






一种用于装配序列生成和爆炸图生成的混合共轭方法
摘要
本文旨在开发一种高效的混合方法,以有效协同解决装配序列生成(ASG)和爆炸图生成(EVG)问题。装配序列生成是指根据装配设计,确定机械产品各组成部件可行的无碰撞运动过程。尽管ASG的执行在计算上复杂且耗时,但对于高效制造过程而言至关重要。由于现有ASG算法存在诸多局限性,目前计算机辅助设计(CAD)软件中仍缺乏明确的方法,因此产品的爆炸图往往无法与任何可行的拆卸序列(拆卸序列是装配序列的逆过程)相对应。当前CAD软件中的EVG算法仅将产品的所有组成部件在整个屏幕上进行可视化展示,而未考虑装配操作的可行顺序。因此,有必要制定一种能够有效联合求解ASG与EVG问题的算法。该需求也已被记录在美国专利商标局(2005年)发布的“专利信息通则:1.84 图纸标准”中,其中指出为任何产品所创建的爆炸图应显示各零件之间允许的装配关系或装配顺序。
设计/方法/途径
本文提出了一种独特的ASG方法,并进一步将其扩展至EVG。该ASG采用确定性方法,以避免冗余数据收集和计算。所提出的方法已有效应用于那些需要非规范方向拆卸可行路径的产品。
研究发现
该方法能够将装配操作组织为线性或并行的装配进程,从而使装配任务在最少阶段数内完成。该结果进一步应用于EVG,被证明是有效的。
原创性/价值
装配序列规划(ASP)大多数情况下仅考虑沿规范轴的几何可行性,而未考虑装配操作的并行可能性。本文提出的方法能够稳健地解决这一问题。考虑可行装配序列规划的爆炸图生成也是本文展示的新颖的方法之一。
关键词 自动装配, 装配序列计划, 装配, 爆炸图, 几何可行性, 装配序列生成, 爆炸图生成, Assembly automation
论文类型 研究型论文
1. 引言
制造业中日益增强的自动化趋势与日俱增,以实现高生产率。设计工程师广泛使用多种面向设计的软件包来开发产品设计。在完整产品开发完成后,人们能够通过使用爆炸图来确定零件在装配中的位置。然而,装配部件在屏幕上的随机分布导致无法实现预期目标。
据作者所知,目前尚无商用设计软件包具备将爆炸图作为可行的装配/拆卸序列的功能。该要求已被记录为美国专利商标局(2005年)发布的“专利信息通则:1.84 图纸标准”中的一项标准。其中指出,为任何产品创建的爆炸图应显示各装配部件之间允许的顺序或关系。因此,有必要开发一种高效算法,以解决任意产品构型的爆炸视图生成(EVG)问题。
装配序列生成(ASG)方法解决了这类问题,即通过适当的优先顺序有效地找到装配单个零件的可行方法。由于只需进行一些有效假设即可通过逆序获得拆卸序列计划,因此ASG具有很强的灵活性。在过去的四十年中,研究人员更加关注具有多种目标的ASG算法,但随着零件数量的每次增加,解空间和搜索空间的复杂性呈指数级增长,导致计算成本高昂(Bahubalendruni 和 Biswal,2016)。尽管许多研究人员致力于采用基于人工智能(AI)的ASG方法以避免计算复杂性,但现有解决方案仍局限于仅沿主轴方向拆卸/装配零件,从而降低了方案的最优性。因此,由于问题建模和计算实现的复杂性,目前市场上尚无能够与计算机辅助设计(CAD)软件集成的、包含ASG和EVG模块的完整解决方案。
由于产品的特定设计特性,开发一种适用于所有产品构型并获得满意解的通用方法非常复杂。该复杂性始于算法的开发,需要能够捕捉、存储并进一步评估每种产品所有必要的装配属性(源自产品结构)。
本文提出了一种名为“基于包络的可行性检测(EBFD)”的有效方法,用于联合解决ASG和EVG问题,以克服现有局限性,并在可接受的装配部件优先顺序下实现装配。以下各节将介绍相关文献,以阐明该方法的背景和思想基础。
2. 文献综述
爆炸图在产品的开发阶段至关重要,并在其整个生命周期中具有重要作用(Cook等,2006)。尽管爆炸图具有重要意义,但该领域开展研究的学者较少。传统上,产品零件和子装配体以计算机辅助模型表示,并通过手动模拟拆卸过程来生成爆炸图(Ko 和 Lee,1987;Sudhakar 和 Faruqi,1988;Shpitalni等,1989)。大多数拆卸/装配序列规划(ASP)方法均采用图形格式来表示产品信息。类似地, Mohammad 和 Kroll 生成了基于表面匹配的 ABOVE 有向图。有向图表示轴与表面之间的接触关系,随后该有向图可被转换为线性有向图来表示产品的爆炸图(Mohammad 和 Kroll, 1993)。一些研究者提出了通过基于组件之间的关系及其配合条件的层次树结构来表示装配体的概念,以建立优先关系 (Wesley等,1980;Popplestone等,1980;Lee 和 Gossard,1985)。大多数 EVG 技术由于其迭代特性,需要熟练用户的干预来建立优先关系,且计算耗时。
考虑到基于 ASG 的方法来解决上述问题,Bourjault 提出了用配合关系来表示零件之间的装配连接。通过人工回答与几何可行性相关的问题,确定了各个装配部件的优先顺序 (Bourjault,1984)。随后开发了一款计算机程序,通过修改 Bourjault 提出的问题,输入装配部件之间的接触关系,从而生成优先关系(De Fazio 和 Whitney,1987)。即使是经验丰富的工程师,由于需要掌握大量关于产品的知识,在回答这些问题时也面临不小的挑战。仅依靠配合关系不足以解决问题,必须识别几何可行性,以确定装配部件爆炸展开的顺序。Hoffman(1989) 提出了一种方法,基于零件对之间的配合条件识别拆卸零件的无碰撞路径,但该方法仅适用于以构造实体几何表示的产品模型。Haynes 和 Morris (1988)提出了一种理论,将产品的描述与其装配序列相关联,依据是组件之间的自由度。图形化表示的复杂性促使研究人员采用数组形式来表达几何可行性数据(Mok等,2001)。
Tseng 提出了一种基于连接件的 ASG 技术,其中零件集合根据连接它们的特定连接件创建,优先关系则根据当前装配环境中零件的可用性来确定(Tseng 和 Li,1999)。然而,如果产品中使用的连接件数量多于零件数量,通过该技术求解 ASG 将非常耗时,且连接类型的数量有限。此外,该方法未明确给出装配方向的可行性判据。随后,该方法结合遗传算法(GA)以寻找优化装配序列(Tseng等,2004)。
为克服上述局限性,研究人员开发了自动化方法,以从产品主轴方向直接提取配合关系和几何可行性数据。Li通过应用几何干涉规则在正交方向上生成局部爆炸视图;然而,确定接触、碰撞和关联关系会消耗更多的计算时间,从而增加了求解包含50多个零件的装配体的复杂性。(Li等人, 2008)。少数其他系统能够根据给定的装配序列生成爆炸图 (Motomasa,2005; Pan等人,2005)。
Huang 提出了一种基于知识库的 ASP 方法,旨在通过图搜索机制为产品获取可行的装配顺序。由于计算时间巨大,该方法无法用于零件数量多的产品(Huang 和 Lee,1991)。
综合考虑装配中的几何和非几何知识
装配序列生成
M.V.A. Raju Bahubalendruni 等人
装配自动化
在通过ASG解决EVG问题时,人们发现大多数研究兴趣集中在基于人工智能的方法上,以针对不同产品构型寻找最优的可行装配序列。迪尼应用遗传算法,在考虑最少夹具更换作为优化参数的同时,通过对相似装配操作进行排序,来寻找最优装配序列(Dini et al., 1999)。史密斯提出了一种两级基于遗传算法的技术用于装配序列生成,以最小化可行装配序列中的方向变化——该序列在第一级生成,然后在下一级通过引入期望参数进一步优化。使用三个遗传算子显著减少了计算时间(史密斯和史密斯,2002)。王提出了蚁群优化在选择性拆卸概念中的应用,以从产品寿命终止阶段的产品中获得选定部件的最优拆卸序列方案(王等人,2003)。
利用基于知识的数据库,已实施神经网络算法用于装配序列生成建模,通过将装配部件所需的能量作为装配序列生成的适应度函数,从而减少大型产品的计算时间(Sinano glu 和 Rıza Börklü,2005)。巴胡巴拉恩德鲁尼采用了先进的基于免疫的策略来达到最优装配序列(巴胡巴拉恩德鲁尼和比斯瓦尔,2018)。研究人员尝试混合不同的AI技术,以提高性能,即在更短的时间内获得全局最优解(单等人,2009)。
一些研究人员在对装配序列生成建模时研究了装配谓词考虑的影响,并证明了其在不同情况下对计算时间和所得解的质量的影响(巴胡巴拉恩德鲁尼等人,2015)。还证实了机械可行性概念可进一步简化计算,尤其是在产品中使用的连接件数量较多时(巴胡巴拉恩德鲁尼和比斯瓦尔,2016)。
以下陈述是通过识别引用文献中的研究空白而汇总得出的:
- 在开发阶段,尚无明确的方法来表示设计产品的EVG。ASG方法可通过提供合适的几何可行性,避免工作界面上装配部件的重叠,从而解决此类问题。 EVG需要在较少的计算次数内以更快的速度获得可行解。传统方法、基于知识的方法、人工智能是ASG中流行的现有方法。现有方法能够在较可观的计算时间内产生可能的解,而人工智能方法虽然能够生成解,但其可行性无法保证。
- 随机解生成及其适用性测试消耗了大部分计算时间,即使通过仅分析装配零件之间的接触(不包括连接件)来生成解决方案。
- 几何可行性范围也仅限于主轴。
- 当前方法致力于开发一种混合ASG‐EVG方法,以解决上述限制。
3. 问题定义和产品数据提取
3.1 问题定义
旨在开发一种能够以高效方式联合处理EVG和ASG的方法,通过消耗最少的计算时间和计算机内存来提供可靠的解决方案。
3.2 决策变量
通过拆卸完整装配体所需操作的可行性来解释生成解决方案的适用性。两个变量,即配合关系和几何可行性,可以决定解决方案的适用性和质量。
随着零件数量的增加,分析接触情况以及在不发生碰撞的情况下移动零件的可行性变得更为复杂。将零件和连接件分别处理可以改善这一状况,并确保其可行性。早期的几何可行性方法需要在所有正负主轴方向上建立干涉矩阵,导致内存消耗较大。为避免这些问题,本文提出了一种新颖的概念EBFD。以下各节将介绍实现可行解所需的数据提取技术。
3.3 产品数据提取
装配产品信息(如接触和连接)可以以图形化或矩阵格式表示。但由于其在计算中的灵活性和兼容性,大多数研究人员认为矩阵(数组)格式更易于进行信息提取和表示(fiLiet al., 2002;Linn and Liu, 1999)。关联矩阵使用“1”和 “0”来表示装配部件之间的接触/无接触关系。如果两个零件在产品结构中存在物理表面接触,则称它们之间具有配合关系。为了满足装配要求,在构建关联矩阵时必须忽略点接触和线接触。
3.3.1 联络数据
联络数据可以通过观察产品结构手动收集。如果希望避免人为干预,仅需使用产品的CAD模型,通过接触分析来开发无错误的关联矩阵。基于CAD模型中装配部件之间的冲突值,可将三个主要特征进行分类,在关联矩阵开发过程中应从产品的装配文件中考虑这些特征,即干涉、接触和间隙。
干涉 :如果装配模型中的任意一对零件存在相互穿透,则其冲突值显示为小于零。任何装配部件之间都不应出现此类情况,因为此类产品在实际中是无效的,应通过设计中的推荐更改来解决这些问题。
接触 :如果一对部件的冲突值等于零,则称这些零件彼此处于物理接触状态。
间隙 :如果冲突值为正值,则装配模型中的这对部件在零件对之间不保持接触。
Liaison Pi; Pj ð Þ ¼ f1 if surface contact exists between part i to part j* i;j 2 1; n ½ ; i 6¼j f0 if no contant/clearance/point=line contact between part i to part j
表I 列出了名为transmission assembly的工业产品的CAD模型的关联矩阵,该模型如图1所示。
零件名称按相同顺序排列成行和列,以创建一个二维数组结构。因此,创建了一个包含总共 n × n 个元素的空数组,其中每对零件的连接状态基于从接触分析获得的冲突值确定。
联络数据仅针对传动总成的主要零件(用于连接它们的连接件除外)进行收集。随着零件数量的增加,解空间呈指数级增长,为了控制这种急剧扩张,大多数研究在ASG中忽略了连接件。然而,在本研究中,连接件也被考虑在内,相关信息存储在一个不同的数组中,将在下一节中详细说明。

表I 传动总成的配合关系数据
| A | B | C | D | E | F | G | H | J | K | L | |
|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 |
| B | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 |
| C | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| D | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 |
| E | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 |
| F | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 |
| G | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| H | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 |
| J | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 |
| K | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 |
| L | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 |
3.3.2 基于包络的几何可行性数据提取
几何可行性(GF)定义了在其他已存在零件存在的情况下,已装配零件进行拆卸或单个零件进行装配时,在适当的无碰撞方向上的可行性。在此情况下,几何可行性(GF)仅限于拆卸,以生成爆炸图。零件安装/拆卸的几何可行性分为两种类型(直线路径;非直线路径)。
在直线路径中,进一步将GF细分为(沿主轴方向;相对于主轴的斜向)现有GF方法在确定可能的拆卸方向时存在以下局限性。用于表示可行性的数据通常采用矩阵或图形格式,每种主轴方向(1X, ±X, 1Y, ±Y, 1Z, ±Z)都需要单独的矩阵或图形。为装配中的每个对象构建定向轴对齐包围盒或几何可达性锥以获取精确方向,但相应的数据提取和干涉检查分析需要较大的计算量(Yu etal., 2014)。
在考虑上述限制因素的基础上,本文提出了一种新颖的 EBFD提取技术,以通过避免冗余信息来提取实施DSG(拆卸序列生成)所需的数据。
提出的GF测试概念不仅限于主轴,还适用于倾斜方向。
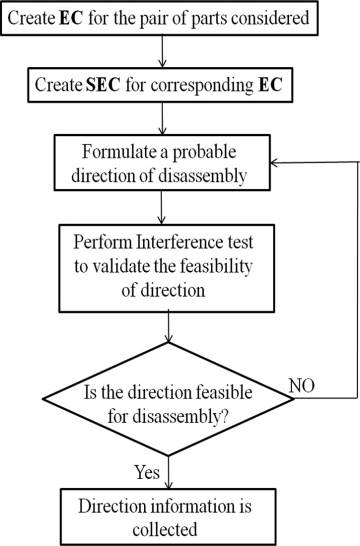
在构建EBFD矩阵之前,列出数据提取所需的规则,以说明提出的方法的工作原理。使用接触包络(EC)来提取装配中零件之间的关系,并在此基础上实施以下规则以进行矩阵构造。
3.3.2.1 接触包络
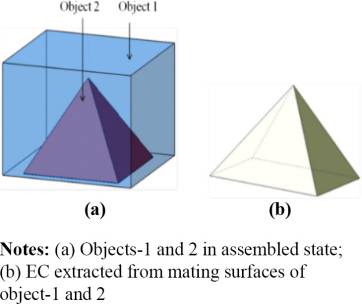
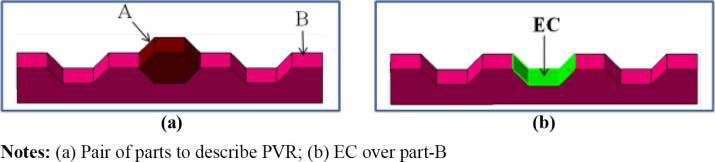
接触包络定义为任意一对刚体之间的配合交界面,这些界面是两个物体(Si, Sj)共有的。两个物体之间的接触如图2(a) 所示,用于说明接触包络,其中接触包络在 图2(b)中显示:
ECk ¼ Si\ S j 8i;j 2 n; n ¼ number of parts in the assembly; k ¼ total number of liaisons:
由于接触包络(EC)是从物体的配合交界面发展而来,因此它具有一对部件之间表面的相同形状特征。因此,接触包络 (EC)可以是一组平面或一个曲面,这完全取决于物体之间的公共配合表面。

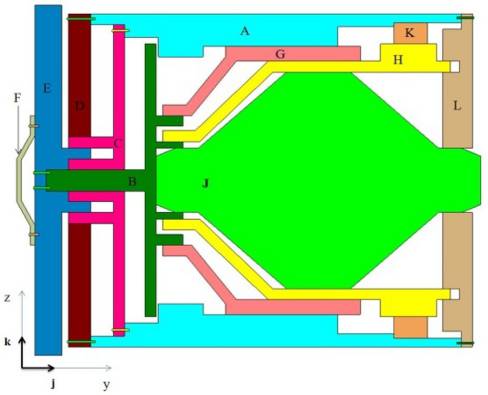
3.3.2.2 规则1:接触包络骨架
命题 :零件的可行域可以从其不可行域的反方向获得。
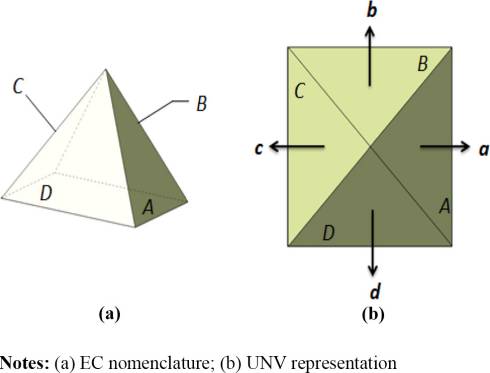
证明 :可以通过接触包络(EC)上的单位法向量(UNV)构建骨架EC(SEC)结构,该结构可表示为(x i 1y j 1 zk)。通过延伸所有构成的SEC
未命名变量图2中使用的对象1和2的SEC,未命名变量表示在 图3(a) 和(b)中。
如果接触包络(EC)是单个平面,则此时的单位法向量 (UNV)为一个。因此,空间排除锥(SEC)可以是平面段或非平面段。大多数开发的计算机辅助设计(CAD)产品将物体转换为多面体,因此仅用平面就足以进行此类零件的可行性测试。
对象2相对于对象1的SEC,如图4所示。创建对象2的 SEC时参考了对象1与对象2的接触包络。在接触包络的每个表面上定义了未命名变量,其方向朝向对象2质量分布的外侧。
由于表面A与表面B和表面D相邻,因此未命名变量“A”” A”的端点连接至未命名变量“B””和“D””的端点。
对象1获得的SEC模型对于对象2同样适用,因为在装配位置视角下,它们的位置会在顶点处横向反转并直接指向彼此。
沿表面的方向无法拆卸,因为其他物体的存在阻碍了其移动路径。但垂直于SEC中任意表面的方向将提供一个可行拆卸方向,这正是
与干涉方向相反,因为接触的两个物体的接触包络相同,只有相应的未命名变量的方向发生反转。
由于接触的两个物体的EC相同,仅对应的UNVs方向相反。沿表面的方向无法拆卸,因为其他物体的存在阻碍了其运动路径。垂直于该平面的方向始终是最优先且最节能的拆卸方向,因为它具有无摩擦运动路径。
3.3.2.3 规则2:半空间规则
命题 :一个不相交的UNV可以在无需检查SEC所提供的整个可行空间的情况下,提供一个可行拆卸方向。
证明 :一个UNV若未与装配中由所考虑的对象对构成 SEC结构的任何其他表面发生干涉,则该UNV成立。
垂直于该平面的方向始终是最优先且最节能的拆卸方向,因为它具有最短的运动路径。
UNVSEC i \ SECj ¼ 0*j 2 n 1
3.3.2.4 规则3:平行视觉规则
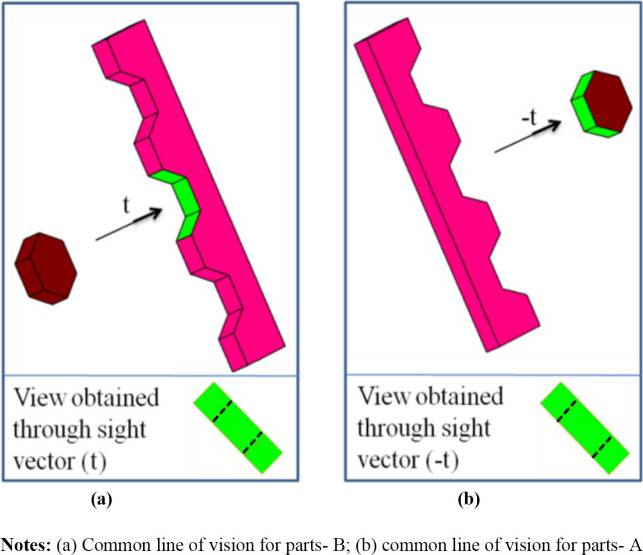
命题 :平行视觉视图是公共视线,在从包围盒外部观察时,EC完全可见且没有任何隐藏元素。因此,公共视线是一个可行的直线方向用于拆卸。
如果出现任何不可避免的情况而无法从所开发的SEC中提供拆卸方向,则可以从并行visionrule获得其他可行方向。
证明 :一对部件在装配状态下被视为不透明体,此时从相反方向的公共视线可以观察到两个物体各自的接触包络。
假设图5(a)和(b)中所示的部件A和部件B在x‐y平面内沿x轴通过配合交界面形成接触包络,因此该接触包络可从A侧x轴正方向以及x轴负方向观察到:x轴的负方向:
EC e S k ; El ð Þ
d i ¼ 1 if S k KEl accessibleP x! P y
0 otherwise Similarly d j p y ! p k ð Þ ¼ d i
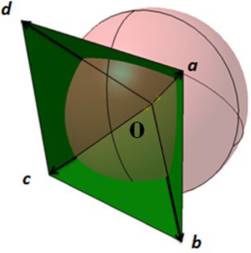
平行视觉视图是指从包围盒外部观察时,接触包络完全可见且没有任何隐藏元素的视图。因此,公共视线是一个可行的直线方向,通过该方向这两个物体可以相互拆卸。
3.3.2.5 数据收集规则的实施
应研究SEC的包络以确定合适的单位向量。第一步是通过使用相应矩阵中的可用联络数据,收集显示连接状态“1”的零件对列表。fi第二步是识别拆卸方向。图7表示拆卸方向识别的流程图。针对所考虑零件的接触包络被提取,并相应地构造空间排除锥(SEC)。
一种可能的
基于PVR和HSR规则,应捕获每一对部件的拆卸方向。首先在产品装配结构中去除所有其他零件的情况下,针对零件沿可获得的拆卸方向进行拆卸,执行干涉测试。如果在直线路径上未发现任何干涉,则表示该对零件通过了指定拆卸方向的干涉测试。若未能通过干涉测试,则根据PVR和HSR规则制定其他可行拆卸方向,并重复后续步骤直至成功。
3.3.2.6 数据存储及其结构
对于每个表现出连接状态的零件对,其可行方向信息“1”被收集并保存在 n×n 数组中。
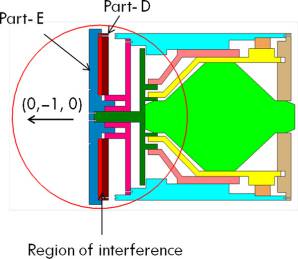
矩阵顶部标明的零件(行)在拆卸过程中运动,而左侧(列)的零件保持静止。图1所示产品的EBFD数据在表II中创建并呈现。图1 中所示产品的EBFD数据在 表II中创建并展示。第 i行和第j列的元素地址表示通过存储的方向坐标从部件i上拆卸部件J。EBFD矩阵中的空单元格代表无连接的部件对,这些部件对所需的数据将在ASG实施过程中进行收集。
最后一行收集了在相应列中出现的方向列表。
表II EBFD Data for transmission assembly
| Movable parts | A | B | C | D | E | F | G | H | J | K | L |
|---|---|---|---|---|---|---|---|---|---|---|---|
| Fixed parts | |||||||||||
| A | (0,−1,0) | (0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0) | (0,−1,0) | ||||||
| B | (0,1,0)(0,−1,0) | 0 | (0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | ||||
| C | (0,1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | |||||||
| D | (0,1,0) | (0,1,0)(0,−1,0) | |||||||||
| E | (0,1,0) | (0,1,0)(0,−1,0) | (0,−1,0) | ||||||||
| F | (0,1,0) | ||||||||||
| G | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | ||||||||
| H | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | 0 | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | |||
| J | (0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | |||||||
| K | (0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | ||||||||
| L | (0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | (0,1,0)(0,−1,0) | |||||
| List of directions | (0,−1,0)(0,−1,0)(0,1,0)(0,−1,0) (0,1,0)(0,−1,0)(0,1,0)(0,−1,0)(0,1,0)(0,−1,0)(0,−1,0)(0,1,0)(0,−1,0)(0,1,0)(0,−1,0)(0,1,0)(0,−1,0)(0,1,0)(0,−1,0)(0,1,0)(0,−1,0) |
3.3.2.7 连接件数据
ASG 中大多数突出的方法由于零件数量增加带来的计算复杂性而未考虑连接件。稳定性和机械可行性准则随后被一些方法用于强调连接件的重要性,但在连接件数量增加时,存储产品信息所需的数据量也随之增加。
本文提出了一种统一结构,以紧凑形式替代上述准则。连接件根据两个准则进行分组。将连接到具有相同拆卸方向的零件集合上的连接件归为单个实体,以便于实现。
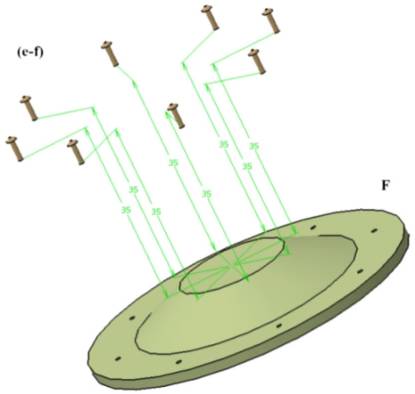
考虑传动总成,它有36个连接件连接到fi五组主要零件,如图8所示。这些连接件组被标识并存储于表III中。该表存储了所有连接关联一对部件的连接件各自的可行拆卸方向。
例如,集合(a‐c)表示附着在零件A和C上的连接件组,且所有该组连接件均可通过GCS的(0, −1, 0)方向进行拆卸。
表III 连接件拆卸方向数据
| 连接件 | 被连接的零件 | 拆卸方向的 | 拆卸设置名称 |
|---|---|---|---|
| C1‐C8 | A, C | (0, −1, 0) | (a‐c) |
| C9‐C16 | A, D | (0, −1, 0) | (a‐d) |
| C17‐C20 | B, E | (0, −1, 0) | (b‐e) |
| C21‐C28 | E, F | (0, −1, 0) | (e‐f) |
| C29‐C36 | A, L | (0, 1, 0) | (a‐l) |
4. 工作原理
早期的ASG算法通过随机生成装配顺序或基于零件对之间的接触(配合关系)来形成装配序列。随后,通过几何可行性验证该方案的适用性。这种随机生成和测试会增加计算时间,以在开发实际可行解时尝试不同的零件对组合。在当前的方法中,引入了两个概念以避免这些问题
计算问题与其宽容性相关。最小L值和S值概念涉及初始解的生成,而序列编辑概念则用于形成可行解。
4.1 连接值(L值)和相对暴露度(S值)
4.1.1 L值
指定零件的连接值定义为“该指定零件与装配中其他已存在零件的所有配合关系之和”。工业传动总成中的部件A与部件 C、D部件、部件G、部件K、部件L存在配合关系;因此,可以说部件A的L值为5。
Lvi ¼ X n j¼1 l Pi; Pj ð Þ 8 l Pi; Pj ð Þ ¼ 1
4.1.2 S值
相对暴露度定义为“其他零件与指定零件形成的全部相关连接关系的总和”,记作S(i)。部件C、D部件、部件G、部件 K和部件L的值分别为4、2、3、2和3,这些值是通过将关联矩阵中对应零件所在列的所有“1”相加得到的。然而,此处的条件是不考虑其他零件与部件A之间未表现出连接关系的那些连接关系。
Sv i ¼ X n j¼1 X n k¼1 l Pj; Pk ð Þ 8 l Pi; Pj ð Þ ¼ 1
4.1.3 初始拆卸序列生成
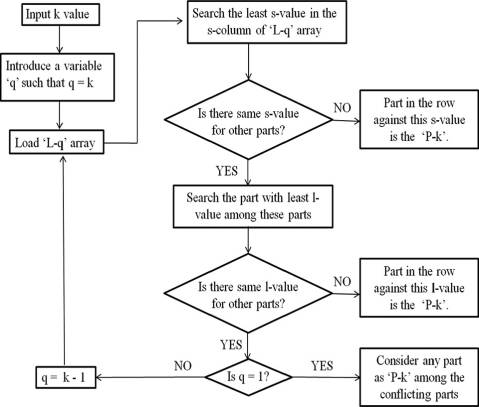
与其他已存在的装配部件具有更多连接关系的零件被称为基体零件。基体零件法表明,由于该零件拆卸时会对其力矩产生影响,从而破坏装配的稳定性,因此基体零件必须在拆卸操作的最后阶段进行拆卸。换句话说,具有最小L值和S值的零件最有可能从零件的装配结构中被轻松移除。通过逐一排列元素形成拆卸序列,并通过移除已拆卸的零件来更新关联矩阵。如果两个装配部件具有相似的S值和L值,则参考上一次更新后的矩阵中的这些数值,并据此制定拆卸序列。
第一级构型(L‐1)中各部件的L值和S值列于表IV。在 L‐1中S值最小为3的部件是部件F。由此推断P‐1为部件F。现在,关联矩阵已更新,移除了与部件F相关的行和列,随后第二级联络数据也进行了更新,并显示在表V中。
部件D和E具有最小的S值9以及相同的L值2。在这种情况下,参考最新更新的矩阵表IV 以确定拆卸序列中部件2的选择。通过参考表IV,选择部件D作为初始拆卸序列(IDS)中的P‐2。类似地,对关联矩阵的所有更高层级进行更新,并依据最小S值和L值规则确定IDS中的后续零件:P‐3为部件E;P‐4为部件C;P‐5为部件K;P‐6为部件A;P‐7为部件L;P‐8为部件G;P‐9为部件J; P‐10为部件B;P‐11为部件H。所得到的
表IV 具有L值和S值的一级配置
| A | B | C | D | E | F | G | H | J | K | L | L值 | S值 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 1 | 1 | 5 | 14 |
| B | 0 | 0 | 1 | 0 | 1 | 0 | 1 | 1 | 1 | 0 | 0 | 5 | 18 |
| C | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 4 | 15 |
| D | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 9 |
| E | 0 | 1 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 3 | 10 |
| F | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 3 |
| G | 1 | 1 | 0 | 0 | |||||||||
| 初始拆卸序列为F‐D‐E‐C‐K‐A‐L‐G‐J‐B‐H。现在将使用序列编辑 概念来验证该初始拆卸序列,如图9 所示,并进一步解释。 |
4.2 序列编辑
序列编辑的概念基于在存在其他零件的情况下,通过特定的 无碰撞方向拆卸装配零件的几何可行性。该理论通过交换相 互干涉的元素位置来处理拆卸顺序。以下将逐步说明所提出 理论的工作过程:
- 条件1 :除非观察到至少任意两个装配部件之间存在干涉, 否则不要编辑初始拆卸序列。
- 条件2 :如果某装配部件在该 列中具有多个拆卸方向,则优先选择更高重复方向,然后是 已存在的装配部件。
- 条件3 :如果在拆卸过程中,初始拆卸 序列中的某个零件与另一个零件发生干涉,则交换测试零件 与被干涉零件的测试顺序。
在拆卸过程中,假设在名为F‐D‐E‐C‐K‐A‐L‐G‐J‐B‐H的初始 拆卸序列中,E部件与D部件发生碰撞,且E部件应在D部件 之前被拆卸。则将两者在初始拆卸序列中的位置互换,得到 F‐E‐D‐C‐K‐A‐L‐G‐J‐B‐H,以优先进行E部件的拆卸操作。
- 条件4 :如果在交换前后,通过其他任意方向进行的干涉测 试合格,则将该方向作为拆卸操作的拆卸方向。
- 条件5 :如 果条件2未能检测到更高重复性的拆卸方向,则选择具有最少 干涉实例数的拆卸方向用于序列编辑。为了更清晰地表示, 图10中列出的一组颜色代码用于区分零件定位:
P ð iÞ() P ðj Þ; P ð iÞ\ P ðj Þ ¼ 0*j 2 j 1 1; n Þ; i 2 1; n 1 ð Þ
序列编辑阶段‐1:
表V L‐2 含“L”和“S”值
| A | B | C | D | E | G | H | J | K | L | L值 | S值 | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| A | 0 | 0 | 1 | 1 | 0 | 1 | 0 | 0 | 1 | 1 | 5 | 14 |
| B | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 1 | 0 | 0 | 5 | 17 |
| C | 1 | 1 | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 4 | 14 |
| D | 1 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 9 |
| E | 0 | 1 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 2 | 9 |
| G | 1 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 3 | 15 |
| H | 0 | 1 | 0 | 0 | 0 | 1 | 0 | 1 | 1 | 1 | 5 | 16 |
| J | 0 | 1 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 1 | 3 | 13 |
| K | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 2 | 10 |
| L | 1 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 3 | 13 |
| 颜色代码 | 图例 |
|---|---|
| 通过干扰测试的部分 | |
| 未通过干扰测试的部分 | |
| 拆卸红色零件时显示干涉的零件 | |
| 剩余需通过干涉测试的零件 |
Input Sequence: F! D! E! C! K! A! L! G! J! B! H.
可以从 图11 中观察到,部件‐F 沿拆卸方向 (0, −1, 0) 移 出产品结构时,与组成部件无任何干涉。部件‐D 在沿拆卸方向坐标 (0, 1, 0) 移动时,与部件‐A、C、B、G、J、H、K和 L 发生干涉;而在沿拆卸方向坐标 (0, −1, 0) 移动时,则与部 件‐E 发生干涉。
因此,D部件采用方向(0, −1, 0),并按如下方式进行序 列编辑。图12 列出了输入序列状态1的修正。
p q g
Output sequence: F! E! D! C! K! A! L! G! J! B! H.
序列编辑状态‐2: q g g
Input Sequence: F! E! D! C! K! A! L! G! J! B! H.
序列编辑从实体位置2开始,对应的部件是E部件。部件‐ E、D和C分别沿(0,−1, 0)方向移动,并从剩余部件的装配结 构中无干涉地移出。部件‐K在沿拆卸方向(0, −1, 0)时与部件‐ A和B发生干涉,而仅在拆卸方向(0, 1, 0)时与部件‐L发生干 涉。因此,考虑(0, 1, 0)方向,序列被修正为如图13所示。
g
Output sequence: F! E! D! C! A! L! K! G! J! B! H.
序列编辑状态‐3: q g g
Input Sequence: F! E! D! C! A! L! K! G! J! B! H.
序列编辑从实体位置5开始。位于实体位置5的部件是部件A。 部件A在沿方向(0, 1, 0)移动时与零件‐L、K、G和H发生干涉, 而在方向(0, ‐1, 0)下则与部件‐B发生干涉。因此,序列被修 正为如下所示图14。
q g g
Output sequence: F! E! D! C! L! K! G! J! B! A! H.
序列编辑状态‐4: q g g
Input sequence: F! E! D! C! L! K! G! J! B! A! H.
序列编辑从实体位置5开始,部件‐L沿方向(0, 1, 0)不与任何 剩余部件发生干涉。部件‐K同样沿(0, 1, 0)方向无干涉地移出。 部件‐G沿方向(0, 1, 0)与部件‐J和H发生干涉,沿方向(0, −1, 0)与部件‐B和A发生干涉。由于在任一方向上与剩余部件的干 涉实例数量均为两次,因此需根据这两个方向进行序列编辑。
按照拆卸方向(0, 1, 0)进行的序列编辑得到的修正顺序如图 15所示:
Output sequence: F! E! D! C! L! K! J! B! A! G! H (a)
根据拆卸方向(0, ‐1, 0)进行序列编辑,得到的修正顺序如图16所 示。

| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F D E C K A L G J B H | ||||||||||
| 修正 | F E D C K A L G J B H |
| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F E D C K A L K G J B H | ||||||||||
| 修正 | F E D C A L K G J B H |
| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F E D C A L K G J B H | ||||||||||
| 修正 | F E D C L K G J B A H |
 的第4阶段序列编辑)
的第4阶段序列编辑)
| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F E D C L K G J B A H | ||||||||||
| 修正 | F E D C L K J B A H G |
 )
)
| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F E D C L K G J B A H | ||||||||||
| 修正 | F E D C L K J B A G H |
序列编辑阶段‐5
继续执行序列(a);
输入序列:F ! E ! D ! C ! L ! K ! J ! B ! A !H! G。序列编辑从实体位置7开始,对应的部件是部件‐J。部件 J、B、A和H依次沿方向坐标(0, 1, 0)、(0, ‐1, 0)、(0, ‐1, 0)和 (0, 1, 0)移动,且与剩余部件无干涉。最后剩下的是部件‐G。 因此,此处序列编辑完成,传动总成主要零件的拆卸进程如 图17所示。
Output sequence: F! E! D! C! L! K! J! B! A! H! G (a1)
继续执行(b)。
实体位置7处的部件是部件‐J。部件J、B、A和G依次沿 方向(0, 1, 0)、(0, −1, 0)、(0, −1, 0)和(0, −1, 0)从剩余部件 的装配中移出,且不与其他任何部件发生干涉。最后一个部 件是部件‐H。因此,此处序列编辑完成,得到传动总成主要 零件的另一种拆卸进程,如图18所示。
Output sequence: F! E! D! C! L! K! J! B! A! G! H (b1)
现在,连接器组已包含在上述拆卸序列中,从而得到包含连 接件的拆卸序列。连接器组在拆卸序列中的位置被安排在与 其连接关系相关的零件之前,这是因为一旦相应的零件集合 可用,连接件便会立即附加到渐进式装配中。采用此策略是 为了降低计算负担。
当连接器组在进程中被赋予位置时,主要零件的输出拆 卸进程(a1)变为如下拆卸序列。
ðe−fÞ! F! ðb− eÞ! E! ða− dÞ! D! ða− cÞ! C! ða−lÞ! L! K! J! B! A! H! G (a2)
当连接器组在进程中被赋予位置时,主要零件的输出拆卸进 程(b1)变为如下拆卸序列。
ðe−fÞ! F! ðb− eÞ! E! ða− dÞ! D! ða− cÞ! C! ða−lÞ! L! K! J! B! A! G! H (b2)
现在对该顺序再次执行干涉测试。测试结果显示全程无干涉。
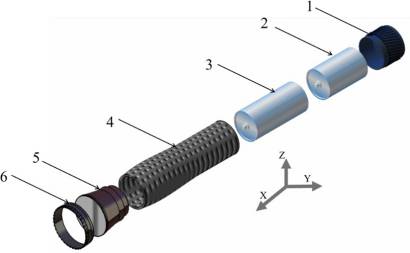
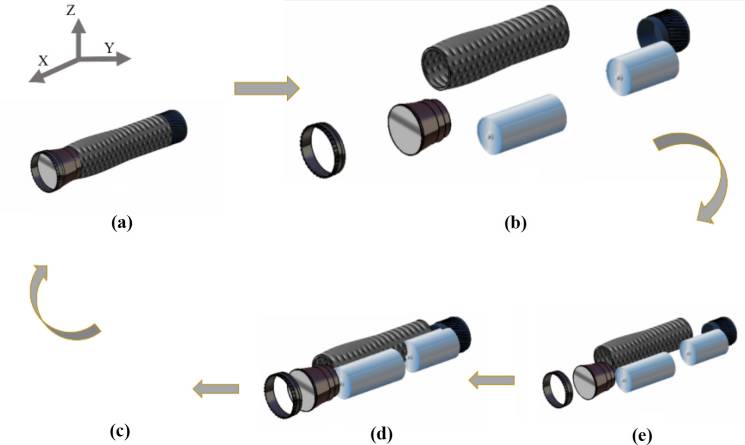
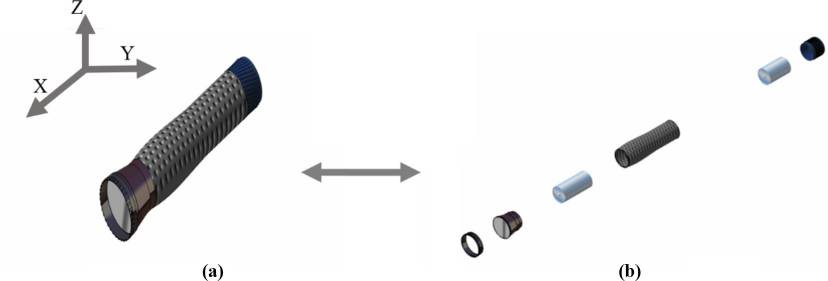
如图19所示的手电筒产品图19 被用于验证所开发的方法, 即在实际装配模型上实现的EBFD方法。将提出的方法获得的 初始和最终解与其他现有的ASG流行方法进行比较,并包含 在第i个表VI(De Mello 和 Sanderson,1991;Li等, 2002)中。通过与现有方法对6部分手电筒组件的求解方法进 行比较评估,在图20 中通过分析完成装配/拆卸操作所需的层 级数量,展示了所开发方法的有效性。由于通过检查连接数 构建了临时解,EBFD能够在更短的计算时间内生成高效的解, 而不同于人工智能方法。已进行了比较评估,并结合装配属 性检索时间、ASG时间、存储空间,在表VI中列出。与现有 其他方法相比,该提出的方法具有更短的计算时间。结果表 明,集成所提出的EBFD方法能够高效地解决EVG问题。表 VII 描述了采用所提出的方法可高效地实现并行装配序列计划 生成。
5. 爆炸图生成
要生成产品的爆炸图,必须识别并排列沿所有方向的并行可 能拆卸操作。在拆卸或装配操作中可能会出现多步操作同时 进行的情况,这将进一步缩短总提前期。识别这些可同时进 行的操作实例, 图17 第5阶段中序列(a)的序列编辑
| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F E D C L K J B A H G | ||||||||||
| 修正 | F E D C L K J B A H G |
 的序列编辑)
的序列编辑)
| 实体位置 | 1 | 2 | 3 | 4 | 5 | 6 | 7 | 8 | 9 | 10 | 11 |
|---|---|---|---|---|---|---|---|---|---|---|---|
| 输入 | F E D C L K J B A G H | ||||||||||
| 修正 | F E D C L K J B A G H |
并行输入因此变得重要。这对于EVG的输入信息也同样至关 重要。序列 (a2) 的拆卸进程按 表八 中所示进行安排。该表 被称为拆卸优先表 (DPT)。它给出了组成部件的拆卸优先关 系和拆解方向。拆卸进程 (b2) 类似地按 表IX 中所示进行安 排。
拆卸优先表 (DPT) 用于将零件和连接件的拆卸优先级排 列为可允许的拆卸操作层级,其中多个装配操作可以同时进 行。从第一方向行中取一个零件,并检查其与同一行中其他 后续零件的干涉情况,随后依次对其他方向行进行类似的干 涉测试,使得这些零件从剩余产品的包围盒中移出,同时根 据产品模型保持剩余部件的完整性。当首次出现干涉失败时, 测试停止,而在此失败之前通过干涉测试的零件被归入第一 拆卸级别。类似地,确定其他拆解级别。以下两条规则用于 构建拆卸进程中的各个拆卸级别。
5.1 拆卸规则
拆卸优先表的第一方向行中的初始零件与同一行中的下一个连 续零件以及其他方向行的零件一起移动,如果其扫过的体积 零件的极端边界互不干扰。
如果零件通过任何连接件相连,则必须从相应层级的更高层级 中取出。
拆卸进程被划分为拆解任务的级别,如表X 和 XI所示,拆卸 序列 (a2) 和 (b2) 的拆卸任务在表X和 XI中给出。
表六 提出的方法的比较评估(时间和存储)
| 名称 | 该方法 | 装配属性提取 通过CAD接口的时间(秒) | 生成时间 装配序列(秒) | 总时间(秒) | 装配属性 存储空间(字节) |
|---|---|---|---|---|---|
| 割集方法 | 304 | 20 | 324 | 6× 6× 7 | |
| GA | 304 | 8 | 312 | 6× 6× 7 | |
| EBFD | 54 | 14 | 68 | 6× 6× 4 |
表VII 所提方法的比较评估(ASP)
| 装配序列计划 | 产品名称 | 割集方法 | 人工智能方法(遗传 算法) | 基于包络的可行性检测(EBFD) |
|---|---|---|---|---|
| 6部分手电筒灯组件 | 4‐5‐6‐3‐2‐1 | 1‐2‐4‐3‐5‐6 | 4‐3‐[5(x−)‐2(x1)]‐[6(x−)‐1(x1)] |
表八 拆卸进程(a2序列)的拆卸优先级
| 方向 | 拆卸优先级 |
|---|---|
| (0,21,0) | (e‐f) F (b‐e) E (a‐d) D (a‐c) C B A G |
| (0,1,0) | (a‐1) L K J H |
表IX 拆卸进程(b2序列)的拆卸优先级
| 方向 | 拆卸优先级 |
|---|---|
| (0,21,0) | (e‐f) F (b‐e) E (a‐d) D (a‐c) C B A G |
| (0,1,0) | (a‐1) L K J H |
表十一 拆卸任务的拆卸序列(b2)等级
| 拆解级别 | 拆解方向 (0,−1,0) | 拆解方向 (0,1,0) |
|---|---|---|
| 一级 | (e−f) | ( a−1 ) |
| 二级 | F | L |
| 三级 | (b−e) | K |
| 4级 | E | J |
| 5级 | (a−d) | |
| 6级 | D | |
| 7级 | (a−c) | |
| 8级 | C | |
| 9级 | B | |
| 10级 | A | |
| 最后部分‐H |
TableX 层级拆解任务用于拆卸序列 (a2)
| 拆解级别 | 拆解方向 (0,−1,0) | 拆解方向 (0,1,0) |
|---|---|---|
| 一级 | (e−f) | (a−1) |
| 二级 | F | L |
| 三级 | (b−e) | K |
| 4级 | E | J |
| 5级 | (a−d) | H |
| 6级 | D | |
| 7级 | (a−c) | |
| 8级 | C | |
| 9级 | B | |
| 10级 | A | |
| 最后部分‐G |
表中获得的结果将用于后续的EVG。同一层级内的操作一并 执行,并按从第一级到最后一级的顺序进行。相对于相反方 向上的更高一级的主要零件,定义了一组新的偏移距离。在 配对部件的配合面之间定义一个偏移距离。通过逐级递增偏 移距离值至所需分离距离,使零件得以拆卸并分离。图20 显 示了
连接件组 (e−f) 与部件F之间定义的最终偏移距离的可视化。 增量速率可以在程序中进行调整,以逐级创建爆炸模拟。
该程序已成功与CAD软件集成,用于实现爆炸的可视化。基 于拆卸优先级,在CAD环境中进行爆炸图模拟。在部件的完 整排列下,预先存在的约束被停用,并定义新的偏移尺寸。
fined。在每一列下,针对所考虑的一对部件,在其包围盒的 极限面范围内定义拆卸方向和偏移约束。通过遍历所有层级, 生成拆卸模拟,并在fi获得的爆炸视图如图21所示。图21。
现在,序列中的层级被反转,以获得装配模拟,其中初 始约束值被替换为最终约束值。这实现了并行装配序列模拟, 并使产品从其组成部件进行装配。爆炸模拟可以反向回放, 以显示产品从其组成部件的装配顺序。
与部件F之间的偏移距离)
图22 表示在CATIA环境中六部件手电筒的通用爆炸视图。 每个零件在装配/拆卸过程中都会与其他零件发生碰撞,但在 爆炸展开以访问组件位置时,未观察到系统化路径。 图23 表示使用提出的EBFD方法生成的同一产品的爆炸图,每个零件 在爆炸展开时均遵循系统化路径,且可访问每个零件及其在 装配中的位置。
6. 结论
在产品开发阶段,有必要对计算机辅助设计(CAD)系统进 行更新,以获得爆炸图、并行装配操作和ASP。这些模块能 够为改进解决方案提供一种确定性方法。
在非正交方向上,该方法对零件数量较多的产品也具有可达 性和适用性。本文提出了一种名为“EBFD”方法的新型高效 方法,用于同时解决EVG和ASG问题,并支持并行装配操作:
- 提出了一种基于装配部件与其余装配部件之间连接关系的最 小连接数概念(如L值和S值),用于初始拆卸序列生成。该 概念旨在通过避免对随机序列进行不必要的计算时间消耗, 生成初始序列以检验其可行性。
- 提出了接触包络、接触骨架包络技术以及平行视觉规则和半空间规则,以检测装配部件在正交和非正交方向上的几何可行性。
- 提出了序列编辑 技术,通过分析拆卸过程的物理可行性来提高所生成拆卸序 列的适用性。
- 提出的方法的优点在于其采用非冗余的产品 信息进行求解生成,所需计算机存储空间和计算时间最少。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









