






前言
1、池化技术 :简单点来说,就是提前保存大量的资源,以备不时之需
对于线程,内存,oracle的连接对象等等,这些都是资源,程序中当你创建一个线程或者在堆上申请一块内存时,都涉及到很多系统调用,也是非常消耗CPU的,如果你的程序需要很多类似的工作线程或者需要频繁的申请释放小块内存,如果没有在这方面进行优化,那很有可能这部分代码将会成为影响你整个程序性能的瓶颈。
池化技术主要有线程池,内存池,连接池,对象池等等。
一、线程池
1、线程池原理
线程池的本质是对任务和线程的管理,而做到这一点最关键的思想就是将任务和线程两者解耦,不让两者直接关联,才可以做后续的分配工作。 线程池中是以生产者消费者模式,通过一个阻塞队列来实现的。 阻塞队列缓存任务,工作线程从阻塞队列中获取任务。 阻塞队列(BlockingQueue)是一个支持两个附加操作的队列。

2、线程池的使用场景
- 某类任务特别耗时,严重影响该线程处理其他任务
- 在其它线程异步执行该函数
- 线程资源的开销与CPU核数之间平衡选择

3、线程池的作用
- 复用线程资源
- 减少线程创建和销毁的开销
- 可异步处理生产者线程的任务
- 减少了多个任务(不是一个任务)的执行时间
4、代码如何实现一个线程池

4.1 thrd_pool.h
#ifndef _THREAD_POOL_H
#define _THREAD_POOL_H
typedef struct thread_pool_t thread_pool_t;
typedef void (*handler_pt) (void *);
thread_pool_t *thread_pool_create(int thrd_count, int queue_size);
//发布任务
int thread_pool_post(thread_pool_t *pool, handler_pt func, void *arg);
//清空任务
int thread_pool_destroy(thread_pool_t *pool);
int wait_all_done(thread_pool_t *pool);
#endif4.2 thrd_pool.c
#include <pthread.h>
#include <stdint.h>
#include <stddef.h>
#include <stdlib.h>
#include "thrd_pool.h"
//任务节点 结构体
typedef struct task_t {
handler_pt func;
void * arg;
} task_t;
//任务队列结构体
#if 1
typedef struct task_queue_t { //一次性分配内存
uint32_t head; //头指针
uint32_t tail; //尾指针
uint32_t count; //任务队列中的 任务节点数
task_t *queue; //任务节点
} task_queue_t;
#else
typedef struct task_queue_t { // 与内存池一起使用
task_t * head;
task_t * tail;
uint32_t count;
} task_queue_t;
#endif
//线程池结构体
struct thread_pool_t {
pthread_mutex_t mutex; //线程锁
pthread_cond_t condition; //条件变量
pthread_t *threads;
task_queue_t task_queue; //任务队列
int closed; //线程退出的标志
int started; // 当前运行的线程数
int thrd_count; //线程数量
int queue_size; //任务队列数量
};
static void * thread_worker(void *thrd_pool);
static void thread_pool_free(thread_pool_t *pool);
thread_pool_t *
thread_pool_create(int thrd_count, int queue_size) {
thread_pool_t *pool;
if (thrd_count <= 0 || queue_size <= 0) {
return NULL;
}
pool = (thread_pool_t*) malloc(sizeof(*pool));
if (pool == NULL) {
return NULL;
}
pool->thrd_count = 0;
pool->queue_size = queue_size;
pool->task_queue.head = 0;
pool->task_queue.tail = 0;
pool->task_queue.count = 0;
pool->started = pool->closed = 0;
pool->task_queue.queue = (task_t*)malloc(sizeof(task_t)*queue_size);
if (pool->task_queue.queue == NULL) {
// TODO: free pool
return NULL;
}
pool->threads = (pthread_t*) malloc(sizeof(pthread_t) * thrd_count);
if (pool->threads == NULL) {
// TODO: free pool
return NULL;
}
int i = 0;
for (; i < thrd_count; i++) {
if (pthread_create(&(pool->threads[i]), NULL, thread_worker, (void*)pool) != 0) {
// TODO: free pool
return NULL;
}
pool->thrd_count++;
pool->started++;
}
return pool;
}
int
thread_pool_post(thread_pool_t *pool, handler_pt func, void *arg) {
if (pool == NULL || func == NULL) {
return -1;
}
task_queue_t *task_queue = &(pool->task_queue);
if (pthread_mutex_lock(&(pool->mutex)) != 0) {
return -2;
}
if (pool->closed) {
pthread_mutex_unlock(&(pool->mutex));
return -3;
}
if (task_queue->count == pool->queue_size) {
pthread_mutex_unlock(&(pool->mutex));
return -4;
}
//队列的操作应该使用自旋锁(效率高),但是这里图方便使用了互斥锁
task_queue->queue[task_queue->tail].func = func;
task_queue->queue[task_queue->tail].arg = arg;
task_queue->tail = (task_queue->tail + 1) % pool->queue_size;
task_queue->count++;
//唤醒一个休眠线程
if (pthread_cond_signal(&(pool->condition)) != 0) {
pthread_mutex_unlock(&(pool->mutex));
return -5;
}
pthread_mutex_unlock(&(pool->mutex));
return 0;
}
static void
thread_pool_free(thread_pool_t *pool) {
if (pool == NULL || pool->started > 0) {
return;
}
if (pool->threads) {
free(pool->threads);
pool->threads = NULL;
pthread_mutex_lock(&(pool->mutex));
pthread_mutex_destroy(&pool->mutex);
pthread_cond_destroy(&pool->condition);
}
if (pool->task_queue.queue) {
free(pool->task_queue.queue);
pool->task_queue.queue = NULL;
}
free(pool);
}
int
wait_all_done(thread_pool_t *pool) {
int i, ret=0;
for (i=0; i < pool->thrd_count; i++) {
if (pthread_join(pool->threads[i], NULL) != 0) {
ret=1;
}
}
return ret;
}
int
thread_pool_destroy(thread_pool_t *pool) {
if (pool == NULL) {
return -1;
}
if (pthread_mutex_lock(&(pool->mutex)) != 0) {
return -2;
}
if (pool->closed) {
thread_pool_free(pool);
return -3;
}
pool->closed = 1;
//让所有阻塞(pool->condition)的线程唤醒
if (pthread_cond_broadcast(&(pool->condition)) != 0 ||
pthread_mutex_unlock(&(pool->mutex)) != 0) {
thread_pool_free(pool);
return -4;
}
wait_all_done(pool);
thread_pool_free(pool);
return 0;
}
static void *
thread_worker(void *thrd_pool) {
thread_pool_t *pool = (thread_pool_t*)thrd_pool;
task_queue_t *que;
task_t task;
for (;;) {
pthread_mutex_lock(&(pool->mutex));
que = &pool->task_queue;
// 虚假唤醒 linux pthread_cond_signal
// linux 可能被信号唤醒
// 业务逻辑不严谨,被其他线程抢了该任务
while (que->count == 0 && pool->closed == 0) {
// pthread_mutex_unlock(&(pool->mutex))
// 阻塞在 condition
// ===================================
// 解除阻塞
// pthread_mutex_lock(&(pool->mutex));
pthread_cond_wait(&(pool->condition), &(pool->mutex));
}
if (pool->closed == 1) break;
task = que->queue[que->head];
que->head = (que->head + 1) % pool->queue_size;
que->count--;
pthread_mutex_unlock(&(pool->mutex));
(*(task.func))(task.arg);
}
pool->started--;
pthread_mutex_unlock(&(pool->mutex));
pthread_exit(NULL);
return NULL;
}4.3 测试代码
// 任务函数
void* mytask(void *arg)
{
printf("thread %d is working on task %d\n", (int)pthread_self(),(int)arg);
return NULL;
}
int main()
{
thread_pool_t *thr_ptr = NULL;
int red = 0;
int i = 0;
handler_pt func;
thr_ptr = thread_pool_create(4, 10);
if(!thr_ptr)
{
(void)printf("create thread pool failed\n");
return 0;
}
for(i=0; i<100; i++)
{
red = thread_pool_post(thr_ptr, (handler_pt)mytask, (void* )i);
if(red)
{
(void)printf("thread pool post failed:i=%d, red=%d\n", i, red);
}
usleep(1);
}
sleep(1);
red = thread_pool_destroy(thr_ptr);
if(red)
{
(void)printf("thread pool destroy failed\n");
}
return 0;
}5、线程池在各种开源框架中的使用
5.1 网络编程reactor中线程池(one eventloop per thread)
在一个事件循环中,可以处理多个就绪事件,这些就绪时间在reactor模型中时串行执行的,一个事件处理延时若耗时较长,会延迟其它同时触发的事件的处理(对于客户端而言,响应会变得较慢)。
线程池作用阶段(read、write) 如下图红色圈圈

5.2 nginx中线程池(磁盘IO密集型)
- 文件缓冲:nginx可以作为静态web服务器,静态文件可以存储到nginx本身而不用放在后端服务器,静态资源在nginx缓冲起来。
- 缓冲方式:
- aio:异步IO的接口发送(只是列出这里可以使用线程池,但是不推荐使用,推荐使用下面两个)
- sendfile:系统调用接口,适合小文件发送
- director:系统调用接口,以256字节快发送(每次发256字节,最后一帧不满足256阻塞发送)适合大文件发送。
线程池作用阶段(处理文件缓冲) 如下图红色圈圈。

# 线程池默认关闭,configure 时,需要 --with-threads来指定;
./configure --with-pcre-jit--with- http_ssl_module--with-http_realip_module--with-http_stub_status_module--with-http_v2_module--with-threads# 解决 gdb 远程权限的问题echo 0 | sudotee/proc/sys/kernel/yama/ptrace_scope# 创建名为 mark 的线程池,线程池数量为32,任务队列为65535thread_pool mark threads = 32 max_queue = 65535 ;location / {root /img;aio threads = mark;}location / {sendfile on;sendfile_max_chunk 128k; # 默认是没有限制的}location / {directio 8m;}
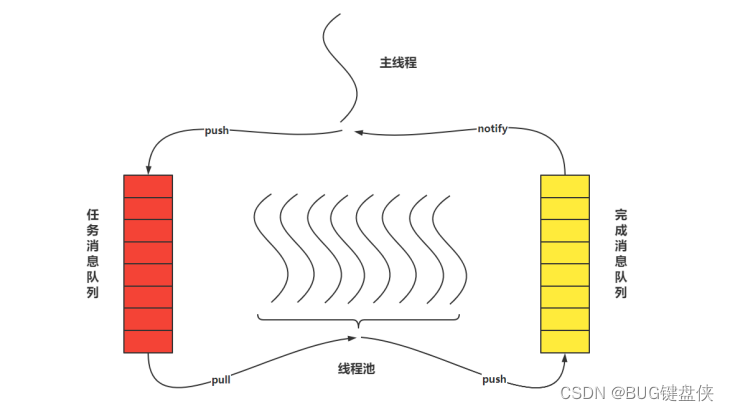
5.3 redis(作为数据库)中线程池-----(网络IO密集型)
5.3.1 使用线程池的前提条件如下图

5.3.2 redis为什么使用线程池?
redis作为数据库使用,客户端请求无非就是读取数据库内容和写入数据库,但是在多个客户端并发请求的情况下,redis服务器就 IO读写 和 数据解析压缩 的压力就很大。
5.3.3 redis使用线程池流程
redis服务器把客户端的读写事件放入任务队列(server.clients_pending),一次事件循环当中,每个事件只有一个fd,不可能出现两个事件有相同的fd(红黑树存放fd)。按照负载均衡的方式放入 IO线程(read decode,encode wite)处理,每个IO线程有一个专属队列,这里可以避免给server.clients_pending队列加锁,主线程(单线程)它也可以作为IO线程(既是生产者也是消费者),等待全部IO线程处理完后再进行业务逻辑处理(compute)。因为redis的数据结构非常高效,因此compute这部分不用线程池优化。

线程池作用阶段(读写io处理以及数据包解析、压缩)

5.4 skynet 中线程池(cpu密集型)

线程池作用阶段


















 498
498

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









