









要了解Reduce,首先要知道Reduce的几个步骤。
1。Shuffle:也称Copy阶段。Reduce Task从各个Map Task上远程拷贝一片数据,并针对某一片数据,如果其大小超过一定阀值,则写到磁盘上,否则直接放到内存中。
2。Merge:在远程拷贝的同时,Reduce Task启动了两个后台线程对内存和磁盘上的文件进行合并,以防止内存使用过多或者磁盘上文件过多。
3。Sort:按照MapReduce语义,用户编写的reduce()函数输入数据是按key进行聚集的一组数据。为了将key相同的数据聚在一起,Hadoop采用了基于排序的策略。由于各个Map Task已经实现了对自己的处理结果进行了局部排序,因此,Reduce Task只需对所有数据进行一次归并排序即可。
4。Reduce:在该阶段中,Reduce Task将每组数据依次交给用户编写的reduce()函数处理。
5。Write:reduce()函数将计算结果写到HDFS。
1. Map:
要了解Shuffle,就需要了解Map的Collect,和Spill步骤。
1.1 NewOutputCollector
MapTask代码如下,其中有一个NewOutputCollector类。
@SuppressWarnings("unchecked")
private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewMapper(final JobConf job,
final TaskSplitIndex splitIndex,
final TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException,
InterruptedException {
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
// make a mapper
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE> mapper =
(org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getMapperClass(), job);
// make the input format
org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE> inputFormat =
(org.apache.hadoop.mapreduce.InputFormat<INKEY,INVALUE>)
ReflectionUtils.newInstance(taskContext.getInputFormatClass(), job);
// rebuild the input split
org.apache.hadoop.mapreduce.InputSplit split = null;
split = getSplitDetails(new Path(splitIndex.getSplitLocation()),
splitIndex.getStartOffset());
org.apache.hadoop.mapreduce.RecordReader<INKEY,INVALUE> input =
new NewTrackingRecordReader<INKEY,INVALUE>
(split, inputFormat, reporter, job, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
org.apache.hadoop.mapreduce.RecordWriter output = null;
org.apache.hadoop.mapreduce.Mapper<INKEY,INVALUE,OUTKEY,OUTVALUE>.Context
mapperContext = null;
try {
Constructor<org.apache.hadoop.mapreduce.Mapper.Context> contextConstructor =
org.apache.hadoop.mapreduce.Mapper.Context.class.getConstructor
(new Class[]{org.apache.hadoop.mapreduce.Mapper.class,
Configuration.class,
org.apache.hadoop.mapreduce.TaskAttemptID.class,
org.apache.hadoop.mapreduce.RecordReader.class,
org.apache.hadoop.mapreduce.RecordWriter.class,
org.apache.hadoop.mapreduce.OutputCommitter.class,
org.apache.hadoop.mapreduce.StatusReporter.class,
org.apache.hadoop.mapreduce.InputSplit.class});
// get an output object
if (job.getNumReduceTasks() == 0) {
output =
new NewDirectOutputCollector(taskContext, job, umbilical, reporter);
} else {
output = new NewOutputCollector(taskContext, job, umbilical, reporter);
}
mapperContext = contextConstructor.newInstance(mapper, job, getTaskID(),
input, output, committer,
reporter, split);
input.initialize(split, mapperContext);
mapper.run(mapperContext);
input.close();
output.close(mapperContext);
} catch (NoSuchMethodException e) {
throw new IOException("Can't find Context constructor", e);
} catch (InstantiationException e) {
throw new IOException("Can't create Context", e);
} catch (InvocationTargetException e) {
throw new IOException("Can't invoke Context constructor", e);
} catch (IllegalAccessException e) {
throw new IOException("Can't invoke Context constructor", e);
}
}通过构造函数生成mapperContext,map中调用context.write(word, one);
mapperContext = contextConstructor.newInstance(mapper, job, getTaskID(),
input, output, committer,
reporter, split);1.2 MapOutputBuffer
最终数据会被写入MapOutputBuffer中,里面有一个SpillThread,该线程是一个消费者,通过互斥锁,将数据写入磁盘。
class MapOutputBuffer<K extends Object, V extends Object>
implements MapOutputCollector<K, V>, IndexedSortable {
private final SpillThread spillThread = new SpillThread();
@SuppressWarnings("unchecked")
public MapOutputBuffer(TaskUmbilicalProtocol umbilical, JobConf job,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
this.job = job;
this.reporter = reporter;
localFs = FileSystem.getLocal(job);
partitions = job.getNumReduceTasks();
rfs = ((LocalFileSystem)localFs).getRaw();
indexCacheList = new ArrayList<SpillRecord>();
//sanity checks
final float spillper = job.getFloat("io.sort.spill.percent",(float)0.8);
final float recper = job.getFloat("io.sort.record.percent",(float)0.05);
final int sortmb = job.getInt("io.sort.mb", 100);
if (spillper > (float)1.0 || spillper < (float)0.0) {
throw new IOException("Invalid \"io.sort.spill.percent\": " + spillper);
}
if (recper > (float)1.0 || recper < (float)0.01) {
throw new IOException("Invalid \"io.sort.record.percent\": " + recper);
}
if ((sortmb & 0x7FF) != sortmb) {
throw new IOException("Invalid \"io.sort.mb\": " + sortmb);
}
sorter = ReflectionUtils.newInstance(
job.getClass("map.sort.class", QuickSort.class, IndexedSorter.class), job);
LOG.info("io.sort.mb = " + sortmb);
// buffers and accounting
int maxMemUsage = sortmb << 20;
int recordCapacity = (int)(maxMemUsage * recper);
recordCapacity -= recordCapacity % RECSIZE;
kvbuffer = new byte[maxMemUsage - recordCapacity];
bufvoid = kvbuffer.length;
recordCapacity /= RECSIZE;
kvoffsets = new int[recordCapacity];
kvindices = new int[recordCapacity * ACCTSIZE];
softBufferLimit = (int)(kvbuffer.length * spillper);
softRecordLimit = (int)(kvoffsets.length * spillper);
LOG.info("data buffer = " + softBufferLimit + "/" + kvbuffer.length);
LOG.info("record buffer = " + softRecordLimit + "/" + kvoffsets.length);
// k/v serialization
comparator = job.getOutputKeyComparator();
keyClass = (Class<K>)job.getMapOutputKeyClass();
valClass = (Class<V>)job.getMapOutputValueClass();
serializationFactory = new SerializationFactory(job);
keySerializer = serializationFactory.getSerializer(keyClass);
keySerializer.open(bb);
valSerializer = serializationFactory.getSerializer(valClass);
valSerializer.open(bb);
// counters
mapOutputByteCounter = reporter.getCounter(MAP_OUTPUT_BYTES);
mapOutputRecordCounter = reporter.getCounter(MAP_OUTPUT_RECORDS);
Counters.Counter combineInputCounter =
reporter.getCounter(COMBINE_INPUT_RECORDS);
combineOutputCounter = reporter.getCounter(COMBINE_OUTPUT_RECORDS);
fileOutputByteCounter = reporter.getCounter(MAP_OUTPUT_MATERIALIZED_BYTES);
// compression
if (job.getCompressMapOutput()) {
Class<? extends CompressionCodec> codecClass =
job.getMapOutputCompressorClass(DefaultCodec.class);
codec = ReflectionUtils.newInstance(codecClass, job);
}
// combiner
combinerRunner = CombinerRunner.create(job, getTaskID(),
combineInputCounter,
reporter, null);
if (combinerRunner != null) {
combineCollector= new CombineOutputCollector<K,V>(combineOutputCounter, reporter, conf);
} else {
combineCollector = null;
}
minSpillsForCombine = job.getInt("min.num.spills.for.combine", 3);
spillThread.setDaemon(true);
spillThread.setName("SpillThread");
spillLock.lock();
try {
spillThread.start();
while (!spillThreadRunning) {
spillDone.await();
}
} catch (InterruptedException e) {
throw (IOException)new IOException("Spill thread failed to initialize"
).initCause(sortSpillException);
} finally {
spillLock.unlock();
}
if (sortSpillException != null) {
throw (IOException)new IOException("Spill thread failed to initialize"
).initCause(sortSpillException);
}
}
public synchronized void collect(K key, V value, int partition
) throws IOException {
reporter.progress();
if (key.getClass() != keyClass) {
throw new IOException("Type mismatch in key from map: expected "
+ keyClass.getName() + ", recieved "
+ key.getClass().getName());
}
if (value.getClass() != valClass) {
throw new IOException("Type mismatch in value from map: expected "
+ valClass.getName() + ", recieved "
+ value.getClass().getName());
}
final int kvnext = (kvindex + 1) % kvoffsets.length;
spillLock.lock();
try {
boolean kvfull;
do {
if (sortSpillException != null) {
throw (IOException)new IOException("Spill failed"
).initCause(sortSpillException);
}
// sufficient acct space
kvfull = kvnext == kvstart;
final boolean kvsoftlimit = ((kvnext > kvend)
? kvnext - kvend > softRecordLimit
: kvend - kvnext <= kvoffsets.length - softRecordLimit);
if (kvstart == kvend && kvsoftlimit) {
LOG.info("Spilling map output: record full = " + kvsoftlimit);
startSpill();
}
if (kvfull) {
try {
while (kvstart != kvend) {
reporter.progress();
spillDone.await();
}
} catch (InterruptedException e) {
throw (IOException)new IOException(
"Collector interrupted while waiting for the writer"
).initCause(e);
}
}
} while (kvfull);
} finally {
spillLock.unlock();
}
try {
// serialize key bytes into buffer
int keystart = bufindex;
keySerializer.serialize(key);
if (bufindex < keystart) {
// wrapped the key; reset required
bb.reset();
keystart = 0;
}
// serialize value bytes into buffer
final int valstart = bufindex;
valSerializer.serialize(value);
int valend = bb.markRecord();
if (partition < 0 || partition >= partitions) {
throw new IOException("Illegal partition for " + key + " (" +
partition + ")");
}
mapOutputRecordCounter.increment(1);
mapOutputByteCounter.increment(valend >= keystart
? valend - keystart
: (bufvoid - keystart) + valend);
// update accounting info
int ind = kvindex * ACCTSIZE;
kvoffsets[kvindex] = ind;
kvindices[ind + PARTITION] = partition;
kvindices[ind + KEYSTART] = keystart;
kvindices[ind + VALSTART] = valstart;
kvindex = kvnext;
} catch (MapBufferTooSmallException e) {
LOG.info("Record too large for in-memory buffer: " + e.getMessage());
spillSingleRecord(key, value, partition);
mapOutputRecordCounter.increment(1);
return;
}
}1.3 NewOutputCollector
NewOutputCollector有个很关键的方法getPartition,
private class NewOutputCollector<K,V>
extends org.apache.hadoop.mapreduce.RecordWriter<K,V> {
private final MapOutputCollector<K,V> collector;
private final org.apache.hadoop.mapreduce.Partitioner<K,V> partitioner;
private final int partitions;
@SuppressWarnings("unchecked")
NewOutputCollector(org.apache.hadoop.mapreduce.JobContext jobContext,
JobConf job,
TaskUmbilicalProtocol umbilical,
TaskReporter reporter
) throws IOException, ClassNotFoundException {
collector = new MapOutputBuffer<K,V>(umbilical, job, reporter);
partitions = jobContext.getNumReduceTasks();
if (partitions > 0) {
partitioner = (org.apache.hadoop.mapreduce.Partitioner<K,V>)
ReflectionUtils.newInstance(jobContext.getPartitionerClass(), job);
} else {
partitioner = new org.apache.hadoop.mapreduce.Partitioner<K,V>() {
@Override
public int getPartition(K key, V value, int numPartitions) {
return -1;
}
};
}
}
@Override
public void write(K key, V value) throws IOException, InterruptedException {
collector.collect(key, value,
partitioner.getPartition(key, value, partitions));
}
}getPartition的方式,对key做了一个hash,同个值的key,将传递到同一个reduce。比如有2个reducetask,“aaa”,和“bbb”会分配到不同的reduce,“ccc”会分配给“aaa”同个的reduce。
public class HashPartitioner<K, V> extends Partitioner<K, V> {
/** Use {@link Object#hashCode()} to partition. */
public int getPartition(K key, V value,
int numReduceTasks) {
return (key.hashCode() & Integer.MAX_VALUE) % numReduceTasks;
}
}2 Reduce
2.1 Reduce获取数据
Reduce是如何获取数据的呢?流程如下图:
1。Copy过程,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
2。Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
3。Reducer的输入文件。不断地merge后,最后会生成一个“最终文件”。为什么加引号?因为这个文件可能存在于磁盘上,也可能存在于内存中。对我们来说,当然希望它存放于内存中,直接作为Reducer的输入,但默认情况下,这个文件是存放于磁盘中的。至于怎样才能让这个文件出现在内存中,之后的性能优化篇 我再说。当Reducer的输入文件已定,整个Shuffle才最终结束。然后就是Reducer执行,把结果放到HDFS上。
2.2 MapOutputCopier
copiers = new ArrayList<MapOutputCopier>(numCopiers);
// start all the copying threads
for (int i=0; i < numCopiers; i++) {
MapOutputCopier copier = new MapOutputCopier(conf, reporter,
reduceTask.getJobTokenSecret());
copiers.add(copier);
copier.start();
}
//start the on-disk-merge thread
localFSMergerThread = new LocalFSMerger((LocalFileSystem)localFileSys);
//start the in memory merger thread
inMemFSMergeThread = new InMemFSMergeThread();
localFSMergerThread.start();
inMemFSMergeThread.start();
// start the map events thread
getMapEventsThread = new GetMapEventsThread();
getMapEventsThread.start();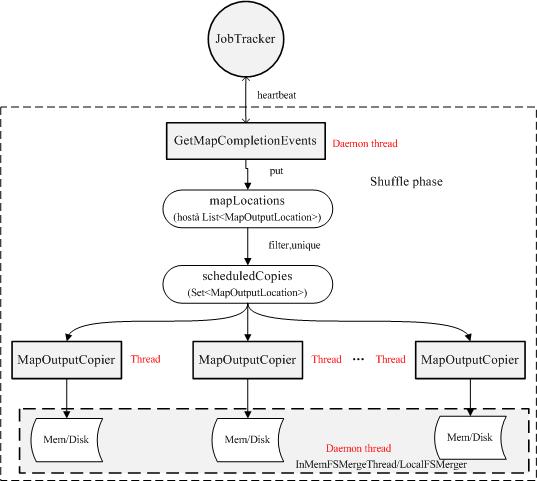
如图所示,每个reduce task都会有一个后台进程GetMapCompletionEvents,它获取heartbeat中(从JobTracker)传过来的已经完成的task列表,并将与该reduce task对应的数据位置信息保存到mapLocations中,mapLocations中的数据位置信息经过滤和去重(相同的位置信息因为某种原因,可能发过来多次)等处理后保存到集合scheduledCopies中,然后由几个拷贝线程(默认为5个)通过HTTP并行的拷贝数据,同时线程InMemFSMergeThread和LocalFSMerger会对拷贝过来的数据进行归并排序。
public static class IntSumReducer
extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}public class ReduceContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
extends TaskInputOutputContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT> {
private RawKeyValueIterator input;
private Counter inputKeyCounter;
private Counter inputValueCounter;
private RawComparator<KEYIN> comparator;
private KEYIN key; // current key
private VALUEIN value; // current value
private boolean firstValue = false; // first value in key
private boolean nextKeyIsSame = false; // more w/ this key
private boolean hasMore; // more in file
protected Progressable reporter;
private Deserializer<KEYIN> keyDeserializer;
private Deserializer<VALUEIN> valueDeserializer;
private DataInputBuffer buffer = new DataInputBuffer();
private BytesWritable currentRawKey = new BytesWritable();
private ValueIterable iterable = new ValueIterable();
public ReduceContext(Configuration conf, TaskAttemptID taskid,
RawKeyValueIterator input,
Counter inputKeyCounter,
Counter inputValueCounter,
RecordWriter<KEYOUT,VALUEOUT> output,
OutputCommitter committer,
StatusReporter reporter,
RawComparator<KEYIN> comparator,
Class<KEYIN> keyClass,
Class<VALUEIN> valueClass
) throws InterruptedException, IOException{
super(conf, taskid, output, committer, reporter);
this.input = input;
this.inputKeyCounter = inputKeyCounter;
this.inputValueCounter = inputValueCounter;
this.comparator = comparator;
SerializationFactory serializationFactory = new SerializationFactory(conf);
this.keyDeserializer = serializationFactory.getDeserializer(keyClass);
this.keyDeserializer.open(buffer);
this.valueDeserializer = serializationFactory.getDeserializer(valueClass);
this.valueDeserializer.open(buffer);
hasMore = input.next();
}
/** Start processing next unique key. */
public boolean nextKey() throws IOException,InterruptedException {
while (hasMore && nextKeyIsSame) {
nextKeyValue();
}
if (hasMore) {
if (inputKeyCounter != null) {
inputKeyCounter.increment(1);
}
return nextKeyValue();
} else {
return false;
}
}
/**
* Advance to the next key/value pair.
*/
@Override
public boolean nextKeyValue() throws IOException, InterruptedException {
if (!hasMore) {
key = null;
value = null;
return false;
}
firstValue = !nextKeyIsSame;
DataInputBuffer next = input.getKey();
currentRawKey.set(next.getData(), next.getPosition(),
next.getLength() - next.getPosition());
buffer.reset(currentRawKey.getBytes(), 0, currentRawKey.getLength());
key = keyDeserializer.deserialize(key);
next = input.getValue();
buffer.reset(next.getData(), next.getPosition(), next.getLength());
value = valueDeserializer.deserialize(value);
hasMore = input.next();
if (hasMore) {
next = input.getKey();
nextKeyIsSame = comparator.compare(currentRawKey.getBytes(), 0,
currentRawKey.getLength(),
next.getData(),
next.getPosition(),
next.getLength() - next.getPosition()
) == 0;
} else {
nextKeyIsSame = false;
}
inputValueCounter.increment(1);
return true;
}
public KEYIN getCurrentKey() {
return key;
}
@Override
public VALUEIN getCurrentValue() {
return value;
}
protected class ValueIterator implements Iterator<VALUEIN> {
@Override
public boolean hasNext() {
return firstValue || nextKeyIsSame;
}
@Override
public VALUEIN next() {
// if this is the first record, we don't need to advance
if (firstValue) {
firstValue = false;
return value;
}
// if this isn't the first record and the next key is different, they
// can't advance it here.
if (!nextKeyIsSame) {
throw new NoSuchElementException("iterate past last value");
}
// otherwise, go to the next key/value pair
try {
nextKeyValue();
return value;
} catch (IOException ie) {
throw new RuntimeException("next value iterator failed", ie);
} catch (InterruptedException ie) {
// this is bad, but we can't modify the exception list of java.util
throw new RuntimeException("next value iterator interrupted", ie);
}
}
@Override
public void remove() {
throw new UnsupportedOperationException("remove not implemented");
}
}
protected class ValueIterable implements Iterable<VALUEIN> {
private ValueIterator iterator = new ValueIterator();
@Override
public Iterator<VALUEIN> iterator() {
return iterator;
}
}
/**
* Iterate through the values for the current key, reusing the same value
* object, which is stored in the context.
* @return the series of values associated with the current key. All of the
* objects returned directly and indirectly from this method are reused.
*/
public
Iterable<VALUEIN> getValues() throws IOException, InterruptedException {
return iterable;
}
}public abstract class TaskInputOutputContext<KEYIN,VALUEIN,KEYOUT,VALUEOUT>
extends TaskAttemptContext implements Progressable {
private RecordWriter<KEYOUT,VALUEOUT> output;
private StatusReporter reporter;
private OutputCommitter committer;
public TaskInputOutputContext(Configuration conf, TaskAttemptID taskid,
RecordWriter<KEYOUT,VALUEOUT> output,
OutputCommitter committer,
StatusReporter reporter) {
super(conf, taskid);
this.output = output;
this.reporter = reporter;
this.committer = committer;
}
public abstract
boolean nextKeyValue() throws IOException, InterruptedException;
public abstract
KEYIN getCurrentKey() throws IOException, InterruptedException;
public abstract VALUEIN getCurrentValue() throws IOException,
InterruptedException;
public void write(KEYOUT key, VALUEOUT value
) throws IOException, InterruptedException {
output.write(key, value);
}
public Counter getCounter(Enum<?> counterName) {
return reporter.getCounter(counterName);
}
public Counter getCounter(String groupName, String counterName) {
return reporter.getCounter(groupName, counterName);
}
@Override
public void progress() {
reporter.progress();
}
@Override
public void setStatus(String status) {
reporter.setStatus(status);
}
public OutputCommitter getOutputCommitter() {
return committer;
}
} private <INKEY,INVALUE,OUTKEY,OUTVALUE>
void runNewReducer(JobConf job,
final TaskUmbilicalProtocol umbilical,
final TaskReporter reporter,
RawKeyValueIterator rIter,
RawComparator<INKEY> comparator,
Class<INKEY> keyClass,
Class<INVALUE> valueClass
) throws IOException,InterruptedException,
ClassNotFoundException {
// wrap value iterator to report progress.
final RawKeyValueIterator rawIter = rIter;
rIter = new RawKeyValueIterator() {
public void close() throws IOException {
rawIter.close();
}
public DataInputBuffer getKey() throws IOException {
return rawIter.getKey();
}
public Progress getProgress() {
return rawIter.getProgress();
}
public DataInputBuffer getValue() throws IOException {
return rawIter.getValue();
}
public boolean next() throws IOException {
boolean ret = rawIter.next();
reducePhase.set(rawIter.getProgress().get());
reporter.progress();
return ret;
}
};
// make a task context so we can get the classes
org.apache.hadoop.mapreduce.TaskAttemptContext taskContext =
new org.apache.hadoop.mapreduce.TaskAttemptContext(job, getTaskID());
// make a reducer
org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE> reducer =
(org.apache.hadoop.mapreduce.Reducer<INKEY,INVALUE,OUTKEY,OUTVALUE>)
ReflectionUtils.newInstance(taskContext.getReducerClass(), job);
org.apache.hadoop.mapreduce.RecordWriter<OUTKEY,OUTVALUE> trackedRW =
new NewTrackingRecordWriter<OUTKEY, OUTVALUE>(reduceOutputCounter,
job, reporter, taskContext);
job.setBoolean("mapred.skip.on", isSkipping());
org.apache.hadoop.mapreduce.Reducer.Context
reducerContext = createReduceContext(reducer, job, getTaskID(),
rIter, reduceInputKeyCounter,
reduceInputValueCounter,
trackedRW, committer,
reporter, comparator, keyClass,
valueClass);
reducer.run(reducerContext);
trackedRW.close(reducerContext);
} @Override
@SuppressWarnings("unchecked")
public void run(JobConf job, final TaskUmbilicalProtocol umbilical)
throws IOException, InterruptedException, ClassNotFoundException {
this.umbilical = umbilical;
job.setBoolean("mapred.skip.on", isSkipping());
if (isMapOrReduce()) {
copyPhase = getProgress().addPhase("copy");
sortPhase = getProgress().addPhase("sort");
reducePhase = getProgress().addPhase("reduce");
}
// start thread that will handle communication with parent
TaskReporter reporter = new TaskReporter(getProgress(), umbilical,
jvmContext);
reporter.startCommunicationThread();
boolean useNewApi = job.getUseNewReducer();
initialize(job, getJobID(), reporter, useNewApi);
// check if it is a cleanupJobTask
if (jobCleanup) {
runJobCleanupTask(umbilical, reporter);
return;
}
if (jobSetup) {
runJobSetupTask(umbilical, reporter);
return;
}
if (taskCleanup) {
runTaskCleanupTask(umbilical, reporter);
return;
}
// Initialize the codec
codec = initCodec();
boolean isLocal = "local".equals(job.get("mapred.job.tracker", "local"));
if (!isLocal) {
reduceCopier = new ReduceCopier(umbilical, job, reporter);
if (!reduceCopier.fetchOutputs()) {
if(reduceCopier.mergeThrowable instanceof FSError) {
throw (FSError)reduceCopier.mergeThrowable;
}
throw new IOException("Task: " + getTaskID() +
" - The reduce copier failed", reduceCopier.mergeThrowable);
}
}
copyPhase.complete(); // copy is already complete
setPhase(TaskStatus.Phase.SORT);
statusUpdate(umbilical);
final FileSystem rfs = FileSystem.getLocal(job).getRaw();
RawKeyValueIterator rIter = isLocal
? Merger.merge(job, rfs, job.getMapOutputKeyClass(),
job.getMapOutputValueClass(), codec, getMapFiles(rfs, true),
!conf.getKeepFailedTaskFiles(), job.getInt("io.sort.factor", 100),
new Path(getTaskID().toString()), job.getOutputKeyComparator(),
reporter, spilledRecordsCounter, null)
: reduceCopier.createKVIterator(job, rfs, reporter);
// free up the data structures
mapOutputFilesOnDisk.clear();
sortPhase.complete(); // sort is complete
setPhase(TaskStatus.Phase.REDUCE);
statusUpdate(umbilical);
Class keyClass = job.getMapOutputKeyClass();
Class valueClass = job.getMapOutputValueClass();
RawComparator comparator = job.getOutputValueGroupingComparator();
if (useNewApi) {
runNewReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
} else {
runOldReducer(job, umbilical, reporter, rIter, comparator,
keyClass, valueClass);
}
done(umbilical, reporter);
}public class TextOutputFormat<K, V> extends FileOutputFormat<K, V> {
protected static class LineRecordWriter<K, V>
extends RecordWriter<K, V> {
private static final String utf8 = "UTF-8";
private static final byte[] newline;
static {
try {
newline = "\n".getBytes(utf8);
} catch (UnsupportedEncodingException uee) {
throw new IllegalArgumentException("can't find " + utf8 + " encoding");
}
}
private void writeObject(Object o) throws IOException {
if (o instanceof Text) {
Text to = (Text) o;
out.write(to.getBytes(), 0, to.getLength());
} else {
out.write(o.toString().getBytes(utf8));
}
}
public synchronized void write(K key, V value)
throws IOException {
boolean nullKey = key == null || key instanceof NullWritable;
boolean nullValue = value == null || value instanceof NullWritable;
if (nullKey && nullValue) {
return;
}
if (!nullKey) {
writeObject(key);
}
if (!(nullKey || nullValue)) {
out.write(keyValueSeparator);
}
if (!nullValue) {
writeObject(value);
}
out.write(newline);
}
public synchronized
void close(TaskAttemptContext context) throws IOException {
out.close();
}
}
参考:
1.《MapReduce:详解Shuffle过程》:http://langyu.iteye.com/blog/992916。
2.《Hadoop技术内幕》:董西成。
3.《Hadoop中shuffle阶段流程分析》:http://dongxicheng.org/mapreduce/hadoop-shuffle-phase/。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









