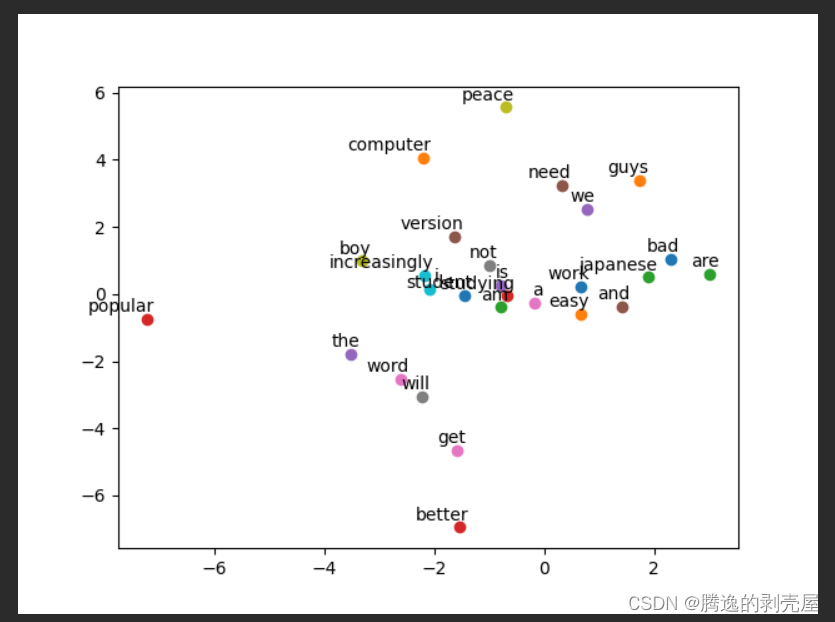
for i, label in enumerate(vocab):
W, WT = model.parameters()
x, y = float(W[i][0]), float(W[i][1])
plt.scatter(x, y)
plt.annotate(label, xy=(x, y), xytext=(5, 2), textcoords='offset points', ha='right', va='bottom')
plt.show()效果图
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









