







一、目的
之前的几篇博文中我们介绍了语音交互框架、语音SDK设计,本篇博文中重点介绍语音交互中的ONESHOT设计。
那什么是语音ONESHOT呢?简单的讲,就是用户唤醒词与要识别的内容连说。
传统的语音交互模式一般是这种情形:
你好小乐(--唤醒提示音播放--提示音播放完毕--)我想听歌---等待对话结果
播放提示音期间不拾音
此种交互方式的优点是语音唤醒后,由于先放唤醒提示音,此过程中设备不拾音,所以不会误拾音;当然缺点也很明显,对于急性子的用户,可能没等提示音播放完毕就开始说话,导致识别收到的音频头部缺失,导致用户体验很差。
那ONESHOT交互模式是怎样的呢?
你好小乐,我想听歌
此刻提示音也正在播放
呈现给用户的体验是,唤醒后直接说话,无论设备会不会播报唤醒提示音。
那么这种实现有哪些技术挑战呢?
设备必须支持录取播放回路音频,用于回声消除处理,并且此项处理必须能很好的消除回声。
二、分析
下面是两个实际音频录音,内容都是“你好小乐,我想听歌”
慢交互
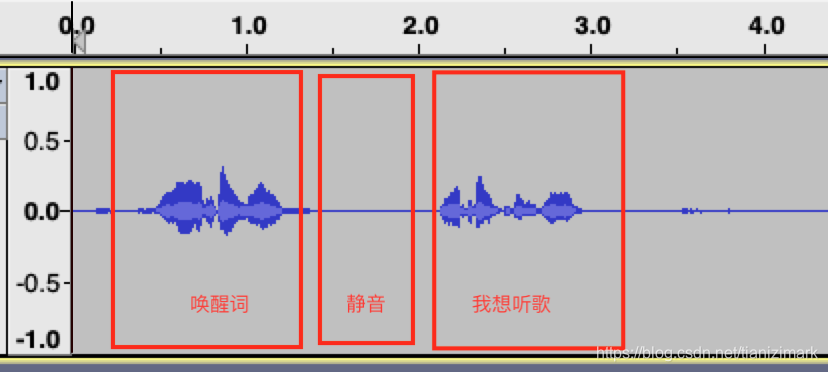
上图可以看到,唤醒和我想听歌之间有接近1s的静音,这个时间内对于传统交互模式下,有可能是在播放提示音。在ONESHOT交互模式下可能只是用户的说话停顿(突然忘词)。
快交互
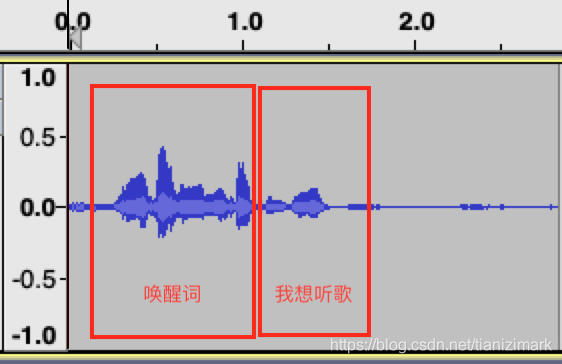
上图可以看到,唤醒和我想听歌之间基本没有停顿,用户一句话说出意图。并且我想听歌这句话说出的时候设备也在播放提示音。
三、设计
那怎么一种ONESHOT才是一种合理的交互方式呢?作者认为ONESHOT模式下要同时兼容慢交互和快交互这两种情形。
由于一些技术瓶颈,例如唤醒某些时候可能会提前唤醒,导致唤醒时刻开始获取的音频数据可能包含部分唤醒残留音,如下图:

上图可以看到唤醒残留音部分与我想听歌间有较长的静音,那么在设计ONESHOT的时候如果能够过滤掉残留音,只将后面的我想听歌的音频进行识别,一样可以完美的输出识别结果。
至于如何过滤残留音,相信聪明的你应该已经知道怎么做了,哈哈,这边就不详细描述了。
至此,如何实现ONESHOT交互方式也介绍完毕。

















 847
847

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









