







 本文介绍了在不同数据集条件下如何选择合适的机器学习模型,并针对过拟合与欠拟合问题提出了模型优化策略。文中详细阐述了从数据样本量、特征维度到模型参数选择的方法论。
本文介绍了在不同数据集条件下如何选择合适的机器学习模型,并针对过拟合与欠拟合问题提出了模型优化策略。文中详细阐述了从数据样本量、特征维度到模型参数选择的方法论。
这套笔记是跟着七月算法四月机器学习班的学习而记录的,主要记一下我再学习机器学习的时候一些概念比较模糊的地方,具体课程参考七月算法官网:http://www.julyedu.com/
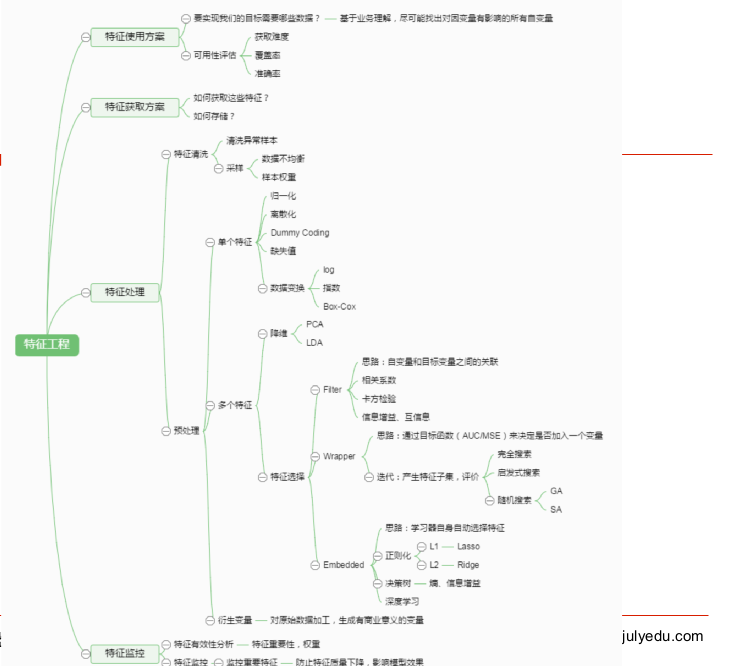
特征工程总结
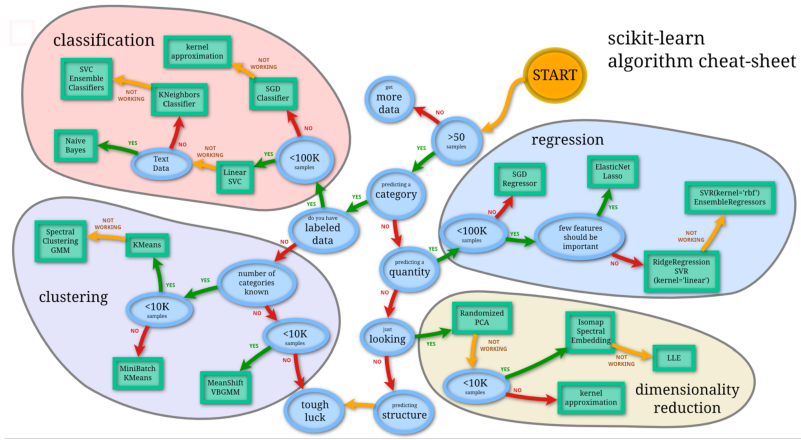
模型选择
- 没有那种模型是万能的,在特定情况下选择适合的模型
对这幅图做如下解释
从start开始,先看数据的训练样本
在数据样本比较小的情况下,需要添加更多样本或放弃机器学习,用人工规则处理。
当样本足够时:并且是连续值问题,采用回归方法解决。
果是离散样本分类,则使用分类模型。当分类样本数量不大,用线性SVM解决,如果是文本数据分类,使用朴素贝叶斯; 如果不是,使用LR或SVM等。如果样本很大,用SVM就很难,它收敛时间非常长,这样,使用随机梯度下降或核估计方法。
如果是回归问题:
在样本数据非常小的情况下,采用线性方法,如果样本数据足够,使用随机梯度下降等方法
如果样本维度很高,使用降维方法(无监督学习)
如果无标签,使用聚类方法。
已知模型,选择参数
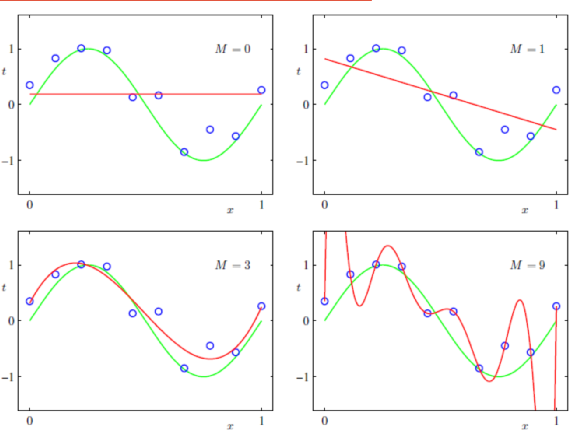
需要考虑参数和次数
- 参数选择方法:
将数据划分
70% 训练集,用于建模
20% 交叉验证, 参数选择
10% 测试集, 效果的评估
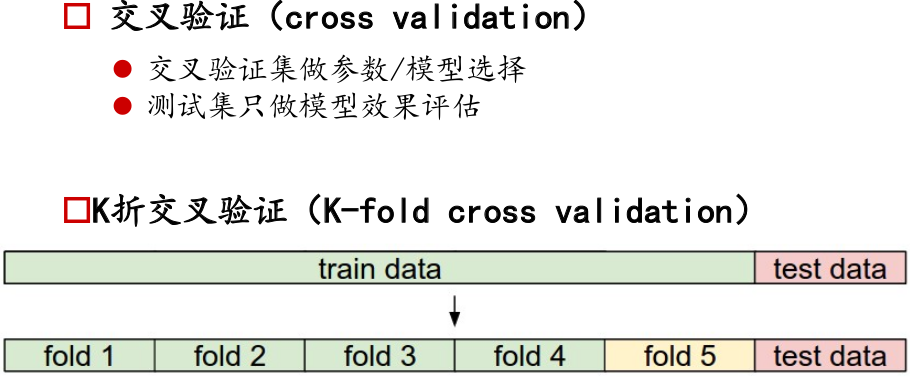
K折交叉验证,
将训练集分为k个部分,轮番用其中某一折作为验证集,前面其他作为训练集。每折用不同测模型,用验证集验证。
模型参数含义
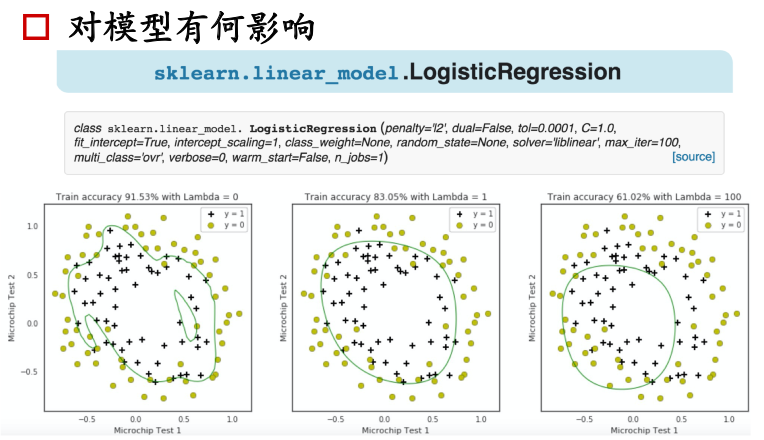
超参数的选取
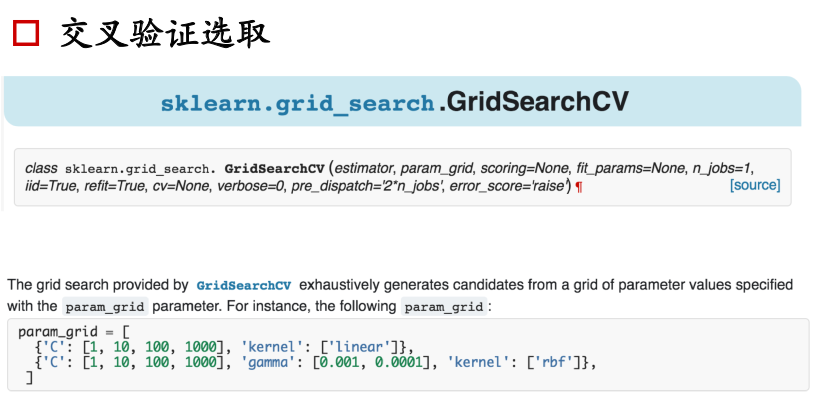
模型效果优化
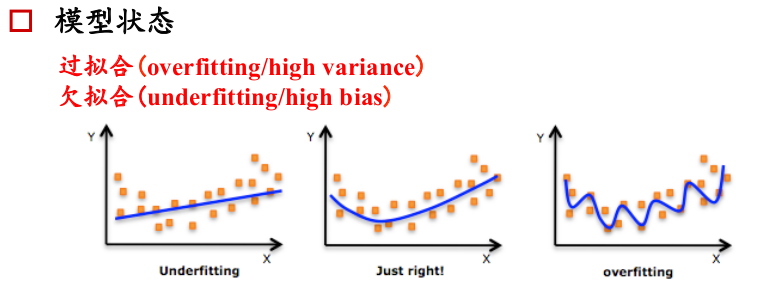
过拟合:高波动
欠拟合:高偏差
工程判定模型处于什么状态:学习曲线
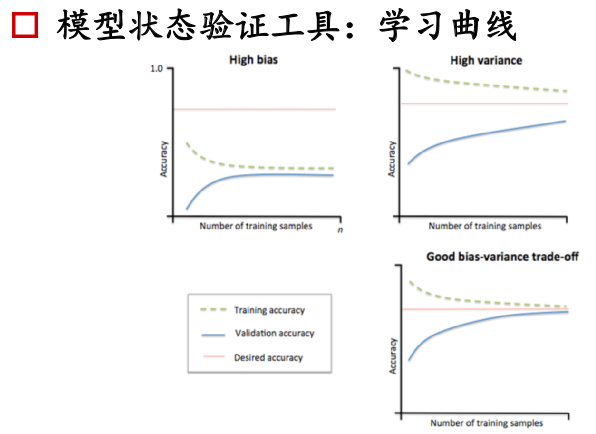
横坐标:不同量的训练样本
纵坐标:准确度。
实线表示交叉验证集的准确度,


对错分样本的处理

模型融合:比如,不同模型一起投票


bagging每次不用全部的数据集。用不同模型判别(比如n个模型给的结果取多数的判定结果)。减小波动


Adboost给分错的样本更高的权重,努力学习错分样本。
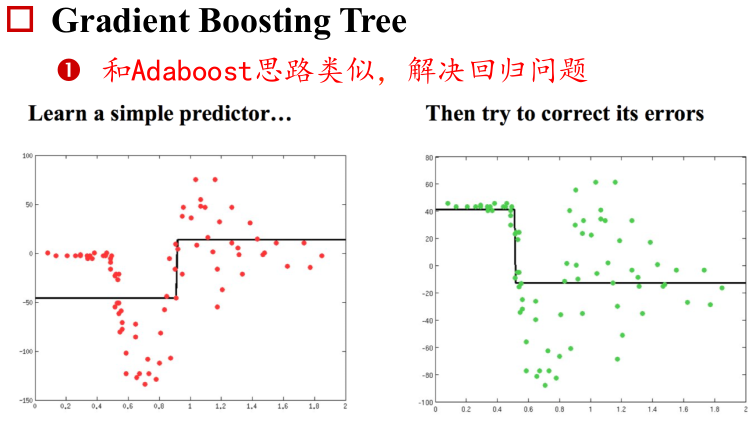
参考资料:
七月算法:机器学习四月班:http://www.julyedu.com/
图片来自于课程PPT


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









