







泛型程序设计的基本概念
所谓泛型程序设计,就是编写不依赖于具体数据类型的程序。泛型程序设计的主要思想是将算法从特定的数据结构中抽象出来,使算法成为通用的、可以作用于各种不同的数据结构。
泛型程序设计的数据类型T的协议:
从函数模板的声明来看,类型参数T可以是任何数据类型,但实际上并非如此。类型T必须具备3个功能:
①类型T的变量之间能够比较大小
②类型T必须具有公有的复制构造函数
③类型T的变量之间能够用“=”赋值
STL简介
STL提供了一些常用的数据结构和算法。STL更大的意义在于,它定义了一套概念体系,为泛型程序设计提供了逻辑基础
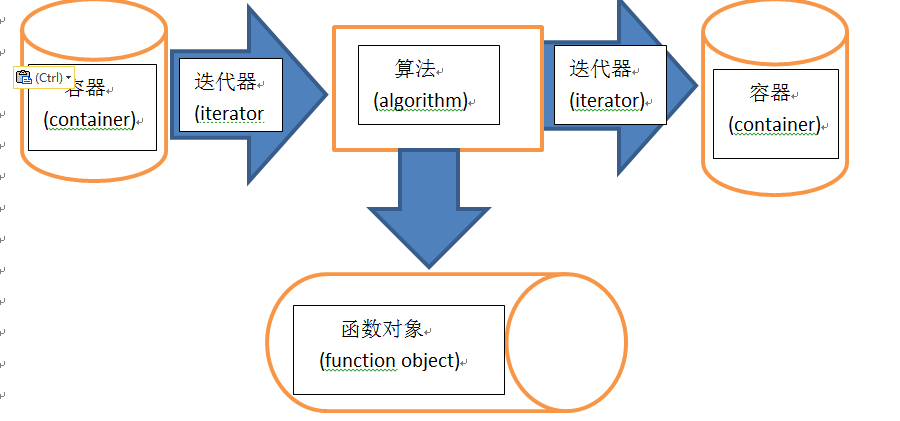
迭代器(iterator)
迭代器简介
STL算法利用迭代器对存储在容器中的元素序列进行遍历,迭代器提供了访问容器中每个元素的方法。指针本身就是一种迭代器,迭代器是泛化的指针,比指针的功能更强大。STL中的算法是通用的函数模板,并不专门针对某一容器类型。算法要适用于多种容器,而每一种容器中存放的元素又可以是任意类型。对迭代器可以使用“++”运算符来获得指向下一个元素的迭代器,可以使用“*”运算符访问一个迭代器所指向的元素。迭代器实际上是一个内部类。每一种容器内部都包含一个叫做迭代器的内部类,这个内部类的成员函数就是对各种运算符的重载。模板使得算法独立于存储的数据类型,而迭代器使算法独立于使用的容器类型。
输入流迭代器和输出流迭代器
输入流迭代器
Istream_iterator<T>(istream& in);
T是使用该迭代器从输入流中输入数据的类型。类型T要满足两个条件:
①有默认构造函数
②对该类型的数据可以使用“>>”从输入流输入。
用“++”运算符可以从输入流中读取下一个元素;若类型T是类类型或结构体,用“->”可以直接访问刚刚读取元素的成员。
Istream_iterator类模板有一个默认构造函数,用该函数构造出的迭代器指向的就是输入流的结束位置,将一个输入流与这个迭代器进行比较就可以判断输入流是否结束。
例如:
copy(istream_iterator<string>(cin),//输入流
istream_iterator<string>(), //输入流结束位置
ostream_iterator<string>(cout,"\n") //输出流及元素分隔符
);
注意:由于该程序会从标准输入流中读取数据直到输入流结束,运行该程序时,输入完数据后,在windows下需要按【ctrl+z】和回车键,在linux下需要按【ctrl+D】键,表示标准输入结束。后面凡是通过一对Istream_iterator读入数据的程序皆如此。
输出流迭代器
一个输出流迭代器可以用下面两个构造函数来构造:
ostream_iterator<T>(ostream&out);
//参数delimiter是可选的,表示两个输出数据之间的分隔符
ostream_iterator<T>(ostream& out,const char * delimiter);
输出流迭代器也支持“++”运算符,但是该运算符实际上不会使该迭代器的状态发生任何改变,支持“++”运算仅仅是为了让它和其他迭代器有统一的接口。
适配器(adapter)是指用于为已有对象提供新的接口的对象,适配器本身一般并不提供新的功能,只为改变对象的接口为存在。输入流迭代器和输出流迭代器将输入流和输出流的接口变更为迭代器的接口,因此它们属于适配器。
迭代器的分类
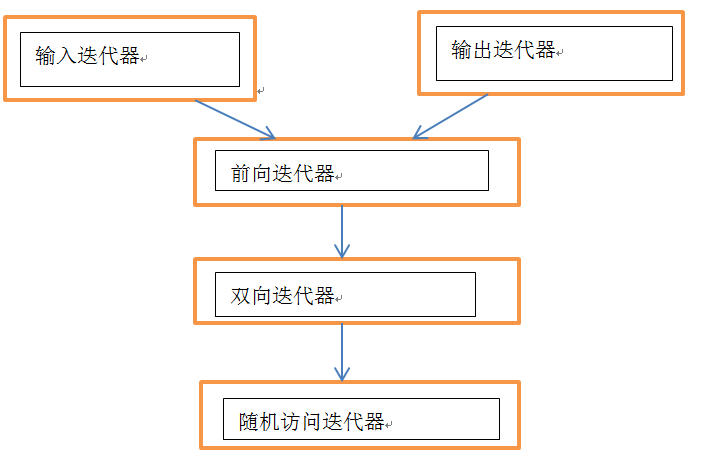
结构图:
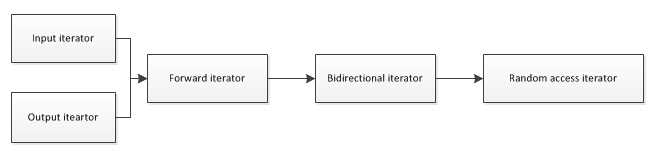
上面即为我们所讨论到的几个迭代器的层次.看起来很像继承是麽?
但是实际上在STL中,这些并不是通过继承关联的.这些只不过是一些符合条件的集合.这样的好处是:少去了一个特殊的基类(input iterator),其次,使得内建类型指针可以成为iterator.其实只要明白iterator是满足某些特别的功能的集合(包括类和内建类型),就不会觉得是继承了.
根据STL中的分类,iterator包括:
InputIterator:只能单步向前迭代元素,不允许修改由该类迭代器引用的元素。
OutputIterator:该类迭代器和Input Iterator极其相似,也只能单步向前迭代元素,不同的是该类迭代器对元素只有写的权力。
ForwardIterator:该类迭代器可以在一个正确的区间中进行读写操作,它拥有Input Iterator的所有特性,和Output Iterator的部分特性,以及单步向前迭代元素的能力。
BidirectionalIterator:该类迭代器是在Forward Iterator的基础上提供了单步向后迭代元素的
能力。
RandomAccess Iterator:该类迭代器能完成上面所有迭代器的工作,它自己独有的特性就是可以像指针那样进行算术计算,而不是仅仅只有单步向前或向后迭代。
输入迭代器
输入迭代器可以用来从序列中读取数据,但是不能够向其中写入数据。输入迭代器支持对序列进行的单向遍历。输入流迭代器就是一种典型的输入迭代器。
注意:输入流迭代器只适用于作为那些只需要遍历序列一次的算法的输入。
input iterator就像其名字所说的,工作的就像输入流一样.我们必须能
• 取出其所指向的值
• 访问下一个元素
• 判断是否到达了最后一个元素
• 可以复制
因此其支持的操作符有 *p,++p,p++,p!=q,p == q这五个.凡是支持这五个操作的类都可以称作是输入迭代器.当然指针是符合的.
输出迭代器
输出迭代器可以用来向序列中写入数据,但是不能够从其中读取数据。输出迭代器也支持对序列进行单向遍历。输出流迭代器就是一种典型的输出迭代器。
注意:使用输出迭代器,写入元素的操作和“++”自增的操作必须交替进行。如果连续两次自增之间没有写入元素,或连续两次使用“*iter = elem”这样的语法写入元素之间没有自增,其行为都是不确定的。
output iterator工作方式类似输出流,我们能对其指向的序列进行写操作,其与input iterator不相同的就是*p所返回的值允许修改,而不一定要读取,而input只允许读取,不允许修改.支持的操作和输入迭代器一样,支持的操作符也是 *p,++p,p++,p!=q,p == q.
程序实例:
template<classInputIterator,class OutputIterator>
void Copy(InputIteratorin1,InputIteratorin2,OutputIteratorout)
{
for (; in1 != in2; ++in1)
{
// out只能解引用写入值,先赋值,再移动迭代器
//in1只能解引用读取值
*out++ = *in1;
//std::cout << *out << std::endl;//error
}
}
//定义输出迭代器对象
ostream_iterator<int> out(cout,"*****");
//从标准输入设备给数组Array赋值(Array.begin()从起始元素开始,覆盖原有元素)
Copy(istream_iterator<int>(cin),istream_iterator<int>(),Array.begin());
//Copy(Array.begin(), Array.end(),ostream_iterator<int>(cout, "***"));//OK匿名对象
//将数组的值输出到标准输出设备上
Copy(Array.begin(), Array.end(), out/*ostream_iterator<int>(cout,"***")*/);
注意:输出迭代器可以先定义再使用,即可重复使用;而输入迭代器不可重复使用。因此Copy传参时,输入迭代器只能传递匿名对象,而输出迭代器可以传递已定义的输出迭代器对象。
前向迭代器
前向迭代器这一概念是输入迭代器和输出迭代器这两个概念的子概念,它既支持数据读取,也支持数据写入。前向迭代器支持对序列进行可重复的单向遍历。它去掉了输入迭代器和输出迭代器这两个概念中的一些不确定性。前向迭代器不再有输出迭代器关于“‘++’自增操作和对元素的写入操作必须交替进行”的限制。
前向迭代器就像是输入和输出迭代器的结合体,其*p既可以访问元素,也可以修改元素.因此支持的操作也是相同的.
双向迭代器
双向迭代器这一概念是单向迭代器的子概念。在单向迭代器所支持的功能基础上,它又支持迭代器向反方向的移动(可以使用“--”运算符)。
双向迭代器在前向迭代器上更近一步,其要求该种迭代器支持operator--,因此其支持的操作有 *p,++p,p++,p!=q,p == q,--p,p—
随机访问迭代器
随机访问迭代器这一概念是双向迭代器的子概念。在双向迭代器所支持的功能基础上,它又支持直接将迭代器向前或向后移动n个元素,因此随机访问迭代器的功能几乎和指针一样。随机访问迭代器即如其名字所显示的一样,其在双向迭代器的功能上,允许随机访问序列的任意值.显然,指针就是这样的一个迭代器.
对于随机存取迭代器来说, 其要求高了很多:
• 可以判断是否到结尾( a==b or a != b)
• 可以双向递增或递减(--a or ++a)
• 可以比较大小( a< b or a > b or a>=b ...etc)
• 支持算术运算( a +n)
• 支持随机访问( a[n])
• 支持复合运算( a+=n)
通过向量容器vector的begin和end函数得到的迭代器就是随机访问迭代器,指针也是随机访问迭代器。
template<class T,class InputIterator,class OutputIterator>
voidMySort(InputIterator first, InputIterator last, OutputIterator result)
{
vector<T> s; //创建向量容器的目的是为了产生随机访问迭代器,便于sort函数的调用
for (; first != last; ++first)
{
s.push_back(*first); //依次将输入迭代器输入的数据压如向量容器s的末尾
}
sort(s.begin(), s.end()); // sort函数的参数必须是随机访问迭代器
copy(s.begin(), s.end(), result); //通过输出迭代器result输出数据
cout << endl;
}
注意:头文件algorithm中的sort函数的参数必须是随机访问迭代器
迭代器性能(其中i为迭代器,n为整数)
| 迭代器功能 | 输入迭代器 | 输出迭代器 | 正向迭代器 | 双向迭代器 | 随机访问迭代器 |
| 解除引用读取 | 有 |
| 有 | 有 | 有 |
| 解除引用写入 |
| 有 | 有 | 有 | 有 |
| 固定和可重复排序 |
|
| 有 | 有 | 有 |
| ++i i++ |
|
| 有 | 有 | 有 |
| --i i-- |
|
|
| 有 | 有 |
| i[n] |
|
|
|
| 有 |
| i+n |
|
|
|
| 有 |
| i-n |
|
|
|
| 有 |
| i+=n |
|
|
|
| 有 |
| i-=n |
|
|
|
| 有 |
迭代器的区间
并不是任何两个迭代器都能确定一个合法的区间,例如:如果iter1和iter2指向的是不同容器中的元素,或者它们虽然指向同一容器中的元素,但iter1>iter2,[iter1, iter2)就不是一个合法的区间。当且仅当对iter1执行n次(n>=0)“++”运算后,表达式iter1==iter2的值是true,[iter1,iter2)就是一个合法的区间。
迭代器的辅助函数
STL为迭代器提供了两个辅助的函数模板——advance和distance。它们为所有迭代器提供了一些原本只有随机访问迭代器才具有的访问能力:前进或后退多个元素,已经计算两个迭代器之间的距离(相差的元素个数)。
advance函数模板原型:
template<class InputIterator, class Distance>
void advance (InputIterator& iter, Distancen);
对于双向迭代器或随机访问迭代器,n可以取负值,表示让iter后退n个元素。对于一个随机访问迭代器iter,执行advance (iter, n)就相当于执行了iter+=n。
distance函数模板原型:
template<class InputIterator>
unsigned distance (InputIterator first, InputIteratorlast);
它用来计算first经过多少次“++”运算后可以达到last,[first, last)必须是一个有效的区间。若first和last皆为随机访问迭代器,distance(first, last)的值就等于last-first,但调用该函数前必须有[first, last)合法。
迭代器支持的操作
迭代器操作 说明
(1)所有迭代器
p++ 后置自增迭代器
++p 前置自增迭代器
(2)输入迭代器
*p 复引用迭代器,作为右值
p=p1 将一个迭代器赋给另一个迭代器
p==p1 比较迭代器的相等性
p!=p1 比较迭代器的不等性
(3)输出迭代器
*p 复引用迭代器,作为左值
p=p1 将一个迭代器赋给另一个迭代器
(4)正向迭代器
提供输入输出迭代器的所有功能
(5)双向迭代器
--p 前置自减迭代器
p-- 后置自减迭代器
(6)随机迭代器
p+=i 将迭代器递增i位
p-=i 将迭代器递减i位
p+i 在p位加i位后的迭代器
p-i 在p位减i位后的迭代器
p[i] 返回p位元素偏离i位的元素引用
p<p1 如果迭代器p的位置在p1前,返回true,否则返回false
p<=p1 p的位置在p1的前面或同一位置时返回true,否则返回false
p>p1 如果迭代器p的位置在p1后,返回true,否则返回false
p>=p1 p的位置在p1的后面或同一位置时返回true,否则返回false
只有顺序容器和关联容器支持迭代器遍历,各容器支持的迭代器的类别如下:
| 容器 | 支持的迭代器类别 | 容器 | 支持的迭代器类别 |
| vector | 随机访问 | deque | 随机访问 |
| set | 双向 | multiset | 双向 |
| map | 双向 | multimap | 双向 |
| list | 双向 | stack | 不支持 |
| queue | 不支持 | priority_queue | 不支持 |
特殊迭代器
back_insert_iterator
back_insert_iterator只能用于允许在尾部快速插入的容器(快速插入是指一个时间固定的算法),如vector、deque。
front_insert_iterator
front_insert_iterator只能用于允许在开始位置快速插入的容器(快速插入是指一个时间固定的算法),如deque(vector不满足要求)
insert_iterator
insert_iterator没有这些限制。可以用insert_iterator将复制数据的算法转换为插入数据的算法。
总结:这些迭代器将容器类型作为模板参数,将实际的容器标识符作为构造函数参数。
程序实例:
void output(const std::stringstr)
{
std::cout <<str << "***";
}
int main()
{
using namespace std;
string str1[3] = {"Why","What","How"};
string str2[2] = {"Hi", "Hello" };
string str3[2] = {"C", "C++" };
string str4[2] = {"VC 6.0", "Visual Studio 2013" };
vector<string> vStr(3);
copy(str1, str1 + 3, vStr.begin());//vStr的空间必须够插入3个元素
for_each(vStr.begin(), vStr.end(), output);//output作为函数对象参数
cout << endl;
//将容器类型作为模板参数,将实际的容器标识符作为构造函数参数
back_insert_iterator<vector<string> > back_iter(vStr);
copy(str2, str2 + 2, back_iter);
for_each(vStr.begin(), vStr.end(), output); //output作为函数对象参数
cout << endl;
/*//将容器类型作为模板参数,将实际的容器标识符作为构造函数参数
//vector不能使用front_insert_iterator
front_insert_iterator<vector<string> >front_iter(vStr);
copy(str3, str3 + 2, front_iter);
for_each(vStr.begin(), vStr.end(), output);
cout << endl;*/
//将容器类型作为模板参数,将实际的容器标识符作为构造函数参数,同时指定插入位置
//此处在末尾插入,当然也可以在开头或其他位置插入
insert_iterator<vector<string> > insert_iter(vStr, vStr.end());
copy(str4, str4 + 2, insert_iter);
for_each(vStr.begin(), vStr.end(), output); //output作为函数对象参数
cout << endl;
return 0;
}
程序输出:
Why***What***How***
Why***What***How***Hi***Hello***
Why***What***How***Hi***Hello***VC6.0***Visual Studio 2013***
容器
容器的基本功能和分类
STL中各容器头文件和所属概念
| 容器名 | 中文名 | 头文件 | 所属概念 |
| vector | 向量 | <vector> | 随机访问容器,顺序容器 |
| deque | 双端队列 | <deque> | 随机访问容器,顺序容器 |
| list | 列表 | <list> | 可逆容器,顺序容器 |
| set | 集合 | <set> | 可逆容器,关联容器 |
| multiset | 多重集合 | < multiset > | 可逆容器,关联容器 |
| map | 映射 | <map> | 可逆容器,关联容器 |
| multimap | 多重映射 | <multimap> | 可逆容器,关联容器 |
|
|
|
|
|
使用一般容器的begin()和end()成员函数所得到的迭代器都是前向迭代器,也就是说可以对容器的元素进行单向的遍历。而可逆容器所提供的迭代器是双向迭代器,可以对容器的元素进行双向的遍历。事实上,STL提供的标准容器都至少是可逆容器,但有些非标准的模板库诸如slist(单向链表)这样的仅提供前向迭代器的容器。
STL为每个可逆容器提供了逆向迭代器(rbegin()、rend())。
逆向迭代器实际上是普通迭代器的适配器,逆向迭代器的“++”运算被映射为普通迭代器的“--”,逆向迭代器的“--”运算被映射为普通迭代器的“++”。
一个迭代器和它的逆向迭代器之间,可以相互转换。对于可逆容器,存在下列等式:
vector<vector<string> > Matrix;
// reverse_iterator逆向迭代器的构造函数,其参数为普通迭代器
Matrix.rbegin()== vector<vector<string> >::reverse_iterator(Matrix.end())
Matrix.rend()== vector<vector<string> >::reverse_iterator(Matrix.begin())
//base为逆向迭代器的成员函数,普通迭代器没有改成员函数
Matrix.end()== Matrix.rbegin().base()
Matrix.begin()== Matrix.rend().base()
顺序容器
顺序容器在逻辑上可以看作是一个长度可扩展的数组,容器中的元素都线性排列。程序员可以随意决定每个元素在容器中的位置,可以随时向指定位置插入新的元素或删除已有的元素。每种类型的容器都有一个类模板,都具有一个模板参数,表示容器的元素类型,该类型必须符合Assignable这一概念(即具有公有的复制构造函数并可以用“=”赋值)。
列表(list)和双端队列(deque)两个容器支持高效地在容器头部插入新的元素或删除容器头部的元素,但向量容器(vector)不支持。
向量(vector)
向量容器对象已分配的空间所能容纳的元素个数,常常会大于容器的实际有效的元素个数,前者叫做向量容器的容量(capacity),后者叫做向量容器的大小(size)。
例如:
// vector<int> vArray[5];//其功能同普通数组没有区别
vector<int> vArray(5);// vector<int> vArray[5];
cout<< "capacityod vArray = "<< vArray.capacity() << endl; //5
cout<< "sizeod vArray = "<< vArray.size() << endl; //5
vArray.resize(3); //resize设置容器的大小
cout<< "capacityod vArray = "<< vArray.capacity() << endl; //5
cout<< "sizeod vArray = "<< vArray.size() << endl; //3
vArray.reserve(7); //reverse设置容器的容量
cout<< "capacityod vArray = "<< vArray.capacity() << endl; //7
cout<< "sizeod vArray = "<< vArray.size() << endl; //3
vArray.reserve(3); //此语句不起任何作用
cout<< "capacityod vArray = "<< vArray.capacity() << endl; //7
cout<< "sizeod vArray = "<< vArray.size() << endl; //3
注意:capacity只会变大,不会变小,这样可以提高效率。
如果插入操作(包括push_back向末尾加入新元素)引起了向量容量的扩展,那么在执行插入之前所获得的该向量的一切迭代器和指针、引用都会失效(因为空间被重新分配了,元素的内存地址发生了改变);如果插入操作未引起向量容量的扩展,那么只有处于插入位置之后的迭代器和指针、引用会失效(因为这些元素被移动了),对插入位置之前的元素不会有影响。
删除操作不会引起向量容量的改变,因此被删除元素之前的迭代器和指针、引用都能够继续使用,而删除元素之后的迭代器和指针、引用都会失效。所谓“失效”,是指继续使用这样的迭代器或指针、引用,结果是不确定的。
不同的编译环境中的STL库具有不同的实现,一个标准的程序应当只依赖于C++标准而不依赖于对标准的具体实现。
技巧:删除向量容器的元素时,并不会使空闲的空间被释放,这是可以使用下面的语句达到释放多余空间的目的(s表示目的容器,T表示容器的元素类型):
vector<T>(s.begin(),s.end()).swap(s); //删除向量容器的元素后执行该语句
即首先用s的内容创建一个临时的向量容器对象,在将该容器和s交换,这时s原先占有的空间已经属于临时对象,该语句执行完成后临时对象会被析构,空间被释放。
为什么swap函数(STL)不会使迭代器失效?
swap函数仅仅是交换迭代器的值(即指针的值),这样指向原来内存的迭代器自然不会失效。
vector<int> ivec(10,1);
const_iterator:
只能读取容器中的元素,而不能修改。
for(vector<int>::const_iteratorciter=ivec.begin();citer!=ivec.end();citer++)
{
cout<<*citer;
//*citer=3; error
}
vector<int>::const_iterator 和 constvector<int>::iterator的区别
const vector<int>::iteratornewiter=ivec.begin();
*newiter=11; //可以修改指向容器的元素
//newiter++; //迭代器本身不能被修改
创建二维数组
实例1:
constint M = 2;
constint N = 3;
//定义多维数组时,内层“<>”与外层“<>”之间要加空格,避免编译器将其解释为右移运算符。不//加空格,在高版本的编译器上不会出现问题,但是在低版本的编译器上将会出现错误。为了程序的//可移植性,建议最好还是加上空格
vector<vector<int> > vArray(M,vector<int>(N, 1));
for (int i = 0; i<M; i++)
{
for (int j = 0; j<N; j++)
{
cout << vArray[i][j] <<" ";
}
cout << endl;
}
实例2:
vector<vector<double> > matrix;
double array1[5] = { 1, 3, 5, 7, 9 };
vector<double> vec1(array1, array1 + 5);
double array2[5] = { 2, 4, 6, 8, 10 };
vector<double> vec2(array2, array2 + 5);
matrix.push_back(vec1);
matrix.push_back(vec2);
for (int i = 0; i<matrix.size(); i++)
{
for (int j = 0; j<matrix[i].size(); j++)
{
cout << matrix[i][j] <<" ";
}
cout << endl;
}
//迭代器式访问
vector<vector<double> >::iterator it2d;
vector<double>::iterator it1d;
for (it2d = matrix.begin(); it2d != matrix.end(); it2d++)
{
for (it1d = (*it2d).begin(); it1d != (*it2d).end(); it1d++)
{
cout << *it1d <<" ";
}
cout << endl;
}
vector对象型元素的拷贝问题
当vector的元素类型为类类型时,如果直接用类对象作为vector元素类型,将会频繁的调用拷贝构造函数,这样会降低效率。建议用类的对象指针作为vector元素的类型,这样可以提升效率。
程序实例:
classDemo{
public:
char *str;
Demo():str(NULL)
{
cout<<"default construct!"<<endl;
}
Demo(constDemo &d)
{
cout<<"copy construct"<<endl;
this->str=newchar[strlen(d.str)+1];
strcpy(this->str,d.str);
}
~Demo()
{
if(str != NULL)
{
cout<<"~Demo"<<endl;
delete[]str;
}
}
};
Demo d1;
d1.str =new char[10];
strcpy(d1.str,"NavyBlue");
cout << d1.str << endl;
//不建议使用
/*
vector<Demo> a1;
a1.push_back(d1);
cout<<(a1.front()).str<<endl;
*/
//建议写法
vector<Demo*> a1;
a1.push_back(&d1);
cout << (a1.front())->str <<endl;
双端队列(deque)
双端队列是一种支持向两端高效地插入数据、支持随机访问的容器。双端队列的内部实现不如向量容器那样直观,在很多的STL的实现中,双端队列的数据被表示为一个分段数组,容器中的元素分段存放在一个个大小固定的数组中,此外容器还需要维护一个存放这些数组首地址的索引数组。
执行向两端插入元素的操作时,会是索引的迭代器失效,但是不会使任何指向已有元素的指针、引用失效。指针和引用不会失效的原因是向两端插入元素不会改变已有元素在分段数组中的位置,而迭代器之所以会失效,是因为向两端插入新元素可能会引起索引数组中已有元素位置的改变(例如索引数组被重新分配),而迭代器需要依赖索引数组。
deque不支持capacity
列表(list)
列表中插入和删除元素的效率很高,插入时不会使任何已有元素的迭代器和指针、引用失效;删除时只会使指向被删除元素的迭代器和指针、引用失效,而不会影响其他迭代器和指针、引用。
列表容器还支持一种特殊的操作——接合(splice)
执行接合操作时,原先指向被接入元素的迭代器和指针、引用都会失效,其他迭代器和指针、引用不会受影响。
list常用函数
unique
unique:相邻重复元素只保留一个
int nArray[] = { 3, 3, 5, 3, 7 };
list<int> L1(nArray, nArray + 5);
L1.unique();//L1{3, 5, 3, 7}相邻重复元素只保留一个
此外,unique可以指定函数对象
template<class T>
bool almost_equal(const T& el1, const T&el2)//必须是两个参数,返回类型必须是bool类型
{
//相邻元素差的绝对值小于等于0.1返回true
return(fabs(double(el1 - el2)) <= 0.1) ? true : false;
}
double array[10] = {3.45, 3.455, 67, 0.67,8.99, 9.0, 9.01, 34.677, 100.67, 19.25};
list<double> lst(array, array + 10);
//相邻元素差的绝对值小于等于0.1的元素只保留一个(第一个)
lst.unique(almost_equal<double>);//lst{ 3.45, 67, 0.67, 8.99, 34.677, 100.67 ,19.25 }
remove
remove:删除所有与给定值相同的元素
remove_if
//奇数
bool is_odd(int& n)//必须是一个参数,返回值必须是bool类型
{
return( n % 2 ) == 1;
}
int nArray[] = {1,2,3,8,9,3,4,2,3};
int nSize =sizeof(nArray)/sizeof(nArray[0]);
list<int> list1;
list1.assign(nArray,nArray+nSize);//调用赋值函数初始化
list1.remove_if(is_odd);//list1 {2, 8, 4,2} 删除list1中所有的奇数
splice
insert和splice之间的区别:insert将原来区间的副本插入到目标地址,而splice则将原始区间移到目标地址。
merge
将两个链表合并,两个链表必须已经排序。
forward_list
forward_list单链表,是不可反转的容器,只需正向迭代器,而不需要双向迭代器。
vector与list区别
vector为存储的对象分配一块连续的地址空间,因此对vector中的元素随机访问效率很高。在vecotor中插入或者删除某个元素,需要将现有元素进行复制,移动。如果vector中存储的对象很大,或者构造函数复杂,则在对现有元素进行拷贝时开销较大,因为拷贝对象要调用拷贝构造函数。对于简单的小对象,vector的效率优于list。vector在每次扩张容量的时候,将容量扩展2倍,这样对于小对象来说,效率是很高的。
list中的对象是离散存储的,随机访问某个元素需要遍历list。在list中插入元素,尤其是在首尾插入元素,效率很高,只需要改变元素的指针。
综上所述:
vector适用:对象数量变化少,简单对象,随机访问元素频繁
list适用:对象数量变化大,对象复杂,插入和删除频繁
最大的区别是,list是双向的,而vector是单向的。
因此在实际使用时,如何选择这三个容器中哪一个,应根据你的需要而定,一般应遵循下面的原则:
1、如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
2、如果你需要大量的插入和删除,而不关心随即存取,则应使用list
3、如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque。
vector表示一段连续的内存区域,每个元素被顺序存储在这段内存中,对vector 的随机访问效率很高,但对非末尾元素的插入和删除则效率非常低。
deque也表示一段连续的内存区域,但与vector不同的是它支持高效地在其首部插入和删除元素,它通过两级数组结构来实现,一级表示实际的容器,第二级指向容器的首和尾
list表示非连续的内存区域并通过一对指向首尾元素的指针双向链接起来,插入删除效率高,随机访问效率低。
stl提供了三个最基本的容器:vector,list,deque。
vector和built-in数组类似,它拥有一段连续的内存空间,并且起始地址不变,因此它能非常好的支持随即存取,即[]操作符,但由于它的内存空间是连续的,所以在中间进行插入和删除会造成内存块的拷贝,另外,当该数组后的内存空间不够时,需要重新申请一块足够大的内存并进行内存的拷贝。这些都大大影响了vector的效率。
list就是数据结构中的双向链表(根据sgi stl源代码),因此它的内存空间可以是不连续的,通过指针来进行数据的访问,这个特点使得它的随即存取变的非常没有效率,因此它
没有提供[]操作符的重载。但由于链表的特点,它可以以很好的效率支持任意地方的删除 和插入。
deque是一个double-ended queue,它的具体实现不太清楚,但知道它具有以下两个特点:
它支持[]操作符,也就是支持随即存取,并且和vector的效率相差无几,它支持在两端的操作:push_back,push_front,pop_back,pop_front等,并且在两端操作上与list的效率也差不多。
因此在实际使用时,如何选择这三个容器中哪一个,应根据你的需要而定,一般应遵循下面的原则:
1、如果你需要高效的随即存取,而不在乎插入和删除的效率,使用vector
2、如果你需要大量的插入和删除,而不关心随即存取,则应使用list
3、如果你需要随即存取,而且关心两端数据的插入和删除,则应使用deque。
顺序容器的适配器
容器适配器不支持迭代器,因为它们不允许对任意元素进行访问。
string类事实上也是一种随机访问容器,因此也可以使用迭代器对它进行遍历。
栈(stack)
栈(stack) <stack> 默认的底层类为deque
后进先出的值的排列 <stack>
定义一个stack的变量stack<int> s;
入栈,如例:s.push(x);
出栈,如例:s.pop();注意,出栈操作只是删除栈顶元素,并不返回该元素。
访问栈顶,如例:s.top()
判断栈空,如例:s.empty(),当栈空时,返回true。
访问栈中的元素个数,如例:s.size()
队列(queue)
queue默认的底层类为deque
优先级队列(priority_queue)
priority_queue默认的底层类为vector
优先级队列必须是支持随机访问的顺序容器,因此它必须是向量容器或双端队列容器,默认为向量容器。
优先级队列支持元素的压入和弹出,每次弹出的总是容器中最“大”的一个元素。
当容器的元素类型是类、结构体这样的符合数据类型时,“<”运算符必须有定义,优先级队列在默认情况下就是根据“<”运算符来决定元素的大小。
priority_queue<int> priq1; //默认从大到小排序
priority_queue<int>priq2(greater<int>); //设置从小到大排序
关联容器
关联容器的分类和基本功能
对于关联容器而言,它的每个元素都有一个键值(key),容器中元素的顺序按照键的取值升序排列。关联容器的最大优势在于,可以高效的根据键值来查找容器中的元素。关联容器会将元素根据键值的大小组织在一棵“平衡二叉树”中,最坏情况下需要次比较就可以根据键值来查找一个元素。而顺序容器最坏需要n次比较。
4种关联容器所属的概念
| 类型 | 简单关联容器 | 二元关联容器 |
| 单重关联容器 | 集合(set) | 映射(map) |
| 多重关联容器 | 多重集合(multiset) | 多重映射(multimap) |
|
|
|
|
单重关联容器中的键值是唯一的,不允许重复。
多重关联容器中,相同的键值允许重复出现。
简单关联容器只有一个类型参数,该类型既是键类型,又是容器类型。
例如:set<int>、multiset<string>
二元关联容器则有两个类型参数,前一个是键类型,后一个是附加数据的类型。
例如:map<int, double>、multimap<string, int>
二元关联容器的元素类型是键类型和附加数据类型的组合。
注意:关联容器的键之间必须能够使用“<”比较大小。如果键的类型是类类型,则需要重载“<”运算符。
细节:重载“<”运算符必须满足以下几条性质
①非自反性:对任何对象x,x<x必须返回false
②“<”传递性:若x<y和y<z皆返回true,则x<z必须返回true
③“==”传递性:把x==y定义为!(x<y)&&!(y<x),那么若x==y和y==z皆为true,那么x==z必须为true
集合(set)
集合用来存储一组无重复的元素。由于集合的元素本身是有序的,因此可以高效的查找指定元素,也可以方便地得到指定大小范围的元素在容器中所处的区间。
关联集合将键看作常量。
程序实例:
int nArray1[] = { 3, 7, 5, 11, 9, 2 };
int nArray2[] = { 21, 89, 34, 2, 5, 90, 12 };
int nSize1 = sizeof(nArray1) / sizeof(nArray1[0]);
int nSize2 = sizeof(nArray2) / sizeof(nArray2[0]);
set<int> s1(nArray1, nArray1 + nSize1);//初始化
set<int> s2(nArray2, nArray2 + nSize2); //初始化
copy(s1.begin(), s1.end(),ostream_iterator<int>(cout," "));
cout << endl;// 2 3 5 7 9 11
copy(s2.begin(), s2.end(),ostream_iterator<int>(cout," "));
cout << endl;// 2 5 12 21 34 89 90
set<int> s3;
//set_union(s1.begin(), s1.end(), s2.begin(), s2.end(),insert_iterator<set<int> >(s3, s3.begin()));//s3 = s1 s2
//set_intersection(s1.begin(), s1.end(), s2.begin(),s2.end(), insert_iterator<set<int> >(s3, s3.begin()));//s3 = s1 s2
//set_difference(s1.begin(), s1.end(), s2.begin(),s2.end(), insert_iterator<set<int> >(s3, s3.begin()));//s3 = s1 s2
set_difference(s2.begin(), s2.end(),s1.begin(), s1.end(),insert_iterator<set<int> >(s3, s3.begin()));//s3 = s2 s1
copy(s3.begin(), s3.end(),ostream_iterator<int>(cout," "));
cout << endl;// 12 21 34 89 90
copy(s3.lower_bound(11), s3.upper_bound(34),ostream_iterator<int>(cout," "));
cout << endl;// 11 12 21 34
copy(s3.lower_bound(10), s3.upper_bound(30),ostream_iterator<int>(cout," "));
cout << endl;// 1112 21
注意:set_union、set_intersection、set_difference
由于关联集合将键看作常量,所以s3.begin()返回的是常迭代器,不能用作输出迭代器,所以最后一个参数不能直接使用s3.begin()。此外,插入要求容器有足够的空间,而insert_iterator可以分配空间,不用事先给容器分配足够的空间。
lower_bound和upper_bound都以键值作为参数,返回迭代器。lower_bound返回不小于键值的第一个数的迭代器,upper_bound返回大于键值的第一个数的迭代器。
映射(map)
通常使用make_pair函数来构造二元组,它是<utility>中定义的一个专用于辅助二元组构造的函数模板:
template<classT1,classT2>
pair<T1,T2> make_pair(T1v1,T2v2){return pair<T1,T2>(v1,v2); }
表达式“map1[key]”所执行的操作是,在map1中查找键值为key的元素,如果存在,则返回它的附加数据的引用,如果不存在,则向map1中插入一个新元素并返回该元素附加数据的引用,该附加数据的初值为T()(如:int()),其中T是附加数据的类型。
因为“[]”会为新键自动创建新元素,因而用它无法判断容器中是否有具有指定键值的元素。
multiset和multimap
多重集合是允许有重复元素的集合,多重映射是允许一个键对应多个附加数据的映射。由于一个键可能对应多个附加数据,因此使用find成员函数得到的迭代器所指向的位置具是不确定性,一般只在确定一个键在容器中是否存在时才使用find成员函数。如果需要访问一个键对应的所有附加数据,可以使用equal_range成员函数。如果需要得到一个键所对应附加数据的个数,可以使用count成员函数。映射所支持的“[]”运算符不被多重映射所支持,原因是一个键不能对应一个唯一的附加数据。
函数对象
所谓函数对象其实就是一个行为类似函数的对象,它可以不需参数,也可以带有若干参数,其功能是获取一个值,或改变操作的状态。在C++程序设计中,任何普通的函数和任何重载了调用运算符operator()的类的对象都满足函数对象的特征。使用类的形式定义的函数对象能够比普通函数携带更多的额外信息。
产生器(generator)、一元函数(unary function)和二元函数(binaryfunction)
将具有0个、1个和2个传入参数的函数对象,分别称为产生器(generator)、一元函数(unary function)和二元函数(binary function)。
调用标准函数对象,需要包含头文件<functional>。标准函数对象是内联函数。
find和find_if
find
template<class InputIterator, class T>
InputIterator find ( InputIterator first,
InputIterator last,
const T& value
)
{
for ( ;first!=last; first++) if ( *first==value ) break;
//返回的是查找的value在容器中的迭代器,如果找不到,返回last
return first;
}
程序实例(find):
vector<string> vArray;
vArray.push_back("Hello");
vArray.push_back("like");
vector<string>::iterator result;
//find
result = find(vArray.begin(), vArray.end(), "Helo");
if (result != vArray.end())
{
cout << "Finded = " << *result<< endl;
}
else
{
cout << "Not Finded" << endl;
}
输出:Not Finded
find_if
template<class InputIterator, class Predicate>
InputIterator find_if ( InputIterator first, InputIterator last, Predicate pred )
{
for ( ; first!=last ; first++ ) if ( pred(*first) ) break;
return first;
}
程序实例(find_if):
bool IsOdd (int i) {
return ((i%2)==1);
}
vector<int> myvector;
vector<int>::iterator it;
myvector.push_back(10);
myvector.push_back(25);
myvector.push_back(40);
myvector.push_back(55);
it = find_if (myvector.begin(), myvector.end(), IsOdd);
cout << "The first odd value is " << *it << endl;//25
输出:The first odd value is 25
foreach
自定义的foreach
这里用到两个技巧:
1,for循环的第一条语句可以声明局部变量;
2,充分利用for循环的过程控制能力。
宏中定义了三重for循环。第一重的意义很清楚:使用容器的遍历者遍历容器中的元素。第二、第三重for循环其实只能执行一次,其主要目的是声明elem变量。C++的变量引用类型使后面的元素访问代码块可以直接使用elem变量。
#define foreach(ElementType, elem, ContainerType,container)\
for(ContainerType::iterator iter =container.begin();iter!=container.end();++iter)\
for(bool go =true;go;)\
for(ElementType elem = (*iter);go;go = false)
double array2[5] = { 2, 4,6, 8, 10 };
vector<double> vec2(array2,array2 + 5);
foreach(double, var,vector<double>, vec2)
{
cout << var << " ";
}
cout<< endl;
其实C++也有自己的foreach,这里只是自己试着玩玩而已。
for each
for each (object varin collection_to_loop)
object:集合中要访问的对象类型,如果写auto编译器会通过collection_to_loop推测类型
var:表示集合中对象的标示符
in:表示在collection_to_loop中
collection_to_loop:要循环访问的集合或数组的名称
下列语句功能同自己定义的宏定义功能一样
//vec2数组:double vec2[]
for each (double varin vec2)
{
cout << var << " ";
}
cout<< endl;
for each (auto varin vec2)//编译器会通过vec2推测出var的类型
{
cout << var << " ";
}
cout<< endl;
for_each
for_each(参数1, 参数2, 参数3)
参数1:开始迭代器
参数2:结束迭代器
参数3:函数对象
template<classT>
void show(constT& ref)
{
cout << "(" << ref.X << ", " << ref.Y << ")" << endl;
}
template<classT>
class Test
{
public:
void operator ()(constT&ref)
{
cout << "(" << ref.X << ", " << ref.Y << ")" << endl;
}
};
//vpArray数组:vector<Point>
//for_each(vpArray.begin(),vpArray.end(), show<Point<int> >);
for_each(vpArray.begin(),vpArray.end(), Test<Point<int> >());
基于范围的for循环
for的使用类似于for each,只是将in换成了“:”而已
template<classT>
void show(constT& ref)
{
cout << "(" << ref.X << ", " << ref.Y << ")" << endl;
}
template<classT>
class Test
{
public:
void operator ()(constT&ref)
{
cout << "(" << ref.X << ", " << ref.Y << ")" << endl;
}
};
//vpArray数组:vector<Point>
for (auto var: vpArray) //编译器会通过vpArray推测出x的类型
{
Test<Point<int> >()(var);
}
for (auto x : vpArray)//编译器会通过vpArray推测出x的类型
show(x);
注意:基于范围的for和for each可以修改容器的内容,只需在参数(var或x)前加引用即可,而for_each不能更改容器的内容(即使函数参数为引用类型,修改的也是临时对象的值)。作为一种编程风格,最好避免直接使用迭代器,而应尽可能使用STL函数(如:for_each())或C++11新增的基于范围的for循环。
string类
构造字符串
构造函数string (initializer_list<char> il)让string类支持列表初始化语法:
string str1 = {"Hello"};
string str2 = { 'H', 'e', 'l', 'l', 'o'};
string str3 { "Hello" };
string str4 { 'H', 'e', 'l', 'l', 'o' };
cout << str1 << endl; // Hello
cout << str2 << endl; // Hello
cout << str3 << endl; // Hello
cout << str4 << endl; // Hello
string类输入
string字符串和C风格字符串
string str; //string字符串
char cstr[20]; //C风格字符串
cin >> str; //以回车为结束符
cin >> cstr; //以回车为结束符
cin.getline(cstr, 20);//最多接收19个字符,最后一个字节存放‘\0’
cin.getline(cstr,',');//第二个参数指定输入结束符,不能省略
getline(cin, str, ',');//第三个参数指定输入结束符,可以省略,默认以回车为结束符
注意:当使用getline输入字符串时,C风格字符串是以cin作为对象来调用getline函数,而string字符串是将cin作为getline函数的参数。cin处参数也可以是文件对象。
string类使用注意事项
open()函数参数为一个C风格字符串,可以通过c_str()方法返回一个指向C风格字符串的指针。
例如:
string filename;
getline(cin, filename);
ofstream fout;
fout.open(filename.c_str());
字符串种类
typedef basic_string<char> string;
typedef basic_string<wchar_t>wstring;
typedef basic_string<char16_t>u16string;//C++11
typedef basic_string<char32_t>u32string;//C++11
C++11新特性
声明:auto、decltype、返回类型后置、模板别名(using=)、nullptr
auto:auto实际上实在编译时对变量进行了类型推导,所以不会对程序的运行效率造成不良影响。另外,似乎auto并不会影响编译速度,因为编译时本来也要右侧推导然后判断与左侧是否匹配。在模板中也是大显身手,可以减少模板参数。
decltype:decltype实际上有点像auto的反函数,auto可以让你声明一个变量,而decltype则可以从一个变量或表达式中得到类型。(intx=3; decltype(x) y=x;)
nullptr:nullptr是为了解决原来C++中NULL的二义性问题而引进的一种新的类型,因为NULL实际上代表的是0。
智能指针:auto_ptr、unique_ptr、shared_ptr、weak_ptr
异常规范方面的修改:noexcept
作用域内枚举:enumclass(struct) NEW{YES,NO,MEYBE}; NEW::NO;//使用枚举常量
新的类功能:移动构造函数(&&)、移动赋值运算符(&&)、默认方法和禁用方法(default和delete)、委托构造函数、继承构造函数、管理虚方法(override和final)
Lambda

①Lambda表达式的引入标志,在”[]”里面可以填入”=”或”&”表示该lambda表达式“捕获”(lambda表达式在一定的scope可以访问的数据)的数据时以什么方式捕获的,‘&’表示以引用的方式;”=”表明以值传递的方式捕获。([&]和[=]捕获所有变量)。封闭函数局部变量不能在lambda体中使用,除非其位于捕获列表中(全局变量可直接使用,默认值传递)。
[&index](doublex)mutable ->double{ //只捕获index,如要捕获多个变量,中间用逗号隔开即可。
index += 10; // change original value
return index*x*x*x;});
②参数列表(lambda的参数列表不允许指定形参的默认值,并且参数列表的长度是不可变的)
③Mutable标识(“=”与按值传递实参根本不同,变量的值可用在lambda中,但不能更新变量的副本,若要修改变量的临时副本,则通过添加mutable关键字实现)
④异常标识(如果要包含mutable说明和throw()说明,则中间必须用一个或多个空格隔开)
⑤返回值(在函数体前指定或通过return判断,否则为void)
⑥“函数”体,也就是lambda表达式需要进行的实际操作
intm = [](int x){ return [](int y) { return y * 2; }(x) + 3; }(5);//m=13
Lambda表达式的包装
Lambda表达式的包装实际上是使用function< >模板赋予lambda表达式一个名字,这不仅提供了在Lambda表达式内递归的可能,而且可以再多条语句使用同样的lambda表达式。(注意:auto只能满足第二条,使用auto类型声明符声明的变量不能出现在其自身的初始值设定项中)
//利用辗转相除法求两个数的最大公约数
function<int(int,int)> hcf = [&](int m, int n) mutable ->int{ if(m < n) return hcf(n,m);
int remainder(m%n);
if(0 == remainder) return n;
return hcf(n, remainder);};
cout << hcf(48, 60) << endl;//12
可变参数模板:模板参数包、函数参数包、展开参数包、递归
#include<iostream>
#include<functional>
#include<string>
usingnamespace std;
//递归出口
template <typenameT>
void show_list(constT&value)
{
cout <<value << endl;
}
template <typenameT,typename...type>//模板参数包
void show_list(constT&value,const type&...args)//函数参数包
{//每次从包中取出一个参数,使下一次递归少一个参数,直到递归结束
cout <<value << ", ";
show_list(args...);//展开参数包
}
int main()
{
show_list(2, 2.0,'*',"hello",string("world"));
return 0;
}
C++11新特性我就做个引子,让初学C++的小伙伴们知道有哪些新特性,具体细节的学习因人而异,希望对大家学习C++编程有一点小小的帮助。由于博主也是个初级软件开发者,如有什么遗漏的地方还望大家谅解,欢迎大家来拍砖,哈哈……















 174
174

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









