







其中一些概念可以参考上一篇《地址、MMU、内存管理相关概念》
转载请注明原文地址:http://blog.csdn.net/ts_dchs/article/details/49991297
1 x86地址映射
Linux采用页式存储管理,进程地址空间被以Page划分,Page默认4KB可以修改。物理内存被划分为相同大小的Page Frame,页帧。
x86逻辑地址(VA)段转化(segment translation)后得到线性地址,页转化(page translation)后得到物理地址(PA)。也就是说程序给入一个逻辑地址,CPU拿到后经过两个映射得到数据总线的地址(物理地址)。
借用前辈的图描述IA_32 (属于X86体系结构的32位版本)段页式地址转化(映射)的过程:
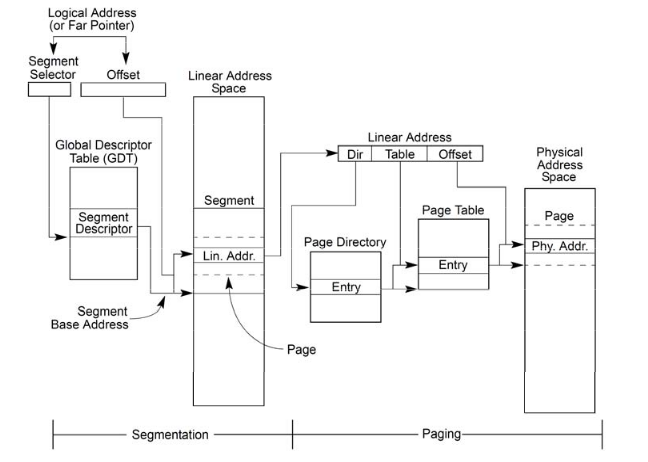
(image source: http://ilinuxkernel.com/?p=448 )
x86 CPU**段机制**(Segmentation)可以将程序的代码(Code)、数据(Data)、栈(Stack)分开。使多各进程互不干扰。也就是说,分段机制把虚拟地址空间的一个逻辑地址转换为线性地址空间的一个内存地址。
页机制(Paging)实现以page为需求的虚拟内存系统,在需要时才分配物理内存。页机制也可以隔离多任务。
逻辑地址有由页号和偏移量组成。内存被分为N个page,一个Job申请了4个Page,0-3,那么内容逻辑上会以此由0排到3号page,3号page中往往或有浪费空间,内部碎片(internal fragmentation)。然后逻辑上连续的这4个Page会被映射在物理内存的不同位置,不一定顺序或者连续。如图:
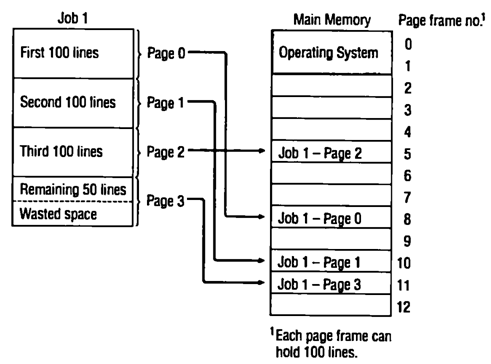
(image source: http://ilinuxkernel.com/?p=448 )
具体x86地址映射说明
IA_32提供的寄存器从功能上可分为类:CPU寄存器、系统寄存器。(笔者自己的分类)
CPU寄存器
IA_32 (属于X86体系结构的32位版本)提供10个32bit,6个16bit寄存器,分三类:
- 通用寄存器(8* 32bit registers)
- 数据寄存器 EAX、EBX、ECX、EDX
- 索引(变址)寄存器 ESI、EDI - 字符串处理指令相关
- 指针寄存器 ESP(Stack Pointer,当前栈顶)、EBP(Base Pointer,当前栈底) - 维护栈
- 控制寄存器(2* 32bit registers)
- EIP,Instruction Pointer,跟踪下一条要执行的指令,也称程序计数寄存器
- EFLAGS,Program Status and Control Register
- 段寄存器(6* 16bit registers)
- CS\ES\DS\FS\GS\SS
- 注:32bit架构中有6个段寄存器所以最多可以同时访问6个段。
- 注:在之后介绍两种CPU运行模式下段寄存器功能的变化。
系统寄存器
初始化CPU和控制系统的相关操作,用到的寄存器。与EFLAGS寄存器也有关。
- EFLAG的IOPL
- 控制寄存器
- CR0、CR2、CR3、CR4 - 系统级别,CPU特殊功能
- 系统描述表寄存器 - 只能在保护模式下使用
- GDTR(全局描述表寄存器 - GDT Entry线性基地址)
- LDTR(局部描述表寄存器 - 进程自己LDT的 段描述符)
- IDTR(中断描述表寄存器)
(image source: http://ilinuxkernel.com/?p=1276 )
- 任务寄存器 TR(Linux 没有使用)
- 调试寄存器 DR0~DR7
- 如DR7是断点控制寄存器
- 测试寄存器 TR0~TR7

如图:
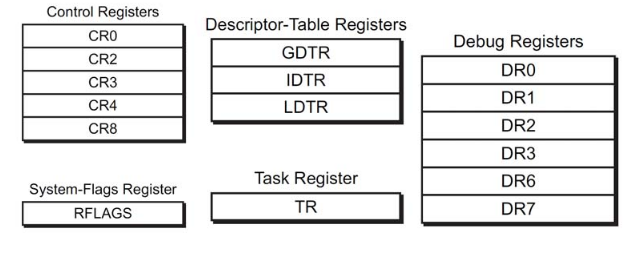
(image source: http://ilinuxkernel.com/?p=1276 )
工作模式
IA_32有两种工作模式:实模式,保护模式。
(有兴趣可以看一个贴,关于”寻访x86处理器“实模式”和“保护模式”的前世今生“)
实模式下:前4个段寄存器CS、DS、ES和SS与先前CPU中的所对应的段寄存器的含义完全一致,内存单元的逻辑地址仍为“段值:偏移量”(Segment:Offset)的形式。为访问某内存段内的数据,必须使用该段寄存器和存储单元的偏移量。
比如分别用CS(Code Segment), DS(Data Segment), SS(Stack Sagmet)来描述进程的代码段,数据段,堆栈段,然后用其中某个地址,如要访问堆栈数据,将SS数据左移4bit + Offset(DI)就是实际要访问的虚拟地址。
实模式由16位段寄存器做段基地址,和6位偏移地址形成20位的物理地址,最大寻址空间1MB,最大分段Limit 64KB。可以使用32位指令。在实模式下,所有的段都是可以读、写和可执行的。所以这种模式直接算出来的就是物理地址。
保护模式下:顾名思义要对内存空间做保护,不能像实模式那样随意访问。得到的是虚拟地址,需要再进行转化才能得到物理地址。
段寄存器装入的不是段地址。新的模式需要描述基地址、长度、权限等等来做保护,使用一64bit的数据结构 - 段描述符Selector。为了用16bit的寄存器来访问这个数据结构的信息,将这些64bit的段描述符放在一个数组中,将段寄存器的值作为下标索引间访问。
上面提到的数组就是GDT(Global Descriptor Table),GDT不但存有段描述符,还有其他64bit描述符。
GDT(Global Descriptor Table)可以放在内存任何位置,知道入口就可以。所以Intel设计了寄存器GDTR,存放GDT入口地址,通过
LGDT指令装入(32bit线性地址+16bit Limit如上描述表寄存器图)。之后CPU根据GDTR来访问GDT。GDT只有一个。GDT需要8Byte对齐,第一个描述符全0。每个CPU一个GDT。
LDT(Local Descriptor Table)与GDT结构类似,不过可以存在多个,非全局可见,只对任务可见。每个任务至多有一个。LDT自身作为一个段存在,段描述符放在GDT中。进程需要通过
LLDT指令(操作数是16bit Selector,GDT中所要LDT的索引)将LDT的段描述符装入LDTR,进而访问自己的LDR。
Linux事实上没有用到LDT。
Segment Descriptor: 64bit in GDT/LDT
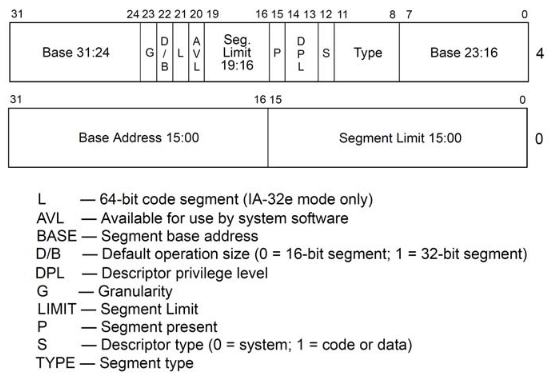
Segment Selector, 段选择子,高13 bit是GDT/LDT下标索引,+ 1 bit 处于GDT or LDT + 2 bit特权请求等级。
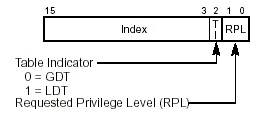
保护模式具体的还有有两种模式:段式,段页式。
段式
IA_32允许将段基地址用任何32bit能表示的值描述,Limit为32bit能表示的2^12的倍数的任何值(4K,Page的倍数)。在保护模式找到所需物理地址的过程是:- 段寄存器装入Selector
- 用这个Selector做索引在GDT/LDT中找到相应的段描述符
- 取出64bit描述符中记录目标段的的Base Address (+越界越权查看)
- 用Base Address + Offset得到要访问的线性地址。
所以可以看出,这样的访问方式适合于没有虚拟地址概念的OS,大家直接管理访问的都是线性地址。对于实现虚拟内存的,段页式更有效。
(image source: Intel Manuals )
段页式
资料中有一种是说尽量模仿纯页模式的映射方法:事实上本身应该是强调页模式,但是
IA_32无法完全禁止段模式,但可以让其效果降低。最终效果事实上是段页式。
方法是利用IA_32提供的“Basic Flat Model”在GDT定义两个段描述符:Code和Data Segment,两者都包含整个线性空间(Segment Limit = 4G, Kernel Segment)。Linux用这种方式,也就是说只使用了两个段,CS,DS每个进程的六个段寄存器值都相同,只有EIP(当前指令)、ESP(栈顶指针)不同。
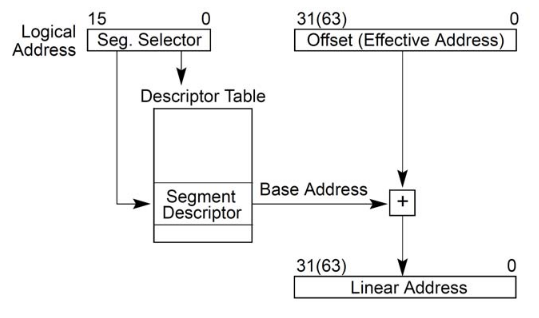
事实上上一步段式操作完成了虚拟到线性地址的映射,需要再做映射完成线性到物理地址的映射,完成本章节开始的第一个图的映射过程。过程是:
- 得到的线性地址是10 bit Directory Index + 10 bit Table Index + 12 bit Offset 如下图。
- 从CR3获取Page Directory基地址(每个进程有自己的控制块
task_strcut,里面记录了自己C3的信息)找到Page Directory的位置。 - 以线性地址的前10bit为索引找到对应PDE(Page Directory Entry)含一个Page Table的地址。
- 以线性地址的第二个10 bit为索引找到PTE(Page Table Entry)含有要访问4KB Page Frame的地址。
- 根据20 bit Page Fram基地址与线性地址中Offset相加得到要访问的物理地址。
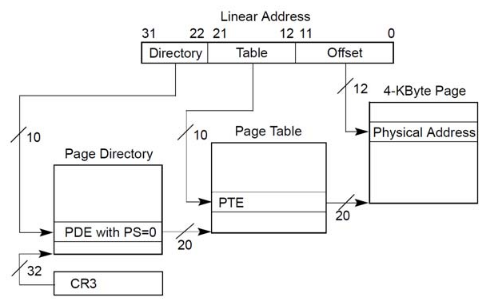
Two-level page table structure in x86 architecture (without PAE or PSE).
(image source: http://ilinuxkernel.com/?p=1276 )
返回来再看Linux的实现(只用两个段地址CS(赋值__USER_CS),DS/ES/SS(赋值__USER_DS),FS/GS是0)。在程序/arch/x86/include/asm/segment.h中所赋值分别是:
//文件中可以看到系统对于GDT的设计
#define GDT_ENTRY_DEFAULT_USER_CS 14
#define GDT_ENTRY_DEFAULT_USER_DS 15
#define __USER_DS (GDT_ENTRY_DEFAULT_USER_DS*8+3)
#define __USER_CS (GDT_ENTRY_DEFAULT_USER_CS*8+3)
//2.6.18内核的,笔者在自己给板子编译zImage的Linux 3.0.8的内核中查看有相同描述得到的结果是:
__USER_DS = 0000000001110 011 //index = 14, GDT
__USER_CS = 0000000000111 011 //index = 15, GDT它们被放入段寄存器中。通过5和6为Index找GDT中对应的段基址。那么GDT中的内容在哪里?段基址是多少?
在2.6.18内核
/*
* The Global Descriptor Table contains 28 quadwords, per-CPU.
*/
.align PAGE_SIZE_asm
ENTRY(cpu_gdt_table)
//中间略去下面是第14 15条
.quad 0x00cffa000000ffff /* 0x73 user 4GB code at 0x00000000 */
.quad 0x00cff2000000ffff /* 0x7b user 4GB data at 0x00000000 */根据上面Segment Descriptor的图的描述,找到对应的Base Address。
入用__USER_DS可以找到对应信息:BaseAddress是0,Limit是0xfffff。颗粒度标志G=1。表示Limit的单位是4KB。所以段的长度为0x0 ~ 0x8000 0000 -1。4G空间。代码段也是一样的。那么最后一个堆栈段上的变量的地址的效果就是 0(SS和DS段基地址一样) + Offset,逻辑地址的值就是线性地址的值。
发现一些内容找不到,在2.6.25内核后没有i386的文件夹,是x86。想问如何找到定义呢?
在得到线性地址后在利用MMU做到物理地址的转化(为了使Linux能在32位和64位CPU上运行,就要采用统一的页面地址模型。从2.6.11内核开始,页面地址模型采用了4级页面):
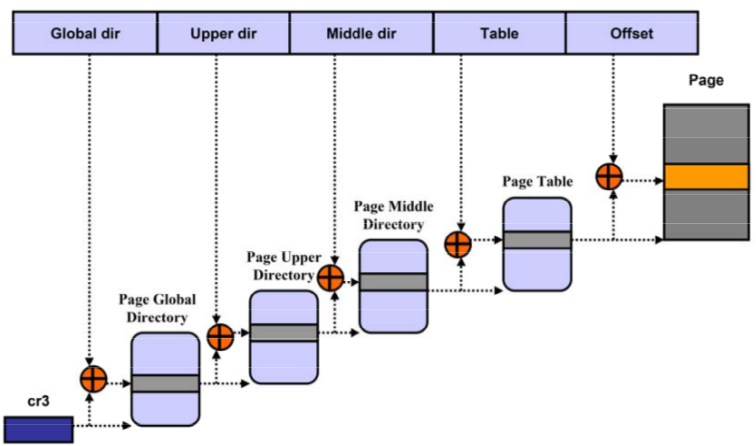
2 三级页表
很多资料依然用到三级页表,做一个介绍。
- PGD,Page Global Directory (页目录);
- PMD,Page Middle Directory (页目录);
*前两者内部的成为PDE,页目录项,Page Directory Entry。 - PTE,Page Table Entry (页表项,每一个表项对应一个物理页)。
相关宏可见下图:

一般由虚拟地址三级查询得到PTE的页表的过程(page table walk):
- 有描述进程占有资源的
struct mm_sturct mm和需要访问的虚拟地址unsigned long addr - 通过
pgd_offset(mm, addr)得到一级页表入口 - 通过
pmd_offset(pgd, addr)得到二级页表入口 - 通过
pte_offset_map(pmd, addr)得到目标页表项
其他相关术语
PAE(Physical Address Extensions),物理地址扩展机制。为了实现32bit系统更多(>4G)的物理内存。当CPU提供PAE机制,需要设置CR0、CR4、IA_EFER(MSR,扩展特性允许)寄存器。MMU会映射52bit(4PB)的地址空间,但系统线性地址仍然是32bit空间。
PSE(Page Size Extensions),页大小扩展,可以为了一些使用内存大的情况,设置Page由默认的4KB为4MB。(CR4.PSE=1)
一些问题:
Q1:两个程序分别访问一个逻辑地址,访问到最后的物理地址是一样的吗?不一样如何实现。
A1:对于有虚拟内存概念的OS,每个进程有自己的4G空间,会出现一样的逻辑地址。在程序中返回自己变量的地址,内容是自己进程的逻辑地址,这在段式映射中就是Offset,参考段式的图。那么选择码在哪呢?IA_32提供了SS(Stack Segment),从其中读出。进而获得进程存放变量的段的基地址,加上Offset就是线性地址。
3 ARM的地址映射
VA - MVA - PA
具体一点解释(网络资料以s3c2410 - ARM920T为例):
VA - MVA
如果总是直接用VA做映射,如果两个进程所用的VA重叠,则切换进程为了把VA映射到不同PA,需要重建页表,这样引起的Cache 无效和MMU(其中的TLB)抖动带来很大开销。所以Kernel会用VA和PID(进程ID)建立MVA来方便进程切换,如果两个不同进程原本访问VA重叠,比如都用(0-32M空间),但是经过PID的移位后就可以分开了。这样生成的MVA减少了进程切换的代价。
芯片的CP15些处理器中register 13是识别进程的寄存器,PID写在[31:25]之后的[25:0]写为0。
这样一来,能识别的进程最多2^7为128个,对应在4G虚拟空间就有每个进程32MB。
手册中:Addresses issued by the ARM9TDMI core in the range 0 to 32MB are translated by CP15 register 13, the ProcID register. Address A becomes A + (ProcID x 32MB). It is this translated address that is seen by both the Caches and MMU. Addresses above 32MB undergo no translation.
表示出来,进程地址的转化就是:PA = VA + PID * 32MB
用这样方式,MMU和Cache使用MVA,就可以减少重建页表的开销。
一些问题
ARM 用上述方式如果有大于32MB的程序呢?是错误吗。
MVA - PA
得到MVA后喂到MMU做到物理地址的映射。过程如下:
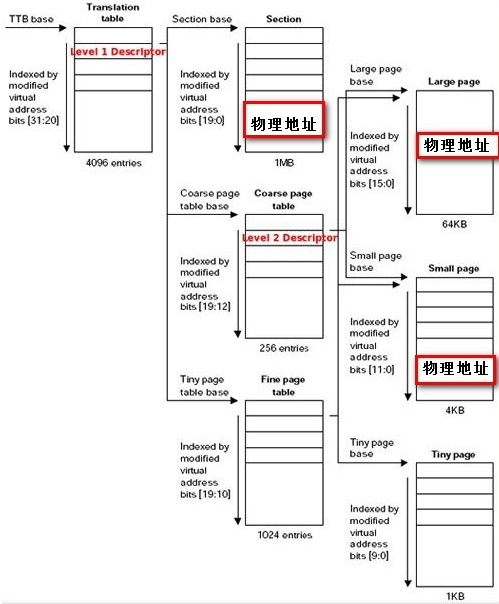
(image source: http://www.embedu.org/Column/Column583.htm )
中间用到的地址:
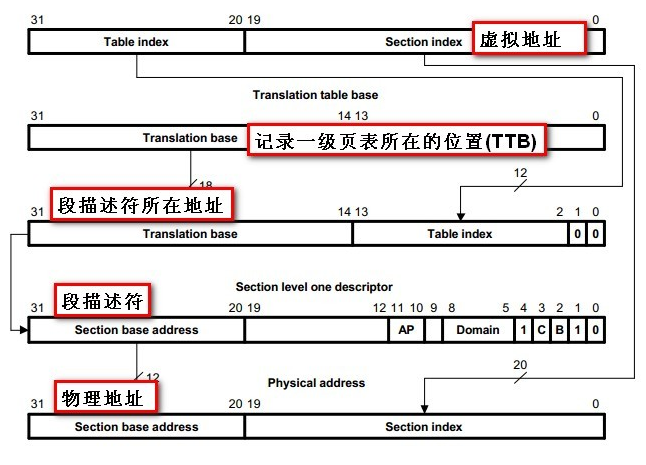
(image source: http://www.embedu.org/Column/Column583.htm )
解释:
- CP15从C2寄存器获得页基地址(TTB, translation table base),一级页表所在位置。要求16K对齐。
- MVA高12bit作为索引值,对应TTB中的一个Entry。12 bit 也就是 4K个,每个Entry可以表示1MB的地址空间。
- TTB + MVA[31:20]得到的Entry有三种:
- 段页(Section)描述符:指向一个1MB物理空间描述符末两位 0b10)
- 粗页(Coarse Page)描述符:有256个二级页表项,每个二级页表项代表4KB空间(理解:Entry指向的1MB空间中要存放32bit(4B)的描述符,可以放256个)(0b01)
- 细页(Fine Page)描述符:有1024个二级页表项,每个二级页表项代表1KB空间。(0b11)
- 还有一种是的得到的末两位为(0b00)没有对应Entry访问会产生fault
- 如果上一步指向Section,用MVA[19:0]作为索引可以找到1MB中对应请求的物理地址。
- 如果指向Coarse Page Table,根据MVA[19:12]做索引可以找到一个Entry,对应有两种情况:
- 找到的是Large Page Descriptor,对应一个64KB大小的物理地址,不过由于之前提到每个粗页表项对应4KB,所以有16个Descriptors对应这一个Large Page Descriptor。再用MVA[15:0]索引这个64KB物理地址中的某个位置。
- 找到的是Small Page Descriptor,对应一个4KB大小的物理地址,所以是1:1。再用MVA[11:0]索引这个Page Frame中的位置。
- 如果指向的是Fine Page Table,则用MVA[19:10]作为索引找到一个Entry,有相应三种情况,分别索引大页(Large Page),小页(Small Page),极小页(Tiny Page),可以根据上图得知索引方式。
notification
source: 《Linux设备驱动开发详解》(第二版),内容为读书笔记和网络资料,有些资料原始来源不详,分享为了方便自己和他人查阅。如有侵权请及时告知,对于带来的不便非常抱歉。转载请注明来源。个人所学有限,若有错误和不足还请不吝赐教,我会及时更正。Terrence Zhou.
http://blog.csdn.net/ts_dchs
reference
特别感谢:Linux内存地址映射 的资料,向前辈们学习。
[1] Linux地址地址映射,http://blog.chinaunix.net/uid-20528014-id-314322.html
[2] Linux内核高端内存,http://ilinuxkernel.com/?p=1013
[3] x86寄存器简介,http://blog.csdn.net/shrekmu/article/details/8588341
[4] 8086寄存器介绍,比较认真,http://www.cnblogs.com/zhaoyl/archive/2012/05/15/2501972.html
[5] Intel® 64 and IA-32 Architectures Software Developer Manuals,http://www.intel.com/content/www/us/en/processors/architectures-software-developer-manuals.html
[6] Page Table,https://en.wikipedia.org/wiki/Page_table
[7] MMU,寄存器,s3c2410,http://blog.csdn.net/WINITZ/article/details/4057495















 1785
1785

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









