






目录
4、spring单例为什么没有安全问题(ThreadLocal)
多线程篇
1、可以运行时kill掉一个线程吗?
1、不可以,线程有 5 种状态,新建( new )、可运⾏( runnable )、运⾏中( running )、阻塞( block )、死亡(dead )。2、 只有当线程 run ⽅法或者主线程 main ⽅法结束,⼜或者抛出异常时,线程才会结束⽣命周期。
2、关于synchronized
1. 在某个对象的所有 synchronized ⽅法中 , 在某个时刻只能有⼀个唯⼀的⼀个线程去访问这些 synchronized ⽅法2. 如果⼀个⽅法是 synchronized ⽅法 , 那么该 synchronized 关键字表示给当前对象上锁 ( 即 this) 相当于synchronized(this){}3. 如果⼀个 synchronized ⽅法是 static 的 , 那么该 synchronized 表示给当前对象所对应的 class 对象上锁 ( 每个类不管⽣成多少对象, 其对应的 class 对象只有⼀个 )
3、分布式锁,程序数据库中死锁机制及解决方案
基本原理:用一个状态值表示锁,对锁的占用和释放通过状态值来标识。
1
、三种分布式锁:
Zookeeper:基于zookeeper瞬时有序节点实现的分布式锁,其主要逻辑如下。⼤致思想即为:每个客户端对某个功能加锁时,在zookeeper上的与该功能对应的指定节点的⽬录下,⽣成⼀个唯⼀的瞬时有序节点。判断是否获取锁的⽅式很简单,只需要判断有序节点中序号最⼩的⼀个。当释放锁的时候,只需将这个瞬时节点删除即可。同时,其可以避免服务宕机导致的锁⽆法释放,⽽产⽣的死锁问题。
对可靠性要求⾮常⾼,且并发程度不⾼的场景下使⽤。如核⼼数据的定时全量 / 增量同步等。

memcached : memcached 带有 add 函数,利⽤ add 函数的特性即可实现分布式锁。 add 和 set 的区别在于:如果多线程并发set ,则每个 set 都会成功,但最后存储的值以最后的 set 的线程为准。⽽ add 的话则相反, add 会添加第⼀个到达的值,并返回true ,后续的添加则都会返回 false 。利⽤该点即可很轻松地实现分布式锁。
- 优点
并发⾼效- 缺点
memcached采⽤列⼊LRU置换策略,所以如果内存不够,可能导致缓存中的锁信息丢失。 memcached⽆法持久化,⼀旦重启,将导致信息丢失。- 使⽤场景
⾼并发场景。需要 1)加上超时时间避免死锁; 2)提供⾜够⽀撑锁服务的内存空间; 3)稳定的集群化管理。
redis : redis 分布式锁即可以结合 zk 分布式锁锁⾼度安全和 memcached 并发场景下效率很好的优点,其实现⽅式和memcached类似,采⽤ setnx 即可实现。需要注意的是,这⾥的 redis 也需要设置超时时间,以避免死锁。可以利⽤ jedis 客户端实现。ICacheKey cacheKey = new ConcurrentCacheKey(key, type); return RedisDao.setnx(cacheKey, "1");
2、数据库死锁机制和解决⽅案:
- 死锁:死锁是指两个或者两个以上的事务在执⾏过程中,因争夺锁资源⽽造成的⼀种互相等待的现象。
- 处理机制:解决死锁最有⽤最简单的⽅法是不要有等待,将任何等待都转化为回滚,并且事务重新开始。但是有可能影响并发性能。
1、超时回滚,innodb_lock_wait_time设置超时时间;
2、wait-for-graph⽅法:跟超时回滚⽐起来,这是⼀种更加主动的死锁检测⽅式。InnoDB引擎也采⽤这种⽅式。
4、spring单例为什么没有安全问题(ThreadLocal)
1 、 ThreadLocal : spring 使⽤ ThreadLocal 解决线程安全问题; ThreadLocal 会为每⼀个线程提供⼀个独⽴的变量副本,从⽽隔离了多个线程对数据的访问冲突。因为每⼀个线程都拥有⾃⼰的变量副本,从⽽也就没有必要对该变量进⾏同步了。ThreadLocal 提供了线程安全的共享对象,在编写多线程代码时,可以把不安全的变量封装进 ThreadLocal 。概括起来说,对于多线程资源共享的问题,同步机制采⽤了“ 以时间换空间 ” 的⽅式,⽽ ThreadLocal 采⽤了 “ 以空间换时间 ” 的⽅式。前者仅提供⼀份变量,让不同的线程排队访问,⽽后者为每⼀个线程都提供了⼀份变量,因此可以同时访问⽽互不影响。在很多情况下,ThreadLocal⽐直接使⽤ synchronized 同步机制解决线程安全问题更简单,更⽅便,且结果程序拥有更⾼的并发性。2 、单例:⽆状态的 Bean( ⽆状态就是⼀次操作,不能保存数据。⽆状态对象 (Stateless Bean) ,就是没有实例变量的对象,不能保存数据,是不变类,是线程安全的。) 适合⽤不变模式,技术就是单例模式,这样可以共享实例,提⾼性能。
5、线程池原理
1 、使⽤场景:假设⼀个服务器完成⼀项任务所需时间为: T1- 创建线程时间, T2- 在线程中执⾏任务的时间, T3- 销毁线程时间。如果T1+T3 远⼤于 T2 ,则可以使⽤线程池,以提⾼服务器性能;2 、组成:
- 线程池管理器(ThreadPool):⽤于创建并管理线程池,包括 创建线程池,销毁线程池,添加新任务;
- ⼯作线程(PoolWorker):线程池中线程,在没有任务时处于等待状态,可以循环的执⾏任务;
- 任务接⼝(Task):每个任务必须实现的接⼝,以供⼯作线程调度任务的执⾏,它主要规定了任务的⼊⼝,任务执⾏完后的收尾⼯作,任务的执⾏状态等;
- 任务队列(taskQueue):⽤于存放没有处理的任务。提供⼀种缓冲机制。
3、原理:线程池技术正是关注如何缩短或调整 T1,T3 时间的技术,从⽽提⾼服务器程序性能的。它把 T1 , T3 分别安排在服务器程序的启动和结束的时间段或者⼀些空闲的时间段,这样在服务器程序处理客户请求时,不会有T1 , T3 的开销了。4、⼯作流程:
- 线程池刚创建时,⾥⾯没有⼀个线程(也可以设置参数prestartAllCoreThreads启动预期数量主线程)。任务队列是作为参数传进来的。不过,就算队列⾥⾯有任务,线程池也不会⻢上执⾏它们。
- 当调⽤ execute() ⽅法添加⼀个任务时,线程池会做如下判断:
如果正在运⾏的线程数量⼩于 corePoolSize,那么⻢上创建线程运⾏这个任务;
如果正在运⾏的线程数量⼤于或等于 corePoolSize,那么将这个任务放⼊队列;
如果这时候队列满了,⽽且正在运⾏的线程数量⼩于 maximumPoolSize,那么还是要创建⾮核⼼线程⽴刻运⾏这个任务;
如果队列满了,⽽且正在运⾏的线程数量⼤于或等于 maximumPoolSize,那么线程池会抛出异常RejectExecutionException。- 当⼀个线程完成任务时,它会从队列中取下⼀个任务来执⾏。
- 当⼀个线程⽆事可做,超过⼀定的时间(keepAliveTime)时,线程池会判断,如果当前运⾏的线程数⼤于corePoolSize,那么这个线程就被停掉。所以线程池的所有任务完成后,它最终会收缩到corePoolSize 的⼤⼩。
6、Java锁多个对象
例如: 在银⾏系统转账时,需要锁定两个账户,这个时候,顺序使⽤两个
synchronized
可能存在死锁的情况,在⽹上搜索到下⾯的例⼦:
public class MyData {
private int j = 0;
public synchronized void add() {
j++;
System.out.println("线程" + Thread.currentThread().getName() + "j为:" + j);
}
public synchronized void dec() {
j--;
System.out.println("线程" + Thread.currentThread().getName() + "j为:" + j);
}
public int getData() {
return j;
}
}
public class AddRunnable implements Runnable {
MyData data;
public AddRunnable(MyData data) {
this.data = data;
}
public void run() {
data.add();
}
}
public class DecRunnable implements Runnable {
MyData data;
public DecRunnable(MyData data) {
this.data = data;
}
public void run() {
data.dec();
}
}
public class TestOne {
public static void main(String[] args) {
MyData data = new MyData();
Runnable add = new AddRunnable(data);
Runnable dec = new DecRunnable(data);
for (int i = 0; i < 2; i++) {
new Thread(add).start();
new Thread(dec).start();
}
}
}
7、Java线程如何启动
1 、继承 Thread 类;2 、实现 Runnable 接⼝;3 、直接在函数体内:4 、⽐较:
- 实现Runnable接⼝优势:
1)适合多个相同的程序代码的线程去处理同⼀个资源
2)可以避免java中的单继承的限制
3)增加程序的健壮性,代码可以被多个线程共享,代码和数据独⽴。- 继承Thread类优势:
1)可以将线程类抽象出来,当需要使⽤抽象⼯⼚模式设计时。
2)多线程同步- 在函数体使⽤优势
1)⽆需继承thread或者实现Runnable,缩⼩作⽤域。
8、如何让保证数据不丢失
1 、使⽤消息队列,消息持久化;2 、添加标志位:未处理 0 ,处理中 1 ,已处理 2 。定时处理。
9、ThreadLocal为什么会发生内存泄漏
1、ThreadLocal原理图

2、OOM实现:
- ThreadLocal的实现是这样的:每个Thread 维护⼀个 ThreadLocalMap 映射表,这个映射表的 key 是 ThreadLocal实例本身,value 是真正需要存储的 Object。
- 也就是说 ThreadLocal 本身并不存储值,它只是作为⼀个 key 来让线程从 ThreadLocalMap 获取 value。值得注意的是图中的虚线,表示 ThreadLocalMap 是使⽤ ThreadLocal 的弱引⽤作为 Key 的,弱引⽤的对象在 GC 时会被回收。
- ThreadLocalMap使⽤ThreadLocal的弱引⽤作为key,如果⼀个ThreadLocal没有外部强引⽤来引⽤它,那么系统 GC的时候,这个ThreadLocal势必会被回收,这样⼀来,ThreadLocalMap中就会出现key为null的Entry,就没有办法访问这些key为null的Entry的value,如果当前线程再迟迟不结束的话,这些key为null的Entry的value就会⼀直存在⼀条强引⽤链:Thread Ref -> Thread -> ThreaLocalMap -> Entry -> value永远⽆法回收,造成内存泄漏。
3
、预防办法:在
ThreadLocal
的
get
(),
set
(),
remove
()的时候都会清除线程
ThreadLocalMap
⾥所有
key
为
null
的
value
。
但是这些被动的预防措施并不能保证不会内存泄漏:
(1)使⽤ static 的 ThreadLocal ,延⻓了 ThreadLocal 的⽣命周期,可能导致内存泄漏。(2)分配使⽤了 ThreadLocal ⼜不再调⽤ get (), set (), remove ()⽅法,那么就会导致内存泄漏,因为这块内存⼀直存在。
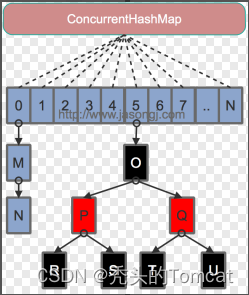
10、JDK8中对ConcurrentHashmap的改进
1.
Java 7
为实现并⾏访问,引⼊了
Segment
这⼀结构,实现了分段锁,理论上最⼤并发度与
Segment
个数相等。
2.
Java 8
为进⼀步提⾼并发性,摒弃了分段锁的⽅案,⽽是直接使⽤⼀个⼤的数组。同时为了提⾼哈希碰撞下的寻址性能,Java 8在链表⻓度超过⼀定阈值(8)时将链表(寻址时间复杂度为
O
(
N
))转换为红⿊树(寻址时间复杂度为
O
(
long
(
N
)))。
其数据结构如下图所示
3.源码
public V put(K key,V value){
return putVal(key,value,false);
}
/**
* Implementation for put and putIfAbsent
*/
final V putVal(K key,V value,boolean onlyIfAbsent){
//ConcurrentHashMap 不允许插⼊null键,HashMap允许插⼊⼀个null键
if(key==null||value==null)throw new NullPointerException();
//计算key的hash值
int hash=spread(key.hashCode());
int binCount=0;
//for循环的作⽤:因为更新元素是使⽤CAS机制更新,需要不断的失败重试,直到成功为⽌。
for(Node<K, V>[]tab=table;;){
// f:链表或红⿊⼆叉树头结点,向链表中添加元素时,需要synchronized获取f的锁。
Node<K, V> f;int n,i,fh;
//判断Node[]数组是否初始化,没有则进⾏初始化操作
if(tab==null||(n=tab.length)==0)
tab=initTable();
//通过hash定位Node[]数组的索引坐标,是否有Node节点,如果没有则使⽤CAS进⾏添加(链表的头结点),添加失败则进⼊下次循环。
else if((f=tabAt(tab,i=(n-1)&hash))==null){
if(casTabAt(tab,i,null,
new Node<K, V>(hash,key,value,null)))
break; // no lock when adding to empty bin
}
//检查到内部正在移动元素(Node[] 数组扩容)
else if((fh=f.hash)==MOVED)
//帮助它扩容
tab=helpTransfer(tab,f);
else{
V oldVal=null;
//锁住链表或红⿊⼆叉树的头结点
synchronized (f){
//判断f是否是链表的头结点
if(tabAt(tab,i)==f){
//如果fh>=0 是链表节点
if(fh>=0){
binCount=1;
//遍历链表所有节点
for(Node<K, V> e=f;;++binCount){
K ek;
//如果节点存在,则更新value
if(e.hash==hash&&
((ek=e.key)==key||
(ek!=null&&key.equals(ek)))){
oldVal=e.val;
if(!onlyIfAbsent)
e.val=value;
break;
}
//不存在则在链表尾部添加新节点。
Node<K, V> pred=e;
if((e=e.next)==null){
pred.next=new Node<K, V>(hash,key,
value,null);
break;
}
}
}
//TreeBin是红⿊⼆叉树节点
else if(f instanceof TreeBin){
Node<K, V> p;
binCount=2;
//添加树节点
if((p=((TreeBin<K, V>)f).putTreeVal(hash,key,
value))!=null){
oldVal=p.val;
if(!onlyIfAbsent)
p.val=value;
}
}
}
}
if(binCount!=0){
//如果链表⻓度已经达到临界值8 就需要把链表转换为树结构
if(binCount>=TREEIFY_THRESHOLD)
treeifyBin(tab,i);
if(oldVal!=null)
return oldVal;
break;
}
}
}
//将当前ConcurrentHashMap的size数量+1
addCount(1L,binCount);
return null;
}
















 2556
2556











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











