







1、Java中常用的数据结构有哪些?
2、JVM熟不熟?简单说说类的加载过程,里面执行了哪些操作?
3、IO 与 NIO 的区别,阻塞与非阻塞的区别?
4、接口如何处理重复的请求?具体的处理方案?
5、线程池的构造类方法的5个参数的具体意义?
--------------------------------------------------------------------------------------------------------------------------------------------------
1、java中常用的数据结构
java数据结构有:
堆、栈、树、图、队列、数组、链表、散列表
常用的有:
| 数组 | List接口(有序可重复) 下 有ArrayList、Vector、LinkedList 实现类,其中 ArrayList、Vector底层数据结构是数组,查询快,增删慢; ArrayList线程不安全效率高,Vector线程安全效率低。 |
| 链表,哈希表(散列表)
哈希表可以说就是数组链表,底层还是数组但是这个数组每一项就是一个链表
| LinkedList底层数据结构是 链表,查询慢,增删快,线程不安全效率高;
Set接口(无序唯一) 下有HashSet、TreeSet、LinkedHashSet 实现类,其中 HashSet 底层数据结构是 哈希表; 哈希表依赖两个方法:hashCode() 和 equals() 执行顺序: 首先判断hashCode()值是否相同 是:继续执行equals(),看返回值为 true,说明元素重复,不添加 false,直接添加到集合 否:自动生成hashCode()和equals() LinkedHashSet 底层数据结构由链表和哈希表组成,其中 链表保证元素有序,哈希表保证元素唯一;
Map接口(双列集合) 下有 HashMap、HashTable、LinkedHashMap、TreeMap 实现类,其中 HashMap、HashTable底层数据结构是哈希表; HashMap线程不安全效率高,HashTable线程安全效率低 LinkedHashMap底层数据结构由链表和哈希表组成; 链表保证元素有序,哈希表保证元素唯一; |
| 树 | TreeSet ,TreeMap 底层数据结构是红黑树(一种自平衡二叉树) |
2、类加载的过程
类加载机制:JVM把class文件加载到内存,并对数据进行校验、解析和初始化,最终形成JVM可以直接使用的java类型的全过程;
类从被加载到JVM中开始,到卸载为止,整个生命周期包括:加载、验证、准备、解析、初始化、使用和卸载七个阶段;
其中类加载过程包括加载、验证、准备、解析和初始化五个阶段;

加载:将class文件字节码内容加载到内存中,并将这些静态数据转换成方法区中的运行时数据结构,在堆中生成一个代表这个类的java.lang.Class对象,作为方法区类数据的访问入口,这个过程需要类加载器参与。
类加载器负责根据一个类的全限定名来读取此类的二进制字节流到JVM内部,并存储在运行时内存区的方法区,然后将其转换为一个与目标类型对应的java.lang.Class对象实例(Java虚拟机规范并没有明确要求一定要存储在堆区中,只是hotspot选择将Class对戏那个存储在方法区中),这个Class对象在日后就会作为方法区中该类的各种数据的访问入口。
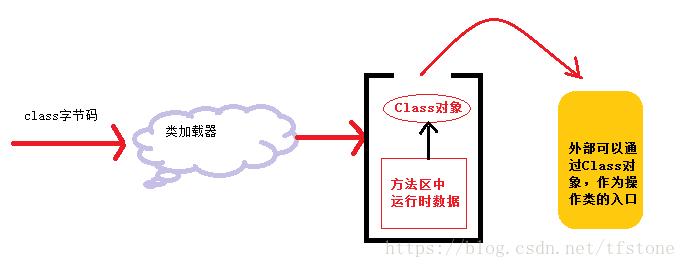
链接(连接):将java类的二进制代码合并到JVM的运行状态之中的过程
- 验证:确保加载的类信息符合JVM规范,没有安全方面的问题(一般情况由javac编译的class文件是不会有问题的,但是可能有人的class文件是自己通过其他方式编译出来的,这就很有可能不符合jvm的编译规则);
- 准备:正式为类变量(static 变量) 分配内存并设置类变量初始值的阶段,这些内存都会在方法区中进行分配;
- 解析:虚拟机常量池的 符号引用 替换为 直接引用 过程
符号引用和直接引用
(比如在方法A中使用方法B,A(){B();},这里的B()就是符号引用,初学java时我们都是知道这是java的引用,以为B指向B方法的内存地址,但是这是不完整的,这里的B只是一个符号引用,它对于方法的调用没有太多的实际意义,可以这么认为,他就是给程序员看的一个标志,让程序员知道,这个方法可以这么调用,但是B方法实际调用时是通过一个指针指向B方法的内存地址,这个指针才是真正负责方法调用,它就是直接引用。)
初始化:为类的静态变量赋予正确的初始值,准备阶段为静态变量赋予的是虚拟机默认的初始值,此处赋予的才是程序编写者为变量分配的真正初始值
(初始化阶段是执行类构造器<clinit>()方法的过程,<clinit>()方法是由编译器自动收藏类中的所有类变量的赋值动作和静态代码块中的语句合并产生的;当初始化一个类的时候,如果发现其父类还没有进行过初始化,则需要先触发其父类的初始化;虚拟机会保证一个类的<clinit>()方法在多线程环境中被正确加锁和同步;当范围一个Java类的静态域时,只有真正声名这个域的类才会被初始化)
3、IO、NIO
| IO | NIO |
| 面向流 (stream oriented) | 面向缓冲 (buffer oriented) |
| 阻塞IO (Blocking IO) | 非阻塞IO (Non Blocking IO) |
|
| 选择器 (Selectors) |
NIO vs IO之间的理念上的区别(NIO将阻塞交给了后台线程执行)
- IO是面向流的,NIO是面向缓冲区的
- Java IO面向流意味着每次从流中读一个或多个字节,直至读取所有字节,它们没有被缓存在任何地方;
- NIO则能前后移动流中的数据,因为是面向缓冲区的
- IO流是阻塞的,NIO流是不阻塞的(异步IO)
- Java IO的各种流是阻塞的。这意味着,当一个线程调用read() 或 write()时,该线程被阻塞,直到有一些数据被读取,或数据完全写入。该线程在此期间不能再干任何事情了
- Java NIO的非阻塞模式,使一个线程从某通道发送请求读取数据,但是它仅能得到目前可用的数据,如果目前没有数据可用时,就什么都不会获取。NIO可让您只使用一个(或几个)单线程管理多个通道(网络连接或文件),但付出的代价是解析数据可能会比从一个阻塞流中读取数据更复杂。 非阻塞写也是如此。一个线程请求写入一些数据到某通道,但不需要等待它完全写入,这个线程同时可以去做别的事情。
- 选择器
Java NIO的选择器允许一个单独的线程来监视多个输入通道,你可以注册多个通道使用一个选择器,然后使用一个单独的线程来“选择”通道:这些通道里已经有可以处理的输入,或者选择已准备写入的通道。这种选择机制,使得一个单独的线程很容易来管理多个通道。
4、接口如何处理重复的请求?
| 前端限制 | 前端限制就是当点击了提交按钮之后,就给按钮添加属性disabled,然后等后台返回提交信息之后再将disabled移除掉 (不推荐,js代码很容易被绕过。比如用户通过刷新页面方式,或使用postman等工具绕过前段页面仍能重复提交表单) |
| Token令牌防止重复请求 | 当客户端请求页面时,服务器会生成一个随机数Token,并且将Token放置到session当中,然后将Token发给客户端(一般通过构造hidden表单)。下次客户端提交请求时,Token会随着表单一起提交到服务器端。 服务器端第一次验证相同过后,会将session中的Token值更新下(删除),若用户重复提交,第二次的验证判断将失败(服务器token为空),因为用户提交的表单中的Token没变,但服务器端session中Token已经改变了。 |
| Redis加锁防止重复请求 | 待补充。。 |
5、线程池构造类方法5个参数的具体意义?
Java中的线程池用ThreadPoolExecutor类来表示,这个类继承自抽象类AbstractExecutorService,AbstractExecutorService又实现了ExecutorService接口,ExecutorService接口又继承了Executor接口。
在ThreadPoolExecutor类中提供了四个构造方法:
public class ThreadPoolExecutor extends AbstractExecutorService {
.....
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,RejectedExecutionHandler handler);
public ThreadPoolExecutor(int corePoolSize,int maximumPoolSize,long keepAliveTime,TimeUnit unit, BlockingQueue<Runnable> workQueue,ThreadFactory threadFactory,RejectedExecutionHandler handler);
…
}事实上,通过观察每个构造器的源码具体实现,发现前面三个构造器都是调用的第四个构造器进行的初始化工作。
| corePoolSize | 核心线程数,核心线程会一直存活,即使没有任务需要处理(核心线程在allowCoreThreadTimeout被设置为true时会超时退出,默认情况下不会退出);
|
| maximumPoolSize | 最大线程数,线程池中最多能创建多少个线程;
|
| keepAliveTime | 空闲时存活时间,线程空闲时间达到keepAliveTime,该线程会退出,直到线程数量等于corePoolSize
|
| unit | keepAliveTime的时间单位, 有7种取值,在TimeUnit类下 :DAYS、HOURS、MINUTES、SECONDS、MILLISECONDS、MICROSECONDS、MANOSECONDS(纳秒) |
| workQueue | 存储等待任务的阻塞队列,有3种选择:
|














 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









