







MySQL优化三
1. 排序优化
永远小表驱动大表
for i in range(5):
for j in range(1000):
pass
for i in range(1000):
for j in range(5):
pass
order by优化
order by子句,尽量使用index方式排序,避免使用filesort方式排序
建表,插入测试数据
create table tbla(
age int,
birth timestamp not null
);

插入数据
insert into tbla(age,birth) values(22,now());
insert into tbla(age,birth) values(23,now());
insert into tbla(age,birth) values(24,now());
建立索引
create index idx_tbla_agebrith on tbla(age,birth);

没出现文件内排序



出现了文件内排序的情况




分析
MySQL支持两种方式的排序,filesort和index,index效率高,MySQL扫描索引本身完成排序。filesort方式效率较低
order by 满足两种情况下,会使用index方式排序
- 1.order by 语句使用索引最左前列
- 2.使用where子句与order by子句条件组合满足索引最左前列

Filesort 是在内存中还是在磁盘中完成排序的?
MySQL 中的 Filesort 并不一定是在磁盘文件中进行排序的,也有可能在内存中排序,内存排序还是磁盘排序取决于排序的数据大小和 sort_buffer_size 配置的大小。
- 如果 “排序的数据大小” < sort_buffer_size: 内存排序
- 如果 “排序的数据大小” > sort_buffer_size: 磁盘排序
filesort有两种算法-双路排序和单路排序
双路排序,MySQL4.1之前是使用双路排序,字面意思就是两次扫描磁盘,最终得到数据,读取行指针和order by列,对他们进行排序,然后扫描已经排序好的列表,按照列表中的值重新从列表中读取对应的数据输出
单路排序,从磁盘读取查询需要的所有列,按照order by列在buffer对他们进行排序,然后扫描排序后的列表进行输出,它的效率更快一些,避免了第二次读取数据,并且把随机IO变成了顺序IO,但是它会使用更多的空间
优化策略调整MySQL参数
增加sort_buffer_size参数设置
增大max_lenght_for_sort_data参数的设置
提高order by的速度
- order by时select * 是一个大忌,只写需要的字段
- 当查询的字段大小总和小于max_length_for_sort_data而且排序字段不是 text|blob类型时,会用改进后的算法–单路排序
- 两种算法的数据都有可能超出sort_buffer的容量,超出之后,会创建tmp文件进行合并排序,导致多次I/O
- 尝试提高sort_buffer_size
- 尝试提高max_length_for_sort_data
以下情况会不会出现文件内排序
索引 a_b_c(a,b,c)
order by a,b 不会
order by a,b,c 不会
order by a desc,b desc,c desc 会
where a = const order by b,c 不会
where a = const and b = const order by c 不会
where a = const and b > const order by b,c 会
order by a asc,b desc,c desc 会
where g = const order by b,c 会
where a = const order by c 会
where a = const order by by a,d 会
2. 分页查询优化
很多时候,业务上会有分页操作的需求,对应的 SQL 类似下面这条:
select a,b,c from t1 limit 10000,10;
表示从表 t1 中取出从 10001 行开始的 10 行记录。看似只查询了 10 条记录,实际这条 SQL 是先读取 10010 条记录,然后抛弃前 10000 条记录,然后读到后面 10 条想要的数据。因此要查询一张大表比较靠后的数据,执行效率是非常低的。
分析两种情况的分页查询
- 根据自增且连续主键排序的分页查询
- 查询根据非主键字段排序的分页查询
根据自增且连续主键排序的分页查询
首先来看一个根据自增且连续主键排序的分页查询的例子
select * from t1 limit 99000,2;
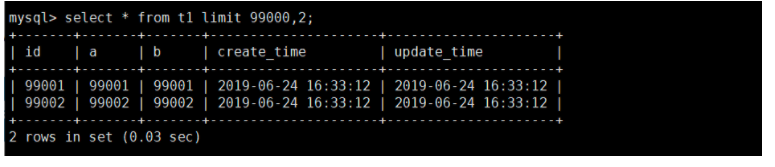
该 SQL 表示查询从第 99001开始的两行数据,没添加单独 order by,表示通过主键排序。我们再看表 t1,因为主键是自增并且连续的,所以可以改写成按照主键去查询从第 99001开始的两行数据,如下:
select * from t1 where id >99000 limit 2;
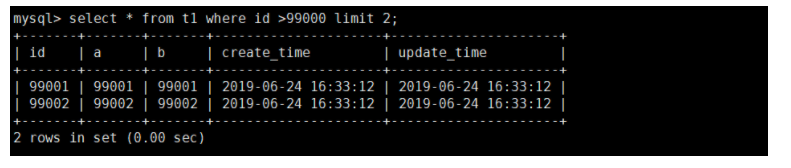
查询的结果是一致的。我们再对比一下执行计划:

原 SQL 中 key 字段为 NULL,表示未走索引,rows 显示 99965,表示扫描的行数 99965行;
改写后的 SQL key 字段为 PRIMARY,表示走了主键索引,扫描了1000行。
显然改写后的 SQL 执行效率更高。
但是,这条 SQL 在很多场景并不实用,因为表中可能某些记录被删后,主键空缺,导致结果不一致,如下图的实验(整个实验过程为:先删除一条前面的记录,然后再测试原 SQL 和优化后的 SQL):

可以发现两条 SQL 的结果并不一样,因此,如果主键不连续,不能使用上面描述的优化方法。
另外如果原 SQL 是 order by 非主键的字段,按照上面说的方法改写会导致两条 SQL 的结果不一致。所以这种改写得满足以下两个条件:
- 主键自增且连续
- 结果是按照主键排序的
查询根据非主键字段排序的分页查询
再看一个根据非主键字段排序的分页查询,SQL 如下: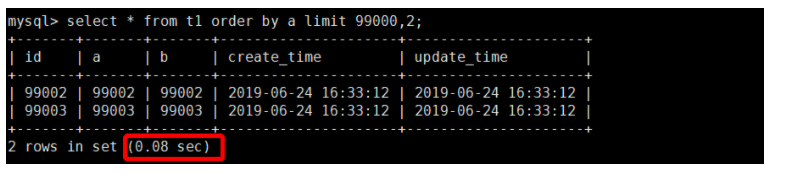
查询时间是 0.08 秒。
我们来看下这条 SQL 的执行计划:

其实关键是让排序时返回的字段尽可能少,所以可以让排序和分页操作先查出主键,然后根据主键查到对应的记录,SQL 改写如下
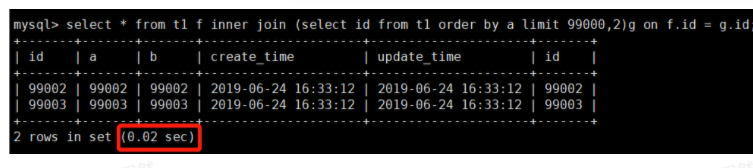
需要的结果与原 SQL 一致,执行时间 0.02 秒,是原 SQL 执行时间的四分之一,我们再对比优化前后的执行计划

对于其它一些复杂的分页查询,也基本可以按照这两个思路去优化,尤其是第二种优化方式。第一种优化方式需要主键连续,而主键连续对于一个正常业务表来说可能有点困难,总会有些数据行删除的,但是占用了一个主键 id。















 1560
1560











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









