









聚簇与非聚簇
首先Mysql中索引是使用了B+Tree的结构,具体数据结构可以看这里。
聚簇索引: 其叶子节点就是对应了物理上的行,并且其保证了叶子结点的顺序与物理位置一致。 这个特性决定了其不适合使用在随机字符串类似的字段上,因为有可能会造成大量的数据移动。 还决定了其能够很好的利用数据库预读以及页读的功能很快的查找范围内的数据。
非聚簇索引: 其叶子节点存储了列值及到行的指针。因此其顺序跟物理顺序无关,插入的效率要高很多,因为仅仅是移动节点的指针不会涉及数据移动。
下面的图比较形象:
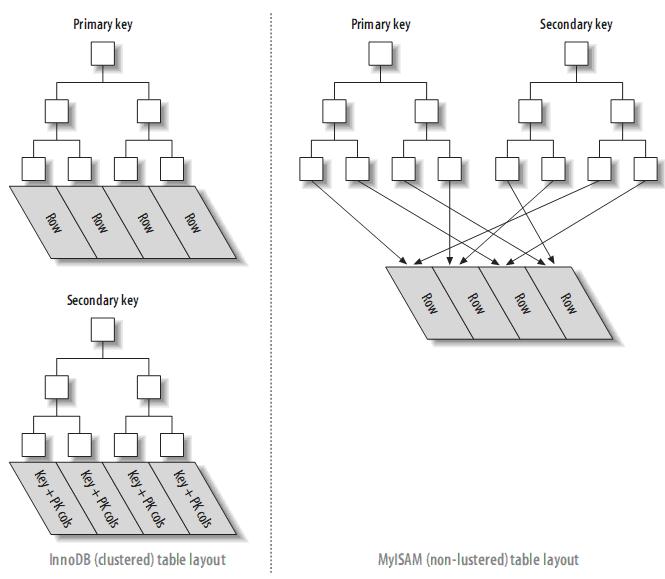
覆盖索引: 当要提取的数据在叶子节点中就能够获取,而不用去查找数据块时就叫做覆盖索引。因为索引中的数据时顺序的,并且空间比较小,因此会带来比较高的性能。
使用取舍:
| 行为 | 聚簇索引 | 非聚簇索引 |
|---|---|---|
| 列常被group by | 可以 | 可以 |
| 列经常被between等范围查询 | 效率高 | 效率低 |
| 频繁更新的列 | 效率低 | 效率高 |
| 列常被order by | 可以 | 可以 |
| 获取大于20%的数据 | 不可 | 不可 |
此外,在插入非常频繁的场景下,聚簇索引因为插入的热点都是在最尾端,因此有可能会有性能问题,可以通过配置innodb_autoinc_lock_mode 来配置这种情况下的处理方式,表锁还是预读预置一些值给语句使用
索引命中规则:
- 全值匹配
- 匹配最左前缀, 即多列索引,从最左列开始匹配
- 匹配列前缀,即 A*这样的匹配方式
- 匹配范围值, between and是可以的
- 精确左,范围右。 where firstName=’123’ and middlename like ‘abc%’
- 覆盖索引
- order by 子句会用到索引
哈希索引
哈希索引使用了哈希算法。其具有如下的特性:
- 只存储hash值和行指针,不存储字段值,因此不能用来读取单一行。
- 不能用于排序
- 只支持等值查找
- 一般不会用到,如果想手工使用可以用mysql自带的CRC32方法来进一步的缩小范围
总结一下:
- 单行访问很慢,因为随机I/O很慢。 最好读取的快中能够包含尽可能多的需要的数据,使用索引可以创建位置引用以提升效率
- 按顺序访问数据很快。 顺序I/O不需要寻到,不需要而外的排序操作
- 索引覆盖很快
















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









