






关于C++的博客C++11?-CSDN博客中提到了内存模型,当时留了很多疑问。
本想借着下面文章,加深理解,发现文中很多概念还是晦涩难懂。
上面链接的本义是解释Linux内核内存模型背后的思想,是为了便于理解。结果发现,对大多数人来说,还是概念太多,还是晦涩难解。下面说说我自己的理解思路,先介绍存储架构和Cache Line和MESI协议,再看内存屏障和内存模型,尽量以例子的方式来帮助理解。
存储架构:
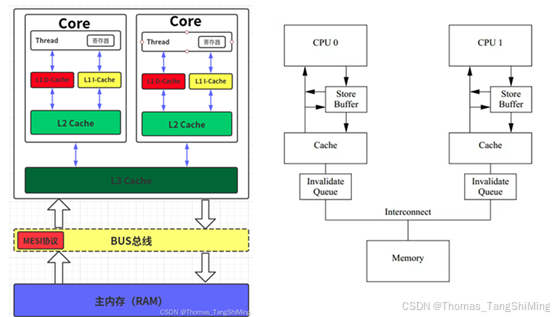
通常,SMP(对称多处理器)系统的架构如下图,每个CPU Core含私有寄存器,有不同级别的缓存(私有的缓存,如下图左边的L1/L2缓存,CPU公有的L3缓存)。写缓冲Store Buffer和无效队列Invalidate Queue是为了优化效率而引入,不是每个CPU架构都有。
Store buffer是CPU和L1 Cache之间的缓存,只缓存CPU的写操作(不管是否cache命中),再由store buffer通过FIFO依次写入L1 Cache。
Invalidate Queue记录来自其他CPU core的缓存无效请求。
以上都属于硬件层面,目的都是提高CPU的处理效率。理解缓存一致性协议,有助于理解Store Buffer和Invalidate Queue的作用。
Cache Line:
要理解缓存Cache,必须要理解Cache Line。理解Cache Line,有助于理解后面的概念。那什么是Cache Line?
Cache通常被分成多个组(set),每个组被分成多个行(Cache Line)。常见的表述如8-way set associative是指,每个组里面有8个Cache Line。CPU要访问一个内存物理地址,就是要求通过物理地址映射到某一个Cache Line。如果是你,要怎么来定义这种映射关系呢?
Cache主要分为两部分,tag部分和Data部分。Cache的Data部分用来保存一片连续内存地址的数据(副本),而Tag部分则是存储这片连续数据的公共地址,一个Tag和所对应的data部分组成的一行称为一个Cache Line。一个Cache Line的大小是固定的(2的N次方,16 ~ 256 byte 不等),Data部分的长度,就是cache操作和cache与主存交换数据的基本单位。
缓存一致性协议:
CPU为了效率,访问私有的缓存;当存在共享变量时,多个CPU的缓存间就存在一个同步问题,就需要一个缓存一致性协议。缓存一致性,指多个CPU看到一个内存地址的数据是否一致,由硬件协议MESI保证Cache一致性。
带你了解缓存一致性协议 MESI (qq.com)详细介绍了如何做到同步的,其实这里的思路适用于所有的同步场景。MESI协议就是以一个CPU节点中的Cache Line可能出现的四种状态命名的。
M : modified,表明数据只在本CPU缓存中,且数据已被修改,此CPU缓存有最新数据。
E : exclusive,表明数据只在本CPU缓存中,且是最新的(内存中也是最新的)。
S : shared,表明数据可能存在多个CPU缓存中,且是最新的(内存中也是最新的)。
I : invalid,表明该数据不在本CPU缓存中(内存中是最新的)。
MESI协议定义了一系列消息机制,在内存和个CPU之间交互,来维护Cache状态,实现数据高效访问。MESI协议消息如下:
- Read。"read" 消息用来获取指定物理地址上的 cache line 数据。
- Read Response。该消息携带了 “read” 消息所请求的数据。read response 可能来自于 memory 或者是其他 CPU cache。
- Invalidate。该消息将其他 CPU cache 中指定的数据设置为失效。该消息携带物理地址,其他 CPU cache 在收到该消息后,必须进行匹配,发现在自己的 cache line 中有该地址的数据,那么就将其从 cache line 中移除,并响应 Invalidate Acknowledge 回应。
- Invalidate Acknowledge。该消息用做回应 Invalidate 消息。
- Read Invalidate。该消息中带有物理地址,用来说明想要读取哪一个 cache line 中的数据。该消息是 read + Invalidate 消息的组合,发送该消息后 cache 期望收到一个 read response 消息。
- Write back。 该消息带有地址和数据,该消息用在 modified 状态的 cache line 被置换时发出,用来将最新的数据写回 memory 或其他下一级 cache 中。
场景1:对于不是共享的数据,处理很简单:
- 当在CPU X上执行时,最初数据未加载到缓存,需要找到一个invalid态的Cache Line;如果缓存满,需要换出(可能回写数据到内存)得到可用的invalid态cache line。
- 如果是读数据请求,载入缓存后,此时该cache line状态为exclusive。
- 如果是写请求,载入缓存后,此时该cache line状态为modified;适当的时候,数据回写到主存。回写后依然缓存有效,cache line状态为exclusive;回写后不再存在缓存中,cache line状态为invalid。
对于多CPU间共享的数据,处理会复杂一点。注意有以下原则:
- 如果某一CPU中的cache line处于shared态,说明在多个CPU的local cache中存在副本,即存在多个对同一内存数据的cache,此时,这些cache line中的数据都是read only的。
- 如果某一CPU要对shared态的cache数据执行写入动作,必须先发送invalidate获取该数据的独占权,而其他的CPU会以invalidate acknowledge回应,清空数据并将其cache line从shared状态修改成invalid状态。
场景2:多CPU间处理共享数据:
- 假设CPU X先以读的方式访问共享数据,参考场景1,此时载入缓存后,对应cache line的状态为exclusive。
- 此时,CPU Y要读取该数据,但它的cache中没有该数据,CPU Y发起read请求。
- CPU X回复Read response,并将自己的cache line状态从exclusive设为shared。
- CPU Y收到read response,将数据放入cache,并将自己的cache line状态从invalid设为shared。
内存屏障:
什么是内存屏障,为什么需要内存屏障?
为什么需要内存屏障 - 知乎 (zhihu.com)内存屏障(Memory Barriers)【下】————从硬件的角度看内存屏障 (chocho-quan.github.io)
我们编码时会有一个指令顺序,即程序顺序,这是最重要的顺序;编译器可能重排代码,生成二进制指令流,这是一个静态的指令顺序;执行代码时,CPU通过多条流水线 + Store Buffer + Invalidate Queue等有实际的执行顺序。
内存屏障是一种指令,用于阻止特定内存操作的重排序。它确保在屏障指令前的操作完成,并使其他处理器看到这些操作后,才执行屏障指令后的操作。
内存屏障指令也叫Fence指令,该指令实质就是把Fence通知到内存子系统。内存子系统(包含cache,Store Buffer,Invalidate Queue)据此作出处理,确保内存顺序。
Linux内核中提供了smp_mb()宏对不同架构的指令进行封装,smp_mb()的作用是防止它后面的读写操作乱序到宏前面的指令前执行。
CPU执行指令中如果遇到了smp_mb(),则需要处理store buffer和invalidate queue。有些CPU提供了更为细分的内存屏障,包括” read memory barrier”和” write memory barrier”,前者只会处理invalidate queue,而后者只会处理store buffer,其函数可分别记为smp_rmb()和smp_wmb()。
smp_mb() 这个内存屏障的操作会在执行后续的store操作之前,首先flush store buffer(也就是将之前的值写入到Cache Line中)。smp_mb()操作主要是为了让数据在local cache中的操作顺序是符合program order的顺序的。
对于read memory barrier指令,它只是约束执行CPU上的load操作的顺序,具体的效果就是CPU一定是完成read memory barrier之前的load操作之后,才开始执行read memory barrier之后的load操作。read memory barrier指令像一道栅栏,严格区分了之前和之后的load操作。同样的,write memory barrier指令,它只是约束执行CPU上的store操作的顺序,具体的效果就是CPU一定是完成write memory barrier之前的store操作之后,才开始执行write memory barrier之后的store操作。全功能的memory barrier会同时约束load和store操作,当然只是对执行memory barrier的CPU有效。
内存一致性和内存模型:
内存一致性关注的是多个CPU读写内存地址的次序。针对内存一致性问题,提出了内存模型的概念。内存模型只关心顺序,内存模型定义了多线程访问共享内存的顺序,内存模型预测了或者说决定了代码中读指令究竟读到什么值。
为什么会有这样的需求呢,读指令不就应该读到目的内存地址上现有的值吗?
考虑一下,编译器可能对代码顺序的进行重排,执行时可能对代码顺序进行调整;再考虑一下,多处理器+缓存的架构,事情就没那么简单了。
r1 = f(5) + g(6);上面这个语句中,目标代码对f(5)和g(6)的调用顺序是不定的,可能f(5)在前,也可能g(6)在前。当然,这种情况,影响不大。
//code snippet 1
r1 = READ_ONCE(x);
if (r1)
{
WRITE_ONCE(y, 2);
... /* do something */
}
else
{
WRITE_ONCE(y, 2);
... /* do something else */
}//code snippet 2
r1 = READ_ONCE(x);
WRITE_ONCE(y, 2);
if (r1)
{
... /* do something */
}
else
{
... /* do something else */
}
上面的代码段2可能是对代码段1的优化(其实,实际编码就应该按照代码段2写)。代码段2中READ_ONCE(x)和WRITE_ONCE(y, 2)执行顺序就可能被调整,导致与最初的语义天渊之别。
x86和SPARC采用的内存模型,称为完全存储定序(Total Store Ordering,简称TSO),是一种强顺序模型,是一种接近程序顺序的顺序模型。所谓Total Store,就是说,内存(在写操作上)是有一个全局的顺序的(所有人看到的一样的顺序), 就好像在内存上的每个Store动作必须有一个排队,一个弄完才轮到下一个,这个顺序和你的程序顺序直接相关。写操作(store)和读操作(load)有4种组合,分别是store-store,store-load,load-load和load-store。TSO模型中,只存在store-load存在乱序,另外3种内存操作不存在乱序。
弱内存模型(简称WMO,Weak Memory Ordering),是把是否要求强制顺序这个要求直接交给程序员的方法,由程序员主动插入内存屏障指令来实现。
C++内存模型:
C++11引入memory order的意义是,程序员有了一个与运行平台无关和编译器无关的标准库,可以在高级编程语言层面实现多处理器对共享内存的交互式控制。C11/C++11使用memory order来描述memory model,而用来联系memory order的是atomic变量, atomic操作可以用load()和release()语义来描述;即必须atomic变量与memory order配合使用,memory order之间也需要组合使用。参考以下链接:C++11内存模型完全解读-从硬件层面和内存模型规则层面双重解读-CSDN博客大白话C++之:一文搞懂C++多线程内存模型(Memory Order)_c++ memory order-CSDN博客
enum memory_order
{
memory_order_relaxed,
memory_order_consume,
memory_order_acquire,
memory_order_release,
memory_order_acq_rel,
memory_order_seq_cst
};
| 模型 | 控制强度 | 枚举值 |
| 宽松的访问序列化模型 | 弱 | memory_order_relaxed |
| 获取/释放语义模型 | 中 | memory_order_consume, memory_order_acquire, memory_order_release, memory_order_acq_rel |
| 顺序一致性模型 | 强 | memory_order_seq_cst |
宽松的访问序列化模型:
#include <iostream>
#include <thread>
#include <atomic>
std::atomic<bool> ready{false};
std::atomic<int> data{0};
void producer()
{
//下面两个store操作的先后顺序无法保证,原子操作都能保证
data.store(42, std::memory_order_relaxed);
ready.store(true, std::memory_order_relaxed);
}
void consumer()
{
//原子性的读取ready的值, 但是不保证内存顺序,即跟producer()的顺序不保证
while (!ready.load(memory_order_relaxed))
{
std::this_thread::yield(); //让出CPU时间片
}
// 当ready为true时, 再原子性的读取data的值
std::cout << data.load(memory_order_relaxed);
}
int main()
{
std::thread t1(producer);
std::thread t2(consumer);
t1.join();
t2.join();
return 0;
}上面例子中,消费者看到ready为true后, 读取到的data值可能仍然是0. 为什么呢?
一方面可能是指令重排引起的. 在producer线程里, data和store是两个不相干的变量, 所以编译器或者处理器可能会将data.store(42, std::memory_order_relaxed);重排到ready.store(true, std::memory_order_relaxed);之后执行, 这样consumer线程就会先读取到ready为true, 但是data仍然是0。
另一方面可能是内存顺序不一致引起的. 即使producer线程中的指令没有被重排, 但CPU的多级缓存会导致consumer线程看到的data值仍然是0。
获取/释放语义模型:
当原子变量同步点的store操作是memory_order_release或memory_order_acq_rel时,而对应的另一个同步点的load操作是memory_order_acquire或memory_order_acq_rel或memory_order_consume时,此时就是acquire-release内存序模型。标准规定:
1, 在release之前的所有store操作绝不会重排到(不管是编译器对代码的重排还是CPU指令重排)此release对应的操作之后,也就是说如果release对应的store操作完成了,则C++标准能够保证此release之前的所有store操作肯定已经先完成了,或者说可被感知了。
编译器会在此store操作执行之前插入一个内存屏障(memory barrier,又称内存栅栏)指令,而且是写内存屏障(store memory barrier,smb)指令。此指令会告诉CPU在执行后续的store之前必须先把store-buffer中的数据flush。
2, 在acquire之后的所有load操作或者store操作绝对不会重排到此acquire对应的操作之前,也就是说只有当执行完此acquire对应的load操作之后,才会执行后续的读操作或者写操作。
当对一个load操作使用acquire时,首先会阻止编译器将load操作之后的任何store或load操作重排到此acquire对应的load操作之前,且也会在此load操作执行之后插入一个读内存屏障(read memory barrier, rmb)。rmb会要求将此CPU的invalidate-queue中的invalidate消息全部执行完后再执行其他操作。
一个典型的“生产者-消费者”例子:
std::atomic<std::string*> ptr;
int data;
void producer()
{
std::string* p =newstd::string("Hello"); //#1
data =42; //#2
ptr.store(p,std::memory_order_release); //#3
//备注:原子变量的store 操作使用了 memory_order_release 标记,
//producer 线程中,#1 和 #2 的内存操作不会被重排到#3这个 store 操作之后。
}
void consumer()
{
std::string* p2;
//备注:对同一原子变量的load操作使用了memory_order_acquire,
//这意味着当其确定取到不为null的值的时候,#1和#2对consumer线程是可见的
//(即#1和#2一定会先执行),所以#5和#6的断言能保证成立。
while(!(p2 = ptr.load(std::memory_order_acquire))); //#4
assert(*p2 =="Hello"); //#5
assert(data ==42); //#6
}
int main()
{
std::threadt1(producer);
std::threadt2(consumer);
t1.join();
t2.join();
}注意:代码中的备注详细解释了代码的顺序;这也说明了C++的std::memory_order重点不是用来做线程同步的(看起来有同步效果,注意与同步机制中的放弃CPU和通知调度的区别),重点是确定访问内存的顺序。
关于memory_order_acq_rel,设有一个原子变量M上的acq_rel operation:自然的,该acq_rel operation之前的内存读写都不能重排到该acq_rel operation之后, 该acq_rel operation之后的内存读写都不能重排到该acq_rel operation之前。其他线程中所有对M的release operation及其之前的写入都对当前线程从该acq_rel operation开始的操作可见,并且截止到该acq_rel operation的所有内存写入都对另外线程对M的acquire operation以及之后的内存操作可见。
顺序一致性模型:
顺序一致性模型对应的约束符号是 memory_order_seq_cst,这个模型对于内存访问顺序的一致性控制是最强的。std::atomic 的操作都使用 memory_order_seq_cst 作为默认值。如果你不确定使用何种内存访问模型,用 memory_order_seq_cst 能确保不出错。
从硬件角度来看的话,使用此内存序语义修饰load或store或RMW操作时,就像是在这个操作的前面和后面都插入了smb指令和rmb指令,以实现最大的同步。或者你可以假想成那些用seq_cst语义修饰的原子变量的store操作的之前的所有其他变量store操作都直接将值写到了内存中,而用seq_cst修饰的原子变量的load操作之后的所有其他变量load操作都直接从内存中拿取值。
从内存模型规则的角度来看的话,不管是load操作还是store操作,只要是用了此内存序标记,其前面的任何操作都不会重排到此操作的后面,且此操作后面的任何操作都不会重排到此操作的前面,且一旦某个内存操作完成了,其他任何线程都能感知到。
下面展示了如何使用 memory_order_seq_cst 来实现一个简单的计数器:
#include <atomic>
#include <iostream>
#include <thread>
#include <vector>
std::atomic<int> counter(0);
void worker(int n)
{
for (int i = 0; i < n; ++i)
{
counter.fetch_add(1, std::memory_order_seq_cst);
}
}
int main()
{
const int n = 100000;
const int num_threads = 4;
std::vector<std::thread> threads;
for (int i = 0; i < num_threads; ++i)
{
threads.emplace_back(worker, n);
}
for (auto& t : threads)
{
t.join();
}
std::cout << counter << std::endl;
return 0;
}最后,总结一下:
使用了标准同步原语(比如自旋锁、信号量)的代码不需要显式的使用 memory order,因为这些原语中已经存在必要的顺序约束,只有一些因性能要求需要避免使用同步原语的复杂代码才需要用到 memory order。
对内存的读写访问代码如果都在同一个线程中,也不需要考虑使用 memory order,因为它们在同一时刻只会在同一个 CPU 上执行。只有在不同线程(可能同时在不同的CPU上并行执行)中访问共享数据的场合,才需要考虑使用 memory order。
Linux内核内存模型:
https://isocpp.org/files/papers/p0124r6.html
原文介绍了Linux内核内存一致性模型(Linux-kernel memory consistency model,简称LKMM)的设计思路。LKMM借鉴了PowerPC,ARM,X86等架构,在实现细节上不同于它们。内存模型(LKMM)是Memory subsystem的一部分,在Linux内核中有一部分代码来支持上述功能。
Volatile变量:
尽管volatile能够防止单个线程内对volatile变量进行reorder,但多个线程同时访问同一个volatile变量,线程间是完全不提供同步保证。而且,volatile不提供原子性!并发的读写volatile变量是会产生数据竞争的,同时non volatile操作可以在volatile操作附近自由地reorder。
总结:
理解上述内容,有助于更好理解系统架构,更好地理解编译器原理。
有助于理解广为使用的fence概念。
有助于掌握多处理器架构下的并发编程。
《完》


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









