






本来玩这些都是满足自己的爱好,然而嘛,,同学突然建议我写一些blog,我才突然想到,是哦,现在怎么投简历都是已读不回,索性把自己的项目都搬上来做个博客吧hhh,说不定也能为简历加点分,毕竟宜家揾食艰难哦~
这又是一篇python,没办法,python好写,是这样的
用到的所有分词文件我已经打包放在下面了,需要自取。
链接:https://pan.baidu.com/s/1f2pUhjFLvtA_SDLkR8wXtQ
提取码:2w8y
现在来讲讲难点吧~
mostdict = degree_word[degree_word.index('extreme') + 1: degree_word.index('very')] # 权重4,即在情感词前乘以4
verydict = degree_word[degree_word.index('very') + 1: degree_word.index('more')] # 权重3
moredict = degree_word[degree_word.index('more') + 1: degree_word.index('ish')] # 权重2
ishdict = degree_word[degree_word.index('ish') + 1: degree_word.index('last')] # 权重0.5
这里是权重文件,可以看到分成most,very,more等权重文件,对应到具体的词语中就是


然后就是停用词,我用的是哈尔滨工业大学的停用词,HITStop.txt,停用词就是把一句话拆成一个个词的词语,这点不再赘述。
def seg_depart(sentence):
sentence_depart = jieba.cut(sentence.strip('\n'))
res=[]
useless=[',',',','.','。','!','!','[',']','?','?','(',')','(',')','{','}','\n']
for i in sentence_depart:
if i not in useless :
res.append(i)
return res当然,还有标点符号,结合这俩再用jieba库就能把一句话拆成很多个词了。拆完后我们来打分。打分前我们还需要观察一个具有情感的词语的方向,比如不喜欢,前缀是不,那就是一个负分的情感了。代码如下:
def judgeodd(num):
if (num % 2) == 0:
return 'even'
else:
return 'odd' if judgeodd(c) == 'odd': # 扫描情感词前的否定词数
poscount *= -1.0
poscount2 += poscount
poscount = 0
poscount3 = poscount + poscount2 + poscount3
poscount2 = 0
else:
poscount3 = poscount + poscount2 + poscount3
poscount = 0
a = i + 1 # 情感词的位置变化还算简单吧?然后基于如上的基本逻辑,我们先随便找一段bilibili的弹幕,爬取b站弹幕见本人博客另一篇文章
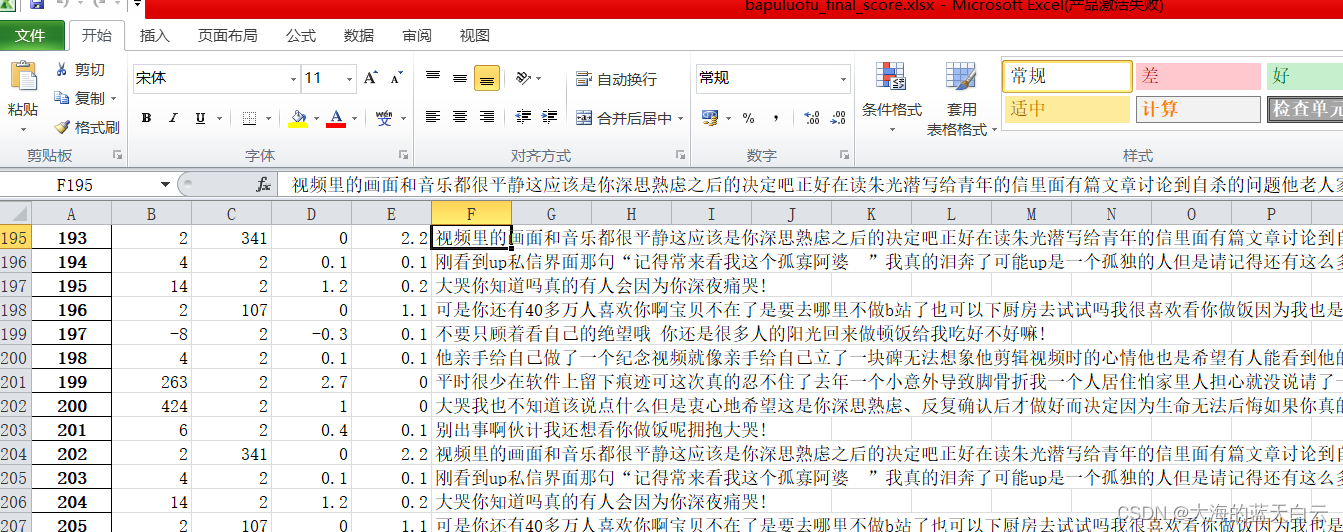
这个爬取的好像是一食纪的弹幕。没记错的话。然后打完分
嗯不错不错,分数打完了可以做LDA分析咯!无非就是把词语塞进一个html网页中,这个后续我们再说。需要完整代码请发邮件到xinkong@1418.com咨询我,备注来意。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









