










使用模型报错
#预测数据
p1=model_best.predict(new_train)
报错信息
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator ExtraTreeRegressor from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator ExtraTreesRegressor from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator StandardScaler from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator StandardScaler from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator StandardScaler from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator StandardScaler from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator StandardScaler from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator SimpleImputer from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator StandardScaler from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator Pipeline from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator QuantileTransformer from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\base.py:318: UserWarning: Trying to unpickle estimator ColumnTransformer from version 1.0.2 when using version 1.2.2. This might lead to breaking code or invalid results. Use at your own risk. For more info please refer to:
https://scikit-learn.org/stable/model_persistence.html#security-maintainability-limitations
warnings.warn(
---------------------------------------------------------------------------
AttributeError Traceback (most recent call last)
Cell In[8], line 2
1 #预测数据
----> 2 p1=model_best.predict(new_train)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\predictor\predictor.py:1371, in TabularPredictor.predict(self, data, model, as_pandas, transform_features)
1369 self._assert_is_fit('predict')
1370 data = self.__get_dataset(data)
-> 1371 return self._learner.predict(X=data, model=model, as_pandas=as_pandas, transform_features=transform_features)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\learner\abstract_learner.py:160, in AbstractTabularLearner.predict(self, X, model, as_pandas, transform_features)
158 else:
159 X_index = None
--> 160 y_pred_proba = self.predict_proba(X=X, model=model, as_pandas=False, as_multiclass=False, inverse_transform=False, transform_features=transform_features)
161 problem_type = self.label_cleaner.problem_type_transform or self.problem_type
162 y_pred = get_pred_from_proba(y_pred_proba=y_pred_proba, problem_type=problem_type)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\learner\abstract_learner.py:141, in AbstractTabularLearner.predict_proba(self, X, model, as_pandas, as_multiclass, inverse_transform, transform_features)
139 if transform_features:
140 X = self.transform_features(X)
--> 141 y_pred_proba = self.load_trainer().predict_proba(X, model=model)
142 if inverse_transform:
143 y_pred_proba = self.label_cleaner.inverse_transform_proba(y_pred_proba)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py:555, in AbstractTrainer.predict_proba(self, X, model)
553 model = self._get_best()
554 cascade = isinstance(model, list)
--> 555 return self._predict_proba_model(X, model, cascade=cascade)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py:1975, in AbstractTrainer._predict_proba_model(self, X, model, model_pred_proba_dict, cascade)
1974 def _predict_proba_model(self, X, model, model_pred_proba_dict=None, cascade=False):
-> 1975 return self.get_pred_proba_from_model(model=model, X=X, model_pred_proba_dict=model_pred_proba_dict, cascade=cascade)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py:569, in AbstractTrainer.get_pred_proba_from_model(self, model, X, model_pred_proba_dict, cascade)
567 else:
568 models = [model]
--> 569 model_pred_proba_dict = self.get_model_pred_proba_dict(X=X, models=models, model_pred_proba_dict=model_pred_proba_dict, cascade=cascade)
570 if not isinstance(model, str):
571 model = model.name
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\core\trainer\abstract_trainer.py:809, in AbstractTrainer.get_model_pred_proba_dict(self, X, models, model_pred_proba_dict, model_pred_time_dict, record_pred_time, use_val_cache, cascade, cascade_threshold)
807 else:
808 preprocess_kwargs = dict(infer=False, model_pred_proba_dict=model_pred_proba_dict)
--> 809 model_pred_proba_dict[model_name] = model.predict_proba(X, **preprocess_kwargs)
810 else:
811 model_pred_proba_dict[model_name] = model.predict_proba(X)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\core\models\ensemble\bagged_ensemble_model.py:323, in BaggedEnsembleModel.predict_proba(self, X, normalize, **kwargs)
321 model = self.load_child(self.models[0])
322 X = self.preprocess(X, model=model, **kwargs)
--> 323 pred_proba = model.predict_proba(X=X, preprocess_nonadaptive=False, normalize=normalize)
324 for model in self.models[1:]:
325 model = self.load_child(model)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\core\models\abstract\abstract_model.py:803, in AbstractModel.predict_proba(self, X, normalize, **kwargs)
801 if normalize is None:
802 normalize = self.normalize_pred_probas
--> 803 y_pred_proba = self._predict_proba(X=X, **kwargs)
804 if normalize:
805 y_pred_proba = normalize_pred_probas(y_pred_proba, self.problem_type)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\models\tabular_nn\torch\tabular_nn_torch.py:405, in TabularNeuralNetTorchModel._predict_proba(self, X, _reset_threads, **kwargs)
403 from ..._utils.torch_utils import TorchThreadManager
404 with TorchThreadManager(num_threads=self._num_cpus_infer):
--> 405 pred_proba = self._predict_proba_internal(X=X, **kwargs)
406 else:
407 pred_proba = self._predict_proba_internal(X=X, **kwargs)
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\models\tabular_nn\torch\tabular_nn_torch.py:422, in TabularNeuralNetTorchModel._predict_proba_internal(self, X, **kwargs)
420 elif isinstance(X, pd.DataFrame):
421 X = self.preprocess(X, **kwargs)
--> 422 return self._predict_tabular_data(new_data=X, process=True)
423 else:
424 raise ValueError("X must be of type pd.DataFrame or TabularTorchDataset, not type: %s" % type(X))
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\models\tabular_nn\torch\tabular_nn_torch.py:429, in TabularNeuralNetTorchModel._predict_tabular_data(self, new_data, process)
427 from .tabular_torch_dataset import TabularTorchDataset
428 if process:
--> 429 new_data = self._process_test_data(new_data)
430 if not isinstance(new_data, TabularTorchDataset):
431 raise ValueError("new_data must of of type TabularTorchDataset if process=False")
File ~\AppData\Roaming\Python\Python39\site-packages\autogluon\tabular\models\tabular_nn\torch\tabular_nn_torch.py:492, in TabularNeuralNetTorchModel._process_test_data(self, df, labels)
489 df = df.drop(columns=drop_cols)
491 # self.feature_arraycol_map, self.feature_type_map have been previously set while processing training data.
--> 492 df = self.processor.transform(df)
493 return TabularTorchDataset(df, self.feature_arraycol_map, self.feature_type_map, self.problem_type, labels)
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\utils\_set_output.py:140, in _wrap_method_output.<locals>.wrapped(self, X, *args, **kwargs)
138 @wraps(f)
139 def wrapped(self, X, *args, **kwargs):
--> 140 data_to_wrap = f(self, X, *args, **kwargs)
141 if isinstance(data_to_wrap, tuple):
142 # only wrap the first output for cross decomposition
143 return (
144 _wrap_data_with_container(method, data_to_wrap[0], X, self),
145 *data_to_wrap[1:],
146 )
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\compose\_column_transformer.py:800, in ColumnTransformer.transform(self, X)
795 else:
796 # ndarray was used for fitting or transforming, thus we only
797 # check that n_features_in_ is consistent
798 self._check_n_features(X, reset=False)
--> 800 Xs = self._fit_transform(
801 X,
802 None,
803 _transform_one,
804 fitted=True,
805 column_as_strings=fit_dataframe_and_transform_dataframe,
806 )
807 self._validate_output(Xs)
809 if not Xs:
810 # All transformers are None
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\compose\_column_transformer.py:652, in ColumnTransformer._fit_transform(self, X, y, func, fitted, column_as_strings)
644 def _fit_transform(self, X, y, func, fitted=False, column_as_strings=False):
645 """
646 Private function to fit and/or transform on demand.
647
(...)
650 ``fitted=True`` ensures the fitted transformers are used.
651 """
--> 652 transformers = list(
653 self._iter(
654 fitted=fitted, replace_strings=True, column_as_strings=column_as_strings
655 )
656 )
657 try:
658 return Parallel(n_jobs=self.n_jobs)(
659 delayed(func)(
660 transformer=clone(trans) if not fitted else trans,
(...)
667 for idx, (name, trans, column, weight) in enumerate(transformers, 1)
668 )
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\compose\_column_transformer.py:349, in ColumnTransformer._iter(self, fitted, replace_strings, column_as_strings)
346 return name, trans, columns
347 return name, self._name_to_fitted_passthrough[name], columns
--> 349 transformers = [
350 replace_passthrough(*trans) for trans in self.transformers_
351 ]
352 else:
353 transformers = self.transformers_
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\compose\_column_transformer.py:350, in <listcomp>(.0)
346 return name, trans, columns
347 return name, self._name_to_fitted_passthrough[name], columns
349 transformers = [
--> 350 replace_passthrough(*trans) for trans in self.transformers_
351 ]
352 else:
353 transformers = self.transformers_
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\sklearn\compose\_column_transformer.py:345, in ColumnTransformer._iter.<locals>.replace_passthrough(name, trans, columns)
344 def replace_passthrough(name, trans, columns):
--> 345 if name not in self._name_to_fitted_passthrough:
346 return name, trans, columns
347 return name, self._name_to_fitted_passthrough[name], columns
AttributeError: 'ColumnTransformer' object has no attribute '_name_to_fitted_passthrough'
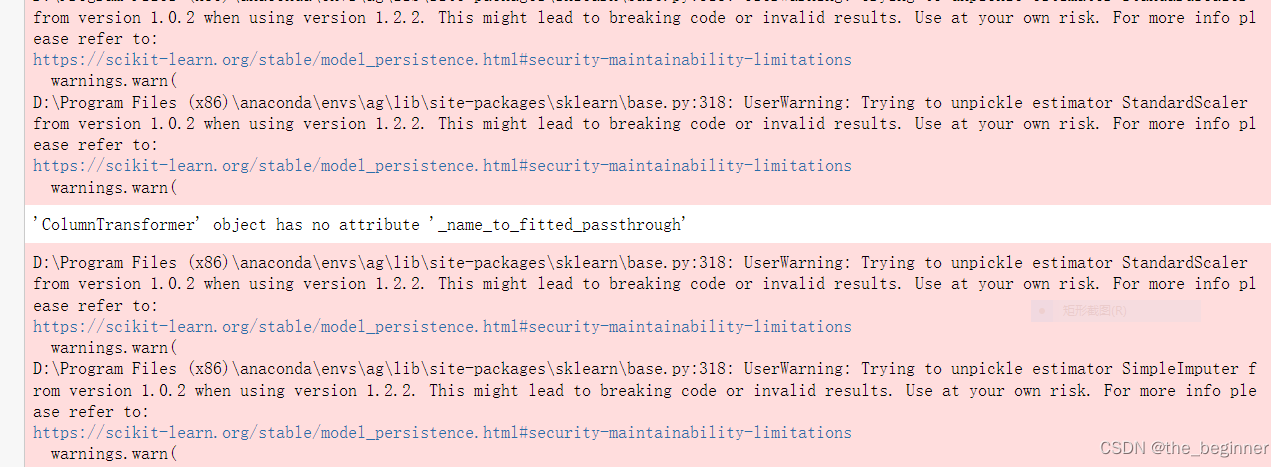
解决办法
The warning messages you provided suggest that there might be compatibility issues between the versions of scikit-learn (sklearn) and PyTorch libraries you are using. It is generally recommended to use the same version of these libraries to avoid potential problems.
The warnings specifically mention the following issues:
Unpickling Estimators: It appears that you are trying to unpickle (load) estimators (ExtraTreeRegressor, ExtraTreesRegressor, and StandardScaler) that were saved using scikit-learn version 1.0.2, but you are currently using version 1.2.2. The warning advises you to be cautious as this mismatch in versions could lead to breaking code or invalid results. The provided link offers more information on the topic.
GPU Compatibility: The warning related to PyTorch indicates that you have a GPU (GeForce GTX 780 Ti) with a compute capability of 3.5, which is not supported by the current version of PyTorch you are using. The minimum supported compute capability is 3.7. This means that you may encounter issues or limitations when using PyTorch on this GPU. Consider using a newer GPU or upgrading PyTorch to a version that supports your current GPU.
ColumnTransformer: The last warning message suggests that the ‘ColumnTransformer’ object you are using does not have the attribute ‘_name_to_fitted_passthrough’. This could indicate a potential issue with the usage or configuration of the ‘ColumnTransformer’ object in your code. You might need to review your code and ensure that the object is being used correctly.
To address these warnings, you can take the following steps:
Check the scikit-learn version you have installed and make sure it matches the version used when the estimators were saved. If possible, consider updating your code and saved models to use the same scikit-learn version.
If you need to use PyTorch with your current GPU, you should either upgrade your GPU to a model with a compute capability of at least 3.7 or install an older version of PyTorch that supports your current GPU. Alternatively, you can use PyTorch with CPU-only mode, which should work regardless of the GPU capabilities.
Review your code that uses the ‘ColumnTransformer’ object and ensure that it is used correctly. Check the scikit-learn documentation or examples for proper usage of this object and verify if any changes or updates are needed in your code.
It’s important to note that the provided suggestions are based on the information you provided, and further investigation or troubleshooting may be necessary to resolve the issues completely.
中文
你提供的警告信息表明你可能在使用不兼容的 scikit-learn(sklearn)和 PyTorch 库版本。通常建议使用相同版本的库以避免潜在问题。
这些警告具体指出以下问题:
反序列化评估器:看起来你正在尝试从 scikit-learn 版本 1.0.2 中反序列化(加载)评估器(ExtraTreeRegressor、ExtraTreesRegressor 和 StandardScaler),但你当前使用的是版本 1.2.2。警告建议你要小心,因为版本不匹配可能导致代码失效或结果无效。提供的链接提供了更多信息。
GPU 兼容性:与 PyTorch 相关的警告表示你的 GPU(GeForce GTX 780 Ti)的计算能力为 3.5,而你当前使用的 PyTorch 版本不支持该 GPU。支持的最低计算能力为 3.7。这意味着在这个 GPU 上使用 PyTorch 可能会遇到问题或限制。考虑更换较新的 GPU,或升级 PyTorch 版本以支持当前 GPU。
ColumnTransformer:最后一个警告消息表明你使用的 ‘ColumnTransformer’ 对象没有属性 ‘_name_to_fitted_passthrough’。这可能意味着你的代码在使用或配置 ‘ColumnTransformer’ 对象时存在问题。你可能需要审查代码,确保正确使用该对象。
为了解决这些警告,你可以采取以下步骤:
检查你安装的 scikit-learn 版本,并确保与保存评估器时使用的版本匹配。如果可能,考虑更新你的代码和保存的模型以使用相同的 scikit-learn 版本。
如果你需要在当前 GPU 上使用 PyTorch,你应该将 GPU 升级到至少具有 3.7 的计算能力的型号,或安装支持当前 GPU 的较旧版本的 PyTorch。另外,你还可以使用 PyTorch 的 CPU-only 模式,无论 GPU 的能力如何,都应该可以正常工作。
检查使用 ‘ColumnTransformer’ 对象的代码,确保正确使用它。查阅 scikit-learn 的文档或示例,了解如何正确使用该对象,并验证代码中是否需要进行任何更改或更新。
请注意,提供的建议基于你提供的信息,可能需要进一步的调查或故障排除才能完全解决问题。
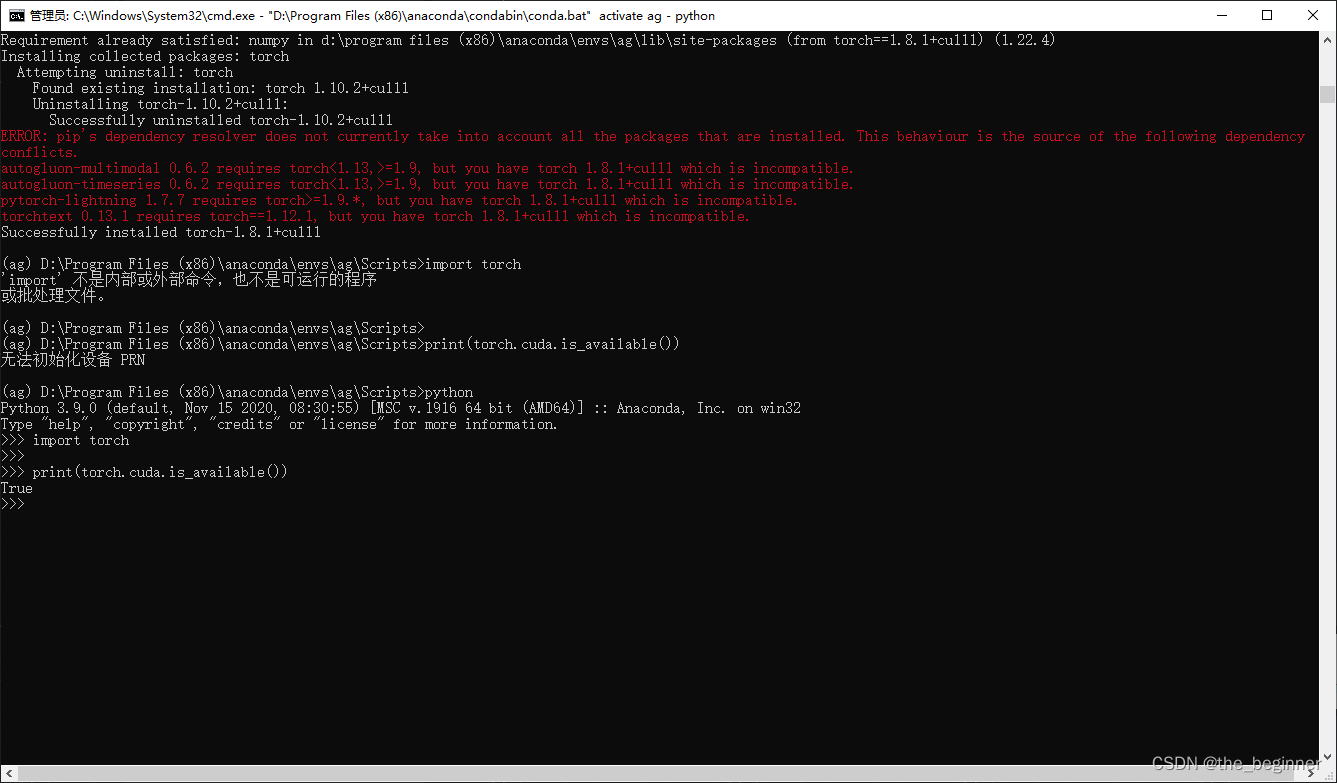
查看scikit-learn版本
import sklearn
print(sklearn.__version__)
查看PyTorch版本
import torch
print(torch.__version__)
运行结果
Python 3.9.0 (default, Nov 15 2020, 08:30:55) [MSC v.1916 64 bit (AMD64)] :: Anaconda, Inc. on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import torch
>>> print(torch.__version__)
1.12.1+cu113
>>> import sklearn
>>> print(sklearn.__version__)
1.2.2
>>>
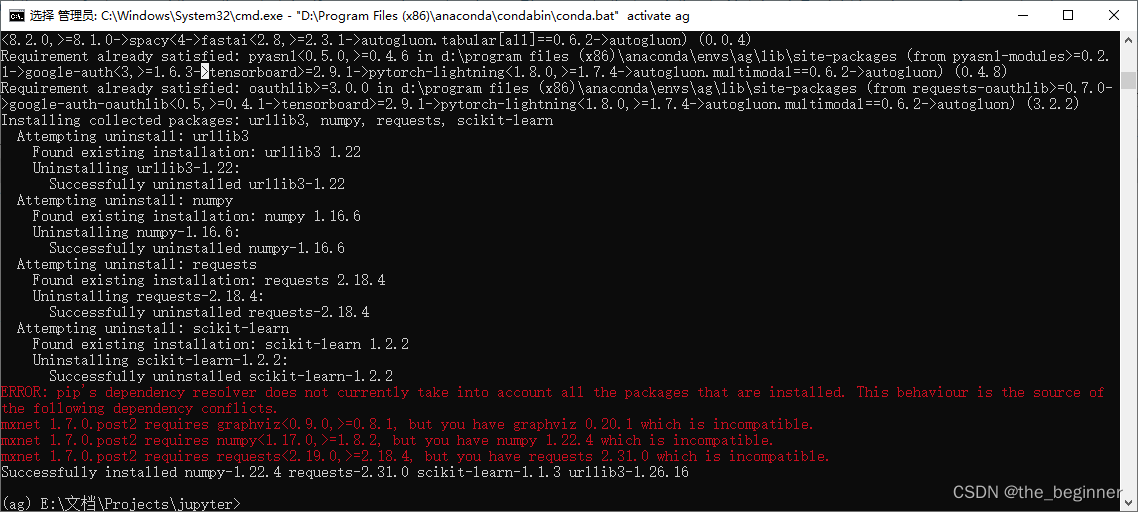
尝试卸载scikit-learn-1.2.2并安装其他软件包时,遇到了一些依赖冲突的问题。错误消息表明当前安装的graphviz、numpy和requests版本与mxnet 1.7.0.post2的要求不兼容。
降级冲突的软件包
pip install graphviz==0.8.1
pip install numpy==1.8.2
pip install requests==2.18.4
更新mxnet版本
pip install mxnet
移除冲突的软件包
pip uninstall graphviz numpy requests mxnet
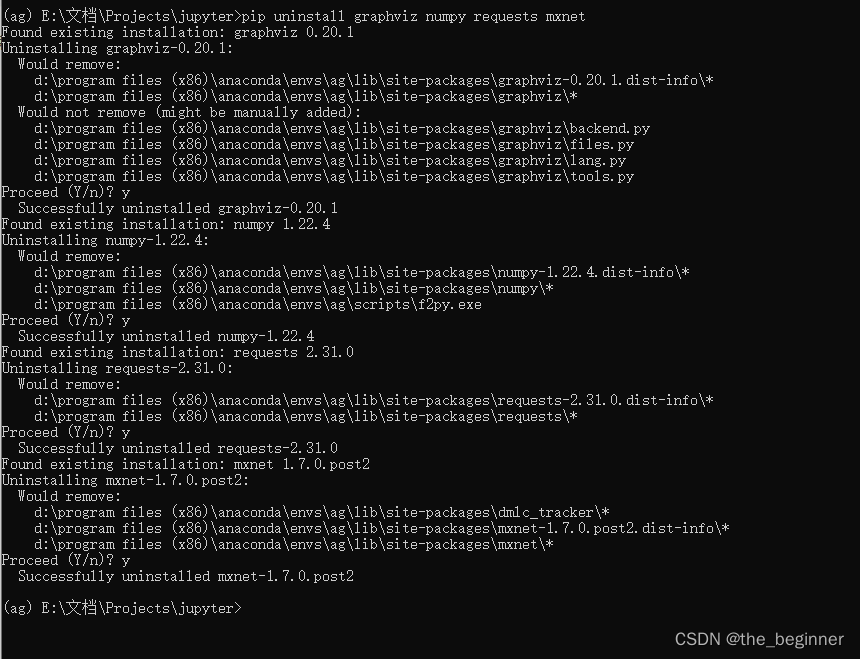
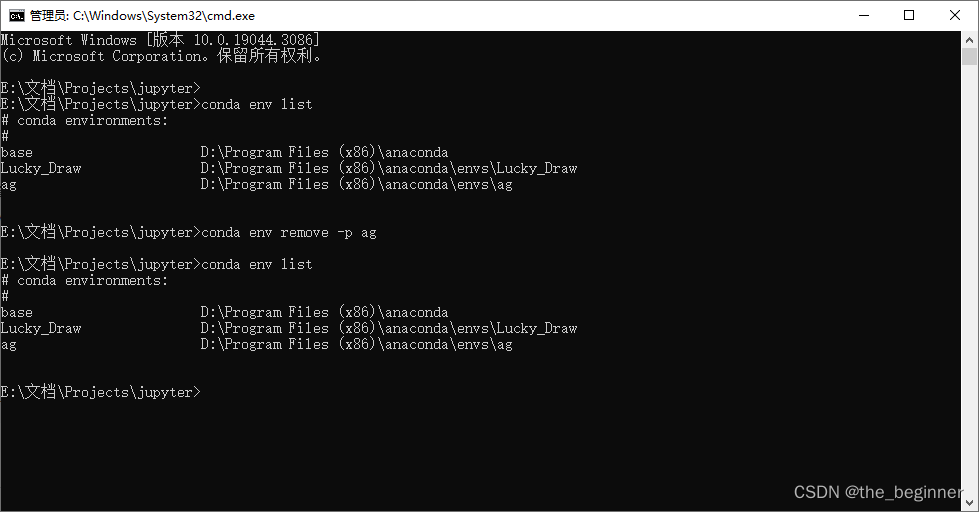
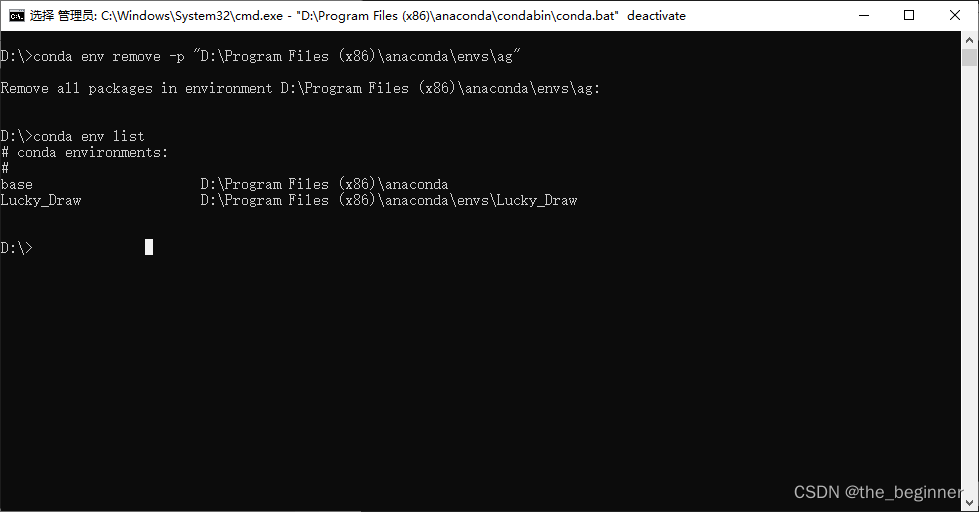
conda env remove -p "D:\Program Files (x86)\anaconda\envs\ag"
重新测试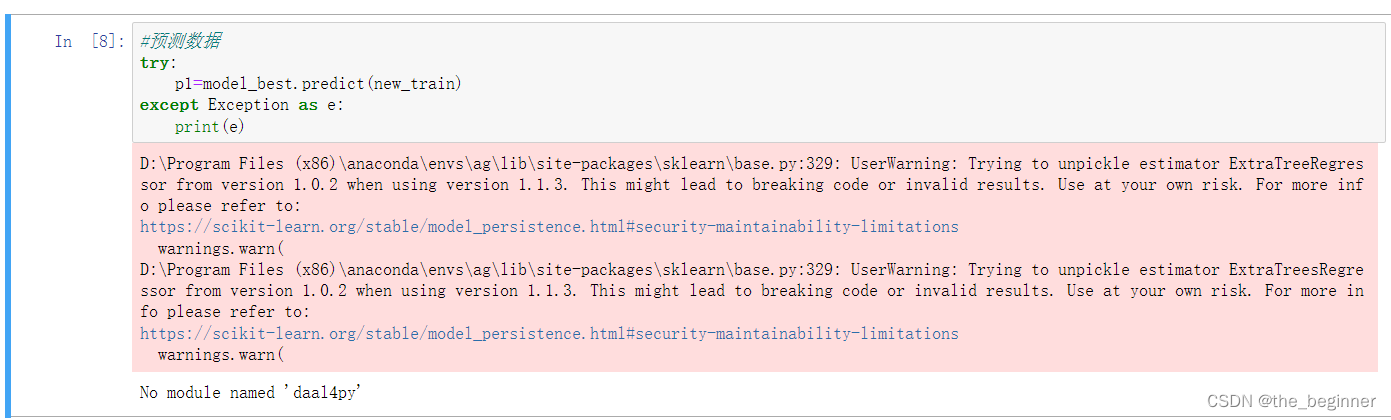
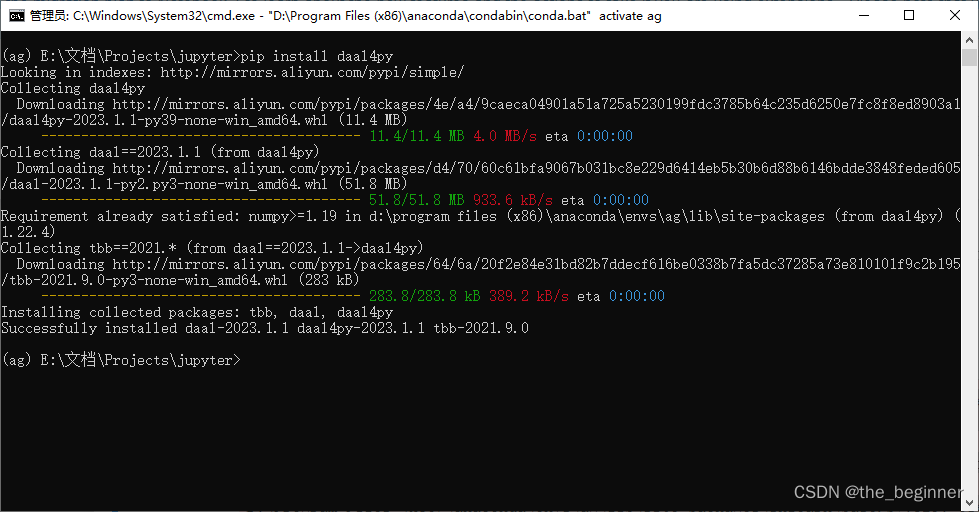
pip install daal4py
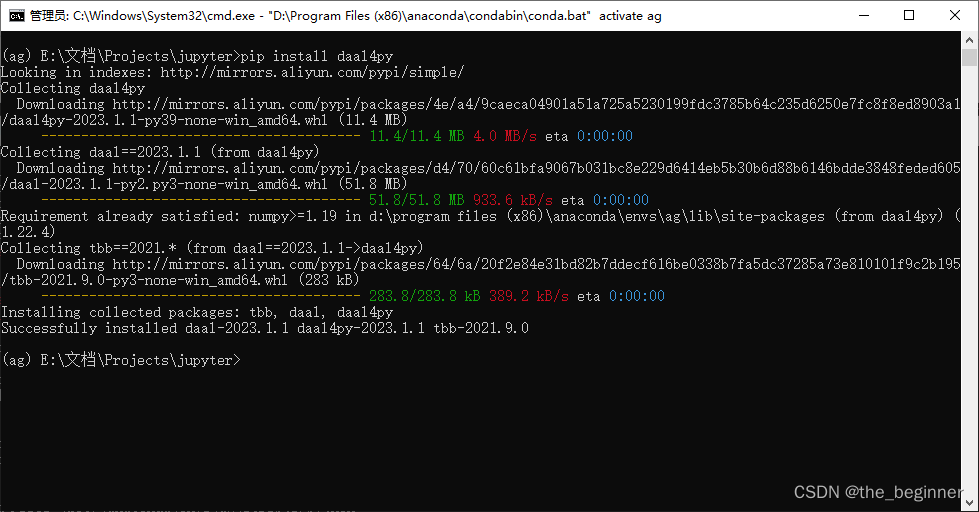
'SimpleImputer' object has no attribute '_fit_dtype'
解决办法
The warnings you are seeing are related to the scikit-learn library. These warnings indicate that you are trying to unpickle (deserialize) an object, specifically a StandardScaler and a SimpleImputer, that was created with scikit-learn version 1.0.2, but you are currently using version 1.1.3.
Unpickling objects that were created with a different scikit-learn version can lead to compatibility issues, breaking code, or producing invalid results. The warning advises you to use it at your own risk and provides a link to the scikit-learn documentation for more information on the limitations and potential issues related to model persistence.
If you encounter this warning, it is recommended to update the pickled objects (StandardScaler and SimpleImputer) using the scikit-learn version that matches your current environment (1.1.3 in your case) to ensure compatibility and avoid any potential problems.
中文回复
你好!收到了你的问题。这些警告信息是与scikit-learn库相关的。警告表明你正在尝试反序列化(unpickle)一个对象,具体是一个StandardScaler和一个SimpleImputer,这些对象是使用scikit-learn版本1.0.2创建的,但你当前使用的版本是1.1.3。
尝试反序列化使用不同版本的scikit-learn创建的对象可能导致兼容性问题,破坏代码,或者产生无效的结果。警告建议你自担风险,并提供了一个链接到scikit-learn文档,以获取有关模型持久性的限制和潜在问题的更多信息。
如果你遇到这些警告,请务必使用与你当前环境匹配的scikit-learn版本(在你的情况下是1.1.3)来更新这些被pickle的对象(StandardScaler和SimpleImputer),以确保兼容性并避免潜在的问题。
解决办法:在当前环境下重新训练模型
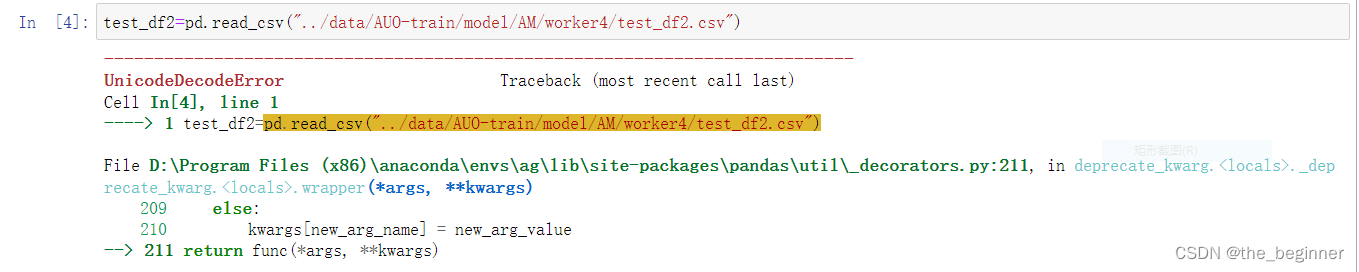
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\pandas\_libs\parsers.pyx:547, in pandas._libs.parsers.TextReader.__cinit__()
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\pandas\_libs\parsers.pyx:636, in pandas._libs.parsers.TextReader._get_header()
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\pandas\_libs\parsers.pyx:852, in pandas._libs.parsers.TextReader._tokenize_rows()
File D:\Program Files (x86)\anaconda\envs\ag\lib\site-packages\pandas\_libs\parsers.pyx:1965, in pandas._libs.parsers.raise_parser_error()
UnicodeDecodeError: 'utf-8' codec can't decode byte 0xb9 in position 2: invalid start byte
解答
The error message you provided suggests that there is an issue with decoding a byte sequence using the ‘utf-8’ codec in the pandas library. This error typically occurs when the file you are trying to read contains characters that cannot be decoded using the specified codec.
To resolve this issue, you can try the following steps:
Check the file encoding: Determine the actual encoding of the file you are trying to read. It’s possible that the file is encoded in a different format, such as ‘latin-1’ or ‘utf-16’. You can use the chardet library or a text editor that supports multiple encodings to identify the correct encoding.
Specify the correct encoding: Once you determine the correct encoding, you can explicitly specify it when reading the file using the encoding parameter in the pandas read_csv() or read_excel() function. For example:
import pandas as pd
# Specify the correct encoding
encoding = 'latin-1'
# Read the file with the specified encoding
df = pd.read_csv('path/to/your/file.csv', encoding=encoding)
Replace ‘path/to/your/file.csv’ with the actual file path.
1.Handle encoding errors: If you encounter further encoding errors or inconsistencies within the file, you can handle them by using the errors parameter in the pandas read_csv() or read_excel() function. The errors parameter allows you to specify how encoding errors should be handled. You can set it to ‘ignore’ to skip the problematic rows or ‘replace’ to replace the problematic characters with a specified placeholder.
import pandas as pd
# Specify the correct encoding and handle errors
encoding = 'latin-1'
error_handling = 'ignore' # or 'replace'
# Read the file with the specified encoding and error handling
df = pd.read_csv('path/to/your/file.csv', encoding=encoding, errors=error_handling)
Remember to replace ‘path/to/your/file.csv’ with the actual file path.
By identifying the correct encoding and handling encoding errors appropriately, you should be able to read the file successfully with pandas.
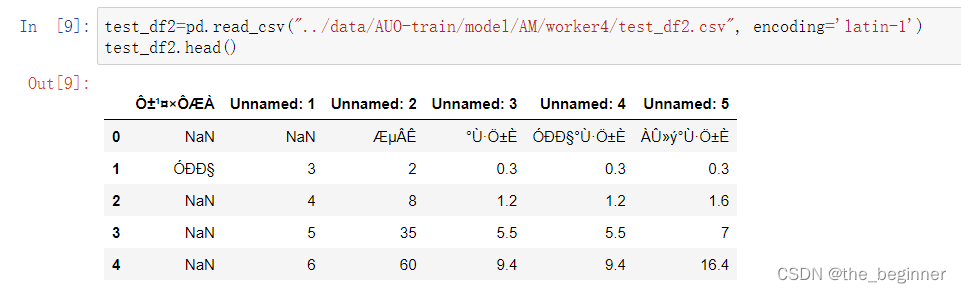
中文翻译
你好!根据你提供的错误信息,看起来是在使用 pandas 库的过程中遇到了解码问题。这个错误通常发生在尝试使用指定的 ‘utf-8’ 编码来解码包含无法使用该编码解码的字符的字节序列时。
要解决这个问题,你可以尝试以下步骤:
-
检查文件编码:确定你尝试读取的文件的实际编码。可能文件是以不同的格式编码的,比如 ‘latin-1’ 或 ‘utf-16’。你可以使用
chardet库或支持多种编码的文本编辑器来确定正确的编码方式。 -
指定正确的编码:一旦确定了正确的编码方式,你可以在使用 pandas 的
read_csv()或read_excel()函数读取文件时显式指定编码方式,使用encoding参数。例如:
import pandas as pd
# 指定正确的编码方式
encoding = 'latin-1'
# 使用指定的编码方式读取文件
df = pd.read_csv('文件路径.csv', encoding=encoding)
请将 '文件路径.csv' 替换为实际的文件路径。
- 处理编码错误:如果在文件中遇到进一步的编码错误或不一致,你可以使用 pandas 的
read_csv()或read_excel()函数的errors参数来处理它们。errors参数允许你指定如何处理编码错误。你可以将其设置为'ignore'来跳过有问题的行,或者设置为'replace'来用指定的占位符替换有问题的字符。
import pandas as pd
# 指定正确的编码方式并处理错误
encoding = 'latin-1'
error_handling = 'ignore' # 或 'replace'
# 使用指定的编码方式和错误处理方式读取文件
df = pd.read_csv('文件路径.csv', encoding=encoding, errors=error_handling)
请记得将 '文件路径.csv' 替换为实际的文件路径。
通过确定正确的编码方式并适当处理编码错误,你应该能够成功使用 pandas 读取文件。如有任何进一步的问题,请随时提问!















 4626
4626











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









