







折腾了好久,终于搞定hadoop 2.6 在yarn框架下运行系统给予的一个mapreduce例子成功
中间报了很多错,折腾了2,3天。
参考:
http://tecadmin.net/setup-hadoop-2-4-single-node-cluster-on-linux/#
https://hadoop.apache.org/docs/r2.6.0/hadoop-project-dist/hadoop-common/SingleCluster.html
前序:设置host
[hadoop_terry@grande hadoop]$ hostname
grande
[hadoop_terry@grande hadoop]$ 我当前的hostname是grande
vim /etc/hosts
127.0.0.1 localhost localhost.localdomain localhost4 localhost4.localdomain4
10.10.10.252 grande
::1 localhost localhost.localdomain localhost6 localhost6.localdomain6vim /etc/sysconfig/network
NETWORKING=yes
HOSTNAME=grande
NETWORKING_IPV6=no上面要注意,我当前的hostname为grande,我查看 /etc/hosts 要存在这个hostname,也就要要存在grande 的host配置
然后我查看network的配置,把HOSTNAME改为grande
最后执行网络重启
/etc/init.d/network restart 上面的部分,最好在安装前做好,如果安装了java,hostname 就不要改了,就用之前设置的,如果改了,安装hadoop 就会在后续出一些莫名其妙的错误
这个是我在安装过程中的报错:http://blog.csdn.net/terry_water/article/details/49949683
1.安装java.
参考:http://tecadmin.net/install-java-8-on-centos-rhel-and-fedora/
cd /opt/
wget --no-cookies --no-check-certificate --header "Cookie: gpw_e24=http%3A%2F%2Fwww.oracle.com%2F; oraclelicense=accept-securebackup-cookie" "http://download.oracle.com/otn-pub/java/jdk/8u66-b17/jdk-8u66-linux-x64.tar.gz"
tar xzf jdk-8u66-linux-x64.tar.gzcd /opt/jdk1.8.0_66/
alternatives --install /usr/bin/java java /opt/jdk1.8.0_66/bin/java 2
alternatives --config java
There are 3 programs which provide 'java'.
Selection Command
-----------------------------------------------
* 1 /opt/jdk1.7.0_71/bin/java
+ 2 /opt/jdk1.8.0_45/bin/java
3 /opt/jdk1.8.0_51/bin/java
4 /opt/jdk1.8.0_66/bin/java
Enter to keep the current selection[+], or type selection number: 4alternatives --install /usr/bin/jar jar /opt/jdk1.8.0_66/bin/jar 2
alternatives --install /usr/bin/javac javac /opt/jdk1.8.0_66/bin/javac 2
alternatives --set jar /opt/jdk1.8.0_66/bin/jar
alternatives --set javac /opt/jdk1.8.0_66/bin/javac java -version
java version "1.8.0_66"
Java(TM) SE Runtime Environment (build 1.8.0_66-b17)
Java HotSpot(TM) 64-Bit Server VM (build 25.66-b17, mixed mode)设置java的 全局变量
#Setup JAVA_HOME Variable
export JAVA_HOME=/opt/jdk1.8.0_66
#Setup JRE_HOME Variable
export JRE_HOME=/opt/jdk1.8.0_66/jre
#Setup PATH Variable
export PATH=$PATH:/opt/jdk1.8.0_66/bin:/opt/jdk1.8.0_66/jre/bin同时把他保存到文件 /etc/environment中,当服务器 重启的时候加载:
vim /etc/environment
export JAVA_HOME=/opt/jdk1.8.0_66
export JRE_HOME=/opt/jdk1.8.0_66/jre
export PATH=$PATH:/opt/jdk1.8.0_66/bin:/opt/jdk1.8.0_66/jre/bin这样就完成了java的安装和全局变量的配置
2. 安装hadoop
创建hadoop账户
adduser hadoop_terry
passwd hadoop_terryAfter creating account, it also required to set up key based ssh to its own account. To do this use execute following commands.
su - hadoop_terry
ssh-keygen -t rsa
cat ~/.ssh/id_rsa.pub >> ~/.ssh/authorized_keys
chmod 0600 ~/.ssh/authorized_keysssh localhost
exit
cd ~
wget http://apache.claz.org/hadoop/common/hadoop-2.6.0/hadoop-2.6.0.tar.gz
tar xzf hadoop-2.6.0.tar.gz
mv hadoop-2.6.0 hadoop配置:编辑文件 ~/.bashrc 文件
export HADOOP_HOME=/home/hadoop_terry/hadoop
export HADOOP_INSTALL=$HADOOP_HOME
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
export PATH=$PATH:$HADOOP_HOME/sbin:$HADOOP_HOME/bin
export JAVA_HOME=/opt/jdk1.8.0_66/
让配置生效:
source ~/.bashrc配置hadoop的配置文件
vim $HADOOP_HOME/etc/hadoop/hadoop-env.shexport JAVA_HOME=/opt/jdk1.8.0_66/配置xml文件:
cd $HADOOP_HOME/etc/hadoopEdit core-site.xml (我的配置是grande,所以value是hdfs://grande:9000)
<configuration>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
</configuration>Edit hdfs-site.xml
<configuration>
<property>
<name>dfs.replication</name>
<value>1</value>
</property>
<property>
<name>dfs.name.dir</name>
<value>file:///home/hadoop_terry/hadoopdata/hdfs/namenode</value>
</property>
<property>
<name>dfs.data.dir</name>
<value>file:///home/hadoop_terry/hadoopdata/hdfs/datanode</value>
</property>
</configuration>Edit mapred-site.xml
<configuration>
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
</configuration>Edit yarn-site.xml
<configuration>
<property>
<name>yarn.nodemanager.aux-services</name>
<value>mapreduce_shuffle</value>
</property>
</configuration>创建文件hdfs 的 namenode和datanode 文件夹路径:
mkdir -p /home/hadoop_terry/hadoopdata/hdfs/namenode
mkdir -p /home/hadoop_terry/hadoopdata/hdfs/datanodeFormat Namenode
bin/hdfs namenode -format日志输出:
15/02/04 09:58:43 INFO namenode.NameNode: STARTUP_MSG:
/************************************************************
STARTUP_MSG: Starting NameNode
STARTUP_MSG: host = svr1.tecadmin.net/192.168.1.133
STARTUP_MSG: args = [-format]
STARTUP_MSG: version = 2.6.0
...
...
15/02/04 09:58:57 INFO common.Storage: Storage directory /home/hadoop/hadoopdata/hdfs/namenode has been successfully formatted.
15/02/04 09:58:57 INFO namenode.NNStorageRetentionManager: Going to retain 1 images with txid >= 0
15/02/04 09:58:57 INFO util.ExitUtil: Exiting with status 0
15/02/04 09:58:57 INFO namenode.NameNode: SHUTDOWN_MSG:
/************************************************************
SHUTDOWN_MSG: Shutting down NameNode at svr1.tecadmin.net/192.168.1.133
************************************************************/启动:
#启动dfs
sbin/start-dfs.sh
#启动Yarn
sbin/start-yarn.shsbin/start-all.sh一次全部关闭:
sbin/stop-all.shHadoop NameNode started on port 50070 default. Access your server on port 50070 in your favorite web browser.
http://svr1.tecadmin.net:50070/
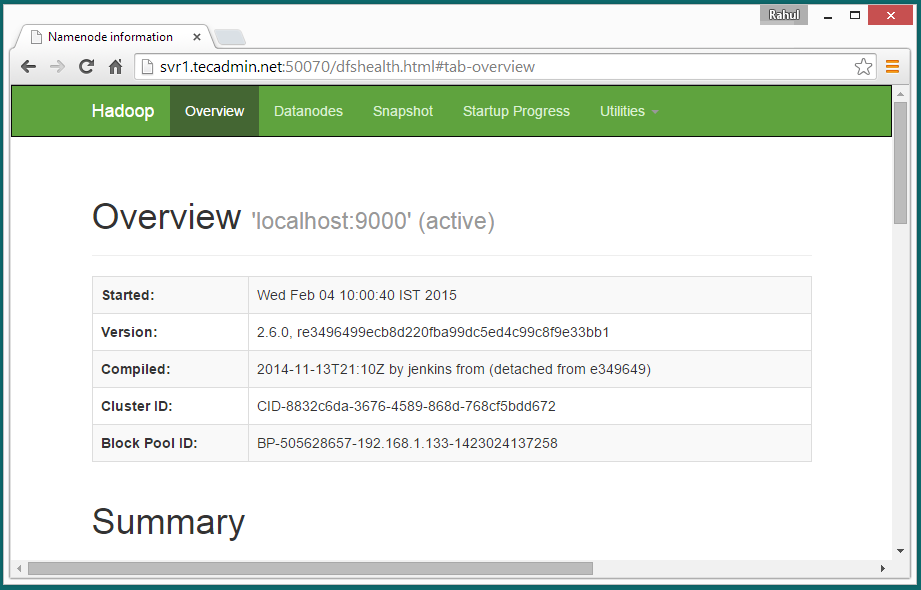
Now access port 8088 for getting the information about cluster and all applications
http://svr1.tecadmin.net:8088/
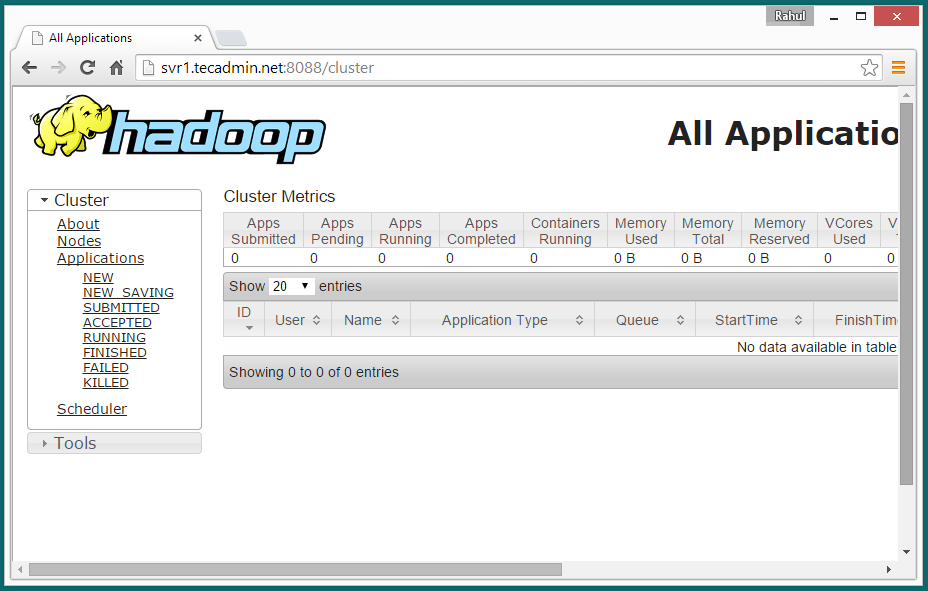
Access port 50090 for getting details about secondary namenode.
http://svr1.tecadmin.net:50090/
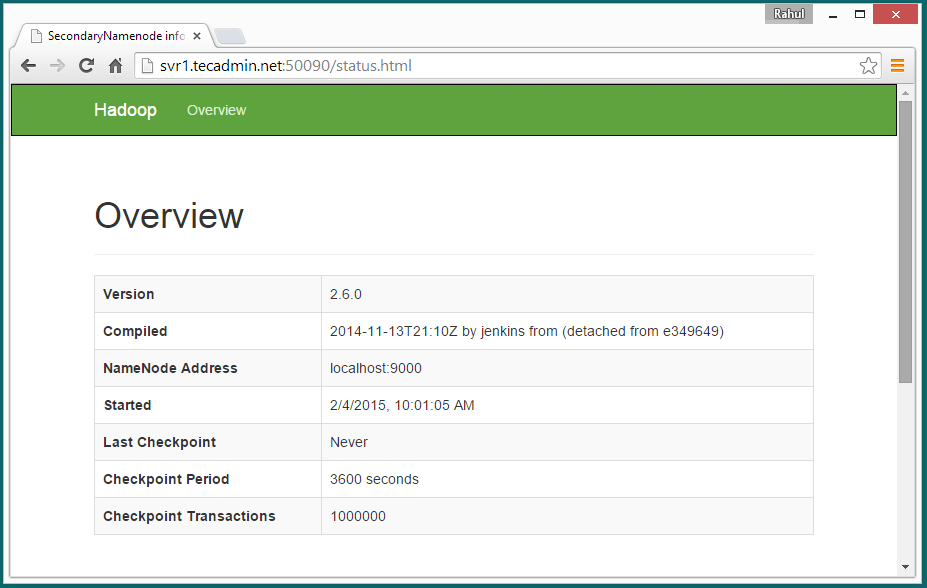
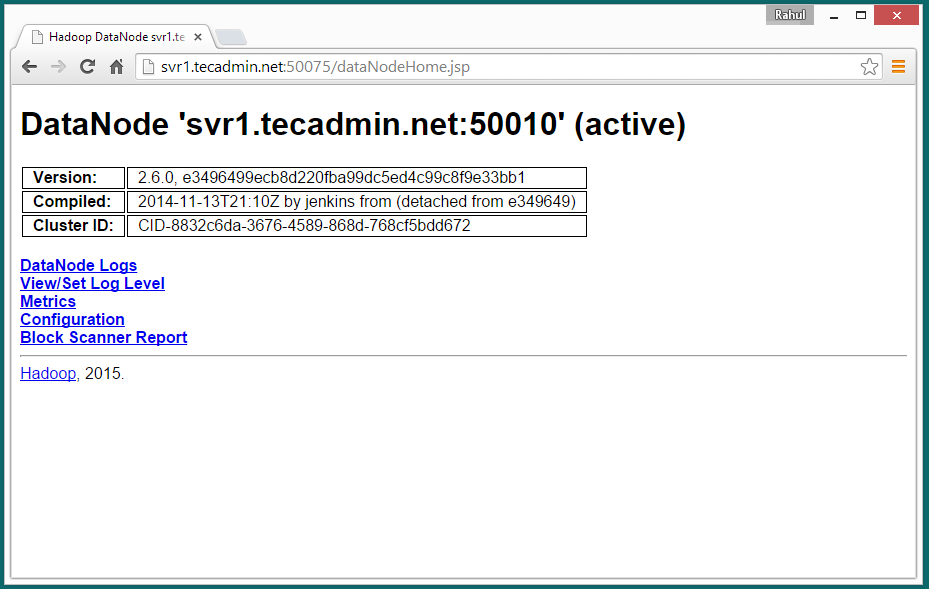
Access port 50075 to get details about DataNode
http://svr1.tecadmin.net:50075/
bin/hdfs dfs -mkdir /user
bin/hdfs dfs -mkdir /user/hadoop_terry
bin/hdfs dfs -put etc/hadoop input
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.6.0.jar grep input output 'dfs[a-z.]+'执行的日志:
15/11/26 12:29:18 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
15/11/26 12:29:19 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/11/26 12:29:20 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
15/11/26 12:29:20 INFO input.FileInputFormat: Total input paths to process : 29
15/11/26 12:29:20 INFO mapreduce.JobSubmitter: number of splits:29
15/11/26 12:29:20 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1448511944803_0001
15/11/26 12:29:20 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
15/11/26 12:29:21 INFO impl.YarnClientImpl: Submitted application application_1448511944803_0001
15/11/26 12:29:21 INFO mapreduce.Job: The url to track the job: http://grande:8088/proxy/application_1448511944803_0001/
15/11/26 12:29:21 INFO mapreduce.Job: Running job: job_1448511944803_0001
15/11/26 12:29:30 INFO mapreduce.Job: Job job_1448511944803_0001 running in uber mode : false
15/11/26 12:29:30 INFO mapreduce.Job: map 0% reduce 0%
15/11/26 12:29:43 INFO mapreduce.Job: map 3% reduce 0%
15/11/26 12:29:44 INFO mapreduce.Job: map 21% reduce 0%
15/11/26 12:29:56 INFO mapreduce.Job: map 31% reduce 0%
15/11/26 12:29:57 INFO mapreduce.Job: map 41% reduce 0%
15/11/26 12:30:08 INFO mapreduce.Job: map 48% reduce 0%
15/11/26 12:30:09 INFO mapreduce.Job: map 52% reduce 0%
15/11/26 12:30:10 INFO mapreduce.Job: map 59% reduce 0%
15/11/26 12:30:13 INFO mapreduce.Job: map 59% reduce 20%
15/11/26 12:30:18 INFO mapreduce.Job: map 66% reduce 20%
15/11/26 12:30:19 INFO mapreduce.Job: map 72% reduce 20%
15/11/26 12:30:20 INFO mapreduce.Job: map 76% reduce 20%
15/11/26 12:30:22 INFO mapreduce.Job: map 76% reduce 25%
15/11/26 12:30:27 INFO mapreduce.Job: map 79% reduce 25%
15/11/26 12:30:28 INFO mapreduce.Job: map 83% reduce 25%
15/11/26 12:30:29 INFO mapreduce.Job: map 86% reduce 25%
15/11/26 12:30:30 INFO mapreduce.Job: map 93% reduce 25%
15/11/26 12:30:31 INFO mapreduce.Job: map 93% reduce 30%
15/11/26 12:30:33 INFO mapreduce.Job: map 97% reduce 30%
15/11/26 12:30:34 INFO mapreduce.Job: map 100% reduce 31%
15/11/26 12:30:35 INFO mapreduce.Job: map 100% reduce 100%
15/11/26 12:30:36 INFO mapreduce.Job: Job job_1448511944803_0001 completed successfully
15/11/26 12:30:36 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=391
FILE: Number of bytes written=3176200
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=80902
HDFS: Number of bytes written=495
HDFS: Number of read operations=90
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=29
Launched reduce tasks=1
Data-local map tasks=29
Total time spent by all maps in occupied slots (ms)=290919
Total time spent by all reduces in occupied slots (ms)=37760
Total time spent by all map tasks (ms)=290919
Total time spent by all reduce tasks (ms)=37760
Total vcore-seconds taken by all map tasks=290919
Total vcore-seconds taken by all reduce tasks=37760
Total megabyte-seconds taken by all map tasks=297901056
Total megabyte-seconds taken by all reduce tasks=38666240
Map-Reduce Framework
Map input records=2083
Map output records=26
Map output bytes=632
Map output materialized bytes=559
Input split bytes=3612
Combine input records=26
Combine output records=15
Reduce input groups=13
Reduce shuffle bytes=559
Reduce input records=15
Reduce output records=13
Spilled Records=30
Shuffled Maps =29
Failed Shuffles=0
Merged Map outputs=29
GC time elapsed (ms)=4931
CPU time spent (ms)=18640
Physical memory (bytes) snapshot=7176192000
Virtual memory (bytes) snapshot=62395002880
Total committed heap usage (bytes)=5927075840
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=77290
File Output Format Counters
Bytes Written=495
15/11/26 12:30:36 INFO client.RMProxy: Connecting to ResourceManager at /0.0.0.0:8032
15/11/26 12:30:36 WARN mapreduce.JobSubmitter: No job jar file set. User classes may not be found. See Job or Job#setJar(String).
15/11/26 12:30:36 INFO input.FileInputFormat: Total input paths to process : 1
15/11/26 12:30:36 INFO mapreduce.JobSubmitter: number of splits:1
15/11/26 12:30:36 INFO mapreduce.JobSubmitter: Submitting tokens for job: job_1448511944803_0002
15/11/26 12:30:36 INFO mapred.YARNRunner: Job jar is not present. Not adding any jar to the list of resources.
15/11/26 12:30:36 INFO impl.YarnClientImpl: Submitted application application_1448511944803_0002
15/11/26 12:30:36 INFO mapreduce.Job: The url to track the job: http://grande:8088/proxy/application_1448511944803_0002/
15/11/26 12:30:36 INFO mapreduce.Job: Running job: job_1448511944803_0002
15/11/26 12:30:47 INFO mapreduce.Job: Job job_1448511944803_0002 running in uber mode : false
15/11/26 12:30:47 INFO mapreduce.Job: map 0% reduce 0%
15/11/26 12:30:53 INFO mapreduce.Job: map 100% reduce 0%
15/11/26 12:30:59 INFO mapreduce.Job: map 100% reduce 100%
15/11/26 12:30:59 INFO mapreduce.Job: Job job_1448511944803_0002 completed successfully
15/11/26 12:30:59 INFO mapreduce.Job: Counters: 49
File System Counters
FILE: Number of bytes read=337
FILE: Number of bytes written=211275
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
HDFS: Number of bytes read=629
HDFS: Number of bytes written=227
HDFS: Number of read operations=7
HDFS: Number of large read operations=0
HDFS: Number of write operations=2
Job Counters
Launched map tasks=1
Launched reduce tasks=1
Data-local map tasks=1
Total time spent by all maps in occupied slots (ms)=3103
Total time spent by all reduces in occupied slots (ms)=3430
Total time spent by all map tasks (ms)=3103
Total time spent by all reduce tasks (ms)=3430
Total vcore-seconds taken by all map tasks=3103
Total vcore-seconds taken by all reduce tasks=3430
Total megabyte-seconds taken by all map tasks=3177472
Total megabyte-seconds taken by all reduce tasks=3512320
Map-Reduce Framework
Map input records=13
Map output records=13
Map output bytes=305
Map output materialized bytes=337
Input split bytes=134
Combine input records=0
Combine output records=0
Reduce input groups=5
Reduce shuffle bytes=337
Reduce input records=13
Reduce output records=13
Spilled Records=26
Shuffled Maps =1
Failed Shuffles=0
Merged Map outputs=1
GC time elapsed (ms)=149
CPU time spent (ms)=1780
Physical memory (bytes) snapshot=415051776
Virtual memory (bytes) snapshot=4167569408
Total committed heap usage (bytes)=312999936
Shuffle Errors
BAD_ID=0
CONNECTION=0
IO_ERROR=0
WRONG_LENGTH=0
WRONG_MAP=0
WRONG_REDUCE=0
File Input Format Counters
Bytes Read=495
File Output Format Counters
Bytes Written=227















 425
425

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









