







线性回归算法梳理
机器学习的一些概念
监督学习:通过已有的一部分输入数据和输出数据的对应关系来生成一个函数模型,将未来的输入映射到对应的输出。例如分类问题和回归问题。训练监督学习的数据集是已经标注好的数据集。
无监督学习:通过对原始的数据进行分类来给数据添加标签,无监督学习并不关心分类的类别。典型的无监督学习例子为聚类算法。
泛化能力:是指已经训练好的模型对新的数据进行识别的能力。类似于举一反三的能力。
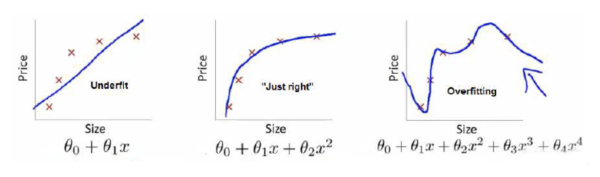
过拟合 :模型的复杂度很高,对于训练数据拟合的很好,但是由于模型复杂度高于实际模型而导致泛化能力很差。
欠拟合 : 欠拟合和过拟合是相对的,模型复杂度低于实际的情况,对训练数据拟合效果很差而导致泛化能力很差。
交叉验证(Cross Validation):有的时候也称作循环估计(Rotation Estimation),是一种统计学上将数据样本切割成较小子集的实用方法,该理论是由Seymour Geisser提出的。
在给定的建模样本中,拿出大部分样本进行建模型,留小部分样本用刚建立的模型进行预报,并求这小部分样本的预报误差,记录它们的平方加和。这个过程一直进行,直到所有的样本都被预报了一次而且仅被预报一次。把每个样本的预报误差平方加和,称为PRESS(predicted Error Sum of Squares)。
用交叉验证的目的是为了得到可靠稳定的模型。
线性回归原理
线性回归:给定由d个属性描述的示例 x = ( x 1 ; x 2 ; x 3 . . . ; x d ) x=(x_1;x_2;x_3 ...;x_d) x=(x1;x2;x3...;xd),其中 x i x_i xi是 x x x在第 i i i个属性上的取值,线性模型试图学的一个通过属性的线性组合来预测函数 ,即 f ( x ) = w 1 x 1 + w 2 x 2 + w 3 x 3 + . . . + w d x d + b f(x)=w_1x_1+w_2x_2+w_3x_3+...+w_dx_d+b f(x)=w1x1+w2x2+w3x3+...+wdxd+b
用向量表示为 f ( x ) = w T x + b f(x)=w^Tx+b f(x)=wTx+b
线性回归是给定数据集 D = ( x 1 , y 1 ) , ( x 2 , y 2 ) , . . . , ( x m , y m ) D={(x_1,y_1),(x_2,y_2),...,(x_m,y_m)} D=(x1,y1),(x
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









