







目录
十四、数据库
14.1 引言
数据的存储传统上是使用没有关联的文件,有时称平面文件。在过去,组织中的每个应用程序都使用自己的文件。例如,学校里的教务处、财务处等部门都使用它们自己有关学生信息的文件。现在,这些平面文件都被组合成一个实体—数据库。
14.1.1 定义
虽然要给出一个广泛接受的数据库定义有一些困难,但我们通常使用下面的定义:
数据库是一个组织内被应用程序使用的逻辑相一致的相关数据的集合。
14.1.2 数据库的优点
与平面文件相比,数据库有以下优点:
1. 冗余较少。平面文件系统中存在着大量的冗余,在学校中,学生的信息就保存在多个文件中。
2. 避免不一致性。如果相同的信息存储在多个文件中,那么对数据的任何修改都必须修改所有的文件,否则就会造成数据不一致。
3. 效率。数据库通常比平面文件系统的效率高得多,因为数据库中一条信息存储在更少的地方。
4. 数据完整性。数据库系统更容易维护数据的完整性,因为数据库中一条信息存储在更少的地方。
5. 机密性。数据集中存储在一个地方,就更容易维护信息的机密性。
14.1.3 数据库管理系统(DBMS)
数据库管理系统是定义、创建和维护数据库的一种工具,也允许用户来控制数据库中数据的存取。数据库管理系统由5部分组成:硬件、软件、数据、用户和规程。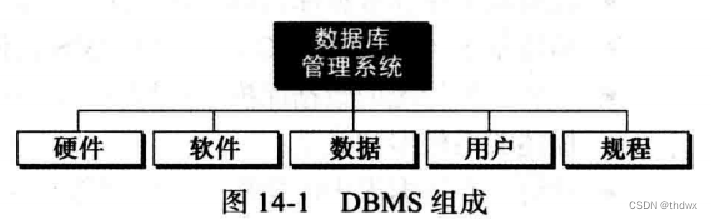
硬件:硬件是指允许存取数据的实际计算机硬件系统。
软件:是指允许用户存取、维护和更新物理数据的实际程序,软件还可以控制那些用户可以对哪部分数据进行存取。
数据:数据库中的数据存储在物理设备上。数据是独立于软件的一个实体,这使得组织可以在不改变物理数据的情况下更换使用的软件。
用户:分为最终用户和应用程序。最终用户可以分为数据库管理员和普通用户。数据库管理员拥有最大的权限,可以控制其他用户以及他们对数据库的存取。数据库管理员可以将他的一些特权授权给普通用户并保留随时收回特权的能力。普通用户只能使用部分数据库和有限的存取。应用程序有时也需要处理和存取数据,所以应用程序也会使用数据库。
规程:是必须被明确定义并为数据库用户所遵循的规程或规程的集合。
14.2 数据库体系结构
美国国家标准协会/标准计划和需求委员会为数据库管理系统建立了三层体系结构:内层、概念层和外层。
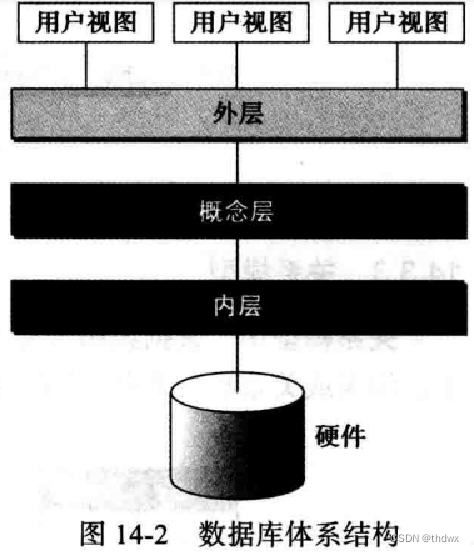
14.2.1 内层
内层决定了数据在存储设备中的实际位置。这个层次处理低层次的数据存取方法和如何在存储设备间传输字节。换句话说,内层直接与硬件交互。
14.2.2 概念层
概念层定义数据的逻辑视图,该层中定义了数据模式。数据库管理系统的主要功能(如查询等)都在该层。数据库管理系统把数据的内部视图转化为用户看到的外部视图。概念层是中介层,它使得用户不必与内层打交道。
14.2.3 外层
外层直接与用户交互。它将来自概念层的数据转化为用户熟悉的格式和视图。
14.3 数据库模型
数据库模型定义了数据的逻辑设计,曾使用过3种模型:层次模型、网状模型和关系模型。
14.3.1 层次模型
层次模型中,数据被组织成一棵倒置的树。每一个实体可以有不同的子节点,但只能有一个父节点。层次的顶端有一个节点,称为根。由于层次模型已经过时,不再过多叙述。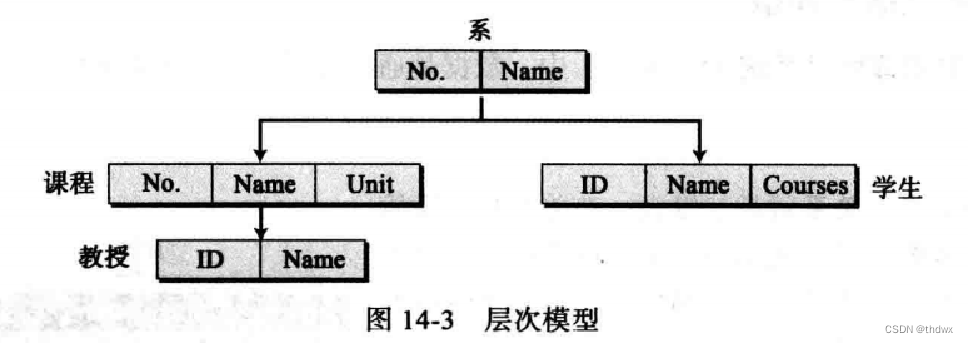
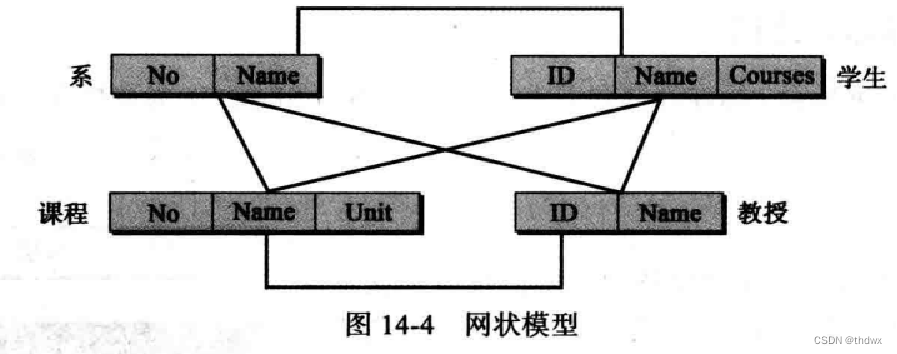
14.3.2 网状模型
网状模型中,实体通过图来组织,图中的部分实体可以通过多条路径来访问。网状模型已经过时,不再过多叙述。
14.3.3 关系模型
关系模型中,数据组织成称为关系的二维表,这里没有任何层次或网络结构强加于数据,但表(关系)相互联系。如今,关系模型是数据库设计中最常用的模型。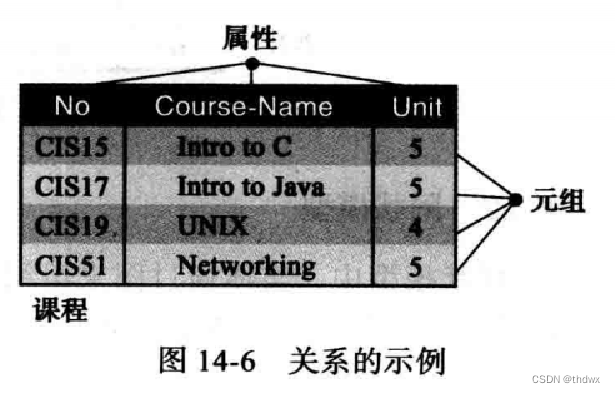
14.4 关系数据库模型
在关系数据库管理系统(RDBMS)中,数据是通过关系的集合来表示的。
14.4.1 关系
在关系数据库管理系统中,数据的外部视图就是关系或表的集合。但这并不代表数据以表的形式存储。物理存储方式与数据的逻辑组织方式毫无关系。
关系数据库管理系统中的关系有几个特征:
名称:每一种关系(表)都具有唯一的名称。
属性(字段):关系中的每一列称为属性,属性在表中是列的头。每一个属性表示存储在该列的数据的含义。表中的每一列在关系范围内有唯一的名称,关系中属性的总数称为关系的度。属性名并不存储在数据库中,概念层中使用属性给每一列赋予一定的意义。
元组:关系中的行称为元组。元组定义了一组属性值,关系中的元组个数称为关系的基数,当增加或删除时,关系的基数就会改变。这就实现了动态数据库。
14.4.2 关系的操作
结构化查询语言(SQL)是美国国标协会和国标标准化组织用于关系数据库的标准化语言。这是一种描述性语言,意味着使用者不需要编写详细的程序而只需要声明它。SQL于1979年首次被Oracle公司实现。以SQL语言为例,说明关系的操作。
插入:一元操作,应用于一个关系,作用是在关系中插入新的元组。![]()
values子句定义了要插入的元组的所有属性。在SQL语言中,字符串需要用双引号括起来,数值则不需要。

删除:一元操作,作用是删除关系中相应的元组。![]()
删除的条件用where定义,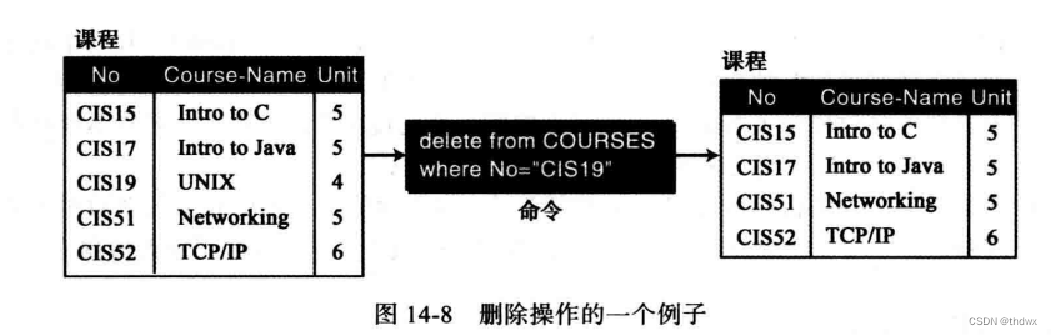
更新:一元操作,作用是修改相应的元组中的属性值。
要更改的属性在set子句中,更新的条件在where子句中, 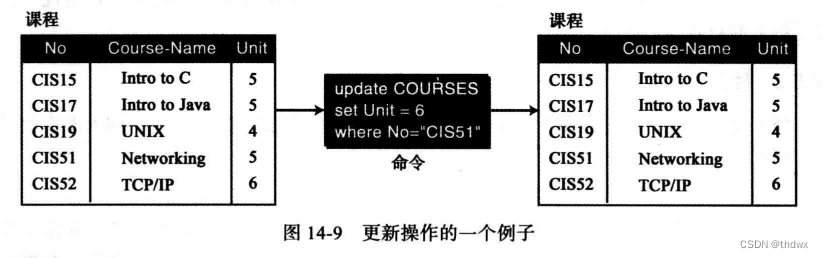
选择:一元操作,它应用于一个关系并产生新的关系。新关系中的元组是原关系元组的子集。
星号(*)表示选择所有属性。
投影:一元操作,它应用于一个关系并产生新的关系。新关系中的属性是原关系属性的子集。
投影所得到的新关系中,元组的属性减少,但元组的数量不变。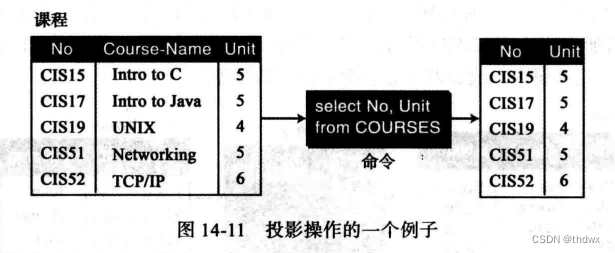
连接:二元操作,它是基于共有的属性将两个关系组合起来(属性增加)。
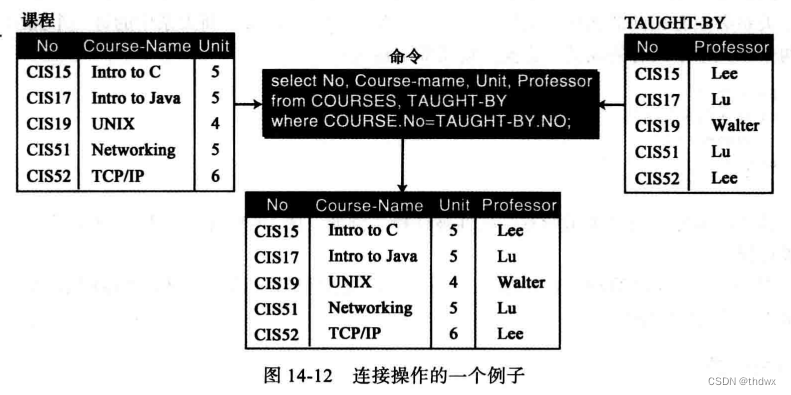
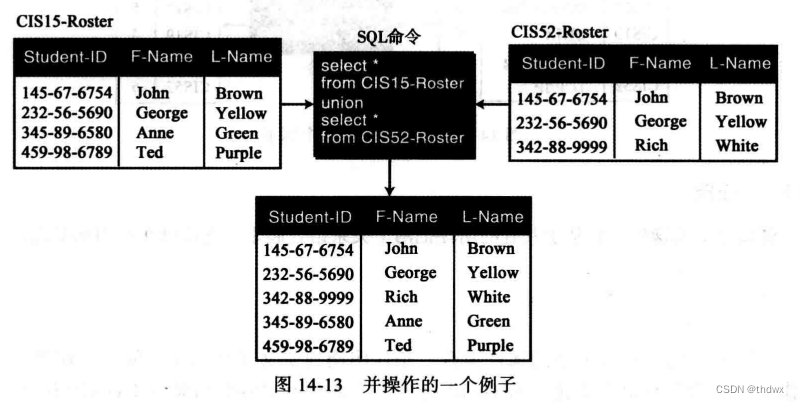
并:二元操作,它将两个属性完全相同(必要条件)的关系组合成一个关系(元组增加) 。
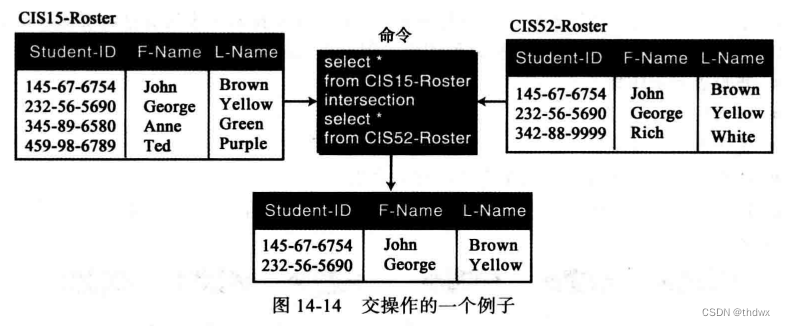
交:二元操作,它对两个关系(属性相同)进行操作并创建一个新关系,新关系中的元组是它们都有的元组。

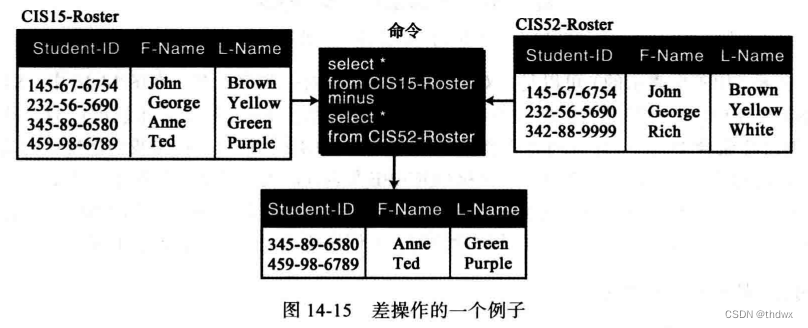
差:二元操作,它对两个关系(属性相同)操作并创建新的关系,新的关系中的元组是第一个关系中有的而第二个关系中没有的。

语句的组合:SQL允许我们组合前面介绍的语句,从数据库中抽取出更复杂的数据。
14.5 数据库设计
数据库设计是一个冗长且只能一步步完成的任务。第一步涉及与数据库潜在用户的面谈(收集需求等);第二步就是建立一个实体关系模型(REM);设计的下一步是基于使用的数据库类型的,关系数据库就是建立基于ERM的关系和规范化这些关系。
14.5.1 实体关系模型
数据库设计者建立实体关系(E-R)图来表示那些信其信息需要保存的实体和实体间的关系。E-R图使用多种几何图形,这里介绍一些:
矩形:表示实体集;
椭圆:表示属性;
菱形:表示关系集;
线:连接属性和实体集以及实体集和关系集。
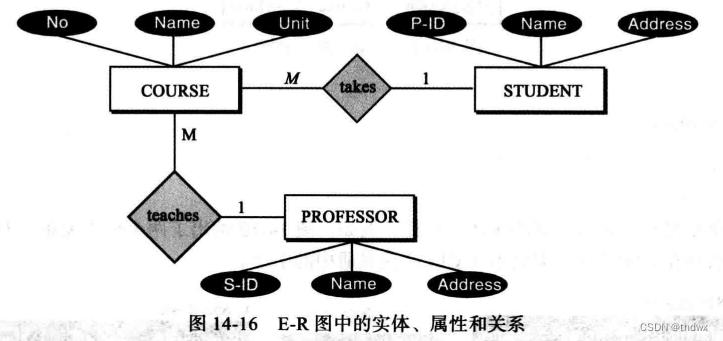
关系可以是一对一、一对多、多对一和多对多。STUDENT和COURSE直接是一对多的关系(用1-M表示),如果将 takes 换成 taken,那么关系就变成了多对一。
14.5.2 从E-R图到关系
实体集上的关系:对于E-R图中的每个实体集,我们都创建一个关系。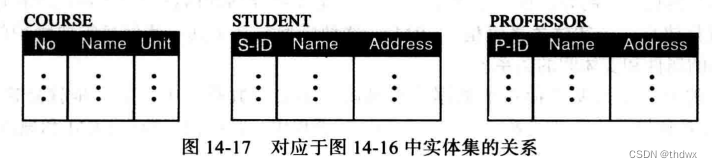
关系集上的关系:对于E-R图中的每个关系集,我们都创建一个关系。这个关系中的列对应于关系所涉及的实体集的关键字,如果关系有属性,这个关系还可以有关系本身属性的列。
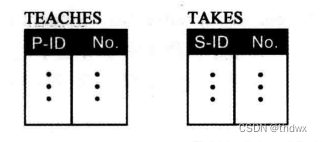
14.5.3 规范化
规范化是一个处理过程,通过此过程给定的一组关系转化成一组具有更坚固结构的新关系。规范化允许数据库中表示的任何关系,可以使用像SQL这样的语言去使用由原子操作组成的恢复操作,要移除插入删除和更新操作中的不规则,要减少新的数据类型被加入时对数据库重建的需要。
规范化过程定义了一组层次范式(NF)。多种范式已被提出,包括1NF、2NF、3NF、BCNF(Boyce-Codd范式)、4NF、PJNF(Projection/Joint范式)和5NF等。范式形成了一个层次结构,也就是说,如果关系是2NF,那么它首先应该是1NF。
第一范式(1NF):当我们把实体或关系转换成表格式的关系时,可能有些关系的行和列的交集有多个值,那么它就不是第一范式。一个不是第一范式的关系可能会遇到许多问题。在数据库系统中,我们总是删除一整条记录,而不是一条记录的一部分。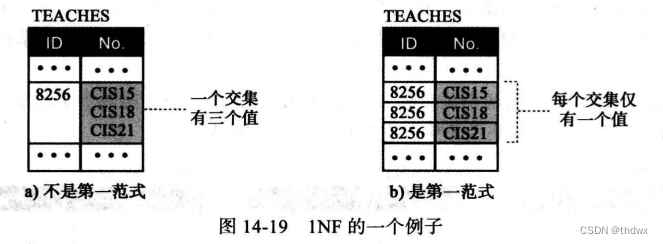
第二范式(2NF):在每个关系中,我们需要有一个关键字(称为主键),所有其他的属性都依赖于它。但是,当关系是依据E-R图建立的,可能有一些复合的关键字(两个或两个以上关键字的组合)。在这种情况下,如果每一个非关键字属性都依赖于整个复合关键字,那么这个关系就是第二范式的。如果有些属性只依赖于复合关键字的一部分,那么就不是第二范式的。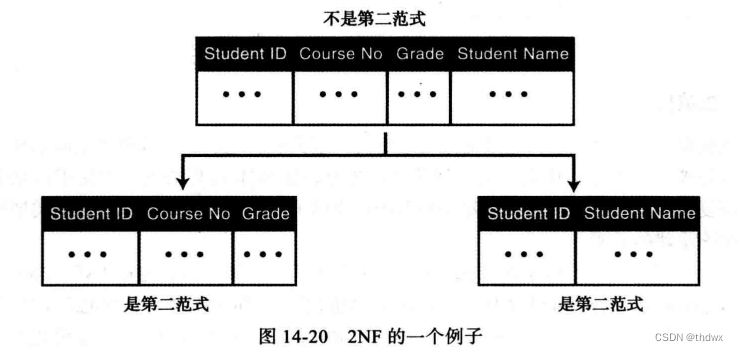
一个不是第二范式的关系会遇到很多问题,例如,在上图中,如果学生没有课程成绩就不能放到关系中。但如果关系是第二范式的,在成绩出来前,信息可以放在右边的表中,成绩出来后信息就能加到左边的表中。
其他范式:其他范式使用属性间更复杂的依赖关系,书中没有讨论。
14.6 其他数据库模型
关系数据库并不是当今唯一通用的数据库模型,另两种通用的模型是:分布式数据库和面向对象式数据库。
14.6.1 分布式数据库
分布式数据库模型实际上并不是一个新的模型,它是基于关系模型的。数据库中的数据存储在一些通过因特网通信的计算机上。每台计算机(站点)拥有部分或全部数据库。换句话说,数据或者是分别存储在每个站点上或者是为每个站点所复制。
不完全的分布式数据库:在不完全的分布式数据库中,数据是本地化的。本地使用的数据存储在相应的站点上。访问大部分情况下是本地的,但偶尔又是全局的。虽然站点对存储的本地数据具有完全控制权,但是通过因特网或广域网,还存在一个全局的控制。
复制式的分布式数据库:在复制式的分布式数据库中,每个站点都有其他站点的一个完全副本。对一个站点数据的修改会在其他站点的副本数据上重复。这样,数据库的安全性得到了加强。如果系统的一个站点出现了问题,用户可以访问其他站点的数据。
14.6.2 面向对象数据库
关系数据库具有数据的特定视图,该视图基于该关系数据库的本质(元组和属性)。关系数据库中最小的数据集合就是一个元组与一个列的交集。但今天,很多程序要求以另一种形式看待数据。
面向对象数据库在试图保留关系模型优点的同时允许应用存取结构化数据。在面向对象数据库中,定义了对象和它们的关系,每一个对象可以具有属性并以域的形式表达。
例如在某个学校中,可以定义对象类型,如学生、学院等。学生类可以定义一个学生对象的属性(姓名、学号、成绩等)以及如何存取它们。学院对象可以定义学院的属性以及如何存取它们。数据库还可以建立学生和学院的关系。
XML:通常用作面向对象数据库的查询语言。起初XML是用来给文本文档增加标记信息的,但现在它还用于数据库查询语言。XML能用嵌套结构表示数据。















 1194
1194











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









