






文章目录
一、ARM指令流水线分析及伪指令
在ARM核中,为增加处理器指令流的速度,ARM7系列使用3级流水线。允许多个操作同时处理,而非顺序执行。不同的ARM核,流水线的级数是不一样的,ARM核版本越高,流水线级数越多。对于软件工程师编程而言,统一按照三级流水线来分析就可以了。
PC指向正被取指的指令,而非正在执行的指令

1. 最佳流水线

该例中用5个时钟周期执行了5条指令,所有的操作都在寄存器中(单周期执行)
指令周期数(CPI)=1
2. 内存访问指令流水线

该例中,用6周期执行了4条指令,指令周期数(CPI)=1.5
3. 分支流水线

4. ARM伪指令、汇编与C混合编程、Volatile关键字
伪指令定义:
为了方便程序员使用,编译器设计的指令,这个指令ARM核无法直接识别,需要编译器对他翻译成ARM核所能识别的指令。
(1)LDR R0,=0x12345678分析
再次强调:PC指向正被取指的指令,而非正在执行的指令
如何看内存中的12345678
正在读取的LDR内存是0x0008 加上 PC所在的地址(因为LDR正在执行 所以pc等于0x0000000C预取的值)
也就是0x0008加上pc的值0x0000000C等于0x00000014

总结
编译器在编译的时候,将Idr r0,=0x12345678翻译成了ldr r0,[pc,#0x0008]这一条读内存的指令。根据PC的值加上偏移量算出0x12345678这个数据在内存的地址,然后使用Idr指令读取这个地址的数据。
(2)LDR R0,=Label 分析
1) 链接地址指定为0x0情况分析
0x00000018等于0x000C加上pc的值0x000C
注意 0x00000018的值是14 这是个值 是编译器算出来的一个值


2) 链接地址指定为0x2000情况分析
修改链接地址

再运行
label的地址也就是0x000c+pc的值0x0000200c=0x00002018

3) 总结
LDR r0,=Label指令表示将Label的值写入r0,Label的值由指定的代码段运行地址(-Ttext=地址值)来决定。
编译器做法:
- 首先根据指定的代码段开始的地址,算出Label标签对应的地址值
- 然后将这个表示的地址值存放在一个位置
- 生成内存访问指令,根据pc +固定偏移量,找到标签对应值存放的位置
注意
当代码编译结束的时候,标签表示的地址值(根据指定的代码段地址)已经编译死存放在程序文件中了。
(3)LDR R0,Label
LDR R0,Label 表示读取Label表示的地址对应数据
不带=的时候 存的是标签里的内容

(4)ADR R0,Label分析
动态方式 根据pc的值+0x00000008
之前是静态的 在编译完的时候 label就已经确定值是什么了
这个是动态
举个例子:如果是用
LDR我把这个代码放到A内存和B内存运行
这两块内存的值是一模一样的 因为在编译完的时候 label就已经确定值是什么了
如果是ADRA内存的0x0008 和B内存的0x0008 是不一样的
有点难理解

ADR R0,Label指令表示根据当前的PC的值 +/-偏移量,动态获取当前Label所表示的内存地址
(5)如何判别代码在实际内存中运行的地址?
ADR r0,_start可以知道,因为他是根据pc的值,动态获取
LDR r0,=_start无法知道,这条指令不论在哪里运行,r0的值都是固定(取决于指定的链接地址)
二、ATPCS标准
1. ATPCS标准介绍
ATPCS是ARM-Thumb Procedure Call Standard 的缩写,也就是ARM-Thumb的程序调用标准.
Synonym表示同义词 Special表示特殊的名字
r0-r4 一般用来做参数传递
r4-r7 一般用来做变量
r8-r11 一般用来做参数传递和特殊功能
r12-r15 特殊功能
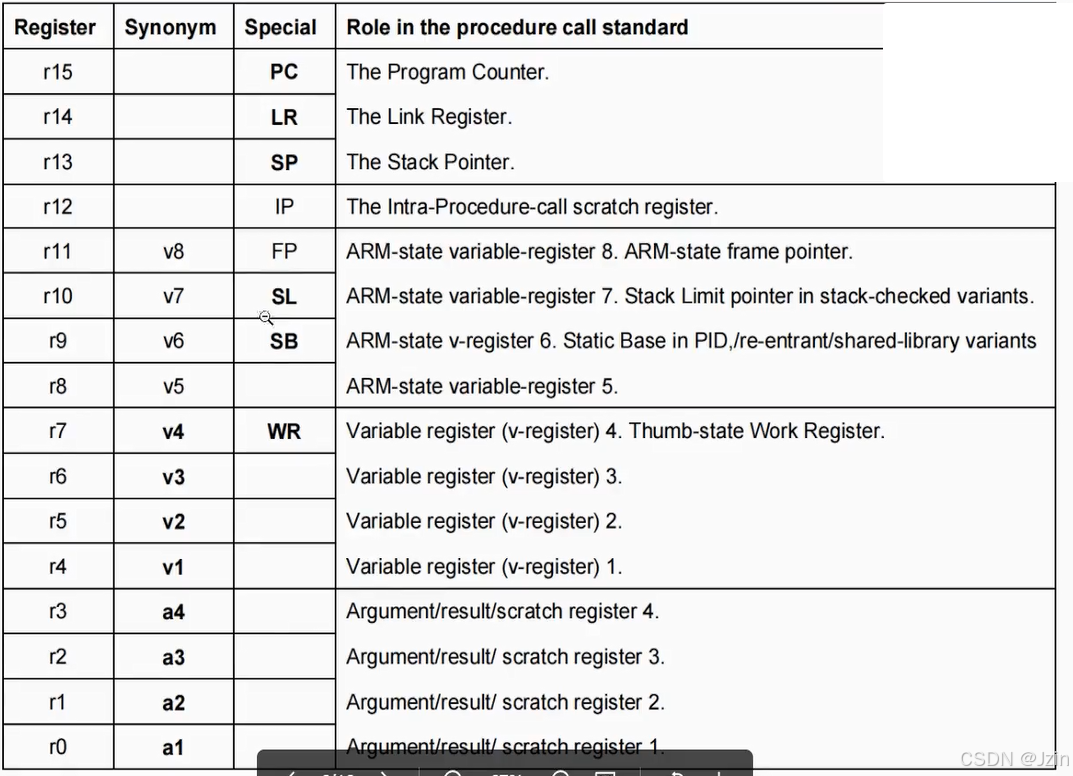
The first four registers rO-r3 are used to pass parameter values into a routine and result values out of a routine, and to hold intermediate values within a routine (but, in general, only between subroutine calls). In ARM-state, register r12-also called Ip-can also be used to hold intermediate values between subroutine calls.
前四个寄存器r0-r3用于将参数值传递给例程,并将结果值传递给例程,并在例程内保存中间值(但通常仅在子程序调用之间)。在ARM状态下,寄存器r12也称为IP也可用于保存子程序调用之间的中间值。
Typically, the registers from r4 to r11 are used to hold the values of a routine’s local variables.They are also labeled v1-v8. Only v1-v4 can be used uniformly by the whole Thumb instruction set(shown emboldened)
通常,从r4到r11的寄存器用于保存例程局部变量的值。它们也被标记为v1-v8。只有v1-v4可以被整个Thumb指令集统一使用(如图所示)
In all variants of the procedure call standard, registers r12-r15 have special roles. In these roles they are labeled IP, SP, LR and PC (or ip, sp, lr, and pc, but this specification uses the upper case name for the special role).
在过程调用标准的所有变体中,寄存器r12-r15都有特殊角色。在这些角色中,它们被标记为IP、SP、LR和PC(或ip、sp、lr和pc,但本规范使用大写名称来表示特殊角色)。
Only registers r0-r7, SP, LR and Pc are ubiquitously available in Thumb state. Their synonyms and special names are shown emboldened. Few Thumb instructions can access the high registers, v5-v8, SB, SL and IP.
只有寄存器r0-r7、SP、LR和PC在Thumb状态下普遍可用。它们的同义词和特殊名称显示得更加大胆。很少有Thumb指令可以访问高寄存器、v5-v8、SB、SL和IP。
2. 参数传递
函数间传递参数的时候,当参数不超过4个时,可以使用毒存器R0~R3来进行参数传递,当参数超过4个时,还可以使用数据栈来传递参数,在参数传递时,将所有参数看做是存放在连续的内存单元中的字数据。然后,依次将各名字数据传送到寄存器R0,R1,R2,R3;如果参数多于4个,将剩余的字数据传送到数据栈中,入栈的顺序与参数顺序相反,即最后一个字数据先入栈.
所以在写C程序进行函数传参的时候,最好不要超过4个参数,这样可以提高效率。

3. 函数返回值
- 返回值为一个32位的整数时,可以通过寄存器R0返回
- 返回值为一个64位整数时,可以通过R0和R1返回,依此类推
4. 栈帧分析
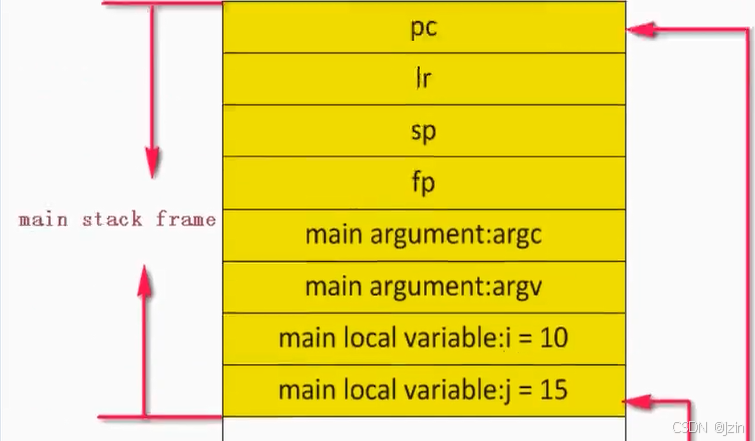

上图描述的是ARM的栈帧布局方式,main stack frame为调用函数的栈帧,func1 stack frame为当前函数(被调用者)的栈帧,栈底在高地址,栈向下增长。
图中FP就是栈基址,它指向函数的栈帧起始地址;SP则是函数的指针,它指向栈顶的位置。
ARM压栈的顺序很是规矩,依次为当前函数指针PC、返回指针LR、栈指针SP、栈基址FP、传入参数个数及指针、本地变量和临时变量。
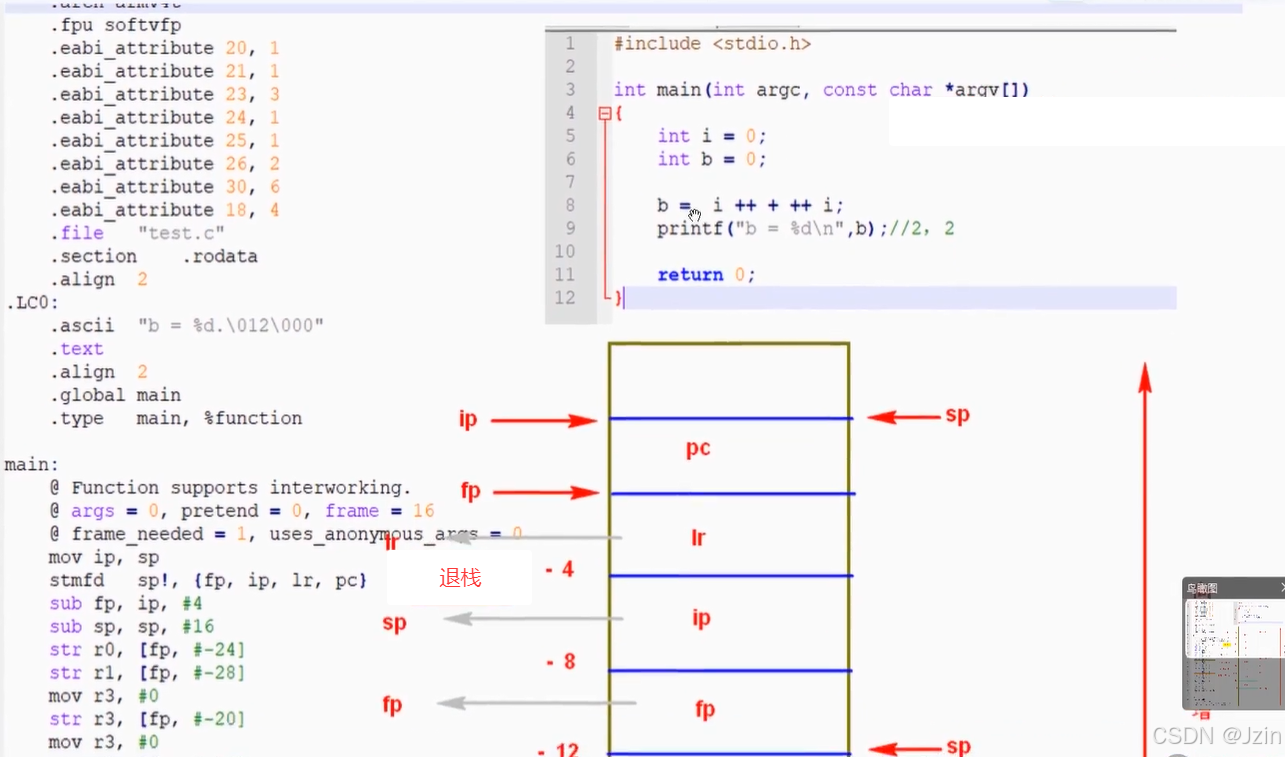
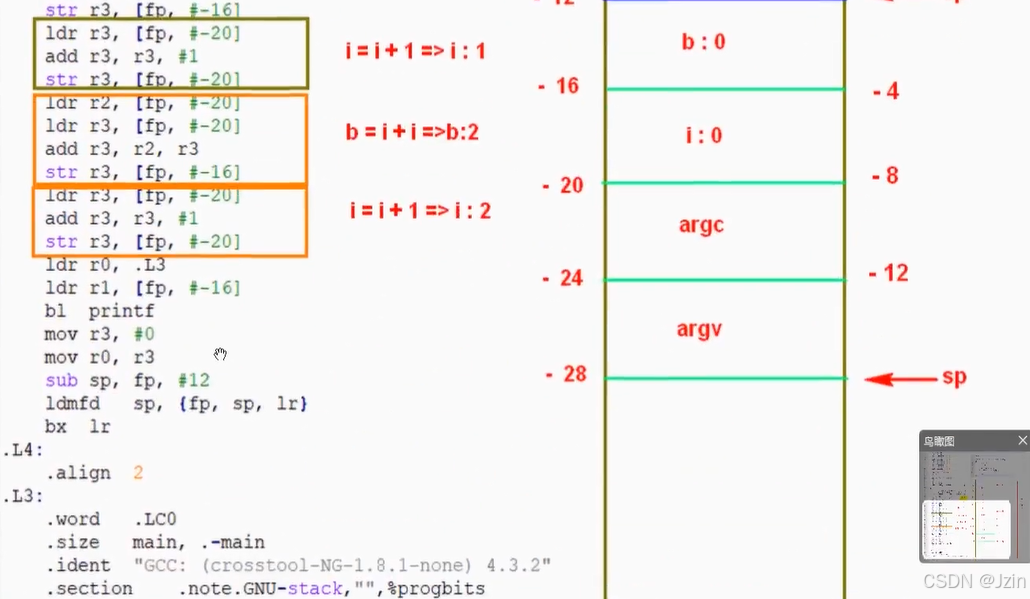
5. 反汇编分析APTCS标准
我目前无法描述 晕
三、汇编与C混合编程
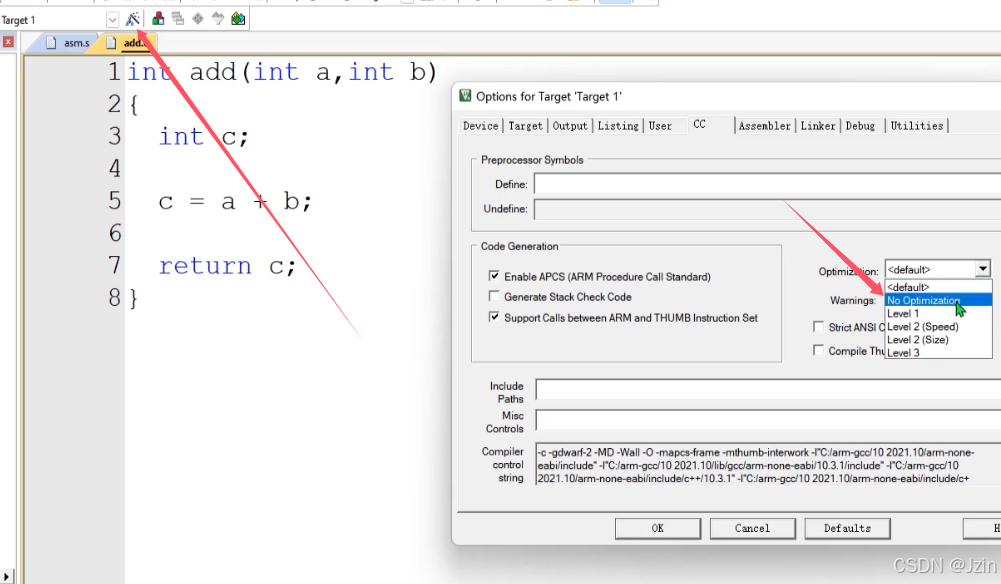
1. 汇编语言调用C语言
注意 编译器默认开启了优化要选择No


2. C语言内嵌汇编
asm(
"指令1\n"
"指令2\n”
……
:输出列表
:输入列表
:修改列表(通用的寄存器)
);
指令:ARM汇编指令
输出列表:将内嵌汇编中的寄存器值输出到c变量
输入列表:将c变量输入到内联汇编中使用的寄存器
修改列表:内联汇编中修改的寄存器

| 修饰符 | 说明 |
|---|---|
| 无 | 被修饰的操作符是只读的 |
| = | 被修饰的操作符只写 |
| + | 被修饰的操作符具有可读写的属性 |
| & | 被修饰的操作符只能作为输出 |
四、volatile 关键字
1. gcc优化
gcc编译器常用的优化级别有三个:
- 01 一级优化
- 02(speed) / Os(size) 二级优化
- 03 三级优化
优化的思想:
如果我们在前面已经将这个变量所对应的内存数据读到寄存器中,而当我们再次需要读这个
变量所对应内存的数据的时候,编译器认为前面我们已经在寄存器中,存放过值了,为了提
高效率,它直接会使用上一次寄存器中的值,而不重新从内存中读值。

翻译为汇编代码 使用O1
注意 使用gcc需要使用arm内核 不能是Intel或amd

汇编代码
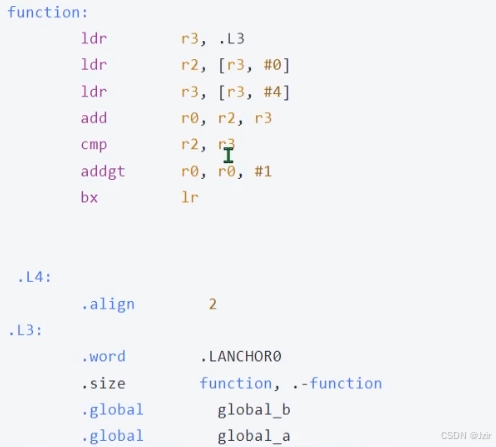
优化带来的问题:
如果内存中的值已经被其他的执行单元(中断处理函数或其他线程)做了更改,而优化之后的
代码每次从寄存器中读值,就会带来寄存器中的值和内存中的值不一致的问题
比如:如果是多线程呢 此时内存已经发生变化了 但是还是使用了cmp r2,r3并没有重新读值 这是错误的
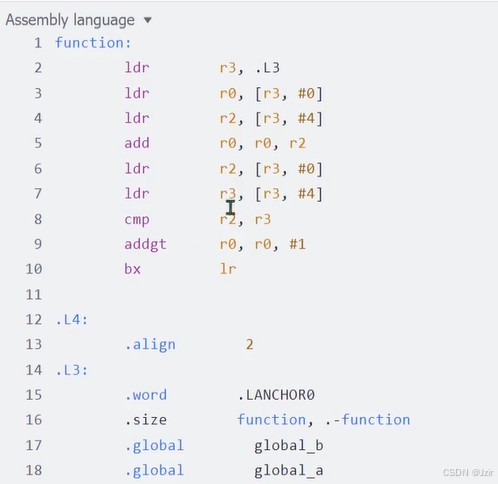
2. volatile关键字
用途:
volatile(易改变的)修饰一个变量,防止编译器优化(本质),告诉编译器每次在使用这个变量的时候,必须从变量所在的内存中重新读值

翻译后:



















 1668
1668

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











