Probabilistic Latent Semantic Analysis
主题模型简介
plsa,也就是概率隐语义分析,是主题模型的一种。主题模型是什么呢?先从文档说起,每篇文档用bag-of-words模型表示,也就是每篇文档只与所包含的词有关,而不考虑这些词的先后顺序。假设文档集 D 有
N
篇文档,主题模型认为在这 N 篇文档中一共隐含了
Z
个主题,每篇文档都可能属于一个或多个主题,这可以用给定文档 d 时所属主题
z
的概率分布 p(z|d) 表示。同理,一个主题下可以包含若干个词 w ,用概率分布
p(w|z)
表示。
所以,如果我们有文档集 D ,又求出对应这个文档集的主题模型,那这有什么意义呢?最明显的意义就是,这相当于给文档聚类了,并且聚类的结果有更合理的解释性。因为我们不但可以知道每一篇文档
d
属于哪个类别 z ,我们还可以根据概率
p(w|z)
知道这个主题的关键词是哪些,从而给这个主题 z 设置合理的标签。知道文档所属的类别,我们就可以判断两篇文档在语义上是否相似了。虽然可以直接根据文档向量的余弦距离来判断它们是否相似,但是这对近义词就无能为力,比如两篇同样介绍电子产品的文档,一篇大量用“苹果”这个关键词,而另一篇大量用“iPhone”,那么通过余弦距离判断的这两个维度上肯定是不相似的。而“苹果”、“iPhone”两个词都与电子产品关系很大,所以这两篇文档可以都属于同一个主题,也就可以断定他们语义上是相似的。
主题模型的用处还是很多的,在推荐系统,舆情监控等等,都有广泛的用途。
plsa原理
介绍完主题模型的基本概念,就要回到本文的重点,给定一个文档集
D
,如何估计主题模型的参数呢?接下来说明如何用plsa来求出这些参数。先放一张图
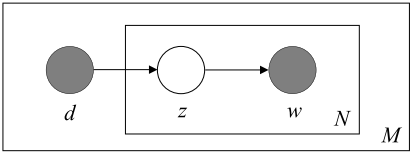
首先介绍一下图中参数: d 代表每一篇文档,
z
表示每一个隐含主题, w 表示具体的单词。
N
表示每篇文档的单词数, M 表示文档集
D
内的文档数。
plsa是一个生成模型,它假设了 d ,
w
, z 之间的关系通过上图的贝叶斯网络 所表示。灰色的节点
d
和 w 表示我们能够观测到的变量,也就是具体的文档与文档中的词。白色的节点
z
就是隐含的主题变量。每篇文档的生成过程是
1. 以概率 p(d) 选定文档。
2. 以概率 p(z|d) 选定一个主题。
3. 以概率 p(w|z) 从主题中选定单词。
我们需要估计的参数就是 p(z|d) 与 p(w|z) ,后文有些地方用 θ 来表示他们。先不管我们知不知道 z 是什么,用极大似然估计试试。
n(d,w)
表示某篇文档 d 中的词
w
出现的次数,这个直接统计得到。 p(d,w) 就是观测到变量 d 与
w
的联合概率分布。写出似然函数
L(θ)=∏d∏wp(d,w)n(d,w)
再写出log似然函数








 概率隐语义分析plsa是主题模型的一种,用于文档聚类和语义理解。通过模型,可以得知每篇文档所属主题及其关键词,进而判断文档间的语义相似性。plsa使用EM算法估计参数,包括E步(求解隐含主题概率)和M步(最大化期望函数更新参数)。在实际应用中,plsa广泛用于推荐系统和舆情监控等领域。
概率隐语义分析plsa是主题模型的一种,用于文档聚类和语义理解。通过模型,可以得知每篇文档所属主题及其关键词,进而判断文档间的语义相似性。plsa使用EM算法估计参数,包括E步(求解隐含主题概率)和M步(最大化期望函数更新参数)。在实际应用中,plsa广泛用于推荐系统和舆情监控等领域。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









