







1、背景
最近公司要搭建一个大数据ETL平台,过程涉及一些测试工作,在测试过程中,将一些可用性强的步骤给记录下来,方便后面开发作业的时候,拿来直接 copy
2、环境介绍
- 作业流程:从Kafka消费数据,直接写入至Hive库表中
- 本机环境:Linux(7.9)、Hadoop(3.1.3)、Hive(3.1.2)、Kafka(2.11-2.4.1)
- 集群节点:3台(node01、node02、node03)
3、任务准备
Flume官网上关于Hive Sink的一句话,即:Hive的表需要是事务表
This sink streams events containing delimited text or JSON data directly into a Hive table or partition. Events are written using Hive transactions. As soon as a set of events are committed to Hive, they become immediately visible to Hive queries. Partitions to which flume will stream to can either be pre-created or, optionally, Flume can create them if they are missing. Fields from incoming event data are mapped to corresponding columns in the Hive table.
我们知道,Hive的事务表其实限制挺多的,我看查看Hive官网就有相关描述:
Limitations:
1、BEGIN, COMMIT, and ROLLBACK are not yet supported. All language operations are auto-commit. The plan is to support these in a future release.
2、Only ORC file format is supported in this first release. The feature has been built such that transactions can be used by any storage format that can determine how updates or deletes apply to base records (basically, that has an explicit or implicit row id), but so far the integration work has only been done for ORC.
3、By default transactions are configured to be off. See the Hive Transactions#Configuration section below for a discussion of which values need to be set to configure it.
4、Tables must be bucketed to make use of these features. Tables in the same system not using transactions and ACID do not need to be bucketed. External tables cannot be made ACID tables since the changes on external tables are beyond the control of the compactor (HIVE-13175).
5、Reading/writing to an ACID table from a non-ACID session is not allowed. In other words, the Hive transaction manager must be set to org.apache.hadoop.hive.ql.lockmgr.DbTxnManager in order to work with ACID tables.
6、At this time only snapshot level isolation is supported. When a given query starts it will be provided with a consistent snapshot of the data. There is no support for dirty read, read committed, repeatable read, or serializable. With the introduction of BEGIN the intention is to support snapshot isolation for the duration of transaction rather than just a single query. Other isolation levels may be added depending on user requests.
7、The existing ZooKeeper and in-memory lock managers are not compatible with transactions. There is no intention to address this issue. See Hive Transactions#Basic Design below for a discussion of how locks are stored for transactions.
8、Schema changes using ALTER TABLE is NOT supported for ACID tables. HIVE-11421 is tracking it. Fixed in 1.3.0/2.0.0.
9、Using Oracle as the Metastore DB and "datanucleus.connectionPoolingType=BONECP" may generate intermittent "No such lock.." and "No such transaction..." errors. Setting "datanucleus.connectionPoolingType=DBCP" is recommended in this case.
10、LOAD DATA... statement is not supported with transactional tables. (This was not properly enforced until HIVE-16732)
没办法,只能创建事务表
3.1 创建表
-- 开启事务支持
set hive.support.concurrency=true;
set hive.txn.manager=org.apache.hadoop.hive.ql.lockmgr.DbTxnManager;
-- 建表,必须是分桶表,仅支持OCR格式
create table dwd_mhs_opt_register (
global_id string
,patient_id string
,med_org_id string
,med_org_name string
,register_dept_id string
,register_dept_name string
,register_date date
,visit_id string
,register_id string
,register_time timestamp
,fee_register decimal(18,2)
,patient_name string
,id_card string
,id_card_type string
,gender string
,birthday string
,patient_phone string
,visit_card_no string
,visit_card_type string
,ds_date date
) clustered by(global_id) into 2 buckets stored as orc tblproperties('transactional'='true');
3.2 创建Kafka主题
# 创建主题 k2h_01
kafka-topics.sh --bootstrap-server node01:9092 --create --replication-factor 3 --partitions 1 --topic k2h_01
# 查看主题
kafka-topics.sh --bootstrap-server node01:9092 --list
3.3 创建flume配置文件
a.sources=source_from_kafka
a.channels=file_channel
a.sinks=hive_sink
#kafka为souce的配置
a.sources.source_from_kafka.type=org.apache.flume.source.kafka.KafkaSource
a.sources.source_from_kafka.batchSize=10
a.sources.source_from_kafka.kafka.bootstrap.servers=node01:9092
a.sources.source_from_kafka.topic=k2h_01
a.sources.source_from_kafka.channels=file_channel
a.sources.source_from_kafka.consumer.timeout.ms=1000
#hive为sink的配置
a.sinks.hive_sink.type=hive
a.sinks.hive_sink.hive.metastore=thrift://node01:9083
a.sinks.hive_sink.hive.database=test
a.sinks.hive_sink.hive.table=dwd_mhs_opt_register
a.sinks.hive_sink.hive.txnsPerBatchAsk=2
a.sinks.hive_sink.batchSize=10
a.sinks.hive_sink.serializer=JSON
a.sinks.hive_sink.serializer.fieldnames=global_id,patient_id,med_org_id,med_org_name,register_dept_id,register_dept_name,register_date,visit_id,register_id,register_time,fee_register,patient_name,id_card,id_card_type,gender,birthday,patient_phone,visit_card_no,visit_card_type,ds_date
#channel的配置
a.channels.file_channel.type=file
a.channels.file_channel.capacity=1000
a.channels.file_channel.transactionCapacity=100
#三者之间的关系
a.sources.source_from_kafka.channels=file_channel
a.sinks.hive_sink.channel=file_channel
4、任务测试
4.1 启动Flume任务
# 默认 Hadoop Kafka等集群都已经启动
flume-ng agent -n a -c $FLUME_HOME/conf -f $FLUME_HOME/conf/kafka_to_hive_01.conf -Dflume.root.logger=INFO,console
4.2 启动Kafka任务
# 启动Kafka控制台生产者,并发送测试数据
kafka-console-producer.sh --broker-list node01:9092 --topic k2h_01

4.3 查看Hive表中数据
# 登录hive查看,此处我登录的是beeline
# 开启 hiveserver2 服务
hive --service hiveserver2 2>&1 >/dev/null &
# 开启元数据服务
hive --service metastore 2>&1 >/dev/null &
# 登录 beeline
beeline -u jdbc:hive2://node01:10000 -n root
# 查询数据
use test;
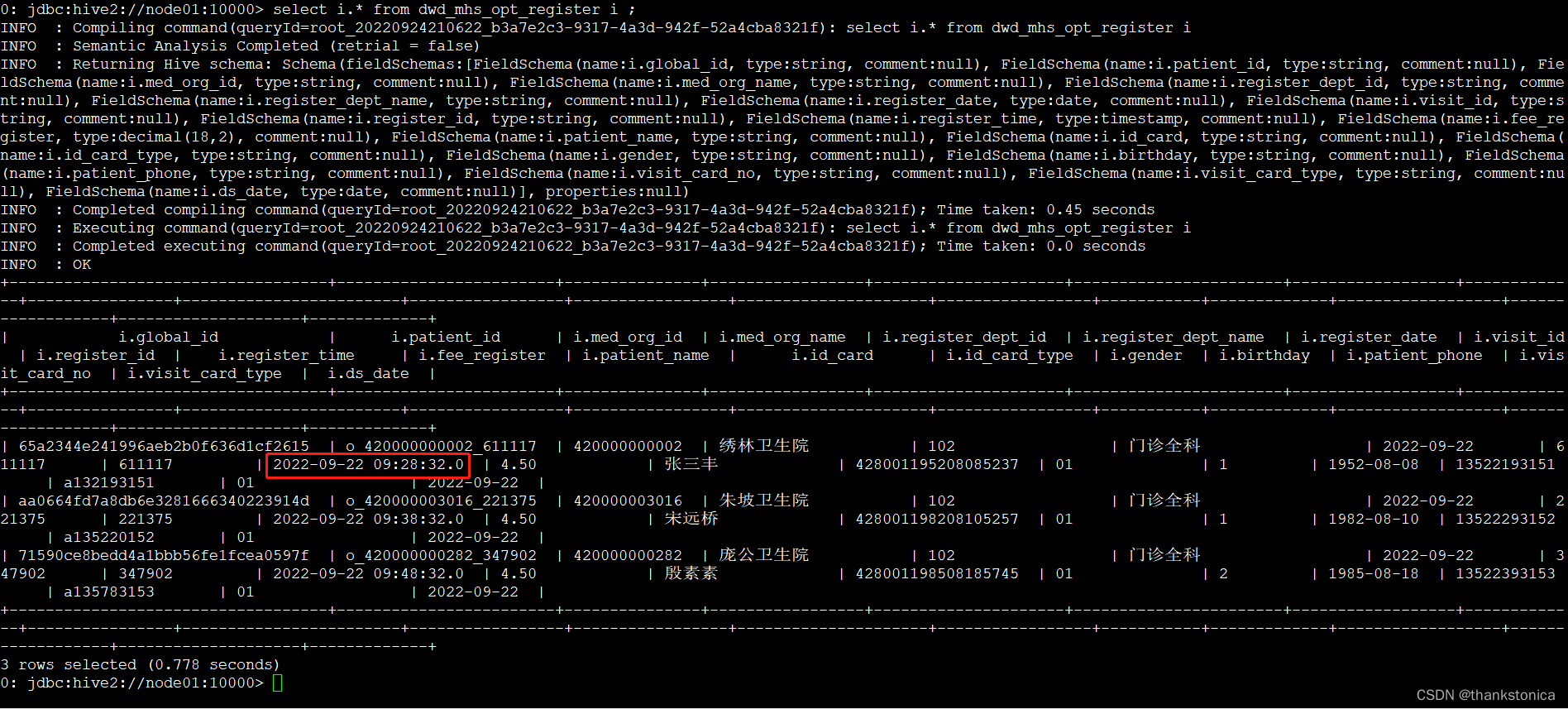
select i.* from dwd_mhs_opt_register i;
5、总结
- Flume的确可以从Kafka读数据并写入Hive中,但是限制颇多(事务表)
- 针对时间戳格式,Kafka导入Hive中默认带了毫秒(可参考上面截图)
- 需要添加上调度,测试平台使用的是dolphinscheduler,后续写一篇文章介绍一下
- 针对速率啥的,需要监控,Ganglia应该是不错的选择,有时间也会研究下















 1173
1173











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









