







一、什么是推荐系统:
根据用户需求、兴趣等,通过推荐算法从海量数据中挖掘出用户感兴趣的项目(如信息、服务、物品等),并将结果以个性化列表的形式推荐给用户。推荐系统的核心是推荐算法,它利用用户与项目之间的二元关系,基于用户历史行为记录或相似性关系帮助发现用户可能感兴趣的项目
推荐算法的形式化定义:用U 表 示 所 有 用 户(User)的集合,用I表示所有项目(item)的集合.在实际系统中,U 和I 具有非常大的规模.定定义一个效用函数s,用来计算项目i对用户u 的推荐度,即s:U×I→R,其中R是一个全序集合。推荐算法的研究问题就是通过计算推荐度为每一个用户u∈U 找到其最感兴趣的项目i′∈I,如下:
。
推 荐 系 统 面 临 的 一个关键问题是效用函数s通常定义在U×I的一个子空间上,推荐算法 必 须 将s外 推 到 整 个U×I空间.例如,我们通常 将 推 荐 度 定 义 为 用 户 对 项 目 的评分,但真实的推 荐 系 统 中,用 户 仅 仅 评 分 了 一 小部分项目,因此在选择推荐度最高的 项目推荐给用户之前,必须先根据已知的评分来 实现对未知评分的预测,这就 是 外 推 的 过 程.推 荐 算 法 对 未 知评分的预测能够 采 用 不 同 的 方 法,包 括 近 似 理 论、机器学习和各种启发式方法等。
目的:快速有效的从纷繁复杂的数据中获取有价值的信息。解决信息过载问题
二、传统的推荐方法
- 关联规则推荐:基于关联规则的推荐算法,应用统计学知识在数据分析的基础上寻找数据集间的相关性。首先找出事件中频繁发生的项目之间的关联特性,形成X→Y形式的关联规则,得到用户感兴趣的内容,然后进行关联推荐。如果某一规则同时满足最小支持度(事件X和事件Y同时发生的概率称为支持度)和最小置信度(在发生X的基础上发生事件Y的概率称为置信度),则称次为强规则关联规则推荐过程:首先设定最小支持度和最小置信度,然后从数据中找到不低于最小支持度的频繁项集,再利用前一步中得到的高频项集来产生满足最小置信度的强规则,最后根据强规则进行推荐。关联规则的相关算法有:Apriori算法、基于划分的算法、FP-树频集算法。该算法的优点是,产生的推荐列表准确性较高,通常用于捆绑销售(强规则)和竞品分析(弱规则)。
- 协同过滤推荐(collaborative filtering recommendation):最经典的推荐算法。基本思想:利用相似用户之间具有相似兴趣偏好的方法,来发现用户对项目的潜在偏好。主要包括:启发式和基于模型两种类型。启发式方法首先通过用户的历史评分差异计算用户(或者项目)之间的相似度,然后根据用户的历史评分和用户之间的相似度计算效用值;基于模型的方法主要通过构建一个用户偏好模型预测用户对项目的潜在偏好。经典的协同过滤算法如:矩阵因子分解,利用用户与项目之间的交互信息为用户进行推荐。是目前应用最为广泛的推荐算法。优点:仅仅需要利用用户的历史评分数据,因此简单有效,是目前应用最为成功的推荐方法.缺点:数据稀疏严重(一个用户评分过的项目仅仅占总项目数量的极少部分)和冷启动问题(新的用户和新的项目往往没有评分数据)。经典的协同过滤算法(CF)采用浅层模型无法学到用户和项目的深层次特征。
- 基于内容的推荐(content-based recommendation):主要根据用户已经选择或者评分的项目,挖掘其它内容上相似的项目作为推荐。首先通过显式反馈(例如评分、喜欢/不喜欢)或隐式反馈(例如观看、搜索、点击、购买等行为)的方式获取用户交互过的项目,然后从这些项目的特征中学习用户的偏好并表示为特征,就能计算用户与待预测项目在内容(由特征刻画)上的匹配度(或相似度),最后根据匹配度对所有待预测项目进行排序,从而为用户推荐潜在感兴趣的项目.基于内容推荐方法的优点:①不需要其他用户数据,不存在冷启动和数据稀疏问题;②可以为有特殊兴趣爱好的用户进行推荐;③对推荐出的项目具有可解释性。缺点是要求内容能抽象成有意义的特征(特征提取困难),且特征内容结构性较好。
- 混合推荐(hybrid recommendation):融合多源异构辅助信息(side information)的混合推荐方法由于能够缓解传统推荐系统中的数据稀疏和冷启动问题,而越来越受到重视,但是由于辅助信息往往具有多模态、数据异构、大规模、数据稀疏和分布不均匀等复杂特征。单一的推荐算法各有各的不足,通过组合不同的推荐算法进行混合推荐可以产生优质的推荐效果。常见的组合策略有:后融合,将多种推荐算法产生的结果以投票或者线性加权等方式组合来产生最终的推荐结果;中融合,以一种推荐算法为主,同时融合另一种推荐算法;前融合,将多种推荐算法集成到统一的模型当中,然后将各类数据中提取的特征输入到模型中,最后产生统一的结果。辅助信息往往具有多模态、数据异构、大规模、数据稀疏和分布不均匀等复杂特征,融合多源异构数据的混合推荐方法研究依然面临着严峻的挑战
总结:①经典的协同过滤方法采用浅层模型无法学习到用户和项目的深层次特征;②基于内容的推荐方法利用用户已选择的项目来寻找其它类似属性的项目进行推荐,但是这种方法需要有效的特征提取,传统的浅层模型依赖于人工设计特征(先验知识),其有效性及可扩展性非常有限,制约了基于内容的推荐方法的性能。
新的推荐算法:基于社交网络的推荐方法、情境感知的推荐方法等
注:多源异构数据指:随着互联网中越来越多的数据能够被感知获取,包括图像、文本、标签在内的多源异构数据蕴含着丰富的用户行为信息及个性化需求信息。
三、深度学习
深度学习通过组合低层特征形成更加稠密的高层语义抽象,从而自动发现数据的分布式特征表示,解决了传统机器学习中需要人工设计特征的问题,在图像识别、机器翻译、语音识别和在线广告等领域取得了突破性进展。在推荐系统领域有利于提取用户项目的深层特征,提高推荐准确的。
1.自编码器(Autoencoder,AE):用于高维复杂数据处理.通过一个编码和一个解码过程来重构输入数据,学习数据的隐层表示.基本的自编码器可视为一个三层神经网络结构:一个输入层x、一个隐层h和一个输 出 层y,其中输出层和输入层具有相同的规模,结构如图1所示:自编码器的目的是使得输入x与输出y 尽可能接近,这种接近程度通过重构误差表示,根据数据的不同形式,通常重构误差有均方误差和交叉熵两种定义方式。如果仅仅通过最小化输入输出之间的误差来实现对模型的训练,自编码器很容易学习到一个恒等函数.为了解决这个问题,研究者提出了一系列自编码器的变种,比较经典的有:稀疏自编码器和降噪自编码器。
稀疏自编码器:通过在损失函数中加入L1正则项,其目的是对过大的权重进行惩罚,使隐层表示中的大量节点为0,从而确保隐层表示尽量稀疏。
降噪自编码器则是通过在自动编码器的输入数据中加入噪声得到,这样降噪自编码器在重构输入数据时,就被迫去除这种
噪声来学习到更加鲁棒的输入数据的表达,降噪自编码器通过这种方式提升了泛化能力。
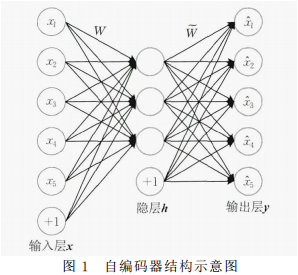
自编码器,尤其是栈式降噪自编码器,在推荐系统中主要被应用于学习用户和项目的隐层特征表
示,其通过对用户或项目相关的信息(包括评分数据和文本、图像等信息)进行重构学习到用户或项目的隐表示,然后基于这种隐表示预测用户对项目的偏好.应用场景主要包括评分预测、文本推荐、图像推荐等。
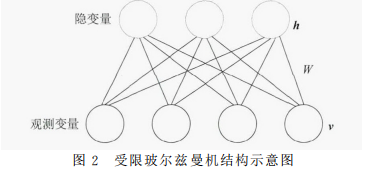
2.受限玻尔兹曼机(Restricted Boltzmann Machine, RBM ):玻尔兹曼机(BM)是一种生成式随机神经网络,BM 由一些可见单元(对应可见变量,亦即数据样本)和一些隐层单元(对应隐层变量)构成,可见变量和隐层变量都是二元变量,其状 态取0-1,状态0表示该神经元处于抑制状态,状态1代表该神经元处于激活状态.BM 能够学习数据中复杂的规则,具有强大的无监督学习能力。但是BM训练过程异常耗时。RBM是对BM的改进,其在玻尔兹曼机的基础上,通过去除同层变量之间的所有连接极大地提高了学习效率.受限玻尔兹曼机的结构如图2所示,包括可见层v以及隐层h,两层之间的节点是全连接的,同层节点间是互不连接的。从 RBM 的结构可以发现,在给定隐层单元的状态时,可见层单元之间是条件独立的;反之,在给定可见层单元的状态时,各隐层单元之间也条件独立。RBM 是推荐系统中最早被应用的神经网络模型,当前的应用主要是通过对用户的评分数据进行重构学习到用户的隐表示,从而实现对未知评分的预测.应用场景主要是用户评分预测
3.深度信念网络(Deep Belief Network,DBN):是一种由多层非线性变量连接组成的生成式模型。在深度信念
网络中,靠近可见层的部分是多个贝叶斯信念网络,最远离可见层的部分则是一个 RBM,其结构如图3所示.DBN 的结构可以看作由多个受限玻尔兹曼机层叠构成,网络中前一个 RBM 的隐层视为下一 个RBM 的可见层.这样,在 DBN 的训练过程中,每一个 RBM 都可以使用上一个 RBM 的输出单独训练,因此与传统的神经网络相 比,DBN 的训练更加简单.同时,通过这种训练方法&
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









