







嵌入式AI快速入门课程-K510篇
| 属性 | 描述 |
|---|---|
| 类别 | 嵌入式AI开发 |
| 文档名 | 嵌入式AI快速入门手册-K510篇 |
| 当前版本 | 1.0 |
| 适用型号 | DongshanPI-Vision |
| 编辑 | 百问科技文档编辑团队 |
| 审核 | 韦东山 |
| 更新日期 | 更新内容 | 更新版本 |
|---|---|---|
| 2023/11/09 | 文档大纲编写完毕 | V1.0 |
文章目录
- 嵌入式AI快速入门课程-K510篇
- 第一篇 课程内容介绍及资料下载
- 第二篇 Ubuntu的基础操作
- 第三篇 环境搭建及开发板操作
- 1.配置VMware使用桥接网卡
- 2.安装软件
- 3.DongshanPI-Vision开发板基本操作
- 4.系统功能及AI应用初体验
- 5.编写一个简单的helloword程序
- 6.编译一个简单的AI demo程序
- 7.嵌入式开发
- 第四篇 AI概念及理论知识
第一篇 课程内容介绍及资料下载
1.嵌入式AI学习路线
1.1 嵌入式AI的组成
嵌入式AI由上层AI应用层和底层AI系统层组成,其实现AI任务的流程如下所示:
- 嵌入式AI应用中的功能模块可以通过申请嵌入式EAI系统服务;
- 嵌入式AI系统会基于模型文件对该功能模块相关的实时数据进行推理;
- 将推理的结果返回给功能模块。
其中对数据的产生处理都在本地进行,可降低数据的传输成本、安全以及决策的实时性。

那么我们想要学习嵌入式AI就需要学习下面部分:
- 数据层:学习如何在嵌入式设备中采集数据,对数据进行预处理,管理设备中所有AI功能所需要的数据。
- 模型层:也称算法模块,我们需要学习多种智能算法,由于不同的功能模块,需要使用不同的模型文件,而不同的模型文件对应不同的智能算法,同时还需要学习如何管理嵌入式AI系统使用的智能算法。
- 算力层:学习如何使用模型模块的算法和数据模块的数据进行推理,并将推理后的结果返回给上层应用中的功能模块。
- 功能模块:学习对推理的结果进行分析处理,并实现对应的AI任务,如:图像检测任务、语音识别任务等。
1.2 教学内容
本教程目前有如图1.2所示内容:

2.资料下载
2.1 资料列表
所有资料分 4 类:
- 开发板配套资料(原理图、虚拟机、烧写工具等),放在百度网盘;
- u-boot、linux 内核、buildroot 等比较大的源码,放在 GIT 仓库;
- 视频,在线观看,放在百问网、B 站等网站;
2.2 下载开发板配套资料
打开官网:https://www.100ask.net/,在首页点击“资料下载” 跳转到下载中心。在下载中心左侧选择开发板,点击后可以看到这一项,建议使用百度网盘下载,如图 2.2 所示
2.3 BSP
BSP,Board Support Package,指板级支持包,是构建嵌入式操作系统所 需的引导程序(Bootload)、内核(Kernel)、根文件系统(Rootfs)和工具链 (Toolchain)。 每种开发板的 BSP 都不一样,并且这些源码都非常庞大。我们把这些源码都 放在 git 仓库里,使用 repo 来管理、下载。 作为初学者,你甚至都还没有安装 Ubuntu、还不会使用 Ubuntu,所以先别 去下载它们。
2.4 在线视频
在线视频 视频可以在线观看,百问网、B 站上都有:
百问网(https://www.100ask.net/)
B 站(https://www.bilibili.com/):搜“韦东山”。为方便大家使用,这是 链接地址: https://space.bilibili.com/275908810/channel/seriesdetail?sid=1714177
2.5 资料更新
资料的更新 随着视频的录制,会发布更多的文档、源码,可以使用 GIT 查看更新信息。 可以每天使用“git pull”查看有无更新,一般更新了 GIT 就表示视频也有了 更新。也可以直接登录百问网(http://www.100ask.net)或是 B 站,查看视频 是否更新了。我们也会在公众号发布视频更新信息,发布其他重大消息,可以关注公众号。

第二篇 Ubuntu的基础操作
具体操作视频链接:https://www.bilibili.com/video/BV19A411J7ci
1. 安装 VMware 运行 Ubuntu
1.1 安装 VMware
Windows 下有很多虚拟机软件,目前市面上流行的有 VMware 和 VirtualBox。
VMware 分为收费专业版 Workstation Pro 和非商用免费版 Workstation Player,推荐使用 Workstation Player。
首先从 VMware 官网(www.vmware.com)下载 Workstation Player 安装 包,或者使用我们提供的安装包。
在 <开发板配套资料>2_DongshanPI-Vision_配套工具\ 【Windows】VMwareWorkstation 安装包中, VMWare 安装软件是:VMware-workstation-full-16.2.3-19376536.exe。下 面给出 VMWare 的安装步骤。
第 1 步:以管理员身份运行安装软件

第2步:点击“下一步”

第3步:勾选“我接受”点击“下一步”

第4步:指定安装目录后点击“下一步”

第5步:设置用户体验后点击“下一步”

第6步:设置快捷方式后点击“下一步”

第7步:点击“安装”开始安装

第8步:等待安装完成

第9步:完成安装

VMWare安装完成后,有两个软件,它们都可以使用,建议使用第2个:
① Vmware Workstation Pro:这是收费的,可以试用30天。
② Vmware Workstation 16 Player:这是免费的。
**注意:**本文是在Windows 10上安装VMware。
1.2 使用VMware打开Ubuntu
1.2.1 下载、解压Ubuntu映像文件
在百度网盘的“2_DongshanPI-Vision_配套工具”中,有Ubuntu映像文件,如图 1.1所示:

在某个磁盘分区里解压文件,这个分区最好有200G的空闲空间。解压后,可以得到如图 1.2所示文件:

1.2.1 在BIOS上启动虚拟化(virtualization)
大部分电脑的BIOS已经启动了虚拟化,可以打开设备管理器确认这点,如图 1.3和图 1.4所示:


如果上图中虚拟化没有显示为“已启动”,需要重启电脑进入BIOS启动虚拟化。各个电脑的BIOS设置界面可能不一样,下面的步骤只是示例:
第1步:进入BIOS
开机或重启电脑过程中,在自检画面处反复按F2键(注:部分机型使用Fn+F2)进入BIOS Setup设置界面。
第2步:找到虚拟化菜单
用键盘的右方向键选中 “Configuration”菜单,然后使用下方向键选中“Intel Virtual Technology”选项并回车,如图 1.5所示:

第3步:使能虚拟化
在弹出的菜单中,选择“Enable”并回车,如图 1.6所示:

第4步:保存
最后按键盘的F10热键(注:部分机型需要配合Fn+F10)调出保存对话框,选择“Yes”保存退出并自动重启电脑,如图 1.7所示:

1.1.1 使用VMware运行Ubuntu
第1步:以管理员身份打开Vmware Workstation 16 player,如图 1.8所示:

第2步:打开虚拟机。
使用vmware打开前面解压得到的“Ubuntu_20.04.4_VM_LinuxVMImages.COM.vmx”,如图 1.9所示:


第3步:播放虚拟机,如图 1.10所示:


第4步:第一次启动Ubuntu时,选择默认的“我已复制该虚拟机”,启动后输入密码“ubuntu”回车即可登录,如图 1.11所示:


注意:虚拟机默认没有开启小键盘,如果使用小键盘输入,请先开启小键盘。如图 1.12所示:

2.第1章 Ubuntu操作入门
1.1 Ubuntu下打开终端
我们安装的Ubuntu是桌面版本,这样我们可以像在windows系统下操作一样,相对于平时所说的Linux命令行下操作来说,这种体验非常舒适。但是一般我们使用Linux都是在命令行下进行操作,所有的操作我们的都可以通过输入命令来完成,绝大多数情况下使用命令行来操作Linux系统比通过在GUI下操作的效率高很多,虽然说我们使用的Ubuntu是包含了GUI的Linux发行版,然而我们可以像在windows下那样唤出Ubuntu的终端,打开Ubuntu的终端非常简单,以我们使用的Ubuntu20.04为例,有种方法可以直接在Ubuntu的用户界面下
1.1.1 用搜索框打开终端
我们要输入各种命令,需要先打开终端。
点击Ubuntu桌面左上角图标进入搜索框,输入“term”可以弹出终端“Terminal”程序,运行它,如图 2.1所示:

然后就可以在里面执行各种命令了。
1.1.1 使用右键打开终端
在桌面或者在文件浏览器的任何目录下右键鼠标后在弹出的菜单栏中选择**“Open in Terminal”**,如图 2.2所示:


1.1.1 快捷键打开终端
这是个比较快捷方便的方法:使用快捷方式打开终端,快捷方式为”Ctrl+Alt+T”,使用快捷方式可在绝大多情况下直接唤出Ubuntu的终端(无论你是在浏览器、文件管理器、查看邮件、甚至在一个已经打开的终端下工作,等等都可以直接唤出Ubuntu的终端)。
第三篇 环境搭建及开发板操作
1.配置VMware使用桥接网卡
1.1 vmware设置
使用桥接模式下,虚拟主机与真实主要在VMnet0构成的局域网内通信,同时通过真实主机中的网关与外网通信,即可实现Ubuntu与开发板进行文件传输。
设置网络适配器为桥接模式。

点击网络适配器 NAT,将网络连接方式选择为桥接模式。

1.2 虚拟网络编辑器设置
在开始菜单搜索“虚拟网络编辑器”,点击“以管理员身份运行”打开虚拟网络编辑器:

参考图 1.4,点击“VMnet0”,选择“桥接模式”,在桥接模式下的“已桥接至”下拉框中,选中你电脑中实际使用WIFI网卡,最后点击确定即可完成vmware配置。
注意:必须是“VMnet0”,如果没有“VMnet0”可以点击“添加网络”。

2.安装软件
2.2 安装 Windows 软件
“<开发板配套资料>\2_DongshanPI-Vision_配套工具\”
在网盘资料包的上述目录中,可以得到一系列的安装软件,建议全部安装。有如下软件:
| 软件名 | 说明 |
|---|---|
| VMwareWorkstation | 虚拟机软件,安装时需要用到管理员权限 |
| SD Card Formatter | SD卡格式化工具 |
| MobaXterm | 串口工具、远程登录工具 |
| Filezilla | 文件传输工具,在Windows和Ubuntu之间传输文件 |
| Source insight | 阅读、编写源码的工具,即装即用;推荐初学者使用 |
2.3 使用MobaXterm远程登录Ubuntu
先确认Ubuntu的IP,在Ubuntu终端执行ifconfig命令确定桥接网卡IP(注意:这个IP过一段时间会发生变化,那就使用新IP重新连接),如图 2.3所示:

安装、运行MobaXterm,如下建立Session:

按图 2.4操作后,在MobaXterm左侧就可以看到图 2.5这项,双击它就可以登录Ubuntu(第1次登录时会提示你输入密码,密码是ubuntu),然后就可以执行各种Linux命令了:

2.4 使用FileZilla在Windows和Ubuntu之间传文件
使用MobaXterm既可以ssh登录又可以传输文件,不过Mobaxterm在传输文件时使用效率上没有 FileZilla高,所以我们推荐Windows和Ubuntu互相传输文件时使用FileZilla。
双击打开FileZilla后,按图 2.6操作:

第1次连接时,会有如图 2.7所示的提示,选择“总是信任”:

在Filezilla中,左边是Windows文件,右边是Ubuntu的文件,如图 2.8:

2.5编程示例:Ubuntu上的Hello程序
本节演示如何在Windows编写程序、上传到Ubuntu,在Ubuntu中编译、执行。只涉及一个简单的Hello程序,使用命令行编译,不涉及Makefile等知识,这些知识在后面的应用基础中讲解。
2.5.1 用Source Insight编写hello.c
启动Source Insight,点击“File”->“New”,新建文件,如图 2.9:

接下来编写代码,保存文件,如图 2.10所示:

图 2.10 SI编写代码并保存
hello.c的源码如下:
#include <stdio.h>
int main(int argc, char **argv)
{
printf("hello, world!\n");
return 0;
}
2.5.2 用FileZilla上传源码
如图 2.11操作:

1.1.1 编译、运行程序
如图 2.12操作,对于gcc命令的用法在后面讲到应用开发基础时再细讲,这里只是体验一下:

3.DongshanPI-Vision开发板基本操作
3.1 DongshanPI-Vision开发板硬件资源简介
DongshanPI-Vision开发板是围绕着嘉楠 勘智K510芯片构建的,采用64位双核RISC-V架构 ,主频为:800MHz,支持双精度FPU扩展。采用64位DSP扩展,主频为:800MHz。芯片内置通用神经网络引擎KPU,拥有2.5TFLOPS BF16/2.5TOPS INT8算力,支持TensorFlow、PyTorch、ONNX等多种框架的算子库。
| 特征 | 描述 |
|---|---|
| 处理器 | 嘉楠 勘智K510 |
| 内存 | 512MB LPDDR3 |
| 存储 | 4GB EMMC |
| WIFI/蓝牙 | 天线:2.4GHz |
| 视频输出 | MIPI显示(MIPI DSI)/HDMI显示(HDMI)/SPI显示(SPI DSI) |
| 视频输入 | 两路MIPI摄像头(MIPI CSI *2)/DVP摄像头(DVP Canera) |
| 音频输入 | MIC咪头 |
| 音频输出 | 扬声器/耳机 |
| 其他连接器 | ·TF卡槽 ·2个USB连接器 · JTAG调试口 ·电池接口 |
开发板组成位置
本章节介绍开发板中关键的元器件及位置功能介绍如下所示,各个标号对应的硬件在板子上都写有名字。
开发板正面图:


开发板背面图:

3.2 DongshanPI-Vision开发板软件资源介绍
3.2.1 开发开发环境

3.2.2 核心软件

3.2.3 文件系统

3.3 启动方式选择
板子上的拨码开关用来设置启动方式,支持这3种方式:EMMC启动、SD卡启动、串口烧写。启动方式如表3-1所示:
| BOOT MODEL | SW1(BOOT0) | SW2(BOOT1) |
|---|---|---|
| EMMC | OFF | OFF |
| SD | OFF | ON |
| 串口烧录 | ON | ON |
这3种启动方式的设置示意图 3.7如下:

注意:设置为串口烧录时,不能插上SD卡、TF卡;上电之后才可以插卡。刚出厂的板子在EMMC上烧写了系统,你可以设置为EMMC启动方式。
3.4 开发板硬件连接
3.4.1 天线连接
要使用WIFI,您需要连接DongshanPI-Vision盒子中提供的2.4GHz天线,下面是将天线连接到DongshanPI-Vision开发板的指南。

3.4.2 连接摄像头
要使用摄像头获取图像数据,如果您只单独购买了DongshanPI-Vision开发板,可能还需另外购买MIPI摄像头。下面图片是将MIPI摄像头连接到DongshanPI-Vision开发板的指南。

3.4.3 连接显示屏
要使用显示屏显示摄像头获取的图像,如果您只单独购买了DongshanPI-Vision开发板,可能还需另外购买MIPI显示屏,或者也可直接使用HDMI线连接电脑显示器。下面是将MIPI显示屏连接到DongshanPI-Vision开发板的指南。

3.4.4串口及OTG连接
通过Type-C线将板连接到PC电脑,您可以使用DongshanPI-Vision盒子中的的两条Type-C线。连接指南如下所示:

注意:请直接将两条数据线连接到电脑端,请勿使用USB HUB连接两条Type-C数据线。如果您的电脑没有多余的USB口,可使用5V1A的电源适配器,连接到OTG口进行供电。
一旦开发板套件通电后,核心板上会亮起红灯,红灯位置如下图中蓝色箭头所示:

3.5 查看串口端口号
在接好串口处的Type-C数据线连接电脑和开发板后,打开电脑的设备管理器,并展开端口(COM和LPT)列表。可以看到下图中,连接后的端口号为COM37。开发板上的USB串口芯片可能是CP210x或CH9102,它们的性能是一样的。你电脑上显示的COM序号可能不一样,记住你电脑显示的数字。

如果电脑没有显示出端口号,就需要手动安装驱动,已经将驱动安装包放入网盘资料中了:

图 3.10 USB串口驱动
如果电脑中没有自动安装驱动,在“设备管理器”会有黄色感叹号提示当前连接的是哪种类型的串口芯片,根据提示选择驱动安装。如果提示中有“CP210x”字样则选择“CP210x_Windows_Drivers.zip”,否则就选择另外一个驱动安装。
3.6 使用MobaXterm软件打开串口
打开MobaXterm,点击左上角的“Session”,在弹出的界面选中“Serial”,如下图所示选择端口号(前面设备管理器显示的端口号COM17或COM19)、波特率(Speed 115200)、流控(Flow Control: none),最后点击“OK”即可。步骤如图 3.11所示。
注意:流控(Flow Control)一定要选择none,否则你将无法在MobaXterm中向串口输入数据。

随后显示一个黑色的窗口, 此时打开板子的电源开关,将收到板子串口发过来的数据,如图 3.12所示。

4.进入串口调试控制台后,如果开发板正在启动uboot或者kernel则会不断打印输出信息直到系统完全启动,如果开发板已经完全启动则不会打印信息,可直接按下回车键,进入开发板系统控制台。

3.7 通过串口操作开发板
在串口看到root@canaan这类登录的提示信息时,输入回车即可,然后就可以执行各种Linux命令了,如图 3.14所示:

3.8 开机自启应用程序
当系统启动后,如果您正常连接两个摄像头和显示屏,系统会在uboot系统启动阶段显示canaan官方logo,效果图如下所示:

当系统完全启动后会自动运行实时预览程序,使用V4L2抓取摄像头图像并实时显示在显示屏上。效果图如下所示:

如果您想结束掉该进程或者想运行其他需要使用摄像头和显示屏的程序,您可以通过在串口终端控制台输入ps查看所以进程,并找到进程名.为v4l2_drm.out所对对应的进程号,如下所示:
188 root 0:00 ./v4l2_drm.out -f video_drm_1920x1080.conf -e 1 -s
可以看到最前面的为进程号,可能您的进程号和我不一致,这里我的进程号为188,此时我应该输入:
kill -9 188
如果您的进程号不是188,需要将188修改为您实际的进程号才能正常结束该应用程序。
3.9 更新系统
3.9.1 更新EMMC系统
硬件要求:
- DongshanPI-Vision开发板
- Type-c数据线 x2
软件要求:
- DongshanPI-Vision开发板EMMC镜像:https://dongshanpi.cowtransfer.com/s/5482c150ff6147
- KendryteBurningTool 烧录工具:https://dongshanpi.cowtransfer.com/s/b3709a719d2342
开始前请下载DongshanPI-Vision开发板EMMC镜像 ,并记住它在计算机中保存的位置。
3.9.1.1 硬件操作
将下图中的拨码开关的boot0和boot1都向上拨,使开发板进入下载模式。使用两条Type-C线连接开发板端和电脑端,用于给开发板进行供电和使用串口进行烧录EMMC系统。

3.9.1.2 安装串口驱动
- 串口驱动安装程序:
2_DongshanPI-Vision_配套工具/【Windows】串口驱动工具
安装前说明:每台计算机安装一次即可。
打开串口驱动安装软件CH341SER.EXE,打开后会进入如下界面:

点击安装

等待安装完成即可。

3.9.1.3 烧录镜像
下载EMMC镜像并记住它在计算机中的位置。打开KendryteBurningTool 烧录工具,进入KendryteBurningTool\bin目录下,双击打开BurningTool.exe,如下所示的文件。
注意:在使用KendryteBurningTool 烧录工具时需要关闭串口软件和虚拟机,防止串口被占用。

打开BurningTool.exe程序后会进入如下界面:

点击选择文件,选择下载好的EMMC镜像。选择完成后点击保存,操作步骤如下所示:

保存后需要在串口选择中选择开发板的串口号,当我们将开发板和PC电脑端通过Type-C连接起来后,可以在BurningTool软件中点击红色箭头处查看我开发板的端口号,选择开发板的串口端口号。(我们也可以在设备管理器中确认开发的端口号)

选择完成后,点击开始烧录烧录。如果您不是第一次进行烧录,此时等待成功烧录完成即可。如果您是第一次进行烧录请继续阅读下面的内容。第一次烧录步骤如下所示:

当PC电脑首次进行烧录时,第一个进度条结束后,会显示下图中的错误信息。此时需要安装驱动。

3.9.1.4 安装烧录驱动
- zadig-2.4烧录驱动安装文件:``
安装前说明:每台计算机安装一次即可。
打开zadig-2.4软件,进入如下界面

点击Option中的选择List All Devices(列出所有设备),具体操作如下所示:

上述操作完成后,可以看到在虚线框内出现了设备名,我们需要切换设备为 Mass storage devices,具体操作如下所示:

点击Replace Driver替换驱动程序,此时会弹出一个确认窗口,点击是。

安装完成后会弹出以下窗口点击close

到此烧录驱动成功安装。
3.9.1.5 完整烧录镜像
安装完成烧录镜像后,再次打开BurningTool.exe烧录工具软件,按照1.3章节中的操作进行烧录即可。完整烧录步骤如下所示:

3.9.1.6 启动EMMC系统
将下图中的拨码开关的boot0和boot1都向下拨,使开发板进入EMMC启动模式。使用两条Type-C线连接开发板端和电脑端,用于给开发板进行供电和使用串口登录开发板控制台。

使用串口软件查看串口控制台,成功启动后会进入开发板控制台。

3.9.2 制作SD卡镜像
硬件要求:
- DongshanPI-Vision开发板
- microSD卡(建议最小8G)
- Type-c数据线 x2
软件要求:
- DongshanPI-Vision开发板SD卡镜像:https://dongshanpi.cowtransfer.com/s/bac8fbdce7c046
- SD卡格式化工具:SD Memory Card Formatter
- SD卡刷机工具:ETCHER
开始前请下载DongshanPI-Vision开发板SD卡镜像,并记住它在计算机中保存的位置。
3.9.2.1 格式化microSD卡
将您的SD卡使用读卡器通过USB口插入您的PC电脑,使用SD卡格式化工具SD Memory Card Formatter格式化您的SD卡。点击下图中红框位置,开始格式化内存卡。

点击完成后会弹出下图所示的提示框,该提示警告我们格式化将清空卡中的所有数据,询问我们是否继续,这里点击是

等待格式化完成后,会弹出以下对话框,提示我们格式化后的文件系统为FAT32以及内存大小可用空间,点击确定即可完成SD卡的格式化。

3.9.2.2 使用Etcher烧录镜像
使用Etcher将DongshanPI-Vision开发板SD卡镜像写入您的microSD卡。
下载Etcher烧写工具并安装它。启动Etcher应用程序,启动后界面如下图所示:

点击Flash from file,如下图所示,点击下图红框处。

此时会弹出文件资源管理器,选择您刚刚下载的DongshanPI-Vision开发板SD卡镜像。

选择完成后会,显示下面的界面,点击下图中红框处Select target,选择要写入的目标microSD卡。

点击完成后会弹出选择目标,此时选择您通过读卡器插入电脑中的microSD卡。

选择完成后,会显示以下界面,点击Flash后即可开始烧写。

如下图所示等待烧写完成即可。

使用Etcher烧写完成后,Windows可能会不知道如何读取您的microSD卡,会弹出如下图所示警告,点击取消后拔出microSD卡即可。

3.9.2.3 启动SD卡系统
将下图中的拨码开关的boot0向下拨和boot1向上拨,使开发板进入SD卡启动模式。将SD卡插入开发板的卡槽中,步骤如下图所示:

使用两条Type-C线连接开发板端和电脑端,用于给开发板进行供电和使用串口登录开发板控制台。

使用串口软件查看串口控制台,成功启动后会进入开发板控制台。

3.10 使用wifi连接网络
3.10.1 结束开启联网脚本
安装启动开发板完成后,打开串口终端进入开发板控制台。由于开发板启动后会启动联网脚本,我们第一次配网时需要手动结束联网脚本。输入ps,查看进程,找到下面所示的两个进程。
159 root 0:00 wpa_supplicant -D nl80211 -i wlan0 -c /etc/wpa_supplicant.
178 root 0:00 udhcpc -R -n -p /var/run/udhcpc.eth0.pid -i eth0 -b

通过上述信息可以发现,我们需要手动结束159和178这两个进程,您的进程号可能和我不一致,按您开发板上世纪的进程操作。输入:
kill -9 <PID>
假设我使用的开发板中wpa_supplicant和udhcpc进程号分别为159和178,此时我应该输入以下命令
kill -9 159
kill -9 178

手动结束后使用ps查看是否还存在对应进程。
3.10.2 填写WIFI信息
修改/etc/wpa_supplicant.conf文件,填写wifi名称和密码,输入
vi /etc/wpa_supplicant.conf
进入vi编辑器后会显示以下信息
ctrl_interface=/var/run/wpa_supplicant
update_config=1
ap_scan=1
在文件末尾增加网络信息
network={
ssid="<wifi名称>"
psk="<密码>"
}
假设我的WiFi名称为Programmers,密码为123456,则实际添加的网络信息为:
network={
ssid="Programmers"
psk="12345678"
}
添加完成后保存并退出vi编辑器。
3.10.3 连接WiFi
连接到 SSID,输入:
wpa_supplicant -B -iwlan0 -c /etc/wpa_supplicant.conf
执行完成后,如下所示

获取ip地址,输入:
udhcpc -i wlan0
获取完成后即为成功连接互联网。
测试WiFi是否可以访问互联网,输入ping www.baidu.com,输入后如下所示:
[root@canaan ~ ]$ ping www.baidu.com
PING www.baidu.com (14.119.104.189): 56 data bytes
64 bytes from 14.119.104.189: seq=0 ttl=55 time=10.241 ms
64 bytes from 14.119.104.189: seq=1 ttl=55 time=16.292 ms
64 bytes from 14.119.104.189: seq=2 ttl=55 time=15.699 ms
64 bytes from 14.119.104.189: seq=3 ttl=55 time=12.508 ms
在后续启动开发板中,开发板会自动连接到SSID,您只需要重新获取ip地址即可访问互联网。
3.11 使用TFTP服务在Ubuntu和开发板传输文件
3.11.1 Ubuntu安装TFTP服务
在Ubuntu中执行以下命令安装TFTP服务:
sudo apt-get install tftp-hpa tftpd-hpa
然后,创建TFTP服务工作目录,并打开TFTP服务配置文件,如下:
mkdir -p /home/ubuntu/tftpboot
chmod 777 /home/ubuntu/tftpboot
sudo gedit /etc/default/tftpd-hpa
在配置文件/etc/default/tftpd-hpa中,将原来的内容删除,修改为:
TFTP_USERNAME="tftp"
TFTP_ADDRESS=":69"
TFTP_DIRECTORY="/home/ubuntu/tftpboot"
TFTP_OPTIONS="-l -c -s"
最后,重启TFTP服务:
sudo service tftpd-hpa restart
查看tftp服务是否在运行,运行如下命令,即可查看是否在后台运行。
ubuntu@ubuntu2004:~/Desktop$ ps -aux | grep “tftp”
ubuntu 4555 0.0 0.0 9040 652 pts/0 S+ 02:33 0:00 grep --color=auto “tftp”
3.11.2 开发板通过tftp传输文件
首先确保Ubuntu或Windows的tftp服务目录内,有需要下载到板子上的文件,比如:
ubuntu@ubuntu2004:~$ ls /home/ubuntu/tftpboot/
object_detect
确认Ubuntu的网络IP,例如

比如下载Ubuntu服务器下的zImage 文件,则在开发板上执行如下命令(Ubuntu的桥接网卡IP是192.168.0.197):
[root@canaan ~ ]$ tftp -g -r object_detect 192.168.0.197
下载过程如下所示:
[root@canaan ~ ]$ tftp -r object_detect -g 192.168.0.197
object_detect 100% |********************************| 894k 0:00:00 ETA
下载完成后,可以在当前目录找到该文件
[root@canaan ~ ]$ ls
data emmc object_detect
如何从开发板上传文件到Ubuntu?比如我们现在开发板家目录下创建一个1.txt 的文本文件,然后写入111111…. :
[root@100ask:~]$ tftp -p -l 1.txt 192.168.5.197
1.txt 100% |********************************| 8 0:00:00 ETA
此时我们查看Ubuntu服务器的tftp服务目录下,即可看到之前在开发板上创建的1.txt:
ubuntu@ubuntu2004:~$ ls /home/ubuntu/tftpboot/
1.txt object_detect
3.12 配置开发板SSH功能
3.12.1 修改ssh配置文件
使用Mobaxterm终端工具访问开发板的串口控制台,等待系统启动后,进入/etc/ssh目录下
[root@canaan ~ ]$ cd /etc/ssh/
[root@canaan /etc/ssh ]$ ls
moduli ssh_config sshd_config
进入ssh目录可以看到有三个文件,您需要修改sshd_config,使用vi命令进行修改
[root@canaan /etc/ssh ]$ vi sshd_config
输入后,进入vi编辑器,修改下图中红框处的两项。
配置SSH登录设置

将红框处两项取消注释,并将参数设置为yes
PermitRootLogin yes
PermitEmptyPasswords yes
修改完成后如下所示:

配置SFTP服务
修改sshd_config中的sftp配置项
修改前:
Subsystem sftp /usr/libexec/sftp-server
修改后:
Subsystem sftp internal-sftp
修改完成后,按下esc,输入:wq,保存并退出编辑器。
3.12.2 启动ssh
当您修改完成配置文件后后,需要手动重启ssh,在终端输入/etc/init.d/S50sshd restart。
[root@canaan ~ ]$ /etc/init.d/S50sshd restart
Stopping sshd: killall: sshd: no process killed
OK
Starting sshd: OK
输入完成后,ssh会重新启动。
3.12.3 连接ssh
开始前请注意:
- 您的PC电脑需要和开发板连接同一个WIFI。
在开发板串口终端输入udhcpc -i wlan0,获取您的开发板连接WIFI的IP地址
[root@canaan ~ ]$ udhcpc -i wlan0
udhcpc: started, v1.31.1
udhcpc: sending discover
udhcpc: sending select for 192.168.0.154
udhcpc: lease of 192.168.0.154 obtained, lease time 122
deleting routers
adding dns 192.168.0.1
adding dns 192.168.0.1
获取完成后,输入ifconfig wlan0 ,查看开发板所连接WIFI的IP地址
[root@canaan ~ ]$ ifconfig wlan0
wlan0 Link encap:Ethernet HWaddr 8C:F7:10:47:9B:6E
inet addr:192.168.0.154 Bcast:192.168.0.255 Mask:255.255.255.0
inet6 addr: fe80::8ef7:10ff:fe47:9b6e/64 Scope:Link
UP BROADCAST RUNNING MULTICAST MTU:1500 Metric:1
RX packets:438 errors:0 dropped:2 overruns:0 frame:0
TX packets:21 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:1000
RX bytes:34571 (33.7 KiB) TX bytes:2446 (2.3 KiB)
可以看到wlan0选项中的IP地址为:192.168.0.154
3.12.4 使用MobaXterm传输文件
使用MobaXterm终端工具,点击会话Session,如下图中红框所示

点击完成后会弹出以下界面,点击使用SSH,如下图红框所示:

进入ssh配置界面后,远程主机Remote host的框输入开发板的IP地址,勾选指定用户名Specify username前的框,在后面填写开发板的用户名root,填写完成后,点击OK即可。如下图所示

点击完成后就会打开一个新的终端,如下图所示:

您可以看到这里也可以访问开发的串口终端。您可以看到左边选项卡中的开发板对应的文件系统,例如data/emmc,您在选项卡中可以对文件夹中内容进行下载或者上传。如下图所示,这里我进入/root/emmc/p3/app/ai/exe/目录中,选择face_detect文件,单击右键后弹出选项栏,选择Download即可开始下载该文件。

如果您想上传文件到当前目录,在左侧选项卡的空白处,点击右键,选择Upload to current folder上传到当前文件夹即可。

4.系统功能及AI应用初体验
4.1 系统功能体验指南
4.1.1 ai demo程序
说明
nncase 的demo程序源码位于SDK目录下的package/ai目录,目录结构如下:
$ tree -L 2 ai
ai
├── ai.hash
├── ai.mk
├── code
│ ├── build.sh
│ ├── cmake
│ ├── CMakeLists.txt
│ ├── common
│ ├── face_alignment
│ ├── face_detect
│ ├── face_expression
│ ├── face_landmarks
│ ├── face_recog
│ ├── hand_image_classify
│ ├── head_pose_estimation
│ ├── imx219_0.conf
│ ├── imx219_1.conf
│ ├── license_plate_recog
│ ├── object_detect
│ ├── object_detect_demo
│ ├── openpose
│ ├── person_detect
│ ├── retinaface_mb_320
│ ├── self_learning
│ ├── shell
│ ├── simple_pose
│ ├── video_192x320.conf
│ ├── video_object_detect_320.conf
│ ├── video_object_detect_320x320.conf
│ ├── video_object_detect_432x368.conf
│ ├── video_object_detect_512.conf
│ ├── video_object_detect_640.conf
│ └── video_object_detect_640x480.conf
└── Config.in
可以参考retinaface_mb_320的源码和CMakeLists.txt添加新的nncase 的demo程序。
模型的编译参见nncase_demo.mk里面定义的POST_INSTALL_TARGET_HOOKS:
NNCASE_DEMO_DEPENDENCIES += mediactl_lib nncase_linux_runtime opencv4 libdrm
define NNCASE_DEMO_COMPILE_MODEL
mkdir -p $(TARGET_DIR)/app/ai/kmodel/kmodel_compile/retinaface_mb_320
cd $(@D) && /usr/bin/python3 retinaface_mb_320/rf_onnx.py --quant_type uint8 --model ai_kmodel_data/model_file/retinaface/retinaface_mobile0.25_320.onnx
cp $(@D)/rf.kmodel $(TARGET_DIR)/app/ai/kmodel/kmodel_compile/retinaface_mb_320/rf_uint8.kmodel
cd $(@D) && /usr/bin/python3 retinaface_mb_320/rf_onnx.py --quant_type bf16 --model ai_kmodel_data/model_file/retinaface/retinaface_mobile0.25_320.onnx
cp $(@D)/rf.kmodel $(TARGET_DIR)/app/ai/kmodel/kmodel_compile/retinaface_mb_320/rf_bf16.kmodel
NNCASE_DEMO_POST_INSTALL_TARGET_HOOKS += NNCASE_DEMO_COMPILE_MODEL
模型的编译需要nncase环境,关于nncase环境的搭建,参考k510_nncase_Developer_Guides.md。以后nncase有更新,buildroot sdk会同步更新到nncase。
retinaface
功能:人脸检测,人脸特征点检测
程序路径: /app/ai/shell 运行: 执行非量化模型,./retinaface_mb_320_bf16.sh 执行uint8量化模型,./retinaface_mb_320_uint8.sh
脚本里面有关于QOS的设置,下面的两个demo的设置一样。
#devmem phyaddr width value
devmem 0x970E00fc 32 0x0fffff00
devmem 0x970E0100 32 0x000000ff
devmem 0x970E00f4 32 0x00550000
跑demo时,需要优先保证屏幕显示正常,即调整显示相关的QoS为高优先级。 QOS_CTRL0.ax25mp write QoS = 5 QOS_CTRL0.ax25mp read QoS = 5 QOS_CTRL2.ispf2k write QoS = 0xf QOS_CTRL2.ispf2k read QoS = 0xf QOS_CTRL2.ispr2k write QoS = 0xf QOS_CTRL2.ispr2k read QoS = 0xf QOS_CTRL2.isp3dtof write QoS = 0xf QOS_CTRL3.display read QoS = 0xf QOS_CTRL3.display write QoS = 0xf
QOS 控制寄存器0(QOS_CTRL0) offset[0x00f4] 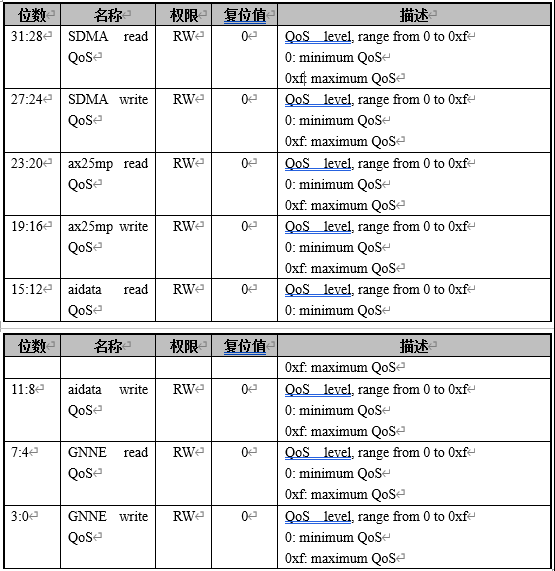
QOS 控制寄存器1(QOS_CTRL1) offset[0x00f8] 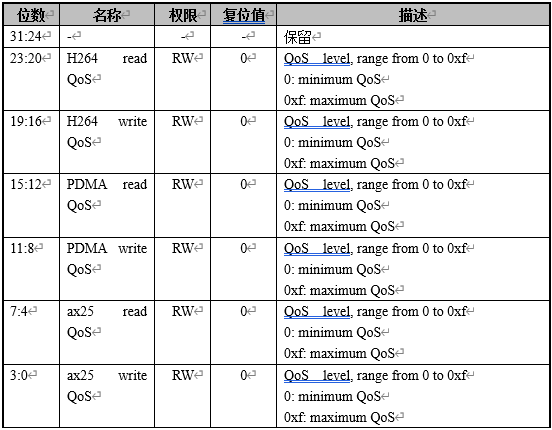
QOS 控制寄存器2(QOS_CTRL2) offset[0x00fc] 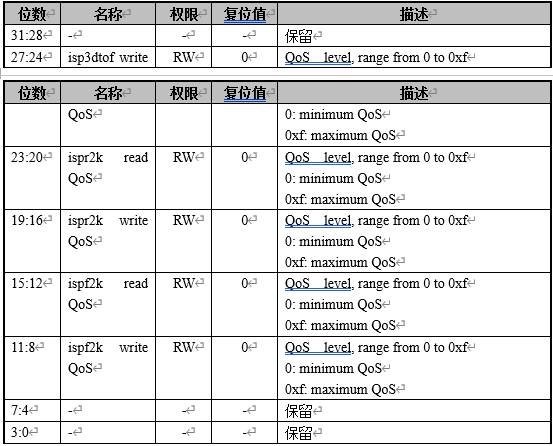
QOS 控制寄存器3(QOS_CTRL3) offset[0x0100] 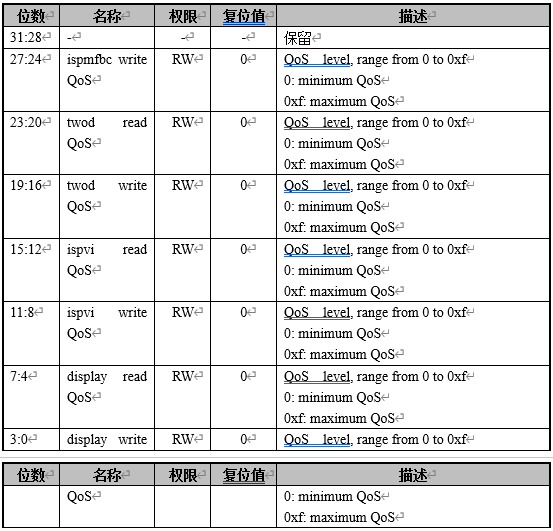
模型的编译安装详见文件package/ai/ai.mk:
编译脚本路径: 100ask_base-aiApplication-demo/code/retinaface_mb_320/rf_onnx.py
object_detect
功能:物体分类检测,80分类
程序路径: /app/ai/shell
运行: 执行非量化模型,./object_detect_demo_bf16.sh 执行uint8量化模型,./object_detect_demo_uint8.sh
模型的编译安装详见文件package/ai/ai.mk
编译脚本路径: 100ask_base-aiApplication-demo/code/object_detect_demo/od_onnx.py
4.1.2 ffmpeg
ffmpeg在ffmpeg-4.4开源代码上进行移植,0001-buildroot-ffmpeg-0.1.patch为补丁包,增加了
ff_k510_video_demuxer:控制isp输入,引用了libvideo.soff_libk510_h264_encoder:控制h264硬件编码,引用了libvenc.so
可以通过help指令查看可配置参数
ffmpeg -h encoder=libk510_h264 #查看k510编码器的参数
ffmpeg -h demuxer=libk510_video #查看demuxer的配置参数
详细运行说明参考K510_Multimedia_Developer_Guides.md
4.1.3 alsa_demo
alsa demo程序放在/app/alsa_demo目录下:
运行准备:
- 插上耳机
使用ALSA UTILS测试。
4.1.4 TWOD demo
运行 rotation 使用方法:
cd /app/twod_app
./twod-rotation-app
将ouput.yuv 拷到yuv显示器上设置尺寸1080 x 1920,显示格式nv12,结果如下

scaler 使用方法
cd /app/twod_app
./twod-scaler-app
将ouput.yuv 拷到yuv显示器上设置尺寸640x480,显示格式nv12,结果如下

运行 rgb2yuv 使用方法:
cd /app/twod_app
./twod-osd2yuv-app
将ouput.yuv 拷到yuv 显示器上设置尺寸320x240,显示格式nv12,结果如下

运行 yuv2rgb 使用方法:
cd /app/twod_app
./twod-scaler-output-rgb888-app
将ouput.yuv 拷到rgb888显示器上设置尺寸640x480,显示格式rgb24,结果如下

运行 输出yuv上叠加osd 使用方法:
cd /app/twod_app
./twod-scaler-overlay-osd-app
将ouput.yuv 拷到显示器上设置尺寸640x480,显示格式nv12,结果如下

API:
/* 创建内存 */
twod_create_fb()
/* 配置原图片参数 */
twod_set_src_picture()
/* 配置输出图片参数 */
twod_set_des_picture()
/* 设置 scaler */
twod_set_scaler()
/* 等待操作完成 */
twod_wait_vsync()
/* Invali cache */
twod_InvalidateCache()
/* flash cache */
twod_flashdateCache()
/* 释放内存*/
twod_free_mem()
/* 设置旋转 */
twod_set_rot()
4.1.5 RTC demo
RTC驱动会注册生成/dev/rtc0设备节点。
应用层遵循Linux系统中的标准RTC编程方法调用驱动,在运行参考例程之前,建议通过shell 控制台关闭内核信息打印。
echo 0 > /proc/sys/kernel/printk
进入/app/rtc目录,输入如下命令启动rtc应用程序。
cd /app/rtc
./rtc 2021-11-3 21:10:59
程序的执行结果为:

RTC demo程序的主要代码片段如下,详细请参考package/rtc 文件夹下的代码。
/*解析参数,获取当前年月日、时分秒*/
if(argc !=3) {
fprintf(stdout, "useage:\t ./rtc year-month-day hour:minute:second\n");
fprintf(stdout, "example: ./rtc 2021-10-11 19:54:30\n");
return -1;
}
sscanf(argv[1], "%d-%d-%d", &year, &month, &day);
sscanf(argv[2], "%d:%d:%d", &hour, &minute, &second);
/*打开RTC设备,设备节点是:/dev/rtc0 */
fd = open("/dev/rtc0", O_RDONLY);
if (fd == -1) {
perror("/dev/rtc0");
exit(errno);
}
/* 设置RTC时间。*/
retval = ioctl(fd, RTC_SET_TIME, &rtc_tm);
if (retval == -1) {
perror("ioctl");
exit(errno);
}
/* 休眠 2秒。 */
sleep(2);
/* 读取RTC当前时间。*/
retval = ioctl(fd, RTC_RD_TIME, &rtc_tm);
if (retval == -1) {
perror("ioctl");
exit(errno);
}
/* 打印 RTC当前时间。*/
fprintf(stdout, "\nRTC date/time: %d/%d/%d %02d:%02d:%02d\n",
rtc_tm.tm_mday, rtc_tm.tm_mon + 1, rtc_tm.tm_year + 1900,
rtc_tm.tm_hour, rtc_tm.tm_min, rtc_tm.tm_sec);
4.1.6 WDT demo
K510一共有三个看门狗,WDT驱动会注册生成/dev/watchdog0、/dev/watchdog1、/dev/watchdog2 设备节点。
应用层遵循 Linux系统中的标准WDT编程方法调用驱动,wathdog应用程序第一个参数可为0、1,分别代表watchdog0、watchdog1,第二个参数表示可设置的超时时间(单位秒),例如如下命令表示启动watchdog0,watchdog0溢出时间40秒。
cd /app/watchdog
./watchdog 0 40
程序启动后将每间隔1秒喂一次看门狗,当shell终端中输入stop字符后,应用程序停止喂狗,看门狗将在设置超时时间溢出后复位设备重启,详细请参考package/watchdog文件夹下的代码。
程序的执行结果为:

注意:当前k510看门狗模块的工作时钟频率为757575Hz,以秒为单位的超时时间需要转换成看门狗实际的工作时钟频率的超时时间,计算公式是2^n/757575,因此实际的超时时间会大于等于输入的超时时间。
实际超时时间的计算过程是:
-
输入40,2^25/757575=44 > 40,2^24/757575=22 < 40,因此设置为44秒;
-
输入155,2^27/757575=177 > 155,因此设置为177秒;
-
输入2000,2^31/757575=2834 > 2000,因此设置为2834秒;
4.1.7 UART demo
K510一共有4个串口,当前驱动中串口2、3没有使能,串口0驱动会注册生成/dev/ttyS0设备节点。
应用层遵循Linux系统中的标准UART编程方法调用驱动。uart应用程序第一个参数可为0、1,分别代表uart0、uart1。
将开发板使用有线网连接到路由器,使得开发板和调试PC在一个网络中,当开发板上电后将自动获取IP,在开发板的shell串口终端中输入ifconfig命令获取IP地址,调试PC利用此IP通过telent连接开发板打开一个telent窗口。例如调试PC通过MobaXterm使用telent连接开发板的操作如下图。

telent终端窗口中输入如下命令启动串口0工作。
cd /app/uart
./uart 0
在telent窗口中输入要发送的内容,可以在shell串口终端窗口看到接收到的数据,详细请参考package/crb_demo/uart文件夹下的代码。
例如,telent窗口的输入:

对应的Shell串口终端窗口显示:

4.1.8 ETH demo
应用层遵循Linux系统中的标准ETH编程方法调用驱动。
Client
设备作为client端,进入/app/client目录,输入如下命令启动client应用程序,ETH应用程序第一个参数表示要建立TCP链接的服务器ip地址,例如输入如下命令表示启动ETH程序与10.20.5.1.13的server建立通信。
cd /app/client
./client 10.20.1.13
通过tcp协议连接server进行通信,在另一台ubuntu机器上运行server程序,详细代码请参考package/app/client文件夹下内容。
设备端显示日志:

Server
设备作为server端,进入/app/server目录,例如输入如下命令表示启动server程序。
cd /app/server
./server
在另一台ubuntu机器上运行client程序,通过tcp协议连接server进行通信,详细代码请参考package/crb_demo/server文件夹下内容。
设备端显示日志:

4.1.9 SDMMC demo
K510一共有3个SDMMC主控制器,开发板上SDMMC0用于接eMMC,SDMMC1用于WIFI模块,SDMMC2控制器用于接sdcard。
SDMMC驱动会注册生成/dev/mmcblk0,EMMC驱动会注册成/dev/mmcblk1设备节点。
SD卡在系统启动后会自动挂载到/root/data ,进入/app/write_read_file目录,SDMMC应用程序第一个参数表示要进行读写操作的文件,如SD卡挂载到/root/data,可对/root/data/目录下的文件进行读写操作,先写后读,输入如下命令启动SDMMC应用程序对SD卡进行读和写的操作并计算读写速度(单位m/s)。
cd /app/write_read_file
./write_read_file /root/data/test.txt
开启对SD卡进行1G数据的读写,代码请参考package/app/write_read_file文件夹下的内容。

4.1.10 SHA/AES demo
SHA/AES demo 使用Linux 内核导出 AF_ALG 类型的 Netlink 接口,在用户空间使用内核加密 API。详细信息请参考https://www.kernel.org/doc/html/latest/crypto/userspace-if.html。
参数:
-h 打印帮助信息
-t 算法类型:hash、skcipher
-n 算法名称:sha256、ecb(aes)、cbc(aes)
-x 解密操作
-k AES KEY(16进制字符串)
-v AES IV(16进制字符串)

sha256 test:
cd /app/crypto
echo -n "This is a test file, hello world" > plain.txt
./crypto -t hash -n "sha256" plain.txt sha256.txt
xxd -p -c 32 sha256.txt
sha256sum plain.txt

ecb(aes) 128 test:
cd /app/crypto
echo -n "This is a test file, hello world" > plain.txt
./crypto -t skcipher -n "ecb(aes)" -k 00112233445566778899aabbccddeeff plain.txt ecb_aes_en.bin
./crypto -t skcipher -n "ecb(aes)" -k 00112233445566778899aabbccddeeff -x ecb_aes_en.bin ecb_aes_de.bin
cmp ecb_aes_de.bin plain.txt
cat ecb_aes_de.bin

cbc(aes) 128 test
cd /app/crypto
echo -n "This is a test file, hello world" > plain.txt
./crypto -t skcipher -n "cbc(aes)" -k 00112233445566778899aabbccddeeff -v 00112233445566778899aabbccddeeff plain.txt cbc_aes_en.bin
./crypto -t skcipher -n "cbc(aes)" -k 00112233445566778899aabbccddeeff -v 00112233445566778899aabbccddeeff -x cbc_aes_en.bin cbc_aes_de.bin
cmp cbc_aes_de.bin plain.txt
cat cbc_aes_de.bin

aes-ecb-128和aes-cbc-128加密时要求明文要16字节对齐,不足会自动补0。
4.1.11 TRNG demo
TRNG demo通过读取/dev/hwrng字符设备产生指定长度的随机数,按16进制字符串输出。
./trng的输入参数含义:
-h 打印帮助信息
-b 指定输出随机数长度,单位byte

4.1.12 DRM demo
drm demo展示了VO硬件多图层功能。
VO共有8个layer:
-
背景层,可配置背景色。
-
layer0是video层,支持YUV422和YUV420,支持NV12和NV21格式,大小端可配,支持硬件scaling up和scaling down。
-
layer1-layer3是video层,支持YUV422和YUV420,支持NV12和NV21格式,大小端可配。
-
layer4-layer6是OSD层,支持多种ARGB格式。
开发板启动后进入/app/drm_demo目录,输入命令:
cd /app/drm_demo
./drm_demo
4.1.13 V4L2_DRM demo
v4l2_drm demo展示了摄像头输入和显示的功能。
开发板启动后进入/app/mediactl_lib目录,输入命令:
cd /app/mediactl_lib
./v4l2_drm.out -f video_drm_1080x1920.conf
或者
./v4l2_drm.out -f video_drm_1920x1080.conf
或者
./v4l2_drm.out -f imx385_video_1920x1080.conf
imx385 demo :
这个需要修改配置,具体参照 K510_V4l2_Developer_Guides.md,运行命令如下:
./v4l2_drm.out -f imx385_video_1920x1080.conf
启动v4l2_drm.out应用程序,v4l2_drm.out显示效果:

4.1.14 LVGL demo
进入/app/lvgl,运行以下命令:
cd /app/lvgl
./lvgl
显示效果如下:

4.1.15 PWM demo
PWM驱动会注册生成/sys/class/pwm/pwmchip0和/sys/class/pwm/pwmchip3设备节点。
本例程可分别对pwm0和pwm1进行配置和使能,进入/app/pwm目录,pwm应用程序第一个参数表示设置pwm的周期,单位为ns,第二个参数设置pwm一个周期中“ON”的时间,单位为ns,第三个参数可以为0、1,分别代表pwm0和pwm1,例如输入如下命令表示使能pwm0,周期为1s,占空比为1000000000/500000000*100% = 50%,详细代码请参考package/app/pwm文件夹下的内容。
cd /app/pwm
./pwm 1000000000 500000000 0
程序的执行结果为:

通过示波器连接K510 CRB5.1.2开发板J15的28号引脚,可以示波器上观察到一个周期为1秒,占空比为50%的波形图。
4.1.16 WIFI demo
WiFi模块驱动加载后会生成无线网卡wlan0,遵循标准网口驱动,正常参考TCP/IP socket编程。
-
在笔记本打开“移动热点”,然后设置热点的名称和密码
-
在笔记本上启动NetAssist,配置协议类型、本地主机IP、本地主机端口、接收设置、发送设置及需要发送的数据,如下图:

-
wifi测试程序的参数格式为:
./wifi <AP name> <password> <local ip> <server ip>
例如进入/app/wifi目录,输入启动wifi测试程序命令,程序的执行结果如下图:

4.1.17 GPIO_KEYS demo
按键驱动使用linux kernel自身集成的基于input子系统的通用gpio-keys驱动,驱动加载后在/dev/input目录下生成事件监控节点eventX,X为事件节点序号,可以通过cat /proc/bus/input/devices查看
gpio-keys例程阻塞式读取按键上报事件并打印事件信息,其信息包括按键编码和按键动作,按键编码标识按键身份,按键动作分为pressed和released,在按键release时例程会计算按键按下的持续时间
程序执行结果如下图所示:

4.2 AI应用体验指南
开发板系统中内置了丰富的AI应用示例程序,对每个示例程序我们都提供有对应的脚本文件,脚本文件中已经设置需要运行AI应用程序和对应的参数。
在开始演示AI应用指南前,需要确保您已经正确连接摄像头和显示屏并正常上电启动开发板。启动开发板后可以发现会自动运行摄像头获取图像并在显示屏上实时预览程序,需要手动结束该应用程序。使用方法如下:
-
输入
ps查看应用程序查看进程号,例如实时预览程序进程端口号为189。189 root 0:01 ./v4l2_drm.out -f video_drm_1920x1080.conf -e 1 -s -
输入
kill -9 <进程号>,结束实时预览程序进程,例如我查看的端口号为189,则应该输入kill -9 189结束实时预览程序后,显示屏会显示白屏,即代表成功结束摄像头获取图像并在显示屏上实时预览程序。
本章节介绍开发板内置的AI应用程序运行脚本都位于/app/ai/shell/目录中。进入该目录,查看是否有对应脚本文件。
[root@canaan ~ ]$ cd /app/ai/shell/
[root@canaan /app/ai/shell ]$ ls
face_alignment.sh object_detect_demo_bf16.sh
face_detect.sh object_detect_demo_uint8.sh
face_expression.sh open_pose.sh
face_landmarks.sh person_detect.sh
face_recog.sh retinaface_mb_320_bf16.sh
hand_image_classify.sh retinaface_mb_320_uint8.sh
head_pose_estimation.sh self_learning.sh
license_recog.sh simple_pose.sh
object_detect.sh
下面介绍每个脚本对应的AI应用程序的运行指南,在进行以下演示时需要确保您的串口终端控制台已进入/app/ai/shell/目录下。
4.2.1人脸对齐
人脸对齐,可得到图像或视频中的每个人脸估计出来的depth或者pncc信息。其中pncc信息为三维人脸形状上的顶点,不仅包含这一点的三维坐标信息,还包含此处的RGB取值。
论文链接:https://sci-hub.et-fine.com/10.1109/TPAMI.2017.2778152
将3D平均人脸的顶点坐标和RGB取值进行归一化操作,即NCC操作。如下图所示,下图取自论文中的截图。

Face Alignment 人脸对齐任务是基于一定量的训练集,得到一个模型,使得该模型对输入的一张任意姿态下的人脸图像能够进行特征点(landmark)标记。Face Alignment 任务一般的呈现方式是人脸特征点的检测与标记。
运行人脸对齐演示示例,在终端输入:
./face_alignment.sh
效果图如下所示:

4.2.2人脸检测
人脸检测采用了retina-face网络结构,backbone选取0.25-mobilenet。
论文链接:https://arxiv.org/pdf/1905.00641.pdf
GitHub链接:https://github.com/deepinsight/insightface
下图为单阶段逐像素密集人脸定位方法。

使用该应用时,可得到图像或视频中的每个人脸检测框以及每个人脸的左眼球/右眼球/鼻尖/左嘴角/右嘴角五个landmark。使用方法如下所示,输入:
./face_detect.sh
人脸检测器-bf16
执行非量化模型。使用方法如下所示,输入:
./retinaface_mb_320_bf16.sh
人脸检测器-uint8
执行uint8量化模型。使用方法如下所示,输入:
./retinaface_mb_320_uint8.sh
4.2.3人脸表情识别
人脸表情识别中需要用到两个模型一个模型用于检测人脸;一个模型用于进行人脸表情识别。人脸表情识别采用了人脸表情分类的方式,使用该应用可得到图像或视频中的每个人脸属于以下表情的概率。使用方法如下所示,输入:
./face_expression.sh
4.2.4人脸关键点检测
人脸关键点检测采用了PFLD(practical facial landmarks detection)。
论文链接:https://arxiv.org/pdf/1902.10859.pdf
使用该应用,可得到图像或视频中的每个人脸轮廓的106个关键点。使用方法如下所示,输入:
./face_landmarks.sh
4.2.5人脸识别
人脸识别采用了人脸特征提取后比对的方式,相同的人的特征会尽可能的像,而不同的人的特征则会有较大差距,使用该应用可得到图像或视频中的每个人脸与人脸底库中的人脸的相似度,以进行人脸识别任务。使用方法如下所示,输入:
./face_recog.sh
执行完成后会进入人脸检测模式,当摄像头检测到人脸后会,按下开发板的Key1,位置如下所示:

按下之后,可以在串口控制台中看到以下输出信息
>>>>> key code: 30, action: pressed <<<<<
total took 55.4448 ms
total took 56.2784 ms
Please Enter Your Name to Register:
>>>>> key code: 30, action: released <<<<<
上述输出信息提示您需要在串口终端输入人脸的登记名称,可直接输入录入人脸的信息,输入完成后按下回车即可。注意:目前登记信息仅支持英文输入。假设我这里输入登记名称为A,如下所示:

输入完成后会继续进入人脸检测模式,此时如果您刚刚登记的人脸再次被检测,则会在检测时标注出该人脸的登记信息。 您可重复进行登记人脸信息,登记后可以在人脸检测模式中进行人脸识别,区分登记不同信息的人脸。但当检测到没有登记的人脸信息则不会在检测时标注出人脸信息。
5.2.6人形检测
使用该应用时,可得到图像或视频中人体的检测框。使用方法如下所示,输入:
./person_detect.sh
人体关键点检测-openpose
人体关键点检测主要有两种检测方式,一个是自上而下,一种是自下而上。本应用采用了自下而上的模型openpose。使用该应用,可得到图像或视频中的每个人体的17个关键点。使用方法如下所示,输入:
./open_pose.sh
人体关键点检测-YOLOV5S
人体关键点检测主要有两种检测方式,一个是自上而下,一种是自下而上。本应用采用了自上而下的模型采用了YOLOV5S进行人体检测,然后使用simplepose进行关键点回归。使用该应用,可得到图像或视频中的每个人体的17个关键点。使用方法如下所示,输入:
./simple_pose.sh
4.2.7指尖指定区域识别
指尖指定区域识别主要包含3个流程,手掌检测+手掌关键点检测+图像识别。其中,手掌检测使用了512x512分辨率的 tiny-yolov3;手掌关键点检测使用了256x256分辨率的squeezenet1.1;图像识别使用了基于imagenet训练出来的mobilenetv2。通过手部关键点检测,利用两个食指尖,框定待识别区域。利用imagenet分类模型,确定待识别区域。使用方法如下所示,输入:
./hand_image_classify.sh
4.2.8头部态角估计
头部态角估计,可得到图像或视频中的每个人脸的roll/yaw/pitch。roll代表了人头歪的程度;yaw代表了人头左右旋转的程度;pitch代表了人头低头抬头的程度。使用方法如下所示,输入:
./head_pose_estimation.sh
4.2.9车牌识别
车牌识别的整体流程实际上包含了车牌检测+车牌识别两个流程。车牌检测采用了retinanet,车牌识别采用了lprnet。使用该应用,可得到图像或视频中的每个车牌的内容。使用方法如下所示,输入:
./license_recog.sh
4.2.10YOLOV5目标检测
目标检测采用了YOLOV5,使用该应用,可得到图像或视频中属于以下标签的目标的检测框。
"person", "bicycle", "car", "motorcycle", "airplane", "bus", "train", "truck",
"boat", "traffic light", "fire hydrant", "stop sign", "parking meter", "bench", "bird", "cat",
"dog", "horse", "sheep", "cow", "elephant", "bear", "zebra", "giraffe",
"backpack", "umbrella", "handbag", "tie", "suitcase", "frisbee", "skis", "snowboard",
"sports ball", "kite", "baseball bat", "baseball glove", "skateboard", "surfboard", "tennis racket", "bottle",
"wine glass", "cup", "fork", "knife", "spoon", "bowl", "banana", "apple",
"sandwich", "orange", "broccoli", "carrot", "hot dog", "pizza", "donut", "cake",
"chair", "couch", "potted plant", "bed", "dining table", "toilet", "tv", "laptop",
"mouse", "remote", "keyboard", "cell phone", "microwave", "oven", "toaster", "sink",
"refrigerator", "book", "clock", "vase", "scissors", "teddy bear", "hair drier", "toothbrush"
使用方法如下所示,输入:
./object_detect.sh
YOLOV5目标检测-bf16
执行非量化模型,使用方法如下所示,输入:
./object_detect_demo_bf16.sh
YOLOV5目标检测-uint8
执行uint8量化模型。使用方法如下所示,输入:
./object_detect_demo_uint8.sh
4.2.11自学习KNN算法
自学习借鉴的是KNN(k-Nearest Neighbors)的思想。该算法的思想是: 一个样本与数据集中的k个样本最相似, 如果这k个样本中的大多数属于某一个类别, 则该样本也属于这个类别。使用方法如下所示,输入:
./self_learning.sh
执行完成后会在显示屏上出现一个绿色的框。
该AI示例需要用到按键(Key 1)和按键(Key 2),两个按键的位置如下所示:

将需要识别的物体放在摄像头范围内,使该物体可以显示在绿色框中的正中间,此时需要手动标记按下Key1开始标记class0,按下Key1时会串口终端会提示以下信息:
>>>>> key code: 30, action: pressed <<<<<
Please press UP or DOWN button, UP: confirm, DOWN: switch!
>>>>> key code: 30, action: released <<<<<
上述信息为提示您,如果按下Key1则为标注图像,按下Key2则为切换模式。
继续按下Key1可开始自动标记该物体,此时串口终端会输出如下信息:
>>>>> key code: 30, action: pressed <<<<<
Pressed UP button!
class_0 : 1
>>>>> key code: 30, action: released <<<<<
此时再按下Key1会继续继续让您选择继续标注图像还是切换。
>>>>> key code: 30, action: pressed <<<<<
Please press UP or DOWN button, UP: confirm, DOWN: switch!
>>>>> key code: 30, action: released <<<<<
如果需要重复标记多次图像,可以继续按下Key1标记该物体。如下所示:

当标注完类别1(class 0)后按下Key2,串口终端会输出以下内容:
>>>>> key code: 48, action: released <<<<<
>>>>> key code: 48, action: pressed <<<<<
Pressed DOWN button!
switch to class_1
此时会切换标注类别1(class 1),继续按下Key 1进行标注类别1,选择功能。
>>>>> key code: 30, action: pressed <<<<<
Please press UP or DOWN button, UP: confirm, DOWN: switch!
>>>>> key code: 30, action: released <<<<<
继续按下Key 1标注类别1物体
>>>>> key code: 30, action: pressed <<<<<
Pressed UP button!
class_1 : 1
>>>>> key code: 30, action: released <<<<<
如果需要重复标记多次图像,可以继续按下Key1标记该物体,与上面类别0(class 0)标注方法一直。
在标注完成后,在不进入功能选择时,按下key 2结束标注,如下图所示。
>>>>> key code: 30, action: pressed <<<<<
Pressed UP button!
class_1 : 8
>>>>> key code: 30, action: released <<<<<
>>>>> key code: 48, action: released <<<<<
>>>>> key code: 48, action: pressed <<<<<
Pressed DOWN button!
Enter recog!
将刚才标注过的物体放在绿框内,此时会开发板会在显示屏上自动检测识别的物品,识别到物体时,左上角会显示对应物体的类别以及检测的精准度。
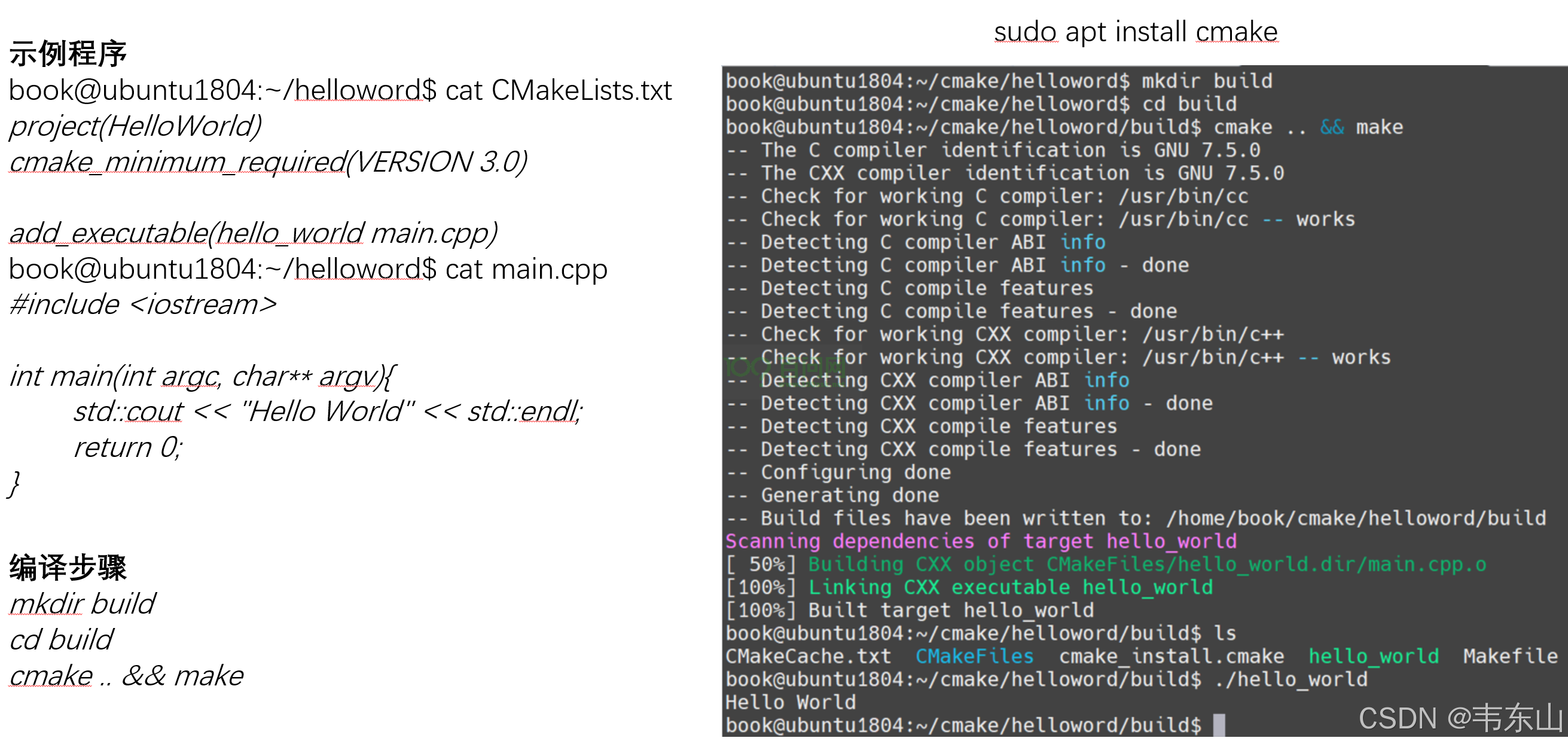
5.编写一个简单的helloword程序
5.1 编写helloword应用程序
打开Ubuntu虚拟机,打开终端进入Home目录中,新建helloword文件夹
ubuntu@ubuntu2004:~$ mkdir helloword
进入 helloword文件夹下,新建hello.c程序。
ubuntu@ubuntu2004:~$ cd helloword/
ubuntu@ubuntu2004:~/helloword$ touch helloword.c
在终端内gedit工具会打开一个 文本编辑器,进入文本编辑器内, 将helloword程序代码粘贴进去,粘贴完成后,直接按下 ctrl + s 保存,最后点击 右上角的 x 关 闭文本编辑器:
ubuntu@ubuntu2004:~/helloword$ gedit helloword.c
helloword程序代码:
#include <stdio.h>
int main (void)
{
printf("hello word!\n");
return 0;
}
编写完成后,保存到 helloword.c 之后。我们需要指定存放交叉编译需要使用的库文件头文件的文件夹。如果需要在任意位置或者终端都可以使用交叉编译工具链,则需要单独 增加 工具链bin的路径至 ubuntu PATH环境变量里,可以添加至 ~/.bashrc也可以在每一个终端单独配置。在终端执行以下命令:
export PATH=$PATH:~/100ask_base-aiApplication-demo/riscv64-buildroot-linux-gnu_sdk-buildroot/bin/
输入完成后,需要验证是否添加成功,在终端输入:
riscv64-linux-gcc -v
输入后可以正常打印gcc version 7.3.0 (2019-11-20_nds64le-linux-glibc-v5d-6c120106e03)即可。
5.2.编写Makefile编译规则
ubuntu@ubuntu2004:~/helloword$ touch Makefile
ubuntu@ubuntu2004:~/helloword$ gedit Makefile
将下面的程序复制到Makefile文件中
CC := riscv64-linux-gcc
helloword: helloword.c
${CC} -o helloword helloword.c
clean:
rm helloword
填写完成后,按下Crtl+s保存Makefile文件。
5.3 交叉编译hellowrod程序
查看当前目录下是否存在helloword.c和Makefile:
ubuntu@ubuntu2004:~/helloword$ ls
helloword.c Makefile
确定文件存在后执行编译命令make进行编译,如下所示:
ubuntu@ubuntu2004:~/helloword$ make
riscv64-linux-gcc -o helloword helloword.c
编译完成后会生成可执行文件hellword。
可以执行 file hellword 命令 来查看编译出来的文件类型 是否是 riscv 架构类型。
ubuntu@ubuntu2004:~/helloword$ file helloword
helloword: ELF 64-bit LSB executable, UCB RISC-V, version 1 (SYSV), dynamically linked, interpreter /lib/ld-linux-riscv64-lp64d.so.1, for GNU/Linux 4.15.0, with debug_info, not stripped
5.2 上传程序到开发板上运行
把编译生成的 hello 文件通过 ssh或者TFTP拷贝到开发板上运行,这里使用TFTP传输,将生成的hello程序拷贝到tftpboot目录下:
ubuntu@ubuntu2004:~/helloword$ cp helloword /home/ubuntu/tftpboot
拷贝完成后,查看Ubuntu当前IP地址,输入ifconfig后,获得IP地址为192.168.0.163

进入开发板的串口终端界面,获取tftpboot目录中helloword文件。
[root@canaan ~ ]$ tftp -g -r helloword 192.168.0.163
helloword 100% |********************************| 11680 0:00:00 ETA
为helloword程序增加可执行权限
[root@canaan ~ ]$ chmod 777 helloword
在开发板端执行helloword程序。
[root@canaan ~ ]$ ./helloword
hello word!
6.编译一个简单的AI demo程序
6.1 编译hello AI的demo程序
在任意目录中使用终端获取Hello AI的demo程序,输入以下命令获取
git clone https://e.coding.net/weidongshan/dongsahnpi-vision/100ask_hello-ai_demo.git
例如:

如果你无法下载,可访问百度网盘资料中的<开发板名称>/5_DongshanPI-Vision_嵌入式AI应用开发资料/2.Hello-AI_demo程序,该目录有demo程序压缩包,传入Ubuntu并解压即可。
下载完成后进入/home/ubuntu/100ask_base-aiApplication-demo/code,新建hello_ai_demo文件夹
ubuntu@ubuntu2004:~$ cd /home/ubuntu/100ask_base-aiApplication-demo/code/
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code$ mkdir hello_ai_demo
进入hello_ai_demo目录下,将获取Hello AI的demo程序拷贝到当前的hello_ai_demo目录下
cp /home/ubuntu/100ask_hello-ai_demo/* ./ -rf
拷贝完成后,可以看到hello-ai-demo文件夹下的文件如下所示:
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code/hello_ai_demo$ ls
CMakeFiles cv2_utils.cc format main.cc object_detect.h
cmake_install.cmake cv2_utils.h images Makefile README.md
CMakeLists.txt file include object_detect.cc
拷贝完成,返回上一级的code目录下,修改code目录下的CMakeLists.txt文件
ubuntu@ubuntu2004:~/ai_demo/100ask_base-aiApplication-demo/code/hello_ai_demo$ cd ../
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code$ gedit CMakeLists.txt
在文件末尾增加一句add_subdirectory(hello_ai_demo),修改后的CMakeLists.txt如下所示:
cmake_minimum_required(VERSION 3.2)
project(ai C CXX)
#set(DEMO_ROOT "${PROJECT_SOURCE_DIR}/../crb_demo")
set(CMAKE_C_FLAGS_DEBUG "-O0 -g3")
set(CMAKE_C_FLAGS_RELEASE "-O2 -s")
set(CMAKE_CXX_FLAGS_DEBUG "-O0 -g3")
set(CMAKE_CXX_FLAGS_RELEASE "-O2 -s")
SET(CMAKE_CXX_FLAGS "${CMAKE_CXX_FLAGS} -fopenmp")
set(input imx219_1080x1920_0.conf imx219_0.conf imx219_1.conf video_192x320.conf video_object_detect_320.conf video_object_detect_432x368.conf video_object_detect_512.conf video_object_detect_640x480.conf video_object_detect_320x320.conf video_object_detect_480x640.conf video_object_detect_640.conf)
install(PROGRAMS ${input} DESTINATION exe)
add_subdirectory(face_detect)
add_subdirectory(face_landmarks)
add_subdirectory(object_detect)
add_subdirectory(face_alignment)
add_subdirectory(face_expression)
add_subdirectory(head_pose_estimation)
add_subdirectory(face_recog)
add_subdirectory(simple_pose)
add_subdirectory(openpose)
add_subdirectory(person_detect)
add_subdirectory(hand_image_classify)
add_subdirectory(license_plate_recog)
add_subdirectory(self_learning)
add_subdirectory(object_detect_demo)
add_subdirectory(retinaface_mb_320)
add_subdirectory(hello_ai_demo)
修改完成后,按下Crtl+s保存修改后的文件。
在code目录的终端下激活环境,输入:
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code$ source build.sh
激活环境完成,进入hello_ai_demo目录,开始进行编译Hello AI的demo程序
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code$ cd hello_ai_demo/
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code/hello_ai_demo$ make

编译完成,即可在hello_ai_demo目录下查看编译完成的可执行程序,如下图红框中所示文件:

6.2 上传程序到开发板运行
把编译生成的 hello 文件通过 ssh或者TFTP拷贝到开发板上运行,这里使用TFTP传输,将生成的hello_ai_demo程序拷贝到tftpboot目录下:
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code/hello_ai_demo$ cp hello_ai_demo ~/tftpboot/
将待检测的图像传入开发板,待测图像已经提前准备在hello_ai_demo目录下的images文件夹下
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code/hello_ai_demo$ cd images/
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code/hello_ai_demo/images$ ls
01_person.bmp 02_cat.bmp
将两张图像拷贝到tftpboot目录下:
ubuntu@ubuntu2004:~/100ask_base-aiApplication-demo/code/hello_ai_demo/images$ cp ./* ~/tftpboot/
拷贝完成后,查看Ubuntu当前IP地址,输入ifconfig后,获得IP地址为192.168.0.163

进入开发板的串口终端界面,获取tftpboot目录中helloword文件。
[root@canaan ~ ]$ tftp -g -r hello_ai_demo 192.168.0.163
hello_ai_demo 100% |********************************| 818k 0:00:00 ETA
[root@canaan ~ ]$ tftp -g -r 01_person.bmp 192.168.0.163
01_person.bmp 100% |********************************| 300k 0:00:00 ETA
[root@canaan ~ ]$ tftp -g -r 02_cat.bmp 192.168.0.163
02_cat.bmp 100% |********************************| 300k 0:00:00 ETA
由于该程序需要使用模型文件对待测图像进行预测,我们可以拷贝开发板中模型文件使用
[root@canaan ~ ]$ cp /app/ai/kmodel/kmodel_release/object_detect/yolov5s_320/yol
ov5s_320_sigmoid_bf16_with_preprocess_output_nhwc.kmodel ./
拷贝完成后可以在当前目录看到对应文件。
[root@canaan ~ ]$ ls
01_person.bmp
02_cat.bmp
data
emmc
hello_ai_demo
yolov5s_320_sigmoid_bf16_with_preprocess_output_nhwc.kmodel
为hello_ai_demo程序增加可执行权限
[root@canaan ~ ]$ chmod 777 hello_ai_demo
在开发板端执行hello_ai_demo程序。
./hello_ai_demo ./yolov5s_320_sigmoid_bf16_with_preprocess_output_nhwc.kmodel ./01_person.bmp
执行结果如下所示:
例子1:
[root@canaan ~ ]$ ./hello_ai_demo ./yolov5s_320_sigmoid_bf16_with_preprocess_out
put_nhwc.kmodel ./01_person.bmp
hello 100ask AI demo!
==> run inference finished!
image inference result: person:0.89
程序识别出01_person.bmp文件中,有人,概率为0.89。
例子2:
[root@canaan ~ ]$ ./hello_ai_demo ./yolov5s_320_sigmoid_bf16_with_preprocess_out
put_nhwc.kmodel ./02_cat.bmp
hello 100ask AI demo!
==> run inference finished!
image inference result: cat:0.86
它识别出02_cat.bmp图片文件中,有猫,概率为0.86。
注意:您可以传入自定义的图像进行预测,需要保证图像格式为bmp,尺寸为320x320。
6.3 hello AI程序讲解
6.3.1 程序框架

6.3.2 程序讲解
从BMP文件提取RGB分量
int get_rgb_from_bmp(char *file, uint8_t *rbuf, uint8_t *gbuf, uint8_t *bbuf)
{
int err;
unsigned int *p;
unsigned int rgb32;
int r_pos = 0, g_pos = 0, b_pos = 0;
/* 点阵数据 */
T_PixelDatas bmpPixelDatas;
/* 解析BMP文件 */
err = GetPixelDatasForIcon(file, &bmpPixelDatas);
if (err)
{
DebugPrint("Can not get digit bmp file: %s\n", file);
return -1;
}
/* 把里面的RGB单独拆出来 */
for (int y = 0; y < MIN(320, bmpPixelDatas.iHeight); y++)
{
p = (unsigned int *)(bmpPixelDatas.aucPixelDatas + y * bmpPixelDatas.iLineBytes);
r_pos = g_pos = b_pos = y*320;
for (int x = 0; x < MIN(320, bmpPixelDatas.iWidth); x++)
{
rgb32 = p[x];
/*将RGB三通道的数据分别存入3个buf*/
rbuf[r_pos++] = (rgb32 >> 16) & 0xff;
gbuf[g_pos++] = (rgb32 >> 8) & 0xff;
bbuf[b_pos++] = (rgb32 >> 0) & 0xff;
}
}
return 0;
}
初始化模型
objectDetect od(0.5, 0.45, 320, {320, 320});//置信度、nms阈值、模型尺寸、图像尺寸
od.load_model(argv[1]); //加载模型 yolov5s_320_sigmoid_bf16_with_preprocess_output_nhwc.kmodel
od.prepare_memory(); // memory allocation 准备内存
使用模型
/* 把RGB数据复制进od里 */
od_r = (uint8_t *)od.virtual_addr_input[0];
od_g = od_r + 320*320;
od_b = od_g + 320*320;
memcpy(od_r, rbuf, 320*320);
memcpy(od_g, gbuf, 320*320);
memcpy(od_b, bbuf, 320*320);
od.set_input(0);//设置输入
od.set_output();//设施输出
od.run();//运行推理
od.get_output();//获得推理结果
后处理
/*后处理:将推理结果转换为可使用的数据*/
std::vector<BoxInfo> result;
od.post_process(result);//运行后处理
for (auto r : result)
{
std::string text = od.labels[r.label] + ":" + std::to_string(round(r.score * 100) / 100.0).substr(0,4);
cout<<"image inference result: ";
cout<<text<<endl;
}
7.嵌入式开发
7.1编译工具链
工具链是一组编程工具,用于开发软件、创建软件产品。工具链通常是另一个计算机程序或一组相关程序。通常,工具链里有多个工具,前一个工具的输出结果,是下一个工具的输入,也就是说前一个工具处理完,再交给下一个工具处理。
一个简单工具链可能由三部分组成:编译器和链接器(将源代码转换为可执行程序)、库(为操作系统提供接口)和调试器(用于测试和调试创建的程序)。一个复杂的软件产品,如视频游戏,需要准备音效、音乐、纹理、3 维模型和动画的工具,以及将这些资源组合成成品的附加工具。
**GNU ** 工具链 是一个广泛收集的、遵守GNU协议的、众多编程工具。这些工具形成一个工具链,用于开发应用程序和操作系统。
GNU 工具链在Linux、一些BSD系统和嵌入式系统软件的开发中起着至关重要的作用。
7.2 交叉编译工具链
**交叉编译器:**在平台A上使用它能够生成程序,这个程序时运行在平台B上的。例如,在PC上运行程序,但这个程序是在Android 智能手机上运行的,这个编译器就是交叉编译器。
在PC上为其他平台(目标平台)编译代码时,需要交叉编译器。能否直接在目标平台上编译程序?比如在ARM板上编译程序?大多时候不可行,因为ARM板资源很可能受限。
交叉编译器的基本用途是将构建环境与目标环境分开。这在几种情况下很有用:
-
设备资源极其有限的嵌入式计算机。例如,微波炉将有一个非常小的计算机来读取它的键盘和门传感器,向数字显示器和扬声器提供输出,并控制烹饪食物的机器。这台计算机通常不够强大,无法运行编译器、文件系统或开发环境。
-
为多目标编译。例如,公司可能希望用同一套代码,支持多个不同的操作系统。通过使用交叉编译器,可以设置单个构建环境,为每个目标系统单独编译程序。
-
在服务器上编译。服务器性能强大,很多公司都是在服务器上为其他平台编译程序。
-
引导到新平台。在为新平台开发软件时,人们使用交叉编译器来编译必要的工具,例如操作系统和本地编译器。


7.3 获得合适的交叉编译工具链
-
获取现成的
- 来自发行版系统内: Ubuntu 和 Debian 有许多现成的交叉编译器。
-
来自不同组织:
-
芯片原厂提供的交叉编译工具链(一般包含在配套的BSP内)。
-
Bootlin社区提供的各种架构工具链 。
-
ARM 官方提供的aarch32 aarch64工具链。
-
Linaro 提供 ARM 和 AArch64 工具链,以及一些早期版本工具链。
-
gnutoolchains 提供可以在windows上运行的交叉编译工具链。
-
riscv-collab 提供的riscv GNU 工具链。
-
-
自己编译构建
-
Crosstool-NG,专门构建交叉编译工具链的工具。 迄今为止拥有最可配置选项/并支持多种功能的。
-
嵌入式Linux构建系统一般都知道如何构建交叉编译工具链:Yocto/OpenEmbedded、Buildroot、OpenWRT等。
-
-
参考文档
-
Crosstool-NG 文档,https://github.com/crosstool-ng/crosstool-ng/blob/master/docs/
-
GCC 文档,https://gcc.gnu.org/onlinedocs/
-
Binutils 文档,https://sourceware.org/binutils/docs/
-
7.4 Makefile构建工具

7. 5 CMake构建工具
CMake 是一个开源的跨平台工具系列,旨在构建、测试和打包软件。 CMake 用于使用简单的平台和编译器独立配置文件来控制软件编译过程,并生成可在您选择的编译器环境中使用的本机 makefile 和工作区。 CMake 工具套件是由 Kitware 创建的,旨在响应 ITK 和 VTK 等开源项目对强大的跨平台构建环境的需求。
CMake 是 Kitware 的商业支持开源软件开发平台集合的一部分。

第四篇 AI概念及理论知识
1.人工智能与机器学习
人工智能是研究开发用于模拟和扩展人的智能的理论、方法、技术及应用系统的一门技术科学。
机器学习是基于大量数据而成,让计算机像人类一样学习和行动的科学,通过以观察和现实世界互动的形式向他们提供数据和信息,以自主的方式改善他们的学习。机器学习包括深度学习、强化学习、传统机器学习等。

深度学习是模拟人脑所构成的,支持从大量数据中学习,学习这些样本数据中的内在规律和表示层次。
强化学习是构建一个智能体,在一个复杂的环境下去最大可能获得奖励,通过感知环境所处的状态对动作的反应来指导获取更好的动作,从而获得最大的收益。
传统机器学习是从一些观测(训练)样本出发,使用统计学、线性代数、优化算法等数学方法,从已有数据中学习并构建预测模型,进而用于对未知数据的预测和分类。
1.1 机器学习
那么如何达到我们定义中像人类学习和行动呢,下面以一个线性回归的例子讲解什么是机器学习。
在X-Y坐标上给定一些样点值,求解一条直线,求该直线可以表示样点值的趋势。这是最基础的线性回归问题,回归分析中,只用一个自变量和一个因变量,且两者的关系可以用一条直线近似表示。

该直线可以看成y=ax函数,其中a代表直线的斜率。如果是依靠我们大致绘制的直线,并测量其a,这样只需要提供x值即可推测出y值。
但这仅局限于数量很少的样点,如果大量的样点数据,依靠人脑是绘制的趋势直线是不准确的。
假设我们设计一个程序求解样点的趋势线,先定义趋势线公式为y=ax,然后如下操作:
-
先随机选取a的值,将样本点的x值代入求出y’值,差值e=(y’-y)^2。如此计算所有样本点的差值,所有差值相加得到总误差E_1 。
-
再将a的值增大或减小:a = a + delta,这个增大或减小的区间值称为步长值。重新计算总误差E_2。
-
对比 E_1和E_2 的值,如果 E_2小于 E_1 ,则代表总误差减小,步长方向正确。如果 E_2大于 E_1 ,则代表总误差增大,步长方向错误,需要修改步长方向: delta = - delta。
-
从步骤2继续循环,直到误差变化不再降低为止。
在这个循环过程中,如果误差比较大,可以加大delta值以减少循环次数;如果误差已经比较小了,可以减小delta值以提高精度。

例如:假设a_1=a_0+步长值,再将所有的样本点重新计算得出新的误差 E_2。对比 E_1和E_2 的值,如果 E_2小于 E_1 ,则代表总误差减小,步长方向正确。如果 E_2大于 E_1 ,则代表总误差增大,步长方向错误,需要修改步长方向。

例如:假设原来的步长值为-0.6,在下次迭代时将 ,
a
2
=
a
1
+
1
=
a
0
−
0.6
+
1
=
a
0
+
0.4
a_2=a_1+1 = a_0-0.6+1=a_0+0.4
a2=a1+1=a0−0.6+1=a0+0.4
此时步长值=+1 ,使原始的a值增加,然后继续迭代。如果在新迭代后,总误差E值降低了,则证明步长方向修改正确。再按照一定的步长与刚刚a值的方向迭代下去,直到总误差值E不再降低为止,此时得到的a就是对所以已知样本点的最佳拟合函数f(x)=ax的参数。

根据误差的变化趋势决定参数的调整方向,力度(误差越大步长值越大,反之则越小)从而获取最低误差的方式就被称为梯度下降法。
**问:**为什么叫做梯度下降法呢?
**答:**我们在线性回归模型中我们需要根据误差来确定步长的调整,计算的方式是均方误差函数(损失函数),公式为:
C
o
s
t
损失函数
:
∑
i
=
1
n
(
y
‘
−
y
i
)
2
n
或者
∑
i
=
1
n
(
y
‘
−
y
i
)
2
2
n
Cost损失函数:\frac{\sum_{i=1}^n (y^`- y^i)^2}{n} 或者\frac{\sum_{i=1}^n (y^`- y^i)^2}{2n}
Cost损失函数:n∑i=1n(y‘−yi)2或者2n∑i=1n(y‘−yi)2
那么我们肯定是想计算出该均方误差公式的最小值,那么想要求得函数最小值,在数学方法中,我们就会想到求导,并求二阶偏导函数的驻点。下面展示均方误差函数J(w)求偏导后的结果:
∂
J
(
w
)
∂
w
=
[
∑
i
=
1
n
(
y
‘
−
y
i
)
2
2
n
]
′
=
∑
i
=
1
n
(
w
x
i
−
y
i
)
n
x
i
\frac{\partial J(w)}{\partial w}=[\frac{\sum_{i=1}^n (y^`- y^i)^2}{2n}]'\\ =\frac{\sum_{i=1}^n (wx^i - y^i)}{n}x^i
∂w∂J(w)=[2n∑i=1n(y‘−yi)2]′=n∑i=1n(wxi−yi)xi
权重w的迭代过程是以负梯度的方向(减少误差的方向)来决定每次迭代时权重w的变化方向,从而使每次迭代后目标函数(误差函数)的值逐渐减小。
w
=
w
−
α
∗
∂
J
(
w
)
∂
w
其中
α
为学习率,
∂
J
(
w
)
∂
w
为误差函数的偏导数
w=w-\alpha *\frac{\partial J(w)}{\partial w}\\ 其中\alpha为学习率,\frac{\partial J(w)}{\partial w}为误差函数的偏导数
w=w−α∗∂w∂J(w)其中α为学习率,∂w∂J(w)为误差函数的偏导数
每次迭代都会修改权重w值,使其以α学习速率沿着偏导数的反方向进行移动。
均方误差函数是一个二次函数。它实际的函数图像可能是如图所示的一个抛物线。图中的损失值Cost就是误差值。假设我们在初始a值的点时,我们的损失值很大,我们想要降低损失值,需要沿着函数的梯度方向(函数的方向)往下走,直到找到损失值的最低点(即找到最低的误差值)。

如果是计算大量样本点的时候,可以知道整个迭代过程中运算量是很大,计算机需要不断的在大量样本点中运算、分析、试错、调整、重新计算,这个过程称为训练。线性回归求解训练过程如图所示:

如图所示的回归分析中,训练的目的就是在大量样本点中找出描述样本点之间规律的函数的参数。上述基本线性模型的整个过程称为机器学习。
1.2 模型和拟合
通过前面的线性回归学习我们知道,建立的模型需要与数据集对应,简单的数据集需要对应简单的模型,复杂的数据集需要对应复杂的模型。以求回归问题为例,求下面两个数据集的回归线:

通过观察上面两个数据集可以发现,我们可以发现样本数据集1可以通过建立简单的y=ax+b的线性模型求得该样本的回归线;样本数据集2数据集较为复杂,如果直接使用简单的y=ax+b的线性模型,无法拟合出样本数据集2的回归线,我们称为不拟合,此时需要建立一个更为复杂的模型,如y=ax^2等,对样本数据集进行回归拟合。

从上图可以看出,模型的复杂度需要和数据集的复杂程序对应,如果复杂数据使用简单模型可能会出现不拟合的情况。

如果机器学习的结果拟合度不够高,结果相差很大,称为不拟合。可以加入高次项。但如果加入了过多的高次幂项,可能会导致正确率不升反降,此现象称为过度拟合。过拟合为得到高精度的拟合结果,而使模型变得过度复杂,导致模型参数不合理、表现力、预测力变差。

1.3 线性回归模型
1.3.1 实现简单线性回归
假设提供一些样本点数据,样本点数据为:[1, 3.5], [2, 4.7], [3, 5.3], [4, 7.1],[5, 9.6],[6, 13.5], [7, 16.2], [8, 19.4],[9, 23.2], [10, 33.8],该样本点在图像中的位置如下图所示:

预先构建一个直线函数y=wx,其中w为权重,不考虑偏置值。使用该直线绘制这样本点的线性回归直线,其中权重更新公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i\\ 损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
下面基于这些样本点我们来构建一个python程序实现,对样本点进行线性回归预测。下面展示代码的流程框图:

代码流程为:
1. 导入numpy包,该包是数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
2. 导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
3. 调用求解权重函数,计算直线函数y=wx中的w值。
1. 判断是否达到迭代次数。
2. 使用权重值w,代入x值计算预测值h
3. 计算预测值h和真实值y的差值
4. 求解梯度值
5. 更新权重值w
6. 计算损失值
7. 当没有达到迭代次数,继续返回步骤2。当达到迭代次数,则返回权重值。
4. 使用新权重值预测数据。
5. 将样本点和回归直线绘制到坐标轴上。
1.3.2 简单线性回归代码解析
导入拓展包,支持矩阵运算和可视化
导入numpy包,该包数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
import numpy as np
import matplotlib.pyplot as plt
初始化样本点数据
使用多维数组存储样本点数据,并获得该数组的行数和列数
#样本点数据
x = np.array([[1, 3.5], [2, 4.7], [3, 5.3], [4, 7.1],[5, 9.6],
[6, 13.5], [7, 16.2], [8, 19.4],[9, 23.2], [10, 33.8]])
m, n = np.shape(x) #获得样本点数据的行数和列数 m:行数 10 n:列数 2
print("x样本点数据的行数m和列数n:",m,n)
获得样本点的x值和y值
创建一个10行2列的多维数组,并将其置为0。将每一行的第一列存储样本点数据的x值,存储结果保存在x_data中。
将样本点数据的y值,存储在y_data中。
x_data = np.zeros((m, n)) #新建10行2列矩阵,并将值都置为0
x_data[:, :-1] = x[:, :-1] #获取样本点数据中除最后一列之外的所有行和所有列,即样本点数据中的x
y_data = x[:, -1] #获取样本点数据中所有行和最后一列,-1代表最后一列,即样本点数据中的y
初始化权重值
创建一个权重矩阵,矩阵为[1,0]。
m, n = np.shape(x_data) #获得样本点数据中的x行数和列数 m:行数 10 n:列数 2
theta = np.array([1,0]).reshape(2) #创建一个权重矩阵,初始化权重为[1,0]
定义权重函数
由于我们定义的直线的函数为y=wx,其中w为权重。该函数主要用于求解权重w值,其中实现了权重更新公式和损失函数,如下所示的两个公式:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i\\ 损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
#求解权重函数
#iter:迭代次数 x:横坐标 y:纵坐标 w:权重 alpha:学习率
def gradientDescent(iter, x, y, w, alpha):
x_train = x.transpose() #交换矩阵的两个维度
for i in range(0, iter):
pre = np.dot(x, w) #矩阵乘法
loss = (pre - y) #预测值和真实值的差值
#权重更新公式
gradient = np.dot(x_train, loss) / m #求解梯度
w = w - alpha * gradient #更新权重
#使用损失函数求解损失值
cost = (1.0 / (2 * m)) * np.sum(np.square((np.dot(x, w)) - y))
print("第{}次梯度下降损失值为: {}".format(i,round(cost,2)))
return w
1.交换矩阵的两个维度
x_train = x.transpose()
∣ 1 0 2 0 3 0 4 0 5 0 6 0 7 0 8 0 9 0 10 0 ∣ 交换矩阵的两个维度,转置矩阵结果为 ∣ 1 2 3 4 5 6 7 8 9 10 0 0 0 0 0 0 0 0 0 0 ∣ \left|\begin{matrix} 1 & 0\\ 2 & 0\\ 3 & 0\\ 4 & 0\\ 5 & 0\\ 6 & 0\\ 7 & 0\\ 8 & 0\\ 9 & 0\\ 10 & 0\\ \end{matrix} \right| 交换矩阵的两个维度,转置矩阵结果为\left|\begin{matrix} 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{matrix} \right| 123456789100000000000 交换矩阵的两个维度,转置矩阵结果为 102030405060708090100
2.计算预测值
pre = np.dot(x, w) #矩阵乘法
假设是第一次进行计算,那么x为样本点的x值,w权重为[1,1],计算方式为:
∣
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
∣
∗
∣
1
0
∣
=
∣
1
2
3
4
5
6
7
8
9
10
∣
\left|\begin{matrix} 1 & 0\\ 2 & 0\\ 3 & 0\\ 4 & 0\\ 5 & 0\\ 6 & 0\\ 7 & 0\\ 8 & 0\\ 9 & 0\\ 10 & 0\\ \end{matrix} \right|*\left|\begin{matrix} 1\\ 0 \end{matrix} \right|=\left|\begin{matrix} 1\\ 2\\ 3\\ 4\\ 5\\ 6\\ 7\\ 8\\ 9\\ 10\\ \end{matrix} \right|
123456789100000000000
∗
10
=
12345678910
3.计算差值
差值等于预测值减真实值,计算权重更新公式中的h(x)-y部分。公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
l
o
s
s
=
(
h
θ
(
x
i
)
−
y
i
)
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i \\ loss = (h_\theta(x^i) - y^i)
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xjiloss=(hθ(xi)−yi)
loss = (pre - y) #预测值和真实值的差值
计算过程如下所示:
l
o
s
s
=
∣
1
2
3
4
5
6
7
8
9
10
∣
−
∣
3.5
4.7
5.3
7.1
9.6
13.5
16.2
19.4
23.2
33.8
∣
=
∣
−
2.5
−
2.7
−
2.3
−
3.1
−
4.6
−
7.5
−
9.2
−
11.4
−
14.2
−
23.8
∣
loss=\left|\begin{matrix} 1\\ 2\\ 3\\ 4\\ 5\\ 6\\ 7\\ 8\\ 9\\ 10\\ \end{matrix} \right|- \left|\begin{matrix} 3.5\\ 4.7\\ 5.3\\ 7.1\\ 9.6\\ 13.5\\ 16.2\\ 19.4\\ 23.2\\ 33.8\\ \end{matrix} \right|= \left|\begin{matrix} -2.5\\ -2.7\\ -2.3\\ -3.1\\ -4.6\\ -7.5\\ -9.2\\ -11.4\\ -14.2\\ -23.8\\ \end{matrix} \right|
loss=
12345678910
−
3.54.75.37.19.613.516.219.423.233.8
=
−2.5−2.7−2.3−3.1−4.6−7.5−9.2−11.4−14.2−23.8
4.权重更新
计算梯度值,即将差值 乘 样本点的x值,再除以样本点的个数,公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
梯度值:
g
r
a
d
i
e
n
t
=
1
m
×
l
o
s
s
⋅
x
j
i
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i \\ 梯度值:gradient=\frac{1}{m} \times loss \cdot x_j^i
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji梯度值:gradient=m1×loss⋅xji
gradient = np.dot(x_train, loss) / m #求解梯度
计算过程如下所示:
g
r
a
d
i
e
n
t
=
∣
1
2
3
4
5
6
7
8
9
10
0
0
0
0
0
0
0
0
0
0
∣
∗
∣
−
2.5
−
2.7
−
2.3
−
3.1
−
4.6
−
7.5
−
9.2
−
11.4
−
14.2
−
23.8
∣
÷
10
=
∣
−
616.6
0
∣
÷
10
=
∣
−
61.66
0
∣
gradient =\left|\begin{matrix} 1 & 2 & 3 & 4 & 5 & 6 & 7 & 8 & 9 & 10\\ 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 & 0 \\ \end{matrix} \right|*\left|\begin{matrix} -2.5\\ -2.7\\ -2.3\\ -3.1\\ -4.6\\ -7.5\\ -9.2\\ -11.4\\ -14.2\\ -23.8\\ \end{matrix} \right| \div 10 = \left|\begin{matrix} -616.6\\ 0\\ \end{matrix} \right| \div 10=\left|\begin{matrix} -61.66\\ 0\\ \end{matrix} \right|
gradient=
102030405060708090100
∗
−2.5−2.7−2.3−3.1−4.6−7.5−9.2−11.4−14.2−23.8
÷10=
−616.60
÷10=
−61.660
计算新权重
新权重 等于 原权重 减 梯度值 乘 学习率,计算公式如下图所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
权重计算公式:
w
=
w
−
α
×
g
r
a
d
i
e
n
t
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i \\ 权重计算公式:w = w - \alpha \times gradient
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji权重计算公式:w=w−α×gradient
w = w - alpha * gradient #更新权重
计算过程如下所示:
w
=
∣
1
0
∣
−
0.01
⋅
∣
−
61.66
0
∣
=
∣
1.6166
0
∣
w=\left|\begin{matrix} 1\\ 0\\ \end{matrix} \right| - 0.01\cdot \left|\begin{matrix} -61.66\\ 0\\ \end{matrix} \right| = \left|\begin{matrix} 1.6166\\ 0\\ \end{matrix} \right|
w=
10
−0.01⋅
−61.660
=
1.61660
5.计算损失值
损失函数公式为:
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
cost = (1.0 / (2 * m)) * np.sum(np.square((np.dot(x, w)) - y))
这段程序直接完整实现了损失函数,程序较为复杂,我们直接把该程序从里到外拆开来看。
从括号最里层来看:
np.dot(x, w)
该程序作用是将权重与样本点的x值 相乘 求得预测值。代码实现公式部分为:
h
θ
(
x
i
)
=
∣
1
0
2
0
3
0
4
0
5
0
6
0
7
0
8
0
9
0
10
0
∣
∗
∣
1.6166
0
∣
=
∣
1.6166
3.2332
4.8498
6.4664
8.083
9.6996
11.3162
12.9328
14.5494
16.166
∣
h_\theta(x^i) =\left|\begin{matrix} 1 & 0\\ 2 & 0\\ 3 & 0\\ 4 & 0\\ 5 & 0\\ 6 & 0\\ 7 & 0\\ 8 & 0\\ 9 & 0\\ 10 & 0\\ \end{matrix} \right|* \left|\begin{matrix} 1.6166\\ 0\\ \end{matrix} \right| = \left|\begin{matrix} 1.6166 \\ 3.2332 \\ 4.8498 \\ 6.4664 \\ 8.083 \\ 9.6996 \\ 11.3162 \\ 12.9328 \\ 14.5494 \\ 16. 166\\ \end{matrix} \right|
hθ(xi)=
123456789100000000000
∗
1.61660
=
1.61663.23324.84986.46648.0839.699611.316212.932814.549416.166
(np.dot(x, w)) - y)
该程序作用是求预测值和真实值的差值。代码实现公式部分为:
(
h
θ
(
x
i
)
−
y
i
)
=
∣
1.6166
3.2332
4.8498
6.4664
8.083
9.6996
11.3162
12.9328
14.5494
16.166
∣
−
∣
3.5
4.7
5.3
7.1
9.6
13.5
16.2
19.4
23.2
33.8
∣
=
∣
−
1.8834
−
1.4668
−
0.4502
−
0.6336
−
1.517
−
3.8004
−
4.8838
−
6.4672
−
8.6506
−
17.634
∣
(h_\theta(x^i) - y^i) = \left|\begin{matrix} 1.6166 \\ 3.2332 \\ 4.8498 \\ 6.4664 \\ 8.083 \\ 9.6996 \\ 11.3162 \\ 12.9328 \\ 14.5494 \\ 16. 166\\ \end{matrix} \right|-\left|\begin{matrix} 3.5\\ 4.7\\ 5.3\\ 7.1\\ 9.6\\ 13.5\\ 16.2\\ 19.4\\ 23.2\\ 33.8\\ \end{matrix} \right|= \left|\begin{matrix} -1.8834 \\-1.4668 \\ -0.4502 \\ -0.6336 \\-1.517\\ -3.8004\\ -4.8838 \\ -6.4672\\ -8.6506 \\-17.634 \end{matrix} \right|
(hθ(xi)−yi)=
1.61663.23324.84986.46648.0839.699611.316212.932814.549416.166
−
3.54.75.37.19.613.516.219.423.233.8
=
−1.8834−1.4668−0.4502−0.6336−1.517−3.8004−4.8838−6.4672−8.6506−17.634
np.square((np.dot(x, w)) - y)
该程序作用是针对差值进行求平方的操作。代码实现公式部分为:
(
h
θ
(
x
i
)
−
y
i
)
2
=
∣
−
1.8834
−
1.4668
−
0.4502
−
0.6336
−
1.517
−
3.8004
−
4.8838
−
6.4672
−
8.6506
−
17.634
∣
2
=
∣
3.54719556
2.15150224
0.20268004
0.40144896
2.30128900
14.4430402
23.85150244
41.8246758
74.8328804
310.957956
∣
(h_\theta(x^i) - y^i)^2 =\left|\begin{matrix} -1.8834 \\-1.4668 \\ -0.4502 \\ -0.6336 \\-1.517\\ -3.8004\\ -4.8838 \\ -6.4672\\ -8.6506 \\-17.634 \end{matrix} \right|^2 =\left|\begin{matrix} 3.54719556 \\ 2.15150224 \\0 .20268004 \\0.40144896\\ 2.30128900 \\14.4430402\\ 23.85150244 \\41.8246758\\ 74.8328804 \\310.957956\end{matrix} \right|
(hθ(xi)−yi)2=
−1.8834−1.4668−0.4502−0.6336−1.517−3.8004−4.8838−6.4672−8.6506−17.634
2=
3.547195562.151502240.202680040.401448962.3012890014.443040223.8515024441.824675874.8328804310.957956
np.sum(np.square((np.dot(x, w)) - y))
3.54719556 + 2.15150224 + 0.20268004 + 0.40144896 + 2.30128900 + 14.4430402 + 23.85150244 + 41.8246758 + 74.8328804 + 310.957956 = 474.514170 3.54719556 + 2.15150224 + 0.20268004 +0.40144896+\\ 2.30128900 +14.4430402+ 23.85150244 +41.8246758+ 74.8328804 +310.957956 =474.514170 3.54719556+2.15150224+0.20268004+0.40144896+2.30128900+14.4430402+23.85150244+41.8246758+74.8328804+310.957956=474.514170
该程序作用是将括号内的矩阵元素进行求和,即将矩阵中的每一个元素进行相加求和,最终得到一个数。
(1.0 / (2 * m)) * np.sum(np.square((np.dot(x, w)) - y))
该程序主要实现公式前面的1/2m与后面的计算出来的数进行相乘,代码实现公式部分为:
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
=
1
2
∗
10
∗
474.514170
=
1
20
∗
474.514170
=
23.7257085
\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2 =\frac{1}{2*10}*474.514170 =\frac{1}{20}*474.514170= 23.7257085
2m1i=1∑m(hθ(xi)−yi)2=2∗101∗474.514170=201∗474.514170=23.7257085
获得新权重
调用求解权重函数后,获得新权重。使用新权重计算预测值,打印输出新权重的值。
result = gradientDescent(1000, x_data, y_data, theta, 0.01) #调用求解权重函数
y_pre = np.dot(x_data, result) #使用新权重求解预测值
print("线性回归模型 w: ", result)
绘制可视化图像
使用matplotlib包中的plt工具绘制坐标系,并将样本点的值绘制在坐标系中,使用绿色的点进行表示;绘制线性回归直线在坐标系中,使用红色的线进行表示;使用一个窗口显示绘制的图像。
plt.scatter(x[:, 0], x[:, 1], color='g',label ="Points") #在XY坐标轴上绘制样本点,样本点的颜色为绿色,标签值为Points
plt.plot(x[:, 0], y_pre, color='r',label ="Linear Regression") #在XY坐标轴上绘制线性回归直线,颜色为红色
plt.xlabel('x') #横坐标的标签
plt.ylabel('y') #纵坐标的标签
plt.legend() #给图像加图例,将样本点和直线的标签值增加到图像中
plt.show() #显示所有打开的图形,即打开一个窗口显示图片
总结
该程序主要带大家了解使用python中的numpy库进行求解线性回归问题,手动实现一个最简单的线性回归模型,了解在机器学习中的训练、损失函数、梯度等概念,同时学习如何在python程序中实现矩阵进行加减乘除操作。大家如果对公式不太理解,可查看线性回归梯度下降公式推导。
1.3.3 Sklearn实现房价预测模型
这里参考经典的波士顿房价预测问题,假设你是一个房产经理人,现在你需要根据手上拥有的房产数据回答客户的问题,客户会提出想购买的房屋面积,你需要根据房屋面积给客户进行报价。
想要解决这个问题,我们需要建立的一个回归模型,并使用房产数据进行训练,训练出的模型可以根据当前地区的房屋面积预测平均价格。这里收集了本地的房地产市场数据,使用开源的机器学习库Scikit-learn,对数据进行回归模型的训练,将训练结果进行线性回归和预测。
下面展示100个房地产数据样本的散点图,横坐标为房屋面积,纵坐标为房屋价格。

使用表格的形式将房地产数据样本存储在HousePrice.csv表格文件下,使用pandas读取表格文件下的样本数据,使用Scikit-learn库中内置的线性回归建立模型,并使用HousePrice.csv文件中的数据进行训练,训练完成之后,将回归直线绘制在房地产数据样本的散点图上。程序流程图如下所示:

代码流程为:
1. 导入numpy包,该包是数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
2. 导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
3. 导入pandas包,该包是数据分析支持库,提供强大的数据处理和分析工具,可支持数据的导入、清洗、转换和分析。
4. 导入sklearn包,该包是开源机器学习库,它基于NumPy、SciPy和matplotlib,支持各种机器学习模型,包括分类、回归、聚类和降维等。
5. 使用pandas库读取csv文件,获取表格文件中房产样本数据,包括房屋面积和售价。
6. 拆分数据集,将1/4的数据集划分为测试数据集,剩下3/4的数据集划分为训练数据集,用于构建线性回归模型。
7. 使用sklearn内置的LinearRegression函数构建线性回归模型,将训练数据集作为参数传入,并进行训练得到线性模型的权重值和偏置值,即函数y=wx+b中的w和b。
8. 使用训练得到的线性模型传入测试数据集中的数据进行预测,得到预测值。
9. 使用matplotlib的工具将样本点和回归直线绘制到坐标轴上。
1.3.4 Sklearn房价预测代码解析
导入拓展包,支持矩阵运算、可视化、
-
导入numpy包,该包数组处理包,提供了处理 n 维数组的工具,即提供矩阵运算能力。
-
导入matplotlib包,该包可支持Python 的 2D 可视化绘图库,可创建静态、动画和交互式可视化图像。
-
导入pandas包,该包是数据分析支持库,提供强大的数据处理和分析工具,可支持数据的导入、清洗、转换和分析。我们主要使用该包用于读取文件中的房产数据。
-
导入sklearn包,该包是开源机器学习库,它基于NumPy、SciPy和matplotlib,支持各种机器学习模型,包括分类、回归、聚类和降维等。我们主要是使用该包中预先定义好的线性回归模型,帮助我们拆分数据集,并训练文件中的房产数据。
import numpy as np
import matplotlib.pyplot as plt
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
读取数据文件中的样本
使用pandas库中read_csv函数读取数据集文件,该函数读取文件后会返回一个reader对象,该对象遍历csv文件的每一行,并返回每一行作为一个列表。
使用pandas库iloc函数读取数据的某行或者某列,将数据集中的除了第一列的所有数据,将所有数据转换为numpy数据,并存放在X中;将数据集中的最后一列的的所有数据,将所有数据转换为numpy数据,并存放在Y中;
dataset = pd.read_csv('HousePrice.csv') #读取csv文件,即读取数据集文件
X = dataset.iloc[ : , : 1 ].values #获取样本点数据中的所有行和除了第1列,即样本点数据中的x
Y = dataset.iloc[ : , 1 ].values #获取样本点数据中所有行和第1列,1代表第一列,即样本点数据中的y
拆分数据集
使用sklearn库中train_test_split函数可以将样本数据拆分为训练数据集和测试数据集,X为输入数据,Y为结果数据,test_size = 1/4为拆分四分之一的数据出来作为测试数据集。
#将数据集拆分为训练数据集X_train,Y_train和测试数据集X_test,Y_test
X_train, X_test, Y_train, Y_test = train_test_split( X, Y, test_size = 1/4)
使用sklearn创建线性回归模型
使用sklearn库中LinearRegression函数创建一个普通最小二乘法的线性回归,使用fit方法传入训练数据集,拟合线性模型,其中权重更新和损失函数的公式与上一小节我们手动构建的线性回归是一致的。公式如下所示:
权重更新公式
:
w
=
w
−
α
1
m
×
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
x
j
i
损失函数
:
c
o
s
t
=
1
2
m
∑
i
=
1
m
(
h
θ
(
x
i
)
−
y
i
)
2
权重更新公式:w=w-\alpha \frac{1}{m} \times \sum_{i=1}^m (h_\theta(x^i) - y^i)x_j^i\\ 损失函数:cost=\frac{1}{2m} \sum_{i=1}^m (h_\theta(x^i) - y^i)^2
权重更新公式:w=w−αm1×i=1∑m(hθ(xi)−yi)xji损失函数:cost=2m1i=1∑m(hθ(xi)−yi)2
model = LinearRegression() #创建线性回归模型
model = model.fit(X_train, Y_train) #训练拟合线性模型
print("****************************")
print("House Price Prediction Done!")
print("model Regression coefficient:",model.coef_) #打印输出权重
print("model Regression intercep",model.intercept_) #打印输出偏置
使用训练后的模型预测新数据
将测试集中的数据传入训练后的线性回归模型进行预测,并打印真实数据和预测数据。
Y_pred = model.predict(X_test) #模型预测
print("测试集中的真实值:",Y_test)
print("测试集中的预测值:",Y_pred)
绘制可视化图
使用matplotlib包中的plt工具绘制坐标系,并将样本点的值绘制在坐标系中,使用绿色的点进行表示;绘制线性回归直线在坐标系中,使用红色的线进行表示;使用一个窗口显示绘制的图像。
plt.scatter(X , Y, color = 'green') #在坐标轴上绘制样本点,颜色为绿色
plt.plot(X , model.predict(X), color ='red') #在坐标轴上绘制回归直线,颜色为为红色
plt.xlabel('Size/m^2') #横坐标的标签
plt.ylabel('Price/w') #纵坐标的标签
plt.show() #显示所有打开的图形,即打开一个窗口显示图片
总结
该程序主要是使用pandas库读取数据集表格文件,读取出房产样本数据后,使用Sklearn库中的回归算法建立模型文件,将房产样本数据传入后训练生成符合房产数据集的线性回归模型。我们使用预先定义好的线性回归模型就可以不用从头开始实现数学公式,可以快速的帮助我们解决线性回归问题,只需要关注训练后的模型是否符合自己的目标。
2.深度学习及神经网络
2.1 深度学习
深度学习是通过预先处理大量的标记数据,找到其内在规律和表示层次。典型的深度学习模型就是神经网络,神经网络中最基本的组成是神经元模型。
在生物神经网络中,每个神经元与与其他神经元相连,神经元之间的联系通过外部的激励信号做变化,每个神经元有可以接受多个激励信号从而呈现兴奋和抑制的状态,所以人脑在处理各种信息的结果是由各个神经元状态决定的。如下图所示,一个神经元接受到的外部电信号,可以呈现出兴奋和抑制两种状态。

2.1.1 人工神经元
人工神经元是根据生物神经元模拟出来的模型,在这个模型中,神经元可以接受n个从其他神经元传递过来的输入信号,输入信号通过带权重ω连接到神经元,将神经元的总输入值与阈值θ 进行比较,最后通过激活函数处理输出

其中x_i为输入信号, ω_i为神经元连接权重, ∑为输入的总信号和, θ为阈值, y为激活函数。如果要使下一个神经元接受到信号,则接收到的各个信号一定要大于某一个阈值θ才能输出信号 ,该阈值有神经元本身决定。
2.1.2 激活函数
激活函数(Activation Function)是一种在人工神经网络中的函数,旨在帮助网络学习数据中的复杂模式。
在神经元中,输入的input经过一系列加权求和后作用于另一个函数,这个函数就是这里的激活函数。
下图中为一个神经单元,该单元先不考虑阈值,展示一个神经元可以使用不同的激活函数来实现不同的任务。

疑问:为什么这里的神经元阈值消失了?
答:神经网络中的阈值函数,一般也可称为激活函数。
可以先理解为把阈值和激活函数捆绑在一起称为一个函数。
神经网络中的激活函数就是为了增加非线性,激活函数选择了一个阈值,即当大于某个值就被激活,小于等于则输出0。其实这么做也符合人类直觉,对于脑细胞而言,应该也是存在某个阈值,该细胞就会被激活,或者变得敏感。
下面以一个阶跃函数为例,这个函数可以理解为:当输入没有超过阈值点时,所有的输出都为0。当输入大于阈值点是,就输出为5。

下面展示一个简单的激活函数,该激活函数称为Sigmoid函数,它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1。

可以从上图看到, Sigmoid激活函数可以将输入的所有实数压缩在[0,1]范围内。所以Sigmoid函数也可以理解为压缩激活函数。
下面假设一个神经元使用Sigmoid激活函数的示意图。

神经元计算过程为:
1.输入数据x_1 、x_2 、…、x_n进行求和操作,得到net值。
2.将net值传输Sigmoid激活函数,计算得到y值。
3.将y值作为神经元的输出。
2.1.3 实现人工神经元模型
我们已经学习了一个拥有sigmod激活函数的神经元的结构及组成,那么下面我们编写一个python程序,使用numpy库实现一个神经元模型。该模型结构如下所示,该神经元接受10个输入信号x,权重w,偏置b。

程序流程图

python代码实现:
import numpy as np #导入numpy库
def sigmoid(x):
return 1 / (1 + np.exp(-x)) #实现sigmod函数公式
class Neuron:
def __init__(self, weights, bias):
self.weights = weights #各输入的权重值
self.bias = bias #偏置值
def forward(self, inputs):
# 对输入进行加权求和,并增加偏置
total = np.dot(self.weights, inputs) + self.bias
return sigmoid(total) #返回sigmod激活函数输出的结果
x = np.array([1, 2, 3, 4, 5, 6, 7, 8, 9, 10]) #输入数据
weights = np.array([0.9, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.1, 0]) #权重参数
bias = 2 #偏置值
n = Neuron(weights, bias) #传入权重和偏置值
print(n.forward(x)) #打印神经元模型输出结果
2.2 感知机
2.2.1 感知机模型
感知机(Perceptron)是一种简单的二元线性分类器,简单的来说就是可以将两个简单的样本进行分类。它和我们提到的神经元模型类似,也是由两层神经元组成,感知机也是通过输入层接受外界信号或其他神经元传递的信号,传递给输出层,输出层就是我们一开始介绍的M-P神经元(人工神经元)。
如下图所示,下图为一个接受两个输入信号的,输出一个信号的感知机。

感知机和人工神经元一样可以接受多个输入信号,输出一个信号。但是对于感知机来说,输出的信号只会是0或1。
感知机与含Sigmoid激活函数的神经元不同的是,感知机使用的激活函数是符号(sign)函数,如下所示:

如果对于接受两个输入信号的,输出一个信号的感知机来说,激活函数可以为:

其中ω_1, ω_2为权重值; x_1, x_1为输入信号;b为偏置值;f(x)为输出信号。
**注意:**增加偏置这个参数,可以提高神经网络的拟合能力,提升模型的精度,网络的自由度更大。
2.2.2 鸢尾花二分类问题
二分类问题可能是应用最广泛的机器学习问题,它指的是所有数据的标签就只有两种,正面或者负面。
现在我们使用感知机算法来处理一个经典的鸢尾花分类问题,在一个鸢尾花数据集中有两种鸢尾花,分别是山鸢尾和变色鸢尾,如下图所示:

那么现在准备山鸢尾和变色鸢尾的数据集,数据集中保存了两种鸢尾花的Sepal(萼片)长度/宽度和Petal(花瓣)长度宽度。下面以萼片长度为横坐标X,花瓣长度为纵坐标Y,绘制两种鸢尾花数据样本在坐标系中的表示,如图所示:

上图中红色样本代表山鸢尾样本,蓝色样本代表变色鸢尾样本。那么现在我就想找到一条直线可以划分红色样本点(负样本)和蓝色样本点(正样本),这就是一个二分类问题。
2.2.3 实现感知机模型
假设直线函数为y=ωx+b,现在我们要找到合适的ω和b值,获得可以将正负样本完全区分开来的直线函数。我们通过感知机模型找到模型中的权重和偏置值从而找到该直线函数的ω和b值。下面我们设计python程序实现感知机模型,程序框图如下所示:

python程序代码:
1.导入依赖库,如numpy、pandas、matplotlib等;
2.使用pandas库读取鸢尾花数据集 ;
3.获得数据集中获得萼片长度和花瓣长度作为输入数据X。
4.以萼片长度为x横坐标,花瓣长度为y纵坐标,在坐标系上绘制鸢尾花数据集样本点。

5.获得鸢尾花数据集中的类别名,将类别名为山鸢尾设置为-1,将类别名为变色鸢尾设置为1。
6.创建感知机模型传入学习率和迭代次数。
7.拟合感知机模型,获得权重和偏置。
8.绘制迭代过程中分类错误的变化。

9.在坐标系中绘制分类直线函数。

在开始代码解析前我们需要先对权重更新和偏置更新进行说明,下面为权重和偏置的更新公式。
权重更新公式:
w
=
w
+
α
(
y
i
−
h
θ
(
x
i
)
)
x
j
i
偏置更新公式:
b
=
b
+
α
(
y
i
−
h
θ
(
x
i
)
)
权重更新公式:w=w + \alpha (y^i-h_\theta(x^i))x_j^i\\ 偏置更新公式:b = b + \alpha(y^i-h_\theta(x^i))
权重更新公式:w=w+α(yi−hθ(xi))xji偏置更新公式:b=b+α(yi−hθ(xi))
假设我们分类目标分别是正类(1)和负类(0),假设我们使用感知机进行分类时,假设原来的某点的正确类别是正类,y=1,算法将它判断为负类,即y=0,如下图所示:

可以看到上图中的蓝色样本点分类错误了,以这个蓝色点为例我们就可以知道,该点的:
x
1
w
1
+
x
2
w
2
+
b
<
0
x_1w_1+x_2w_2+b<0
x1w1+x2w2+b<0
感知机输出的值为0,所以才会将蓝色点分为负类(0),蓝色点正确的类别是正类(1),那么我们进行更新应该是将权重和偏置增加使得其感知机输出的值大于0才能正确分类。所以我们就有
w
=
w
+
α
(
y
i
−
h
θ
(
x
i
)
)
x
j
i
w=w + \alpha (y^i-h_\theta(x^i))x_j^i\\
w=w+α(yi−hθ(xi))xji
更新后的权重,使得像原来的分类错误的负值向正值走。
下面我们来详细解析感知机解决鸢尾花二分类代码。
# 导入依赖库
import numpy as np
import pandas as pd
from matplotlib import pyplot as plt
# 创建感知机对象
class Perceptron(object):
#启动学习速率和迭代次数。
def __init__(self, Learn_Rate=0.5, Iterations=10):
self.learn_rate = Learn_Rate #学习率
self.Iterations = Iterations #迭代次数
self.errors = []
self.weights = np.zeros(1 + x.shape[1]) #初始化偏置和权重 [0,0,0]
# 确定模型训练的拟合方法。
def fit(self, x, y):
self.weights = np.zeros(1 + x.shape[1]) #获得初始化权重
for i in range(self.Iterations): #循环迭代
error = 0
#xi:输入参数
#target:真实值
#zip(x, y)将可迭代的对象作为参数,将对象中对应的元素打包成一个个元组,然后返回由这些元组组成的对象,这样做的好处是节约了不少的内存。
for xi, target in zip(x, y):
loss = (target - self.predict(xi)) # 计算差值=(真实值-预测值)
self.weights[1:] += self.learn_rate * loss * xi #更新权重
self.weights[0] += self.learn_rate * loss #更新偏置
error += int(self.learn_rate * loss != 0) #记录分类错误数
self.errors.append(error) #向error列表末尾添加元素
print("echo:{},error:{}".format(i,error))
return self.weights[1:],self.weights[0]
# 网络输入法,用于将给定的矩阵输入及其相应的权重相加
def net_input(self, x):
return np.dot(x, self.weights[1:]) + self.weights[0]
# 预测数据输入分类的预测方法
def predict(self, x):
return np.where(self.net_input(x) >= 0.0, 1, 0) #相当于感知机的激活函数
# 数据检索和准备
print("Loading dataset...")
y = pd.read_csv("./iris.data", header=None) #读取鸢尾花数据集
#数据集变量:萼片长度、萼片宽度、花瓣长度、花瓣宽度、类别名
x = y.iloc[0:100, [0, 2]].values #获得萼片长度和花瓣长度
plt.scatter(x[:50, 0], x[:50, 1], color='red',label ="Iris-setosa") #绘制山鸢尾样本点
plt.scatter(x[50:100, 0], x[50:100, 1], color='blue', label = "Iris-versicolor") #绘制变色鸢尾样本点
plt.xlabel('sepal_length') #增加x轴标签
plt.ylabel('petal_length') #增加y轴标签
plt.legend() #给图像加图例,将样本点和直线的标签值增加到图像中
print("Load dataset Succeed!!!")
plt.show() #显示所有打开的图形,即打开一个窗口显示图片
y = y.iloc[0:100, 4].values #获得鸢尾花的类别名
y = np.where(y == 'Iris-setosa', 0, 1) #当y等于Iris-setosa成立时where方法返回-1,当条件不成立时where返回1
# 模型训练和评估
Classifier = Perceptron(Learn_Rate=0.01, Iterations=10) #创建感知机模型传入学习率和迭代次数
print("Start fitting network...")
w,b = Classifier.fit(x, y) #拟合模型
print("fitting network succeed!!!")
print("weights:{},b:{}".format(w,b))
plt.plot(range(1, len(Classifier.errors) + 1), Classifier.errors, marker='o') #绘制迭代过程中分类错误数变化
plt.xlabel('Epochs')
plt.ylabel('Number of misclassifications')
plt.show()
#绘制分类直线函数
plt.scatter(x[:50, 0], x[:50, 1], color='red',label ="Iris-setosa") #绘制山鸢尾样本点
plt.scatter(x[50:100, 0], x[50:100, 1], color='blue', label = "Iris-versicolor") #绘制变色鸢尾样本点
plt.plot(x[:, 0], (w[0]*x[:, 0] + b)/(-w[1]),color='green') #绘制分类直线 w0*x0+w1*x1+b=0 => x1=(w0*x0+b)/(w1)
plt.xlabel('sepal_length') #增加x轴标签
plt.ylabel('sepal_width') #增加y轴标签
plt.legend()
plt.show()
2.3 多层神经网络
2.3.1 XOR问题
在学习多层神经网络前,我们为什么要学习多层神经网络?

单层单节点神经网络可以去拟合一条直线y=ax+b,可分别求解线性回归问题和二分类线性可分问题。
如果求解的问题,不能通过一条直线就去解决,那么单层单节点神经网络就不适用了。例如经典的XOR问题:
假设需要对下面红蓝样本点进行分类,红蓝样本数据的分布如下所示:

通过观察上图可以发现,我们无法通过如上一小节一样建立感知机模型,绘制一条直线将上图中的红蓝样本数据进行分类。由于无论分类直线位于哪个位置,都无法解决此种分类问题。如下所示:

那么我们该如何解决这种XOR问题(异或问题)?我们需要引入拟合能力更强的多层神经网络,去解决一些非线性的问题,可以使用多层感知机来解决此类问题(组合多个简单函数,从而实现更复杂的任务)。
下面展示建立怎么样的多层感知机模型,我们先将红蓝样本以坐标系中象限的方式划分红蓝样本:

我们可以发现红色样本点在第1象限和第3象限中,蓝色样本点在第2象限和第4象限中,那么可知红色样本的x值和y值相乘结果为正,蓝色样本的x值和y值相乘结果为负。那么我们可以设计如下多层感知机模型。

绿色的感知机分类器,主要是判断样本是位于y轴的正区间还是负区间。
紫色的感知机分类器,主要是判断样本是位于x轴的正区间还是负区间。
从上面这两个感知机分类器中获得分类器结果后,对比两个结果是否一致,一致为正样本,不一致为负样本。
将预测结果为正的类,分类为正样本;将预测结果为负的类,分类为负样本。

通过上图可以看到,红色样本点2和3的结果都是正,蓝色样本点1和4的结果都是负。那么就可以说明我们使用多层神经网络就可以解决XOR问题。
2.3.2 多层网络组成
多层神经网络是含中间层的人工神经网络。那么什么是中间层呢?下面以一个两层输入层,一个输出层的神经网络展示:

如上图所示,在输入层和输出层有一个中间层网络,下面分别介绍各个在这个网络结构中的作用:
输入层:将数据输入到网络中,不做处理直接输入隐含层。
隐含层(隐层):对输入层输出的数据进行求和操作,并使用激活函数对输入总数据进行操作。
输出层:将隐含层输出的数据进行求和操作,求和后直接输出。
注意:在多层神经网络中,输出层可以包含激活函数也可以不包含激活函数。
常见的多层神经网络下图所示,每层神经元与下一层完全相连,神经元之间不允许同层相连,也不允许跨层相连,也可以称为全连接神经网络。

多层神经网络采用一种单向多层结构。其中每一层包含若干个神经元。在此种神经网络中,各神经元可以接收前一层神经元的信号,并产生输出到下一层。第0层叫输入层,最后一层叫输出层,其他中间层叫做隐含层(或隐藏层、隐层)。隐层可以是一层,也可以是多层。
2.4 参数的传播方向
当我们知道这些神经元的构成后,我们还需要知道参数是如何传播的?传播方向是什么样的?我们应该怎么去更新对应的权重值?
我们训练的意义就是为了找到合适的权重值等参数,所以参数传播的方向是十分重要的。
参数的传播方向:前向传播、反向传播

2.5 前向传播和反向传播
前向传播是指在神经网络中沿着输入层到输出层的顺序,将上一层的输出作为下一层的输入,并计算下一层的输出,依次计算到输出层为止。这里举一个简单的例子,便于大家理解。假设输入信号有x_1,x_2,x_3。神经网络结构如下图所示:

通过上图可以看出节点f_1 (x)与输入信号x_1,x_2,x_3 相连,节点f_5 (x)和f_6 (x)分别与节点f_1 (x)、 f_2 (x) 、f_3 (x)、 f_4 (x)相连。
输入数据x_1,x_2,x_3的通过隐含层节点后f_1 (x)…f_6 (x),最后到输出层y_1输出。
反向传播算法也称为误差逆传播算法(error BackPropagation),简称BP算法**。现在很多神经网络都用BP算法,特别多用于多层前反馈神经网络,所以一般BP网络则是指BP算法的**多层前反馈神经网络。
假定数据集为D={(x_1,x_2 ) ,(x_3,x_4),…,(x_n,x_n+1)} ,这里我以最简单的模型举例,以1层输入层,1层隐含层h_1,h_2,1层输出层y_1,激活函数a_1,a_2,a_3 。在前面我们已经对神经网络有了初步了解,输入层是不对输入的信号进行处理的,只有隐含层和输出层有激活函数,输出激活值。
在前面我们已经对神经网络有了初步了解,输入层是不对输入的信号进行处理的,只有隐含层和输出层有激活函数,输出激活值。

对于隐含层:

对于输出层:

上述过程就为正向传播,我们这里使用平方差损失函数衡量预测结果,对于误差值有:

通过梯度下降法和链式法则,求解梯度。
对于输出层,求解梯度值:

更新权重值和偏置值为:


对于隐含层

更新权重和偏置值为:

对于隐含层其他的也是类似的,这里就不举例了。
所谓反向传播就是将正向传播计算的结果,反向传回给初始化参数,从而改变权重值,再次训练后再查看预期值是否符合预期结果,如果不符合则继续改变权重,直至获得的权重训练的结果满足预期目标。
反向传播的步骤如下:
1.初始化权重ω和偏置值b等初始化参数
2.正向传播,计算每个神经元的输出
3.通过损失函数计算误差值
4.通过梯度下降法和链式法则求解每个神经元的梯度
5.更新网络参数。
通过上述步骤可以看出,反向传播的作用主要是更新权重,使训练拟合的模型性能更加优秀。
2.6 损失函数
前面我们讨论了我们需要通过训练不断去更新权重值,那么这里就有一个问题,我们如何去判断我们得到的权重是符合我们数据的网络要求的?
这里就需要引入一个判断标准,去判断我们更新的网络模型可以正确的预测目标。
这个判断标准叫做损失函数,损失函数是度量模型的预测值f(x)与真实值Y的差异程度的运算函数,它是一个非负实值函数,通常使用L(Y, f(x))来表示,损失函数越小,模型的鲁棒性就越好。可以用来评价模型的预测值和真实值不一样的程度。

通过损失函数计算出来的值叫做损失值,损失值是预测值和真实值的差值。损失值越小,通常模型的性能越好。如上图所示,我们经过不断迭代,就是为了找出损失值的最低点。
由于不同的模型也需要不同的损失函数。常用的损失函数有绝对值误差, 平方差、log对数损失函数等。
下面展示一下常见的两种损失函数,绝对值误差损失函数、log对数损失函数的函数图像。

下面介绍什么是绝对值误差函数?它是基于y轴对称的函数,其表达式为:

它描述了目标值和预测值的差值的绝对值之和,表示预测值的平均误差程度,且不考虑方向问题。
假设现在以求解线性回归问题(求解样本点趋势线)为例,我们通过预测得到的某一样本点为(1,2),实际的样本点为(1,4)。
L
1
=
∣
4
−
2
∣
=
2
L_1=|4-2 |=2
L1=∣4−2∣=2
上述公式是求解一个样本点的绝对值误差,即(实际值的平方-预测值的平方)的绝对值。
L
=
(
L
1
+
L
2
+
…
+
L
n
)
/
n
L=(L_1+L_2+…+L_n)/n
L=(L1+L2+…+Ln)/n
将所有的预测样本点和实际的样本点进行上述操作获取绝对值误差,并将所有的绝对值误差进行求和操作后再除以样本点总数,即可获取总绝对值误差。
3.深度学习框架Pytorch入门
3.1 深度学习框架简介
什么是深度学习框架?
在深度学习初始阶段,每个深度学习研究者都需要写大量的重复代码。为了提高工作效率,这些研究者就将这些代码写成了一个框架放到网上让所有研究者一起使用。接着,网上就出现了不同的框架。随着时间的推移,最为好用的几个框架被大量的人使用从而流行了起来。
深度学习框架是一种界面、库或工具,它使我们在无需深入了解底层算法的细节的情况下,能够更容易、更快速地构建深度学习模型。深度学习框架利用预先构建和优化好的组件集合定义模型,为模型的实现提供了一种清晰而简洁的方法。深度学习框图如下所示:

下面举两个例子来解释深度学习框架。
例子1:深度学习框架就是库,目前市面上有很多不同牌子的库,库里面就一套积木。这套积木里面包含很多组件,如:模型、算法等。也就是说这些积木已经把底层的数学公式帮你实现了,你无需从零开始实现数学公式的复杂运算,只需要关心怎么设计积木搭建城建符合你数据集的积木。目前就有很多牌子的积木,如Pytorch、TensorFlow、Caffe等。
这套积木里面包含:预定义模型、反向传播算法、梯度下降等预先定义的函数,供开发者可以自由搭建成符合自己数据集的神经网络。

例子2:假设数据集就是食材,我们需要对食材进行加工,需要用到锅、铲子、刀等厨具。这里我们就需要去选择不同品牌的厨具,当然我们厨具里面有很多工具,你只需要自己搭配厨具使用,不需要从头开始磨刀/炼钢(不需要从零开始实现数学公式)。假设你要做的菜是糖醋排骨,那么不同牌子提供的厨具套装里面,都可以实现你这道菜,那可以使用Pytorch牌厨具套装做成,你也可以使用TensorFlow牌厨具套装做成。

为什么要使用深度学习框架?
因为使用深度学习框架可以降低入门的门槛,你可以不用从复杂的神经网络开始编写代码,也不需要去手动实现梯度下降、前向传播、反向传播等,你可以依据预先定义好的模型的基础上增加自己的模型、搭建自己的网络层、选择自己需要的分类器。简而言之,使用深度学习框架这个库就是加快搭建神经网络的速度,直接使用其预先定义好的API,即可实现自己的神经网络模型的搭建。

深度学习框架对比

3.2 深度学习框架-pytorch
由于Pytorch的生态建设较好同时底层细节较好,下面主要使用Pytorch来对深度学习框架进行讲解快速入门程序。打开Pytorch网址:https://pytorch.org/

打开官方Pytorch快速入门的链接:https://pytorch.org/tutorials/beginner/basics/quickstart_tutorial.html

3.3 求解服饰图像多分类问题
3.3.1 多分类问题介绍
快速入门程序是求解多分类问题,从网上下载的FashionMNIST数据集,该数据集包含黑白图像有:
t-shirt(T恤),trouser(牛仔裤),pullover(套衫),dress(裙子),coat(外套),sandal(凉鞋),shirt(衬衫),sneaker(运动鞋),bag(包),ankle boot(短靴)。
多分类问题目的是:建立一个模型可以实现下面图像的分类。

3.3.2 程序流程框图
程序流程图如下所示:

3.3.3 程序源码解析
程序源码解析:
1.引入pytorch包
import torch #引入pytorch包,该包中包含tensor(多维矩阵)的数据结构以及对应的数学运算
from torch import nn #引入pytorch中的nn包,该包预先定义网络层,例如卷积层、池化层、激活函数及损失函数等。
from torch.utils.data import DataLoader #该包主要用于加载数据集和对数据集进行划分。
from torchvision import datasets #该包主要用于引入数据集模块,该模块中包预定义有常见的数据集,同时可用于构建自定义的数据集。
from torchvision.transforms import ToTensor #该包主要用于将PIL图像或者numpy中N维数组类型的对象 转换为 tensor ,并且支持缩放对应值。
2.下载训练数据集
# Download training data from open datasets.下载训练数据集
training_data = datasets.FashionMNIST(
root=“data”, #数据集存放路径,当前目录下的data文件夹下
train=True, #表示该数据集为训练数据集
download=True, #是否需要网络下载
transform=ToTensor(), #将下载的数据集快速切换为pytorch可使用的tensor(多维矩阵)
)

3.下载测试数据集
# Download test data from open datasets.
test_data = datasets.FashionMNIST(
root="data", #数据集存放路径,当前目录下的data文件夹下
train=False, #表示该数据集为测试数据集
download=True, #是否需要网络下载
transform=ToTensor(), #将下载的数据集快速切换为pytorch可使用的tensor(多维矩阵)
)

4.加载数据集
batch_size = 64 #设置批次大小(批次:每次读取的数量)
# Create data loaders.
train_dataloader = DataLoader(training_data, batch_size=batch_size) #加载训练集
test_dataloader = DataLoader(test_data, batch_size=batch_size) #加载测试集
#每次以迭代器的方式返回一批64个数据和标签。
for X, y in test_dataloader:
print(f"Shape of X [N, C, H, W]: {X.shape}") #X为转换后的tensor数据
print(f"Shape of y: {y.shape} {y.dtype}") # y为标签, y.dtype表示数据元素的数据类型
break
X [N, C, H, W]: batchsize,channel,height,weight。batchsize是我们设置的批次大小64,也就是一次取64张图像;channel为1表示通道数,灰度图为1,彩色图为3;高度和宽度则是单张图像的大小28*28像素。
5.指定加载设备
# Get cpu, gpu or mps device for training.
device = (
“cuda”
if torch.cuda.is_available() #判断系统是否支持CUDA
else “mps”
if torch.backends.mps.is_available() #判断系统是否支持MPS
else "cpu"
)
print(f"Using {device} device")
CUDA 是 NVIDIA 发明的一种并行计算平台和编程模型。它通过利用图形处理器 (GPU) 的处理能力,可大幅提升计算性能。
多进程服务(MPS)是另一种二进制兼容的实现CUDA应用程序编程接口,透明地支持协作式多进程CUDA应用程序
6.定义模型
创建pytorch模型,为了定义一个模型,创建一个从nn.Module继承的类,在NeuralNetwork类中使用__init__函数定义了网络层,使用forward函数定义指定数据如何通过网络。
# Define model
class NeuralNetwork(nn.Module):
def __init__(self):
super().__init__()
self.flatten = nn.Flatten()
self.linear_relu_stack = nn.Sequential(
nn.Linear(28*28, 512),
nn.ReLU(),
nn.Linear(512, 512),
nn.ReLU(),
nn.Linear(512, 10)
)
#参数传播方向:前向传播
def forward(self, x):
x = self.flatten(x)
logits = self.linear_relu_stack(x)
return logits
model = NeuralNetwork().to(device)
print(model)
nn.Flatten():将连续的维度范围展平为张量。
nn.Sequential:有序容器,神经网络模块将按照在传入构造器的顺序依次被添加到计算图中执行,同时以神经网络模块为元素的有序字典也可以作为传入参数。

6.1 Linear层研究
Linear是线性层;ReLU是激活函数。Linear的函数定义为:
torch.nn.Linear(
in_features, #每次输入的样本大小
out_features, #每次输出的样本大小
bias=True, #如果设置为False,该层附加偏置。默认值:True
device=None,
dtype=None
)
Linear线性层是将输入执行一次线性变换,函数定义为:
y
=
x
A
T
+
b
y=xA^T+b
y=xAT+b
其中x为输入,A^T 为权重,A^T为A的转置矩阵,b为偏置.
import torch
from torch import nn
model = nn.Linear(2,1) #输入特征数为2,输出特征数为1
print(model)
input = torch.Tensor([[100,200],[300,400]]) #输入一个2×2的矩阵
print(input)
print(input.size())
output = model(input)
print(output)
print(output.size())
for param in model.parameters():
print(param)
该段程序的运行结果:
Linear(in_features=2, out_features=1, bias=True)
tensor([[100., 200.], [300., 400.]])
torch.Size([2, 2])
tensor([[47.2638], [99.8806]], grad_fn=<AddmmBackward0>)
torch.Size([2, 1])
Parameter containing:
tensor([[0.0527, 0.2103]], requires_grad=True)
Parameter containing:
tensor([-0.0788], requires_grad=True)
其中model是通过torch.nn创建的线性层模块,input是通过torch.Tensor创建的2×2矩阵, output是input矩阵通过线性层后的结果矩阵。
由打印信息可知,创建的model函数输入特征数为2,输出特征数为1。偏置设置为True,即使用偏置值。输入矩阵input为[(100&200@300&400)],输出矩阵output为[(47.2638@99.8806)],权重矩阵A为[8(0.0527&0.2103)],偏置值为-[0.0788]
Linear层数学推导:

其中b原本为-[0.0788],由于广播机制,变换为b=[(-0.0788@-0.0788)]
最后计算的y值为[(47.2512@99.8512)],与程序计算出来的[(47.2638@99.8806)]
是存在一定的误差,这就是计算机利用二进制表示小数,在进行矩阵运算时,尾数存储时会出现舍入的情况,类似于我们小时候学习的四舍五入,舍入的情况会导致二进制的保存值大于真实值或小于真实值,这就会导致计算机在计算浮点数产生误差的原因。
7.损失函数和优化器
为了训练模型,还需要增加一个损失函数和一个优化器对象,优化器对象可以保存当前状态,并根据计算出的梯度更新参数。损失函数使用交叉熵损失函数,优化器使用的是torch.optim.SGD随机梯度下降。
loss_fn = nn.CrossEntropyLoss() #损失函数使用交叉熵损失函数
optimizer = torch.optim.SGD(model.parameters(), lr=1e-3) #神经网络优化器,主要是为了优化我们的神经网络,使他在我们的训练过程中快起来,节省神经网络训练的时间。
交叉熵损失函数是用来衡量目标值和预测值之间的差距,在深度学习中常用于解决多分类问题。

随机梯度下降用于在反向传播中更新模型中的梯度值。梯度值如图中红色箭头所示。
torch.optim.SGD()是随机梯度下降函数,传入的参数为:保存有权重和偏置的参数量model.parameters(), 学习率lr。梯度下降一般分为批量梯度下降和随机梯度下降,其中批量梯度下降是在更新参数时使用所有样本来更新梯度,随机梯度是在求解梯度时没有使用全部的样本,而是仅随机选取一个样本来求解梯度。
批量梯度下降:

随机梯度下降:

如何理解上述两个公式:
1.批量梯度下降:每次都要计算所有实际样本与预测样本的误差值。
2.随机梯度下降:每次随机选取一个实际样本与预测样本计算误差值。

8.定义训练函数
在训练循环中,模型对训练的数据集进行预测,使用反向传播预测误差并更新模型的参数,同时根据测试数据集检查模型的性能确保训练的方向正确。
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) #数据集的长度
model.train() #设置模型为训练模式
for batch, (X, y) in enumerate(dataloader):
X, y = X.to(device), y.to(device) #指定数据加载到指定设备中
# Compute prediction error
pred = model(X) #利用模型求解预测值
loss = loss_fn(pred, y) #求解预测值和真实值的损失函数
# Backpropagation
loss.backward() #反向传播计算当前梯度
optimizer.step() #根据梯度更新网络参数
optimizer.zero_grad() #梯度清零
if batch % 100 == 0:
# loss.item()是提取损失值的高精度值, (batch + 1) * len(X) 是计算当前训练的数据位置
loss, current = loss.item(), (batch + 1) * len(X)
print(f"loss: {loss:>7f} [{current:>5d}/{size:>5d}]")
9.定义测试函数
测试函数中不去反向计算梯度,只使用模型去求解预测损失值,并且计算其模型损失值和精度。
def test(dataloader, model, loss_fn):
size = len(dataloader.dataset) #数据集的长度
num_batches = len(dataloader) #批次大小
model.eval() #设置模型为测试模式
test_loss, correct = 0, 0
with torch.no_grad(): #不计算反向梯度
for X, y in dataloader:
X, y = X.to(device), y.to(device) #指定数据加载到指定设备中
pred = model(X) #利用模型求解预测值
test_loss += loss_fn(pred, y).item() #计算模型损失
correct += (pred.argmax(1) == y).type(torch.float).sum().item() #计算模型精度
test_loss /= num_batches
correct /= size
print(f"Test Error: \n Accuracy: {(100*correct):>0.1f}%, Avg loss: {test_loss:>8f} \n")
10.训练模型
我们设置的迭代次数为5次,每调用训练模型的函数一次,就调用测试模型函数去测试模型的精度和损失值。当迭代完成五次后,保存迭代后的模型文件为‘model.pth’
epochs = 5 #设置迭代次数
for t in range(epochs):
print(f“Epoch {t+1}\n-------------------------------”)
train(train_dataloader, model, loss_fn, optimizer) #调用训练模型函数
test(test_dataloader, model, loss_fn) #调用测试模型函数
print("Done!")
通过上述运行结果可以发现在不断的迭代后,精度在不断提升,损失在不断下降。这说明外面对模型的优化方式是可行的。
torch.save(model.state_dict(), “model.pth”) #保存模型,保存为当前目录中的model.pth
print("Saved PyTorch Model State to model.pth")
模型训练过程示意图

11.Pytorch使用训练好的模型进行测试
加载刚刚训练完成的模型文件,将模型设置为测试模式,使用模型加载测试集中的图像,返回的结果与真实值比较,查看是否一致。
model = NeuralNetwork().to(device)
model.load_state_dict(torch.load("model.pth"))
classes = [
“T-shirt/top”,
“Trouser”,
“Pullover”,
“Dress”,
“Coat”,
“Sandal”,
“Shirt”,
“Sneaker”,
“Bag”,
“Ankle boot”,
]
model.eval() #设置模型为测试模式
x, y = test_data[0][0], test_data[0][1] #设置测试数据和标签值
with torch.no_grad():
x = x.to(device) #指定数据加载到指定设备中
pred = model(x) # #利用模型求解预测值
predicted, actual = classes[pred[0].argmax(0)], classes[y] #查看预测值和真实值
print(f'Predicted: "{predicted}", Actual: "{actual}"')
Pytorch训练测试模型完整流程示意图

4.基础算子及卷积神经网络
4.1 基础算子
函数的定义域为一个数集,值域也为一个数集,即函数是数值到数值的映射。
泛函的定义域为函数集,值域为是实数集,即泛函是函数到数值的映射。
算子的定义域为函数集,值域为函数集,即算子是函数到函数的映射。
在深度学习是由一个个计算单元组成的,这些计算单元我们称为算子(Operator),**算子在神经网络中表示对应层的计算逻辑。**例如:在深度学习中对tensor(矩阵)的操作,如线性运算,加权求和等数学函数计算。
对于激活函数,如sigmoid函数、符合函数等,我们称为用作激活函数的算子。
下面演示一些基础的算子,帮助理解算子是什么?
例如微分算子,是使函数y处理变成y^′,其表达式为:
D
(
y
)
=
y
′
D(y)=y^′
D(y)=y′
这表示对函数y求了一次导,同理可以将D(y)微分算子再求一次导:
D
(
D
(
y
)
)
=
y
′
′
D(D(y))=y^′′
D(D(y))=y′′
由此归纳总结出:
D
n
(
y
)
=
y
(
(
n
)
)
D^n (y)=y^((n))
Dn(y)=y((n))
其中n表示对函数y求导了n次。

下面以求和算子进行举例说明算子在神经网络中是如何运用的,在之前我们学习到了神经元会接收n个输入x_i,进行一些数学运算,再产生一个输出y。

如上图所示,求和算子就是接收n个输入后,将每个输入乘以其权值后相加,相加后的值为总输入,将总输入作为参数X传给激活函数,公式为:X=∑_(i=1)^n[x_1+x_2+…+x_n ],经过激活函数输出Y。
4.2 卷积神经网络
神经网络有许多算子构成的网络框架,典型的神经网络如下图的卷积神经网络,其中至少有一层是由卷积算子构成的网络

卷积神经网络(Convolutional Neural Networks)是人工神经网络的一种特殊类型,在其至少一层中使用称为卷积的数学运算代替通用矩阵乘法。它们专门设计用于处理像素数据,并用于图像识别和处理。

一个卷积神经网络主要由以下5层组成:
•数据输入层/ Input layer
•卷积计算层/ CONV layer
•池化层 / Pooling layer
•ReLU激励层 / ReLU layer
•全连接层 / FC layer
4.3 卷积算子
4.3.1 为什么需要卷积?
在机器学习中输入都是以高维数据为主,在之前我们使用简单的线性学习器,如下图所示:

上述是各个维度线性可分的情况,我们可以通过简单的直线或者将样本进行分类。但如果样本的分布出现如下图所示的情况,样本变成了线性不可分了。

下图可以看出来在2维中我们不能使用一条直线将红蓝样本分类,但我们还是想两个样本进行分类,所以我们将样本映射到3维上,如上图中3维所示,原本在2维上不可分的样本,在3维就可以使用一个平面将样本分开,所以我们通过一个映射函数将样本从n维映射到n+1维或者更高维度,使得原本线性不可分的问题变成线性可分,以解决样本分类。

所以我们为了去求解分类问题,我们如何去升维呢?
假设H为特征空间,如果存在一个从低维空间X和高维空间H的映射,映射过程记为∅(x),则有:

使得对所有的x,y∈X,函数K(x,y)满足条件

其中函数K(x,y)被称为核函数,∅(x)称为x的映射函数,∅(y)称为y的映射函数,∅(x)∙∅(y)是∅(x)和∅(y)的内积。

将原始空间中的向量作为输入向量,并返回特征空间(转换后的数据空间,可能是高维)中向量的点积的函数称为核函数。
核函数就是为了找到样本的分割函数而产生的能使样本从低维空间映射到高维空间,使得原本在低维空间中不可分的数据在高维中可分。

4.3.2 图像卷积
对于图像的卷积,则输入是二维的图像I,核函数为K,因为m,n的取值范围相对较小,在许多神经网络库中还会实现一个互相关函数为:

在许多机器学习库中的互相关函数也称为卷积。所以我们知道卷积过程就是图像乘核函数。
卷积完成后可以在高维空间将图像中的像素样本变成可分的,即提取特征值。

卷积层(conv)是使用卷积核(核函数)来提取图像的特征信息并将其输入到神经网络中,我们可以通过重复的卷积操作来获得图像的在不同层次的特征,从而减少源图像中各种噪声的污染。如图所示,卷积中运算过程由二维数字矩阵卷积核对原图像进行卷积,具体步骤为:
1.在图像的某个位置覆盖卷积核;
2.将卷积核中的值与图像中的对应像素矩阵的值相乘;
3.将步骤2的乘积结果相加,得到的和为输出图像中的目标像素值;
4.对图像的全部位置重复上述操作。

4.3.3 卷积与互相关
我们从上一小节学习到图像的卷积过程就是源图像与核函数对应像素值相乘,并将乘积结果进行累加。可以发现其实这个操作直观上来看更像加权求和的感觉,那么为什么叫做卷积呢?目前图像卷积是根据卷积的思想而来的相关运算,所以在神经网络中会实现互相关函数。
那么这里的**“互”**是谁和谁相关呢?我们以3×3的卷积核来看,原图像经过一个卷积核之后,输出一个值,那么这个值就是源图像中“中间像素”与周围一圈像素的关系。也就是说,卷积核帮助我们找这两者的关系,分别为两种:另一种是周围像素对中间像素的关系影响;另一种是中间像素与周围像素的关系影响。所以卷积实际上是分为两种操作,分别是:
- 考虑周围像素如何对当前中间像素点产生影响的。
- 当前中间像素点对周围像素的试探和选择。

4.3.4 卷积处理图像
那么下面我们来看看哪一种是我们前面用于提取特征值的操作。
周围像素对中间像素的影响:我们以图像模糊为例,带大家了解周围像素如何对中间像素产生影响的。我们使用OpenCV库的实现一个简单的均值模糊。
#导入opencv模块
import cv2 as cv
#读取当前目录图像,支持 bmp、jpg、png、tiff 等常用格式
img = cv.imread("test.jpg")
#创建一个input窗口用于显示图像
cv.namedWindow("input")
#在input窗口中展示输入图像
cv.imshow("input",img)
#图像均值模糊处理,使用3*3的卷积核处理,处理结果图像存储在blur
blur = cv.blur(img, (3,3), 0)
#创建一个Output窗口用于显示图像
cv.namedWindow("Output")
#在Output窗口中展示输入图像
cv.imshow("Output",blur)
#创建的窗口持续显示,直至按下键盘中任意键
cv.waitKey(0)
#释放窗口
cv.destroyAllWindows()
输入和经过均值模糊处理后的图像,如下所示:

可以通过两张图片看出来,经过均值模糊后的图像与原图像对比更加模糊了,减小了噪声。那么这个均值模糊也是和我们前面说的一样,原图像经过一个卷积核进行处理,处理后的图像输出即为卷积后的图像。下面我们来看一下均值模糊是如何实现这一个模糊过程的。
我们这里就不以公式的角度理解均值模糊,我们根据图像像素值的角度来看。首先我们需要清楚,图像模糊的本质是处理图像中与周围差异较大的点,将其像素值调整为与周围点像素值近似的值。
均值模糊:每一个像素点都取周边像素的平均值后,如果中间值大于平均值,就降低中间值;如果中间值小于平均值,就升高中间值。在数值上就表现出平滑的效果,在图像中就表现为模糊的效果。

如果用坐标的形式表示中间像素和周围像素,可如下所示:

所以程序中均值模糊中的卷积操作是:
1.在图像的某个位置覆盖卷积核,归一化卷积核为
k
=
1
9
∣
1
1
1
1
1
1
1
1
1
∣
k =\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|
k=91
111111111
2.将卷积核中的值与图像中的对应像素矩阵的值相乘;
3.将步骤2的乘积结果相加,得到的值为输出图像中的目标像素值;
4.对图像的全部位置重复上述操作。
那么下面我们通过放大输入图像和经过均值模糊的输出图像,来看一下均值模糊的计算过程。

我们通过上图知道输入图像黄色框中的RGB值和输出图像黄色框中的RGB值,两个黄色框是图像中的同一位置。计算过程如下:
-
为更好的展示过程,我们单独计算RGB通道,那么卷积核覆盖位置的原图像RGB值分别为:
R = ∣ 146 132 118 130 119 112 124 115 111 ∣ , G = ∣ 75 60 49 59 47 43 53 43 42 ∣ , B = ∣ 57 45 33 41 32 27 35 28 26 ∣ R=\left|\begin{matrix} 146 & 132 & 118\\ 130 & 119 & 112\\ 124 & 115 & 111\\ \end{matrix} \right|,G=\left|\begin{matrix} 75 & 60 & 49\\ 59 & 47 & 43\\ 53 & 43 & 42\\ \end{matrix} \right|,B=\left|\begin{matrix} 57 & 45 & 33\\ 41 & 32 & 27\\ 35 & 28 & 26\\ \end{matrix} \right| R= 146130124132119115118112111 ,G= 755953604743494342 ,B= 574135453228332726 -
将RGB三通道的值分别与卷积核k相乘
R 1 = R ∗ k = ∣ 146 132 118 130 119 112 124 115 111 ∣ ∗ 1 9 ∣ 1 1 1 1 1 1 1 1 1 ∣ = 1 9 ∣ 146 132 118 130 119 112 124 115 111 ∣ , G 1 = G ∗ k = ∣ 75 60 49 59 47 43 53 43 42 ∣ ∗ 1 9 ∣ 1 1 1 1 1 1 1 1 1 ∣ = 1 9 ∣ 75 60 49 59 47 43 53 43 42 ∣ , B 1 = B ∗ k = ∣ 57 45 33 41 32 27 35 28 26 ∣ ∗ 1 9 ∣ 1 1 1 1 1 1 1 1 1 ∣ = 1 9 ∣ 57 45 33 41 32 27 35 28 26 ∣ R_1=R*k=\left|\begin{matrix} 146 & 132 & 118\\ 130 & 119 & 112\\ 124 & 115 & 111\\ \end{matrix} \right|*\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|=\frac{1}{9}\left|\begin{matrix} 146 & 132 & 118\\ 130 & 119 & 112\\ 124 & 115 & 111\\ \end{matrix} \right|, \\G_1=G*k=\left|\begin{matrix} 75 & 60 & 49\\ 59 & 47 & 43\\ 53 & 43 & 42\\ \end{matrix} \right|*\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|=\frac{1}{9}\left|\begin{matrix} 75 & 60 & 49\\ 59 & 47 & 43\\ 53 & 43 & 42\\ \end{matrix} \right|, \\B_1=B*k=\left|\begin{matrix} 57 & 45 & 33\\ 41 & 32 & 27\\ 35 & 28 & 26\\ \end{matrix} \right|*\frac{1}{9}\left|\begin{matrix} 1 & 1 & 1\\ 1 & 1 & 1\\ 1 & 1 & 1\\ \end{matrix} \right|=\frac{1}{9}\left|\begin{matrix} 57 & 45 & 33\\ 41 & 32 & 27\\ 35 & 28 & 26\\ \end{matrix} \right| R1=R∗k= 146130124132119115118112111 ∗91 111111111 =91 146130124132119115118112111 ,G1=G∗k= 755953604743494342 ∗91 111111111 =91 755953604743494342 ,B1=B∗k= 574135453228332726 ∗91 111111111 =91 574135453228332726
- 再将乘积结果相加,得到的值为输出图像中的目标像素值
R 2 = 1 9 ( 146 + 132 + 118 + 130 + 119 + 112 + 124 + 115 + 111 ) = 123 G 2 = 1 9 ( 75 + 60 + 49 + 59 + 47 + 43 + 53 + 43 + 42 ) = 52 B 2 = 1 9 ( 57 + 45 + 33 + 41 + 32 + 27 + 35 + 28 + 26 ) = 36 R_2=\frac{1}{9}(146+132+118+130+119+112+124+115+111)=123\\ G_2=\frac{1}{9}(75+60+49+59+47+43+53+43+42)=52\\ B_2=\frac{1}{9}(57+45+33+41+32+27+35+28+26)=36 R2=91(146+132+118+130+119+112+124+115+111)=123G2=91(75+60+49+59+47+43+53+43+42)=52B2=91(57+45+33+41+32+27+35+28+26)=36
- 目标像素RGB值为:
R G B = ∣ 123 52 36 ∣ RGB=\left|\begin{matrix} 123\\ 52\\ 36\\ \end{matrix} \right| RGB= 1235236
我们对比图像中显示的RGB和我们计算出来的一致。所以卷积在图像处理中操作可以用于考虑周围像素对中间像素的影响,根据周围像素的值来计算计算中间像素的值,从而实现图像模糊的效果,降低图像噪点。
4.3.5 卷积提取图像特征
前面我们学习了考虑周围像素对中间像素的影响的卷积可以去实现一些对图像的处理,那么卷积又是如何实现特征提取的呢?
以下示例来源国外作者Charles Crouspeyre的《卷积神经网络是如何工作的?》
假设我现在需要识别下面黑白图像中的是X还是O,由于图像中的X和O处于不同位置,如果通过我们人眼是可以判断出对应图像里的是X和O的。

如果电脑去判断两张X图像,其中X的位置不同,如果使用传统的方法比较图像中的元素值,可以电脑就可以得出,两张图像不一致,且无法判断图像中有X。

所以我们需要使用卷积神经网络来对这些图像处理,就可以知道传入的图像是X还是O,那么卷积神经网络中的卷积是如何处理这些图像的?
在开始前我们先观察这两张图像中有哪些相同特征,我们可以看到他们两个有些局部特征是相同的,如下图中红黄蓝框所示:

可以看到这些局部特征是有相似的,下面根据这些局部特征,我们创建三个3*3的卷积核,如下所示:

可以看到这个特征可以和图像X中特征对应上,如下图所示:

那么现在我使用第一个卷积核来进行卷积操作,计算如下图中绿框位置,卷积后的值输出在下图中右边黄色框中。

继续使用与上图相同的卷积核,计算下图中绿框位置,卷积后的结果输出在下图中右边黄色框中。

计算完成后得到卷积后的图像矩阵图下图所示:

我们可以看到一个现象,经过这个卷积核之后会,卷积结果图像得到的特征是一条从左上到右下的对角线,他与图像中X的从左到右向下的对角线相匹配,所以我们可以看到在结果图像中所有高的值,都在这条对角线上,这条对角线与卷积核的匹配比其他地方与卷积核的匹配的匹配更好。
那么下面我们分别来看三个卷积核后的卷积结果,如下图所示:



用中间的X卷积核和从斜向上的卷积核,经过卷积后得到特征出现的位置和我们期望的特征是一致的,也就是说可以提取到原图像中X的特征值。那么在神经网络中使用一堆卷积核对图像进行处理并提取特征,这就称为卷积层。

通过上图我们又可以看出一个规律,假设输入图像为X,卷积核为w,偏置为b,那么卷积输出的结果为Y,则有:
Y
=
X
⋆
w
+
b
,其中
⋆
为卷积操作
Y=X\star w + b,其中\star为卷积操作
Y=X⋆w+b,其中⋆为卷积操作
上述式子中卷积核W和偏置b是可学习的参数,即:可通过训练改变的参数。
4.3.6 一维卷积和二维卷积
我们已经知道卷积的作用,那么如何使用pytorch深度学习框架来实现卷积操作?
一维卷积实现
下面是使用pytorch实现的一个例子,展示一维的tensor经过一维卷积后的结果矩阵。
import torch
from torch import nn
#设置卷积函数,输入通道为1,输出通道为1,核函数大小为3,步长为3,偏置为0
conv1 = nn.Conv1d(in_channels=1,out_channels=1,kernel_size=3,stride=3,bias=0)
input = torch.Tensor([[1,2,3,4,5,6,7,8,9]])
print(input)
nn.init.constant_(conv1.weight, 1)#核函数参数设置为1
print(conv1)
output = conv1(input)
print(output)
输出结果:
输出信息为:
tensor([[1., 2., 3., 4., 5., 6., 7., 8., 9.]])
Conv1d(1, 1, kernel_size=(3,), stride=(3,), bias=False)
tensor([[ 6., 15., 24.]], grad_fn=<SqueezeBackward1>)

二维卷积实现
下面是使用pytorch实现的一个例子,展示二维的tensor经过二维卷积后的结果矩阵。
import torch
from torch import nn
#设置卷积函数,输入通道为1,输出通道为1,核函数大小为3,步长为1,偏置为0
conv2 = nn.Conv2d(in_channels=1,out_channels=1,kernel_size=3,stride=1,bias=0)
input = torch.Tensor([[[1,1,0,0,1,1],[0,0,1,0,1,0],[0,1,1,1,0,0],[0,1,0,0,1,1],[1,0,1,1,0,0],[1,1,1,0,0,1]]])
print(input)
nn.init.constant_(conv2.weight, 1)#核函数参数设置为1
print(conv2)
output = conv2(input)
print(output)
输出结果:
tensor([[[1., 1., 0., 0., 1., 1.],
[0., 0., 1., 0., 1., 0.],
[0., 1., 1., 1., 0., 0.],
[0., 1., 0., 0., 1., 1.],
[1., 0., 1., 1., 0., 0.],
[1., 1., 1., 0., 0., 1.]]])
Conv2d(1, 1, kernel_size=(3, 3), stride=(1, 1), bias=False)
tensor([[[5., 5., 5., 4.],
[4., 5., 5., 4.],
[5., 6., 5., 4.],
[6., 5., 4., 4.]]], grad_fn=<SqueezeBackward1>)
二维卷积实现过程

4.4 池化层
4.4.1 最大池化与均值池化
池化层(pooling)又称为下采样层,池化层的卷积核只是对应位置的最大值和平均值。池化与卷积操作不同主要表现在矩阵运算规律的差异。其主要功能是保持特征不变性,包括平移、旋转和尺度。利用池化进行特征降维,降低了卷积层对冗余信息的敏感性,提取了重要特征值。
池化层的每一次操作都是对输入图像数据,利用一个固定形状窗口中的元素的计算输出,其中该运算有最大池化和平均池化。
最大池化是在二维中的最大池化,窗口从输入数组的左上角开始,按照从左到右和从上到下的顺序向下滑动。当最大池化窗口滑动到某个位置时,窗口中输入子数组的最大值是输出数组中相应位置的元素。
均值池化是池化特征图的局部感受,当池化平均窗口滑动到某个位置并返回其集合平均时,窗口中输入子数组的平均值是输出数组中相应位置的元素。池化操作过程如图所示。


4.4.2 卷积网络中的最大池化
我们回到3.3.5中的例子,我们已经经过卷积之后提取到原图像中X的特征值,如下图所示:

那么下面我们对着卷积提取的特征图像进行最大池化(Max Pooling)操作,如下图所示:

可以看到经过最大池化后我们得到了一个更小的图像,但是图像中仍然保存这卷积提取的特征值在特征图像的对角线上。也就是我们将原本7*7的特征图像,降维为4*4的特征图像,大小只有原来的一半。
小思考:如果我们的图像比较大,分辨率比较高,那么卷积操作提取特征之后,图像尺寸还是很大,那么这很不利于我们部署在一些嵌入式设备中,这种图像像素缩小,还能保存特征的方式是十分有用的。
如果你想寻找图像中的特征,它可能会向左一点或者向右一点,或者旋转一点,但特征依然可以被提取,可以对所有的经过卷积的图像进行最大池化,可获得卷积之后的更小的特征图像。


4.5 RELU 激励层
4.5.1 线性整流激活函数
RELU激励层,也称非线性激活层。 RELU激励层使用线性整流激活函数,该函数可以保留大于0的值,即保留特征比较好的值,将特征小于0的值舍去。
下面展示线性整流函数(Rectified Linear Unit)的函数公式:

relu函数图像为:

ReLU激活函数的主要优点是:
•卷积层和深度学习:它们是卷积层和深度学习模型训练中最常用的激活函数,可以使网络有非线性表达,增加网络拟合能力。
•计算简单:整流函数实现起来很简单,只需要一个max()函数。
•代表性稀疏性:整流器函数的一个重要优点是它能够输出一个真正的零值。
4.5.2 卷积网络中的RELU层
RELU函数由于其导数在正区间且恒为1,可以避免梯度的随着网络层数的增加而消失的问题,所以我们在网络层的任意位置都可以使用它作为激活函数。我们回到4.3.5中的例子,我们已经经过卷积之后提取到原图像中X的特征值,我们对卷积提取的特征值使用RELU激活函数处理,如下图所示:

通过上图我们看到RELU激活函数就是遍历图像中的所有负值的像素,将所有负值都变为0。当经过一次激活函数后会得到一个原来十分相似的图像。对所有图像都经过RELU激活函数处理后,即为RELU层

下面我们将卷积层、RELU层、池化层叠加使用,可得到如下所示结构:

我们用过上图了解到,图像输入卷积后,输出的卷积结果,传给RELU层进行处理,RELU层输出的结果,传给Pooling层进行池化操作,最后输出。多层网络的规律就是一个层的输出作为下一个层的输入。那么下面我们再次对网络进行堆叠,建立更多层的卷积层、RELU层、池化层,如下所示,对网络层进行深度堆叠。

当然,如果您的图像尺寸比较大,你还可以进行堆叠,堆叠成一个更多层的网络。每次图像经过卷积层之后都会获得特征图像,随着卷积层和池化层的层数增加,特征图像也会变得越来越小。
4.6 全连接层
4.6.1 全连接层核心公式
全连接层(full connection)是把每个结点连接到上层的所有结点,以合成从前端层提取的特征,并接受图片特征值的输入,进行训练,训练完成后就可对输入的特征值进行分类。
全连接的核心公式为:
f
(
x
)
=
W
∙
x
+
b
f(x)=W∙x+b
f(x)=W∙x+b
其中:x为全连接层的输入矩阵,W为权重系数,b为偏置。
4.6.2 卷积网络中的全连接层
在卷积神经网络中,经过了卷积层、RELU层、池化层的特征提取后,最后一层网络需要使用到全连接层。以4.5.2中经过深度堆叠后的特征图像,经过全连接过程如下所示:

将现在经过多次过滤且尺寸大大减小的图像特征,分解出来并重新排列,放入一个列表中,对结果进行计算。可以把全连接形象的理解为,特征值中的每一个值就是一个人,原来特征值是排成方阵形式的,现在将他们一个一个拎出来,排成一排。让每一个人去对类别X和O进行投票,每个人都可以对X和O进行投票。
当我们输入图像含X时,每一个人为类别X的获得更多的票数,也就是说他们更倾向于这张图像是X图像。
当我们输入图像含O时,每一个人为类别O的获得更多的票数,也就是说他们更倾向于这张图像是O图像。
如果我们通过训练得到了全连接中合适的权重和偏置,如果我们的网络得到了一个新的输入图像,那么此时就会根据卷积池化RELU得到的结果,再次进行投票,如下所示:

我们再次对X和O进行投票,最终我们可以通过观察那个票数高,来判断输入的图像是X还是O。
当然,我们也可以像卷积、池化、RELU一样,可以叠加很多层,类似于下图所示:

所以我们的卷积神经网络可以设计成下图这样,经过卷积、池化、RELU后经过两层的全连接层,最终投票输出X和O的概率。

4.6.3 分布式特征映射
全连接层利用分布式特征表示将特征值映射到样本标记空间中,具体步骤简图如下所示:
(全连接层是把特征表示整合到一起,输出为一个值)
假设下面以一个检测人脸和猫的网络的简图,其中就演示了全连接神经网络,就是特征整合成一个值,这个值越大就证明检测的图像中有人脸或有猫,不论其在图像中的位置。

全连接层在整个网络中起到“分类器”的作用。如果说卷积层、池化层和激活函数等操作是将原始数据映射到隐层特征空间的话(特征提取+选择的过程),全连接层则起到将学到的特征表示映射到样本的标记空间的作用。换句话说,就是把特征整合到一起(高度提纯特征),方便交给最后的分类器或者回归。
4.7 训练与超参数
我们了解了卷积神经网络中的卷积层、池化层、全连接层,下面我们来看他们在整个卷积神经网络中的作用。

前面我们讨论了卷积神经网络中的卷积、池化、RELU、全连接是如何提取特征,并把特征输出出来。这就需要有合适的权重和偏置值等需要通过训练找到合适参数。那么训练是如何更新参数的呢?这里就需要用到前面我们学习了的反向传播算法,反向传播就是利用全连接层最后输出的预测结果,计算误差来确定网络的调整和变化程度。
E
r
r
o
r
=
(
p
r
e
d
i
c
t
v
a
l
u
e
)
−
(
a
c
t
u
a
l
v
a
l
u
e
)
误差
=
(
预测值
)
−
(
真实值
)
Error = (predict\quad value) -(actual\quad value)\\ 误差 = (预测值) - (真实值)
Error=(predictvalue)−(actualvalue)误差=(预测值)−(真实值)
例如,我们如果得到的3.6.3中的预测概率X和O分别是0.93和0.35,我们已知正确值X和O应为1和0,那么我们就有以下表格:
| predict value | actual value | Error | |
|---|---|---|---|
| X | 0.93 | 1 | 0.07 |
| O | 0.35 | 0 | 0.35 |
| Total | 0.42 |
使用梯度下降法获得最低误差,如下所示:

在不断训练中去调整卷积核、全连接权重等参数,看看误差如何变化,调整的量取决于有多大的误差;误差越大调整越大,误差越小调整的越小。就像小球在山上找下山的路一样,小球想沿着这个斜坡走下去,也就是沿着梯度找到最底部,因为最底部是误差最小的时候。
超参数是在网络开始学习过程之前设置值的参数,我们来看一下卷积神经网络中的超参数有哪些:
-
卷积层Convolution
- 卷积核的数量
- 卷积核大小
-
池化层Pooling
- 池化窗口尺寸
- 池化步长
-
全连接层Fully Connected
- 隐藏层神经元数量
下面展示一个卷积神经网络的交互式节点连接可视化网站:https://adamharley.com/nn_vis/

5.模型及部署
5.1 模型
我们有了网络结构,那么这里就需要继续引入一个概念 模型 。
什么是模型?在人工智能中,模型本质就是一个函数。而这个函数是通过我们大量的数据给到机器中,机器通过不断的迭代找出一个满足我们提供的数据的函数,可以根据这个函数去预测新数据所对应的结果。通过上面介绍的几种基本的算法,就是在数据的基础上创建机器学习的模型的过程。

模型=参数+架构+算法。
参数是什么?在上文我们已经提及,我们在神经网络中从输入层传输到隐含层的权重、偏置都算是参数,这就是模型中可训练的参数。

架构是什么?创建了两个不同架构的神经网络,相同的数据集使用不同的架构也会产生不同的预测函数,所以架构也构成模型的重要组成。

算法是什么?我们创建的模型里存储的目标函数,那么怎么去求解该目标函数的方法就称为算法。就例如在解决机器学习过程中的损失函数的求解就有:最小二乘法、牛顿法、阻尼牛顿法等。激活函数的选择:Sigmoid函数、双曲正切激活函数、ReLU激活函数等。这些就是需要选择符合你数据集的的算法。

5.2 模型的部署
模型的部署分为云端部署和边缘部署。
云端部署主要是在中心服务器中训练的引擎库,边缘部署是在主机设备中进行数据的处理和模型推理,生成模型后打包进SDK包中,编译后集成到嵌入式设备里。
在前几年的时候,嵌入式设备只能利用CPU执行简单的AI任务或者将数据发送到云端服务器,使用云端服务器接收到申请后,将数据使用服务器端的模型进行推理,推理结果返回给嵌入式设备进行进一步处理。
随着芯片技术的发展,嵌入式设备的算力增加使得可以将模型部署到嵌入式设备中,不需要将数据发送到云端来运行模型;嵌入式设备采集数据,直接运行模型进行推理,再将推理结果返回用作某项任务的一部分。采集的数据也可暂时存储到设备中,后者发送到云端进行存储。
嵌入式AI中数据的采集和分析推理都在本地,可以降低数据传输的成本和保证数据的安全以及推理决策的实时性。所以为了保证实时性我们的模型需要在指定设备中推理运行。
6.边缘部署
6.1 部署硬件GPU/FPGA/ASIC
随着人工智能的发展,21世纪开始,对算力的需求也越来越高。人工智能的体系分为基础层,技术层和应用层,其中最底层的就是基础层的算法处理芯片,需要使用它来提高最基础的算力,传统通用CPU处理器算力不足,主要来源于GPU/FPGA/ASIC等AI芯片所提供的算力,下面我们就针对这三种不同的AI芯片进行讨论。
6.1.1 图形处理单元GPU
**图形处理单元(GPU)**其实是从中央处理器(CPU)演变而来的,原本是专为3D图形渲染的并行计算而设计的。在计算机早期,CPU是需要负责图形应用程序所需要的计算的,例如渲染2D和3D图像,动画视频等,但随着图形密集型应用程序的增多,给CPU带来了很多压力,导致整个计算机的性能下降,为了帮助CPU减轻压力,把图像相关的应用程序转移出来,所以GPU就应运而生,专门用于快速并行的执行图形相关的计算。
GPU通常包括多个处理器,每个处理器有一个共享内存,外加多个处理器和对应的寄存器,支持大规模并行处理,每个内核都专注于高效计算。CPU可以认为是整个系统的监工,协调通用的计算任务,而GPU执行的是更专业的任务(通常为数学任务)。CPU和GPU的架构简图如下所示:

注意:越靠近核心的缓存速度越快
在一些嵌入式设备中也有独立的GPU,也可以流畅的渲染3D图形和视频,例如手机,机顶盒。广告机等设备,GPU可以快速的在显示屏上呈现内容。现代GPU已经适应比最初设计的图形任务范围更广的任务,因为目前GPU比过去更具有编程性,目前GPU还能用于机器学习/训练深度学习神经网络/图像识别/视频游戏/视频编辑内容创造等工作。下面我们来展示GPU是如何工作的,为什么GPU可以加速图形和神经网络任务?
在学习GPU如何工作前,我们需要知道并行计算是什么?并行计算是一种计算类型,其中特定的计算被分解成可以同时执行的独立的较小的计算,最后将计算结果重新组合或者同步。也就是说将原来一个比较大的运算任务分解成多个任务进行运算,任务的数量取决于核心的数,在硬件核心上的单元就是GPU中的处理器单元,在GPU中通常有数千个核心进行运算。

如果计算可以支持并行计算的任务,我们就可以使用并行编程方法和GPU加速我们的计算。
下面我们以GPU渲染3D模型为例,3D模型可以可以由许多小三角形组成,如下图所示:

你可以想象一下,如果想让这个兔子像视频一样变得能动,那么就需要为每个小三角形的三个角的坐标值进行计算,假设每个角都使用X,Y,Z坐标来表示,如下图所示制作三角形来组成模型就需要制作三个顶点的坐标值,当然如果你的模型是由一个个正方形组成亦是如此,可能是由四个顶点组成。我们这一小节主要针对三角形构成的模型进行讨论,三角形的三个顶点可以在各个三角形之间共享,那么如果你的模型有1000个三角形,那么可能就不需要3000个顶点来组成模型。

回到我们的一开始说的,如果我们需要让这个兔子动起来,我们就需要将这一个个三角形进行平移/旋转/缩放等操作,这些操作统称为变换。
在现实3D图形中,使用数学的方式表达XYZ坐标的最佳方式就是使用向量的方式进行表达,如果想对向量进行变换操作,最简单的方式就是使用矩阵运算的方式,将原来的坐标乘一个3*3的矩阵,例如:

你可以看到矩阵的每行都有不同的属性值,你只需要使用特定的预先定义好的矩阵进行相乘后即可对这个小三角形进行平移/缩放/旋转等操作,所以要使得能很轻易的让那么多个小三角形进行变换,那么GPU需要十分擅长矩阵运算,并且支持大量的矩阵运算。

从上图中,我们看到我们需要将这些矩阵数据加载到内存中,加载后,GPU会同时访问内存并运输大量的矩阵块数据。核心在处理当前矩阵块数据时,它从系统内存中获取了更多的块,所以GPU永远不会空闲。GPU获取了一块矩阵块后会交给GPU计算完成完成还需要使用着色器对每个小三角形都填充颜色,当然这个由GPU渲染器来完成的。

如果对于是大矩阵的运算,GPU则会取一部分一部分的取出大矩阵的数据进行计算,我们就以两个大矩阵相乘的例子来看GPU是如何进行计算优化的。假设存在两个4*4的矩阵A和B,将矩阵A和矩阵B相乘,乘积结果使用C进行保存。如下所示:

我们可以将这个4*4矩阵分块,拆分成2*2的块矩阵,那么乘积结果C就等于两个2*2的块矩阵相乘,最终计算出矩阵块的乘积结果。我们就重点来看C矩阵是如何在GPU上实现并行计算的。我们就3个核心的GPU为例,如下图所示:

我们先来计算C11的块矩阵元素,我们可以将子矩阵块A11,B11从L2缓存中取出,放到L1缓存中,SM-1核心对获取的数据进行运算,将乘积结果放到共享内存SMEM中,将A12和A21从L2缓存中取出,放到L1缓存中,SM核心对获取的数据进行运算,将乘积结果放到共享内存中。最后从共享内存中取出两个乘积结果进行求和就可以得出完整C11。同时我们可以使用其他SM核心并行的计算这些子矩阵块,最终计算完矩阵中的不同的块矩阵的数据,从而得到整个C矩阵的数据。
我们用更多的内存带宽将数据块从系统内存提取到GPU中的缓存中,使用多处理器来并行的处理。那么对于大矩阵块的乘法,我们就需要知道一些超参数,也就是我们怎么每次取的块大小是多少?需要使用多少个核心进行处理,以及使用哪一个核心进行处理?

CUDA就可以负责确定这些超参数,同时如果我们需要使用GPU对我们的矩阵运算进行加速,使用CUDA即可完成。
CUDA是 NVIDIA 专为图形处理单元 (GPU) 上的通用计算开发的并行计算平台和编程模型。借助 CUDA,开发者能够利用 GPU 的强大性能显著加速计算应用。
在经 GPU 加速的应用中,工作负载的串行部分在 CPU 上运行,且 CPU 已针对单线程性能进行优化,而应用的计算密集型部分则以并行方式在数千个 GPU 核心上运行。使用 CUDA 时,开发者使用主流语言(如 C、C++、Fortran、Python 和 MATLAB)进行编程,并通过扩展程序以几个基本关键字的形式来表示并行性。
那么回到我们的问题为什么在深度学习中我们经常需要使用GPU设备呢?
因为在神经网络中进行的许多计算可以很轻易的分解为多个彼此独立的较小计算任务。例如我们前面学习的卷积运算:

我们通过前面学习的卷积过程就可以知道,我们每次运算都是独立于其他计算的,所以我们可以发现每次卷积计算都不会依赖其他计算的结果,因此所有这些独立的卷积计算都可以在GPU上并行的运算,并且整个输出通道可以在整个计算完成后生成,所以我们就可以使用并行计算方法在GPU上加速卷积运算。

6.1.2 现场可编程门阵列FPGA
现场可编程门阵列 (FPGA) 是一种半导体集成电路,它基于通过可编程 互连 连接的可配置逻辑块 (CLB) 矩阵。FPGA 可以在制造后根据所需的应用或功能要求进行重新编程。FPGA中芯片的逻辑单元是可以通过编程的方式改变,同时逻辑单元的连接也是可以改变的。
FPGA的基本结构包括可编程输入输出单元,可配置逻辑块,数字时钟管理模块,嵌入式块RAM,布线资源,内嵌专用硬核,底层内嵌功能单元。编程语言有VHDL/Verilog等。
下面我以一个简单的神经网络为例,带大家来看FPGA上是如何加速神经网络的,如下图所示:

下面根据这个神经网络中来设计一个逻辑电路,那么我们先编写一个框图,展示神经网络的参数,如下所示

可以看到我们主要是实现隐藏层和输出层的四个神经元,那么我们来看如果FPGA中如何实现单个神经元的逻辑电路如下所示:

对于一个神经元,我们有三个输入信号x_1,x_2,x_3,输入信号的的权重w_1,w_2,w_3,对它们两个进行相乘;将乘积结果相加起来,并且加上偏置值。将最终的输入信号和传入ROM中,我们在ROM(只读存储器)中存储了sigmoid激活函数,经过ROM中的激活函数处理后输出最终的值。我们就根据原来的神经元模型在FPGA上使用VHDL设计对应的逻辑电路。那么对于神经网络,FPGA的逻辑电路就可以设计成这样,我们将神经网络的结构映射成硬件的结构。如下图所示:

下面我们来看一下FPGA的优缺点。
优点:
-
加速深度学习推理: FPGA可以通过硬件加速深度学习推理任务,提高模型的性能和效率。深度学习模型通常需要大量的计算资源,FPGA的并行计算能力使其成为加速推理任务的理想选择。
-
**灵活性和可编程性:**FPGA具有可编程性,允许用户根据特定需求设计和实现定制化的硬件加速器。这种灵活性使得FPGA适用于各种不同的人工智能应用,包括图像识别、语音处理和自然语言处理等。
-
低功耗: 相对于传统的通用处理器,FPGA通常具有较低的功耗。这对于在嵌入式系统和移动设备等资源受限的环境中使用人工智能技术是非常重要的。
-
实时处理: FPGA可以提供实时性能,适用于需要即时响应的应用,如自动驾驶、智能摄像头和物联网设备等。
-
加速算法和模型优化: 利用FPGA的并行性和硬件加速能力,可以对人工智能算法和模型进行优化,加速训练和推理过程,提高整体性能。
缺点:
-
复杂性: FPGA的设计和编程相对复杂,需要专业的硬件设计和编程技能。
-
成本: FPGA通常相对昂贵,尤其是高性能和大规模的FPGA。这可能成为一些项目和应用采用FPGA的障碍,尤其是在预算受限的情况下。
-
功耗波动: 虽然相对于某些通用处理器,FPGA具有较低的功耗,但在某些情况下,由于FPGA的可编程性和灵活性,其功耗可能难以精确估计,导致功耗波动。
-
相对固定的硬件资源: FPGA的硬件资源是有限的,并且通常是相对固定的。这可能导致在处理某些大规模或复杂的人工智能任务时,资源不足的问题。
-
**编译使用:**工具链的质量参差不齐,一次编译的时间较长。
6.1.3 专用集成电路ASIC
专用集成电路是为特定任务或应用定制设计的集成电路 (IC)。与FPGA板不同,FPGA板在制造后可以进行编程以满足各种用例要求,而ASIC设计是在设计过程的早期进行定制的,以满足特定需求。两种主要的ASIC设计方法是门阵列和全定制。ASIC由IC设计人员根据特定的电路需求,设计专用的逻辑电路,在设计完成后生成设计网表,交给芯片制造厂家流片。在流片之后,内部逻辑电路就固定了,芯片的功能也就固定的。通常ASIC芯片可用于通信(通信芯片)/汽车电子(电机芯片)/航天航空(导航/飞行控制芯片)等。
在深度学习领域,ASIC专门针对深度学习任务的集成电路被称为硬件加速器,可提高深度神经网络的推理和训练速度,并在相同时间内降低功耗。深度学习ASIC的电路结构和功能经过专门优化,以满足深度学习任务的计算需求。这种硬件优化可以提供高度并行计算、特定网络架构的支持以及其他深度学习运算的硬件加速。
ASIC中最有标志性的就是Google TPU,它是由谷歌设计的专用硬件加速器,用于机器学习和深度学习任务。TPU的设计目标是提供高性能和高效能的硬件,以加速谷歌云平台上的机器学习工作负载。并且其对TensorFlow框架具有很好的兼容性,使得在TensorFlow上训练和部署模型时能够充分发挥TPU的性能优势。
目前国内外在做ASIC的厂商有:国外的谷歌/英伟达/英特尔/AMD等,国内的华为/全志/瑞芯微/地平线/寒武纪/嘉楠/比特大陆/芯原等。
在深度学习的ASIC设计中,一些硬件加速器采用了类似于脉动阵列(systolic array)的结构,以实现高度并行的计算。它就是利用多个小型计算核心并行执行矩阵乘法等操作,以提高性能。对于这种ASIC的计算单元主要是由计算单元PE阵列组成,通常以规则的二维或三维排列,形成一个紧凑的网格结构。这有助于实现高度的并行计算。如下图所示:

下面我以一个两个矩阵相乘的例子来看,脉动阵列是如何对矩阵运算进行加速的。
C
=
A
∗
B
=
[
a
11
a
12
a
13
a
21
a
22
a
23
a
31
a
32
a
33
]
∗
[
b
11
b
12
b
13
b
21
b
22
b
23
b
31
b
32
b
33
]
C
11
=
a
11
∗
b
11
+
a
12
∗
b
21
+
a
13
∗
b
31
C
12
=
a
11
∗
b
12
+
a
12
∗
b
22
+
a
13
∗
b
32
C
13
=
a
11
∗
b
13
+
a
12
∗
b
23
+
a
13
∗
b
33
.
.
.
C
33
=
a
31
∗
b
13
+
a
32
∗
b
32
+
a
33
∗
b
33
C
=
A
∗
B
=
[
c
11
c
12
c
13
c
21
c
22
c
23
c
31
c
32
c
33
]
C=A*B= \left[\begin{matrix} a_{11} & a_{12} & a_{13} \\ a_{21} & a_{22} & a_{23} \\ a_{31} & a_{32} & a_{33} \\ \end{matrix} \right] * \left[\begin{matrix} b_{11} & b_{12} & b_{13}\\ b_{21} & b_{22} & b_{23} \\ b_{31} & b_{32} & b_{33} \\ \end{matrix} \right] \\ C_{11}= a_{11}* b_{11} + a_{12}*b_{21} + a_{13}*b_{31}\\ C_{12}= a_{11}* b_{12} + a_{12}*b_{22} + a_{13}*b_{32}\\ C_{13}= a_{11}* b_{13} + a_{12}*b_{23} + a_{13}*b_{33}\\ ...\\ C_{33}= a_{31}* b_{13} + a_{32}*b_{32} + a_{33}*b_{33}\\ C=A*B=\left[\begin{matrix} c_{11} & c_{12} & c_{13}\\ c_{21} & c_{22} & c_{23} \\ c_{31} & c_{32} & c_{33} \\ \end{matrix} \right]
C=A∗B=
a11a21a31a12a22a32a13a23a33
∗
b11b21b31b12b22b32b13b23b33
C11=a11∗b11+a12∗b21+a13∗b31C12=a11∗b12+a12∗b22+a13∗b32C13=a11∗b13+a12∗b23+a13∗b33...C33=a31∗b13+a32∗b32+a33∗b33C=A∗B=
c11c21c31c12c22c32c13c23c33
我们先来看我们如果需要进行两个矩阵乘法,需要进行多少次运算,可以看到我们求出一个矩阵C中的一个元素c11需要进行5次乘法和加法运算,矩阵C中总共有9个元素需要求,那么总共需要45次运算。那么如果使用ASIC芯片,并且使用脉动阵列中的计算单元来看一下是如何优化矩阵乘法。如下图所示:


下面我们对上图中的展示上图中脉动阵列的计算流程进行说明:
-
将A矩阵放在计算单元PE阵列中,将B矩阵放在输入的位置。
-
将输入数据往右移一列,将矩阵B的数据传入计算单元PE阵列中,与计算单元中的元素作乘法运算。
-
将输入数据再往右移一列,再次进行矩阵乘法运算。将上一次计算的结果往下移一行,对计算单元的元素进行加法计算。
-
重复将数据往右移计算乘积结果,往下移计算加法结果,直到将所有数据计算完成。
我们可以看到如果使用脉动阵列的方式进行矩阵乘法运算,我们可以快速减少计算步骤和所需时间。我们经过上述方法可以将整个输出矩阵C的结果放到输出里面了。可以看到我们的矩阵A的尺寸和脉动阵列的尺寸是一致的,才能保证进行乘法运算的结果正常运算,那么对于一般的矩阵乘法(尺寸可能和阵列不一致),可以通过分块或者填充来匹配阵列的尺寸大小。
对于sigmod/RELU等激活函数,脉动阵列无法实现的功能,可以使用其他硬件单元来实现。
6.2 嵌入式模型部署
从零到最后嵌入式模型部署流程是准备数据集、数据预处理、数据标注、选择算法、训练、调整参数、生成模型、边缘部署。
①准备数据集包括文本数据、图像数据、音频数据等,图像数据中有包括数字数据集、人脸数据集、人形数据集、道路数据集等。
②数据预处理,主要是为了检查、修正、删除在数据集中不适用于模型的数据。常见的方法是:特征缩放、缺失值处理、异常值处理、数据转换等。
③数据标注,对于图像数据,对目标物体进行画框,导出其在图像中的位置。对于音频数据,对时间轴上标注出音标或者特定词等。
④选择算法,我们需要根据数据集来选择算法如:文本的检测算法、分类算法等;图像的目标检测算法、人脸检测算法、人形检测算法等,音频的语音识别算法、语音合成算法等。
⑤训练后生成模型,评估模型后修改模型或参数,直至模型达到最优的效果。
⑥模型部署,使用AI芯片中的神经网络处理单元进行模型的推理。
6.3 嵌入式AI芯片
目前主流的嵌入式AI芯片做法都是将AI模块嵌入到定制的SOC中,允许芯片架构针对特定的计算应用进行优化。一般都是多个核心放在单个SOC上,现实中很多AI芯片的做法都是多核异构,即采用多个核心,且不同架构。
嘉楠公司的K510含有三核 RISC-V 处理器和KPU通用神经网络引擎;
全志公司的V853含有Arm Cortex-A7@1GHz 、E907@600MHz和NPU神经网络处理器;
英伟达公司的jetson nano含有四核Arm Cortex-A57主核、28核Maxwell架构GPU图形处理单元;
下图为嘉楠K510芯片架构图,可以从红框中为该芯片为CPU+ASIC架构。

下图为全志V853芯片架构图,可以从红框中为该芯片为CPU+ASIC架构。

6.4 边缘部署流程
边缘部署的流程包括模型转换、量化压缩、打包封装。
6.4.1 模型转换
模型转换是由于我们训练和推理的设备不一致,用于连接不同框架的模型。由于目前许多开源算法都要自己的模型格式,主流的做法是将原本的模型转换成onnx或Caffe的格式,再转换成AI芯片所要求的格式。
例如对于yolov5目标检测算法,嘉楠公司的K510的模型格式转换流程为:pt->onnx->kmodel ;
全志公司的V853芯片的模型格式转换流程为:pt->onnx->nbg。
英伟达公司的jetson nano的模型格式转换流程为:pt->onnx->tensorRT 。
其中pt格式是pytorch的模型格式,onnx格式是开放神经网络交换格式,用于表达深度学习的模型标准,可使模型在不同框架之间进行转移。Kmodel格式是嘉楠公司的KPU所用的文件格式。nbg为芯原公司的NPU所用的文件格式。 tensorRT为英伟达公司所用的文件格式。

6.4.2 量化压缩
为了缩小模型,我们常使用量化压缩,它是由于在卷积神经网络中为了追求更好的精度,常会采用浮点float-32,这导致参数量、计算量、占用内存都会变得很大,为了减小模型存储和内存占用、压缩参数、提高速度使得可以部署到资源较少的嵌入式设备中,需要转换成int整型。

减小了模型所占用到的资源,模型的精度也会下降,但如果要使量化后的模型可以落地使用就需要将量化后的精度损失降低到可接受范围内,同时还需要保证部署后的速度、资源占用率和能耗。

非对称模式是不以0为中心点,以所有参数的中间值为中心点,将整个模型中的所有参数等比例映射到0-255范围内。
对称模式是以0为中心点,将整个模型中的所有参数等比例映射到0-255范围内。
参考资料:神经网络量化白皮书
6.4.3 打包封装
打包封装是指将模型文件、模型的前处理和后处理、模型推理等打包供嵌入式设备中的应用程序使用。
在了解前处理和后处理之前,我们来回顾一下模型的输入内容和输出内容。

模型的输入是以声音/图像/文本,进行模型推理后,输出的数据也是由模型本身确定的输出的数据内容,输出内容可以是函数的参数、tensor特征向量、格式化文本。
6.4.4 端侧推理
①前处理是指由于模型的输入是由模型本身确定的,有些会以多维矩阵(Tensor)的数据作为输入,但嵌入式设备采集的数据一般为图像格式、音频格式和文本格式等,如果想将数据推入模型中进行推理需要根据模型的输入要求,将采集数据的格式转换为多维矩阵,或不进行处理直接将数据输入模型。
②模型推理是`指将转换后的多维矩阵在转换成特定格式的模型上运行,输出的多维矩阵可以满足精度、性能等需求。例如英伟达公司的jetson nano转换后的模型使用TensorRT引擎进行推理;嘉楠公司的K510转换后的模型使用nncase框架进行推理。全志公司的V853转换后的模型使用芯原VIPLite引擎进行推理。
③后处理是指将推理后的处理结果(参数/多维矩阵/格式化文本)进行处理或者解码,转化为嵌入式设备输出给外设的图像特征、音频特征或文本特征等。

















 2671
2671

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









