







 对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。同时每个成长路线对应的板块都有配套的视频提供:当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。
对于从来没有接触过网络安全的同学,我们帮你准备了详细的学习成长路线图。可以说是最科学最系统的学习路线,大家跟着这个大的方向学习准没问题。同时每个成长路线对应的板块都有配套的视频提供:当然除了有配套的视频,同时也为大家整理了各种文档和书籍资料&工具,并且已经帮大家分好类了。
企业数据安全治理,除了熟悉法律法规条文,信息采集最小化,服务入口明确隐私协议外,更多的是需要建设内部基础能力,如数据识别、分类分级、数据加密、权限管控等数据安全的基础能力。
本文数据为中心的理念,围绕数据识别、分类分级、基础防护几个方面,结合开源软件做一次梳理和功能演示,希望能帮助有需要的人员对数据安全有个直观的了解。
在数据识别基础上,建立数据资产大盘,实现数据资产风险识别、监测、运营的资产全生命周期管理;
在数据分类分级的基础上,对不同数据资产进行分类、分级,将优势资源投入到关键资产的安全防护上;
在数据安全基础防护方面,除了应具有基础设施和架构的安全稳固外,基于数据识别和分类分级,对存储、传输的敏感数据进行加密防护、账号权限管控、数据脱敏和分发管控,结合内外部风险变化,最终走向数据安全风控之路。
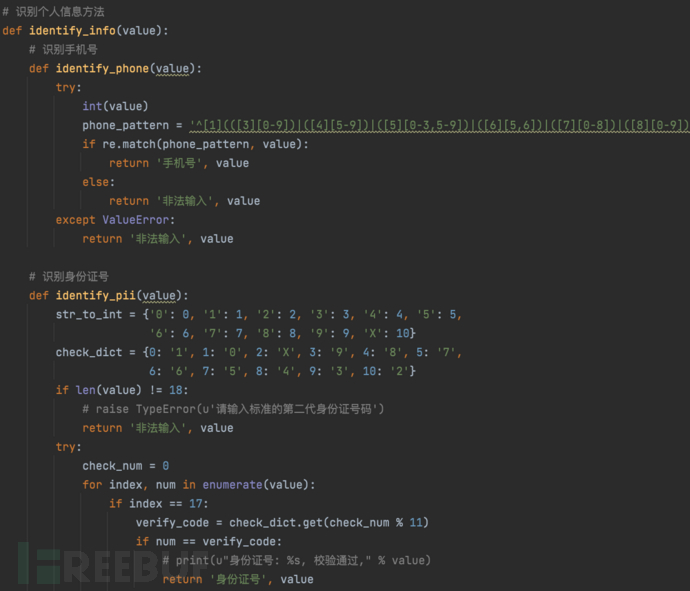
1、数据识别、分类
在大数据时代的今天,如何做好数据识别、分类,在这个基础上建立数据资产全生命周期管理是很多企业面临的挑战。比如企业内部有多少数据库表明文存储手机号字段、有多少接口对外暴露且有手机号字段,这些数据库表、接口等资产又面临哪些风险,如何做到全生命周期的风险管控。针对结构化数据,如数据库表中字段识别、半结构化数据,如日志中的数据识别、非结构化如图片、音视频文件的数据识别,在识别能力的覆盖范围、识别准确率、对性能的影响等方面,这对很多企业还是有不小的挑战。
1.1. 内容识别示例
数据识别可以通过关键字、正则、算法等实现,网上文章很多,以及一些大厂也有成熟的识别技术和方案,从落地实现上主要还是基于业务场景,从数据类型上看主要分为结构化、半结构化、非结构化的数据识别。
结构化:关系型数据库
半结构化:日志数据、JSON数据、XML文档等
非结构化:HTML网页、办公文档、图片、音视频文件等
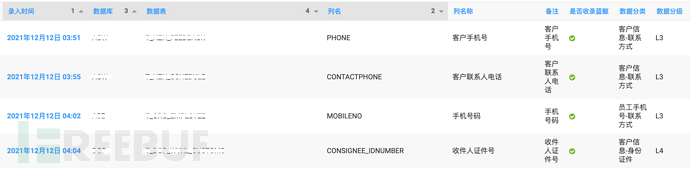
1.2. 分类分级管理展示
2、利用ShardingSphere-Proxy实现敏感数据加密
ShardingSphere是apache顶级开源项目,旨在构建异构数据库上层的标准和生态。它关
注如何充分合理地利用数据库的计算和存储能力,而并非实现一个全新的数据库。ShardingSphere 站在
数据库的上层视角,关注他们之间的协作多于数据库自身。
连接、增量和可插拔是 Apache ShardingSphere 的核心概念。
- 连接:通过对数据库协议、SQL方言以及数据库存储的灵活适配,快速的连接应用与多模式的异构数据库;
- 增量:获取数据库的访问流量,并提供流量重定向(数据分片、
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 3351
3351











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









