









要构建SSG静态站点时,一般为了方便增加algolia搜索框,但这里algolia配置使用时用很多的坑,折腾了我好几天,网上没有一个可用的教程。
自己弄了几天,终于搞明白里面的道道了,现在分享出来给大家,避免踩坑。
前面注册的就不用了。
比如:用的docusaurus、vitepress构建SSG静态站点,安装algolia依赖的,都会有algolia的设置。此处不讲这些简单的。
先看效果图:
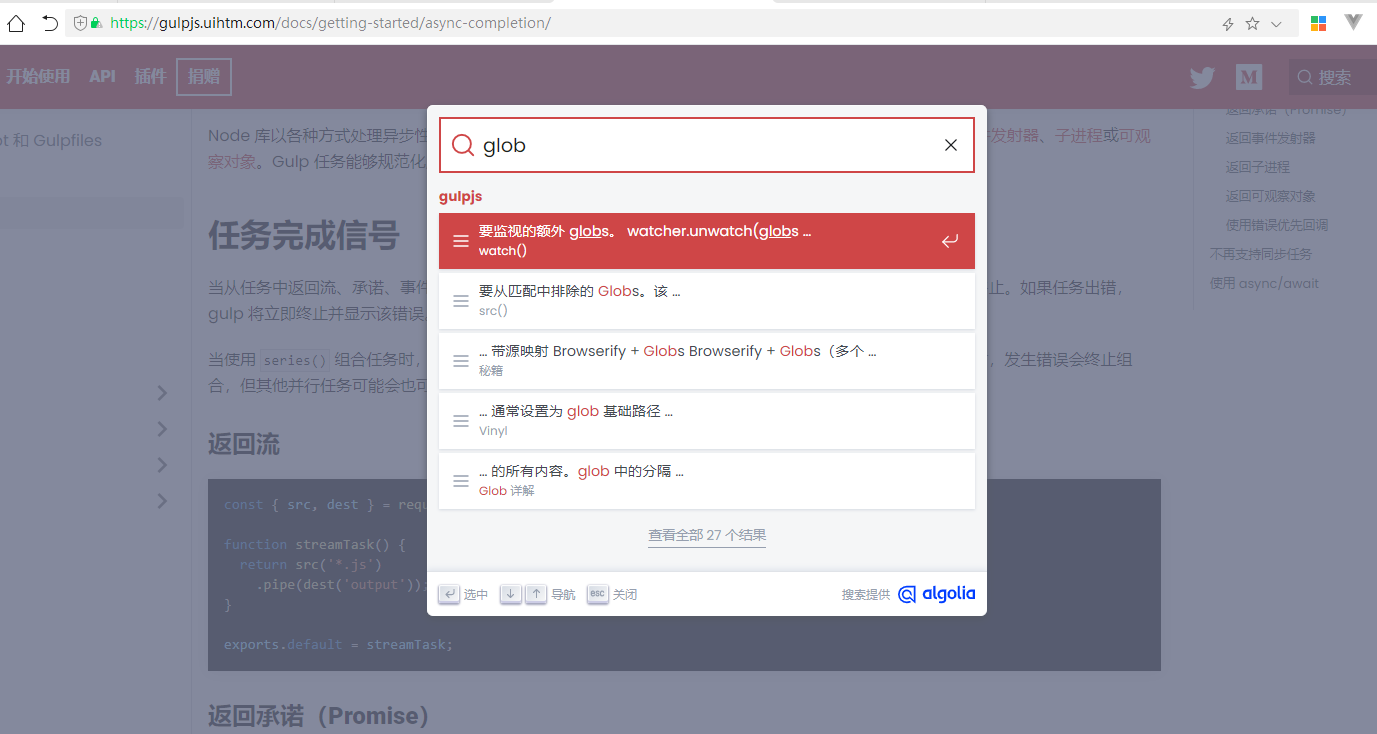
algolia设置步骤
- docusaurus、vitepress设置appid、key、抓取配置等
- algolia新建app
- 创建爬虫
- 设置索引
实操说明
下面以我自构建的一个gulp文档静态站点:https://gulpjs.uihtm.com 为演示,一步步怎么设置完成的。
静态站配置algolia密钥、索引名、appid
本站点是使用docusaurus来构建静态站点的,在docusaurus.config.js配置文件里有一个设置algolia的appId、apiKey、indexName
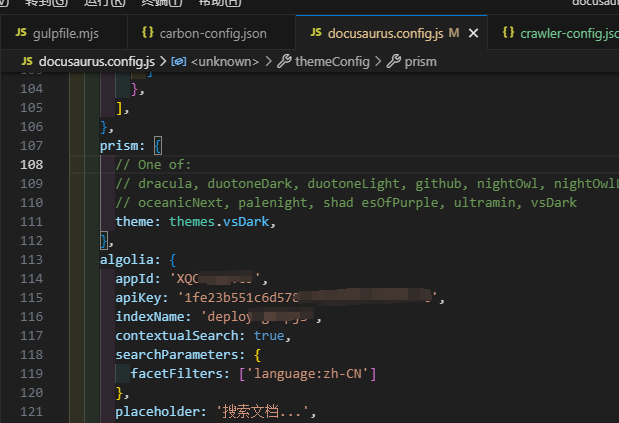
algolia: {
appId: 'XQC8CUNYC9',
apiKey: '1fe23b551c6d578e296aeb91ef858c2e',
indexName: 'deploy-gulpjs',
contextualSearch: true,
searchParameters: {
facetFilters: ['language:zh-CN']
}
}
这里的appId、apiKey、indexName对应的是algolia后台:https://dashboard.algolia.com/ 面板里的。
先在后台创建应用才能得到appid、apikey,
创建应用
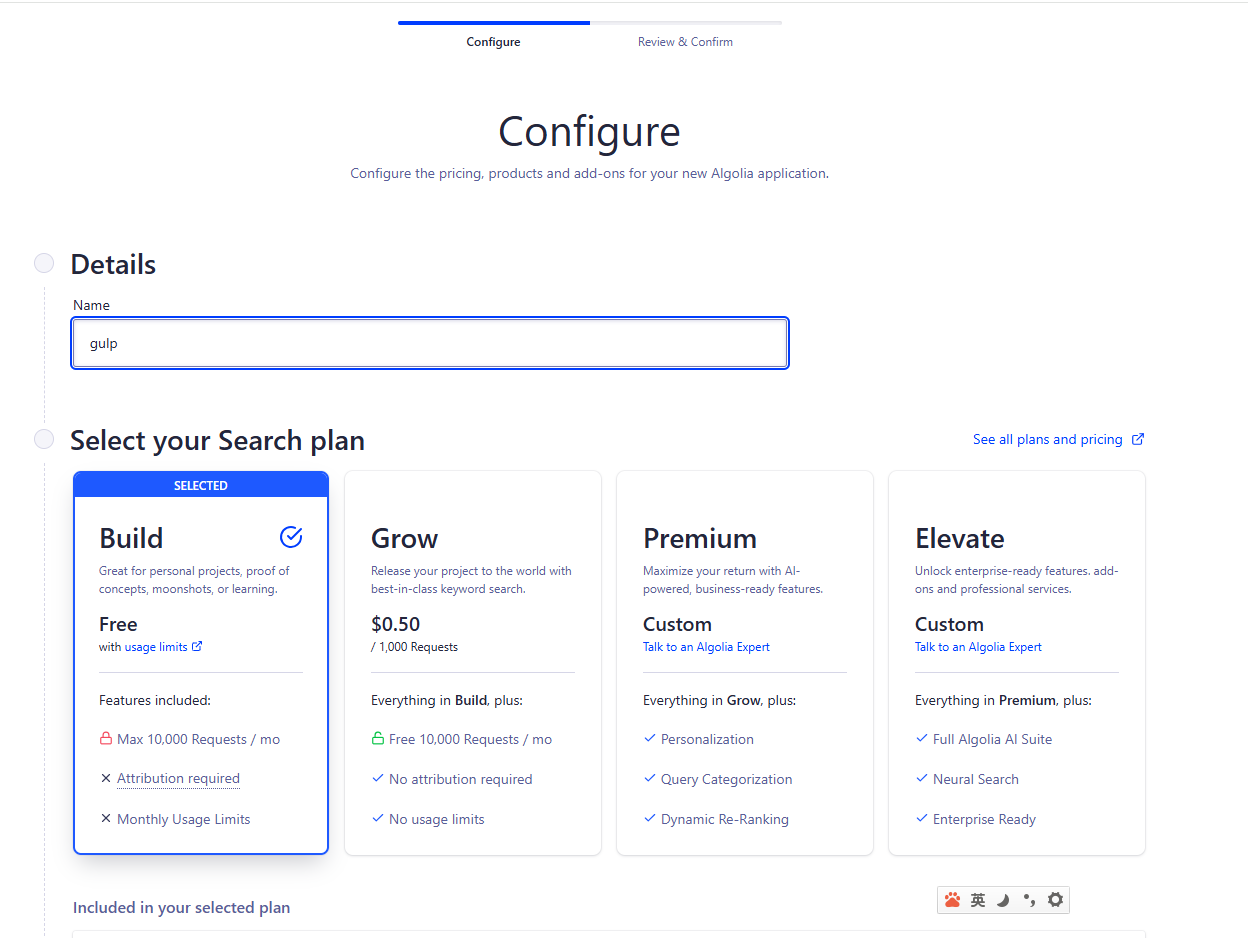
选择地域区,随便选一个
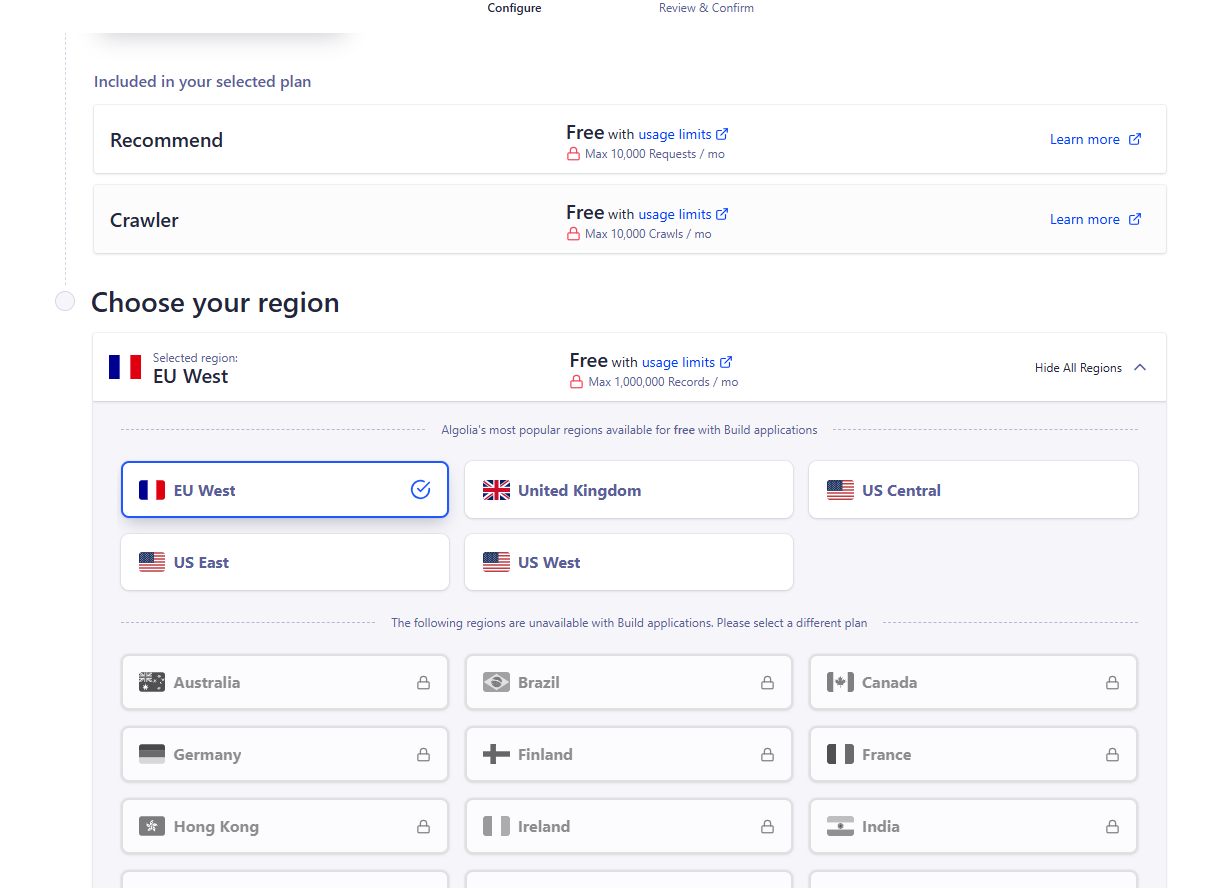
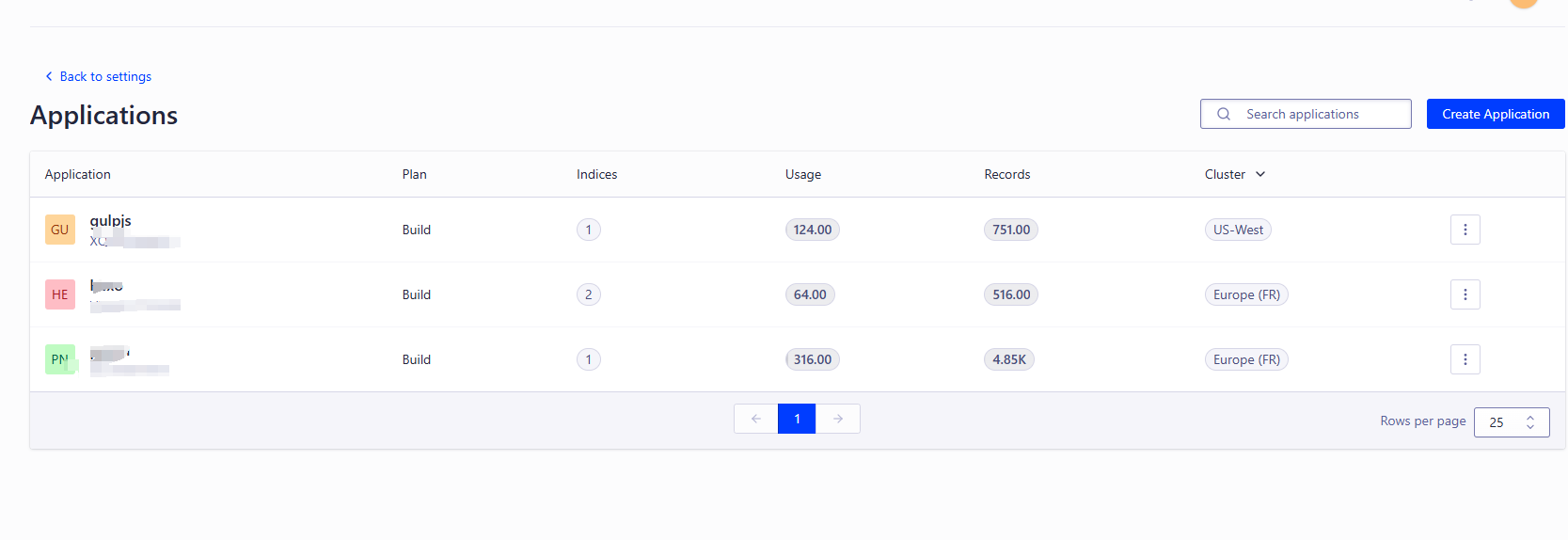
创建完点击应用就可以对相应应用设置
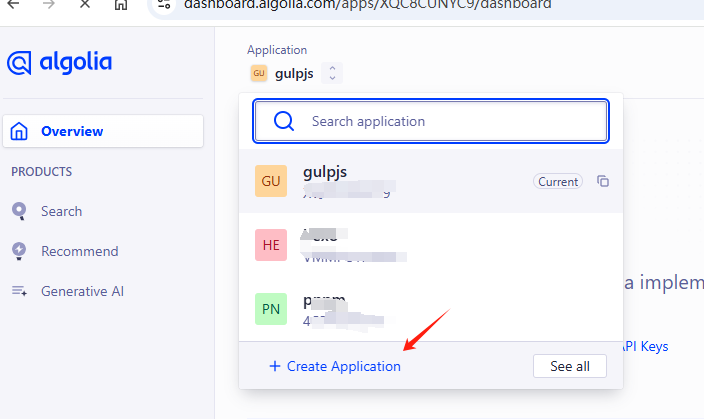
apikey在这里:Search API Key
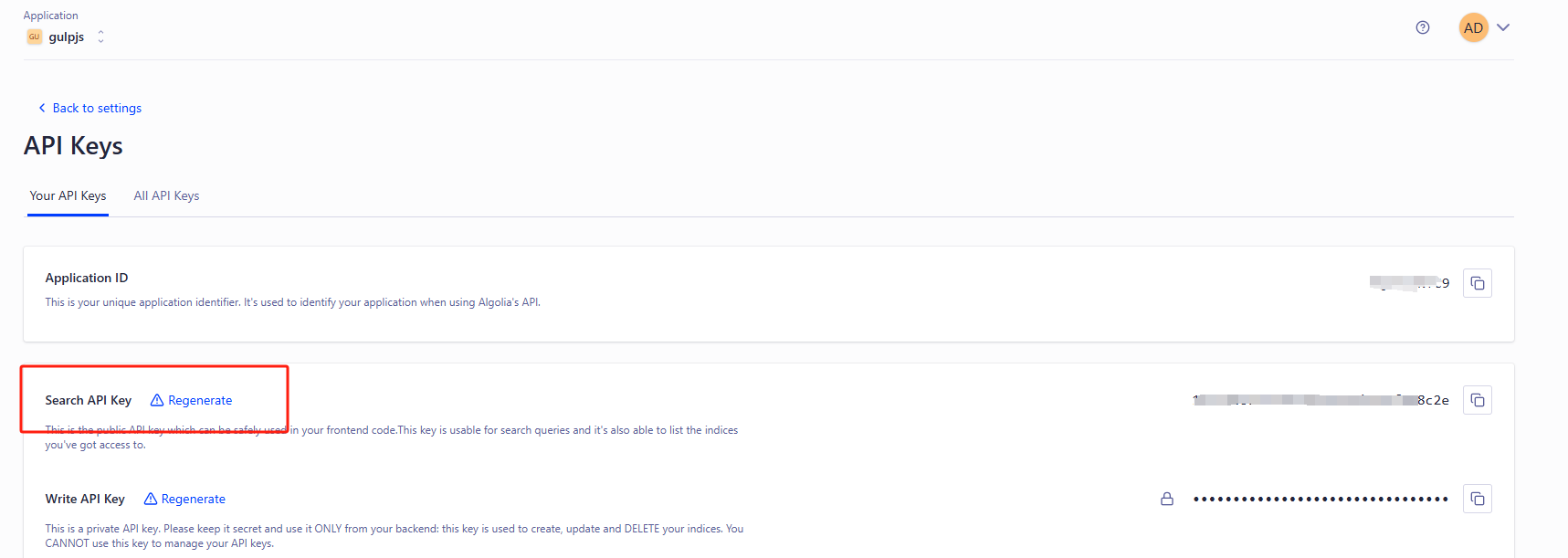
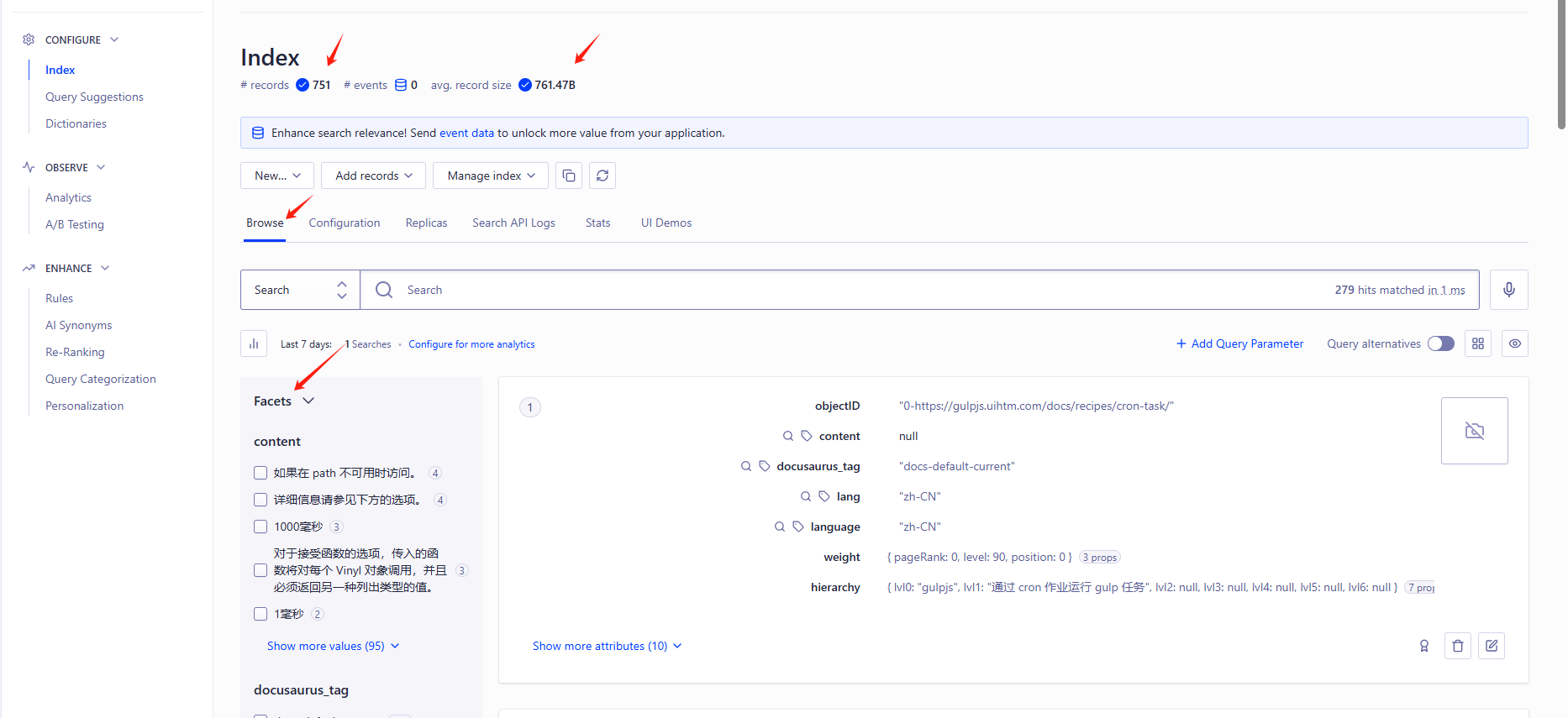
algolia 索引index创建
点击这里的serach就会到index页面,
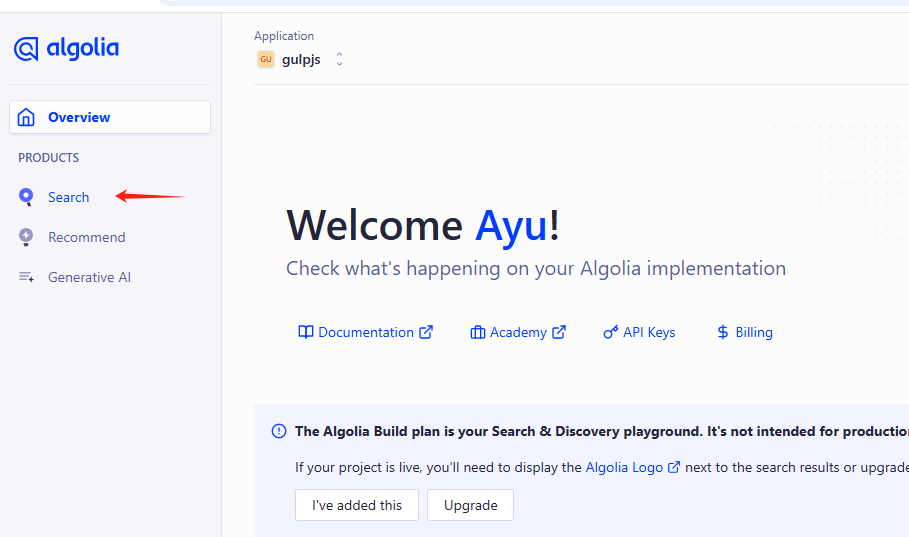
默认索引里的,records,record size是空的0,点击event data进去,再点Crawler爬取设置
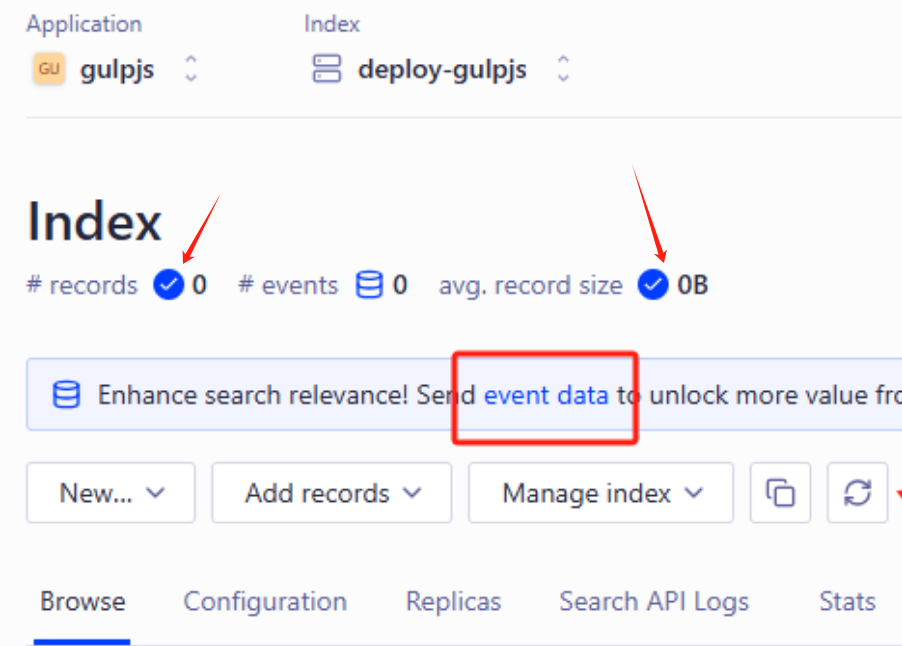
设置爬虫
创建爬虫,爬虫可以创建多个的,其实只需要一个就够了。到时验证域名,点击爬虫名称,进入爬取设置
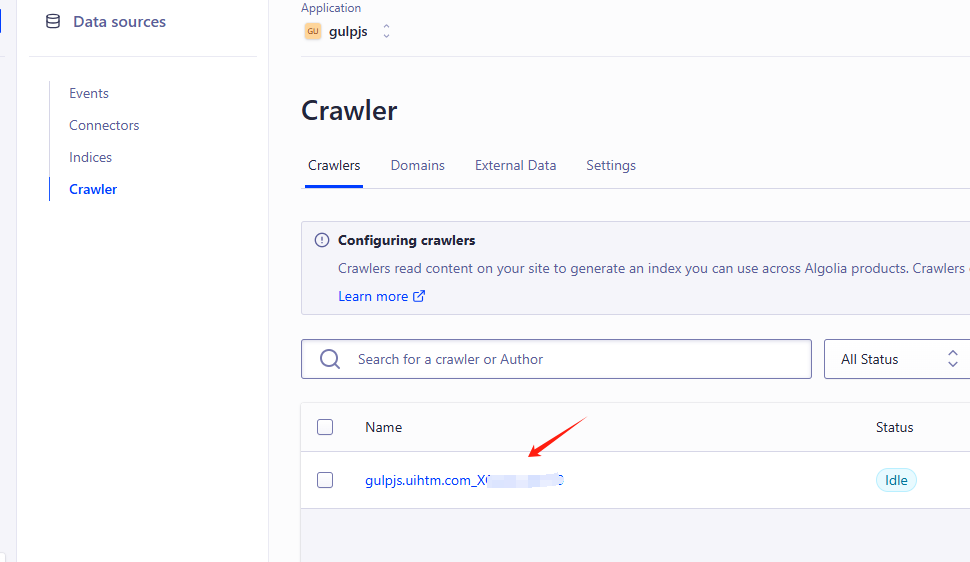
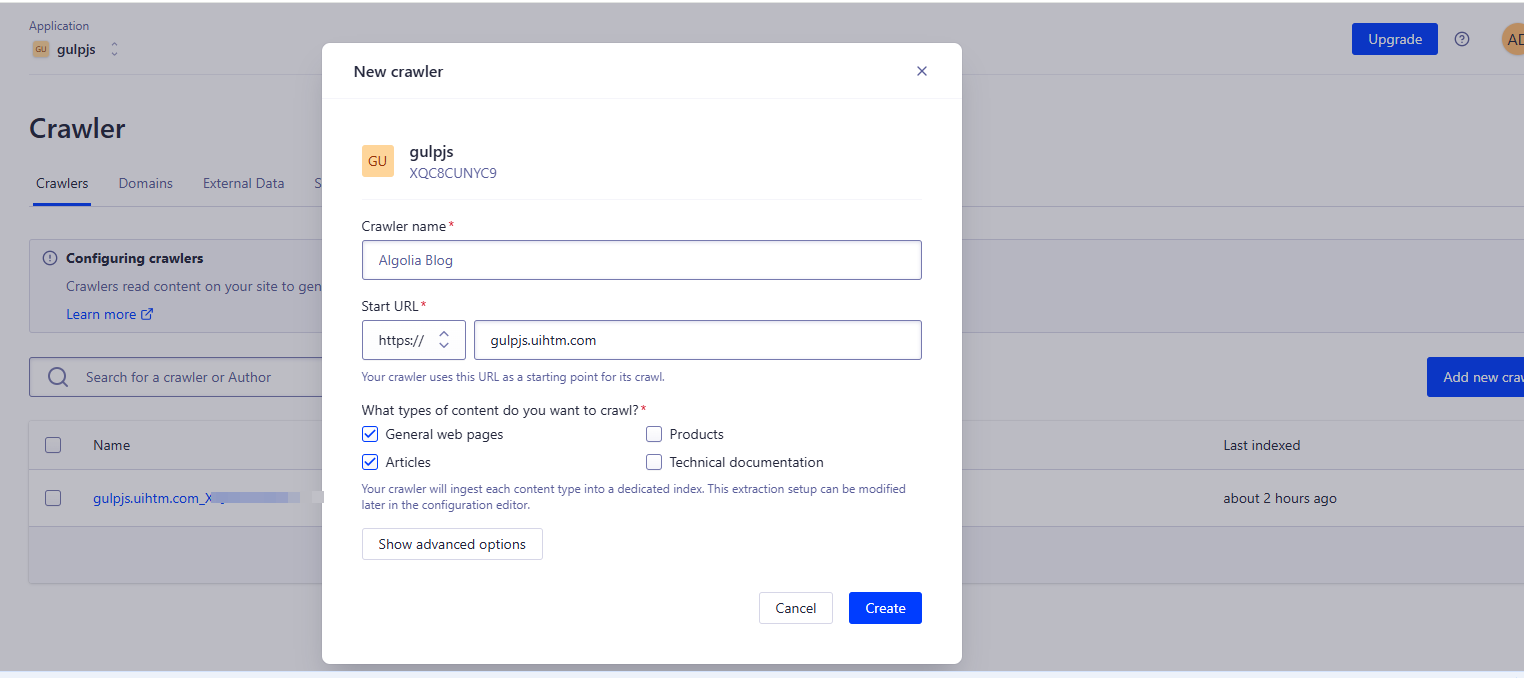
点击Resume crawling 会自动爬取域名里的网址,爬取前可以设置,爬取的开始域名,最有url数和爬取周期
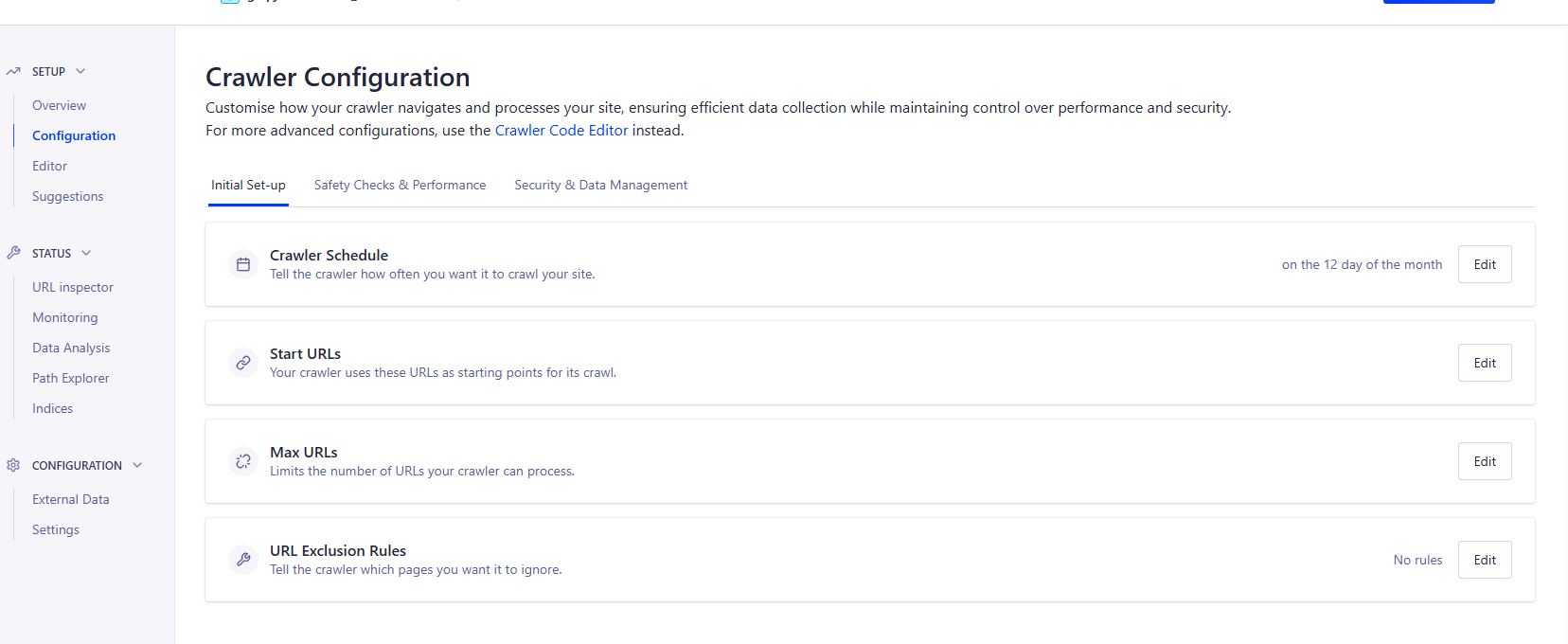
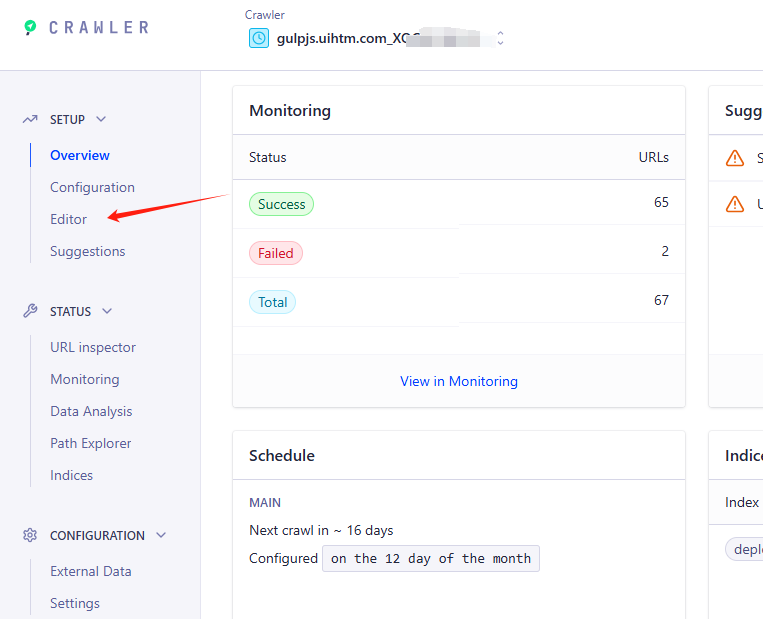
这里就是爬取完的显示,这是有爬取完成的url数量,url里的记录数,
注意这里的Indices,
- 这里有个名称为:
deploy-gulpjs,的索引名。是填到静态站点配置里的, - 索引是可以有多个
- 如果没设置edtor,爬取出来的索引是随机名,后面可以重命名
- 注意索引有没有records记录
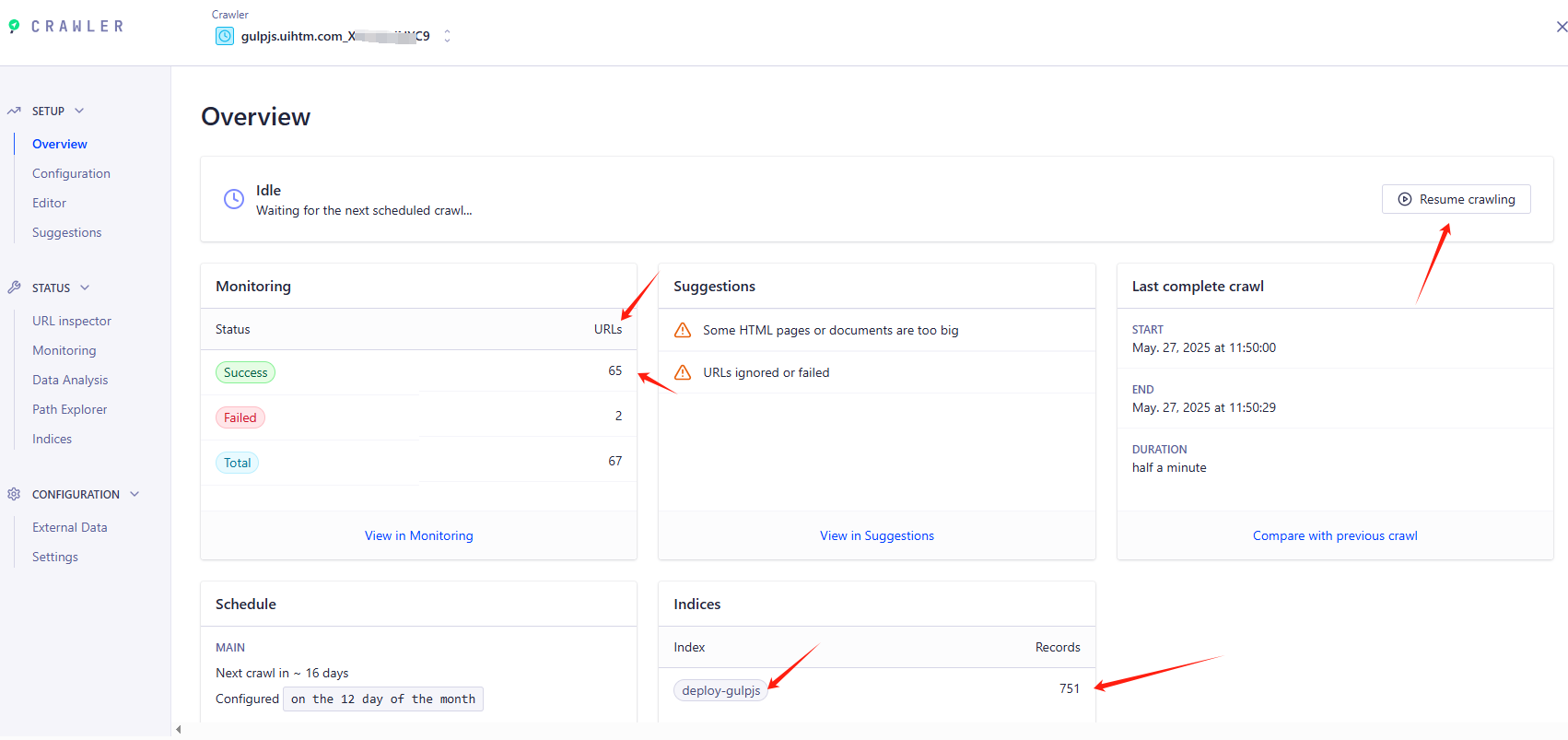
在爬取过程,有一个deploy-gulpjs.tmp的名称,在爬完后自动消失。
自定义爬虫设置
在这里点击editor,可以设置测试爬取内容等配置。
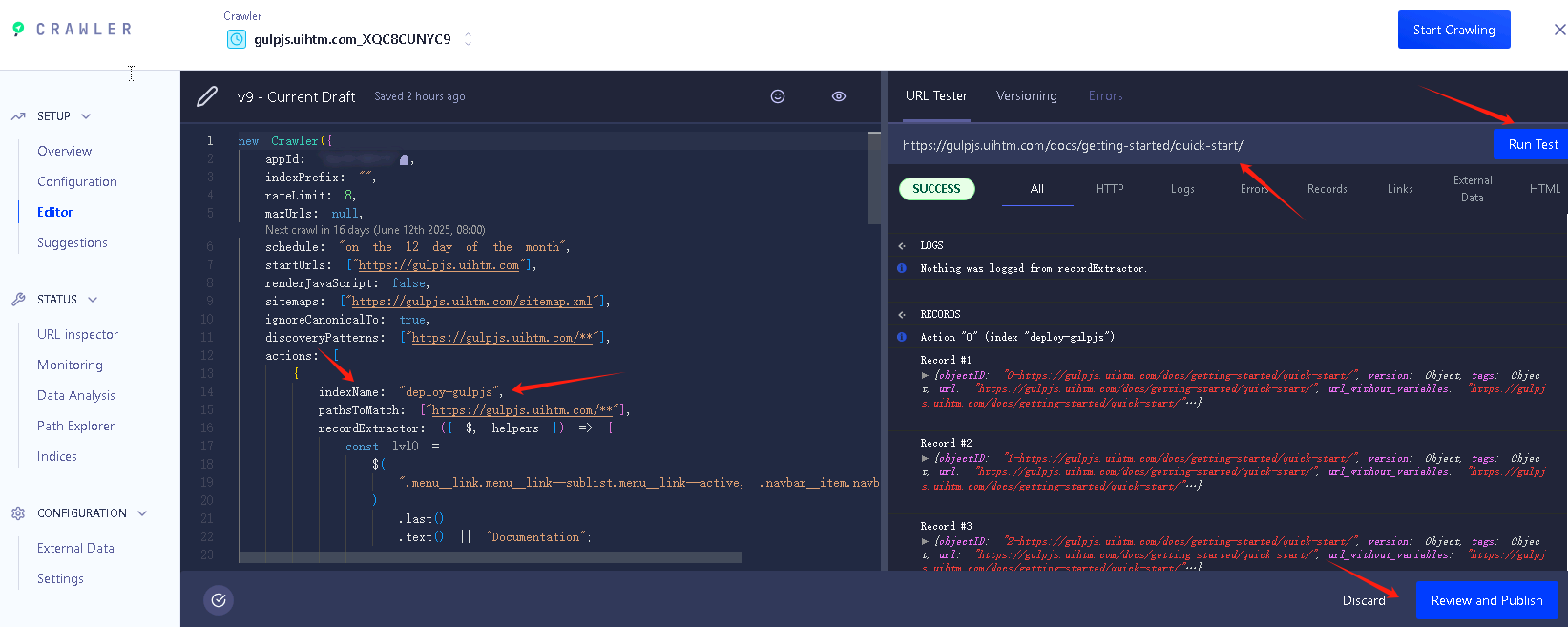
可以编辑里面的json参数设置爬取。代码里的indexName: "deploy-gulpjs",就是我设置爬取后生成的索引名称,还有一点是站点语言,一般
new Crawler({
appId: "xxxxxx",
indexPrefix: "",
rateLimit: 8,
maxUrls: null,
schedule: "on the 12 day of the month",
startUrls: ["https://gulpjs.uihtm.com"],
renderJavaScript: false,
sitemaps: ["https://gulpjs.uihtm.com/sitemap.xml"],
ignoreCanonicalTo: true,
discoveryPatterns: ["https://gulpjs.uihtm.com/**"],
actions: [
{
indexName: "deploy-gulpjs",
pathsToMatch: ["https://gulpjs.uihtm.com/**"],
recordExtractor: ({ $, helpers }) => {
const lvl0 =
$(
".menu__link.menu__link--sublist.menu__link--active, .navbar__item.navbar__link--active",
)
.last()
.text() || "Documentation";
const records = helpers.docsearch({
recordProps: {
lvl0: {
selectors: "",
defaultValue: "gulpjs",
},
lvl1: ["header h1", "article h1"],
lvl2: "article h2",
lvl3: "article h3",
lvl4: "article h4",
lvl5: "article h5, article td:first-child",
lvl6: "article h6",
content: "article p, article li, article td:last-child",
},
aggregateContent: true,
recordVersion: "v3",
});
// 设置中文
records.forEach((record) => {
record.lang = "zh-CN";
});
return records;
},
},
],
safetyChecks: { beforeIndexPublishing: { maxLostRecordsPercentage: 30 } },
initialIndexSettings: {
deployGulpjs: {
attributesForFaceting: [
"type",
"lang",
"language",
"version",
"docusaurus_tag",
],
attributesToRetrieve: [
"hierarchy",
"content",
"anchor",
"url",
"url_without_anchor",
"type",
],
attributesToHighlight: ["hierarchy", "content"],
attributesToSnippet: ["content:10"],
camelCaseAttributes: ["hierarchy", "content"],
searchableAttributes: [
"unordered(hierarchy.lvl0)",
"unordered(hierarchy.lvl1)",
"unordered(hierarchy.lvl2)",
"unordered(hierarchy.lvl3)",
"unordered(hierarchy.lvl4)",
"unordered(hierarchy.lvl5)",
"unordered(hierarchy.lvl6)",
"content",
],
distinct: true,
attributeForDistinct: "url",
customRanking: [
"desc(weight.pageRank)",
"desc(weight.level)",
"asc(weight.position)",
],
ranking: [
"words",
"filters",
"typo",
"attribute",
"proximity",
"exact",
"custom",
],
highlightPreTag: '<span class="algolia-docsearch-suggestion--highlight">',
highlightPostTag: "</span>",
minWordSizefor1Typo: 3,
minWordSizefor2Typos: 7,
allowTyposOnNumericTokens: false,
minProximity: 1,
ignorePlurals: true,
advancedSyntax: true,
attributeCriteriaComputedByMinProximity: true,
removeWordsIfNoResults: "allOptional",
},
},
apiKey: "xxxxxxx",
});
看你的静态站点html是设置什么语言,lang="zh-CN",那对应要json参数设置爬取
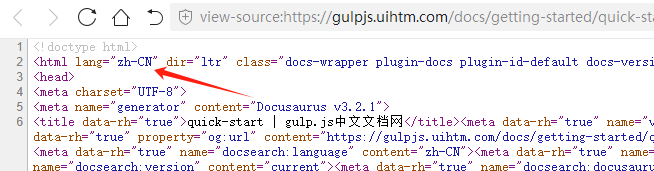
// 设置中文
records.forEach((record) => {
record.lang = "zh-CN";
});
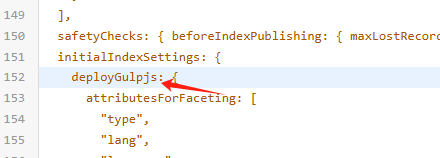

重点,索引设置
索引设置里的Searchable attributes 、Facets、Language
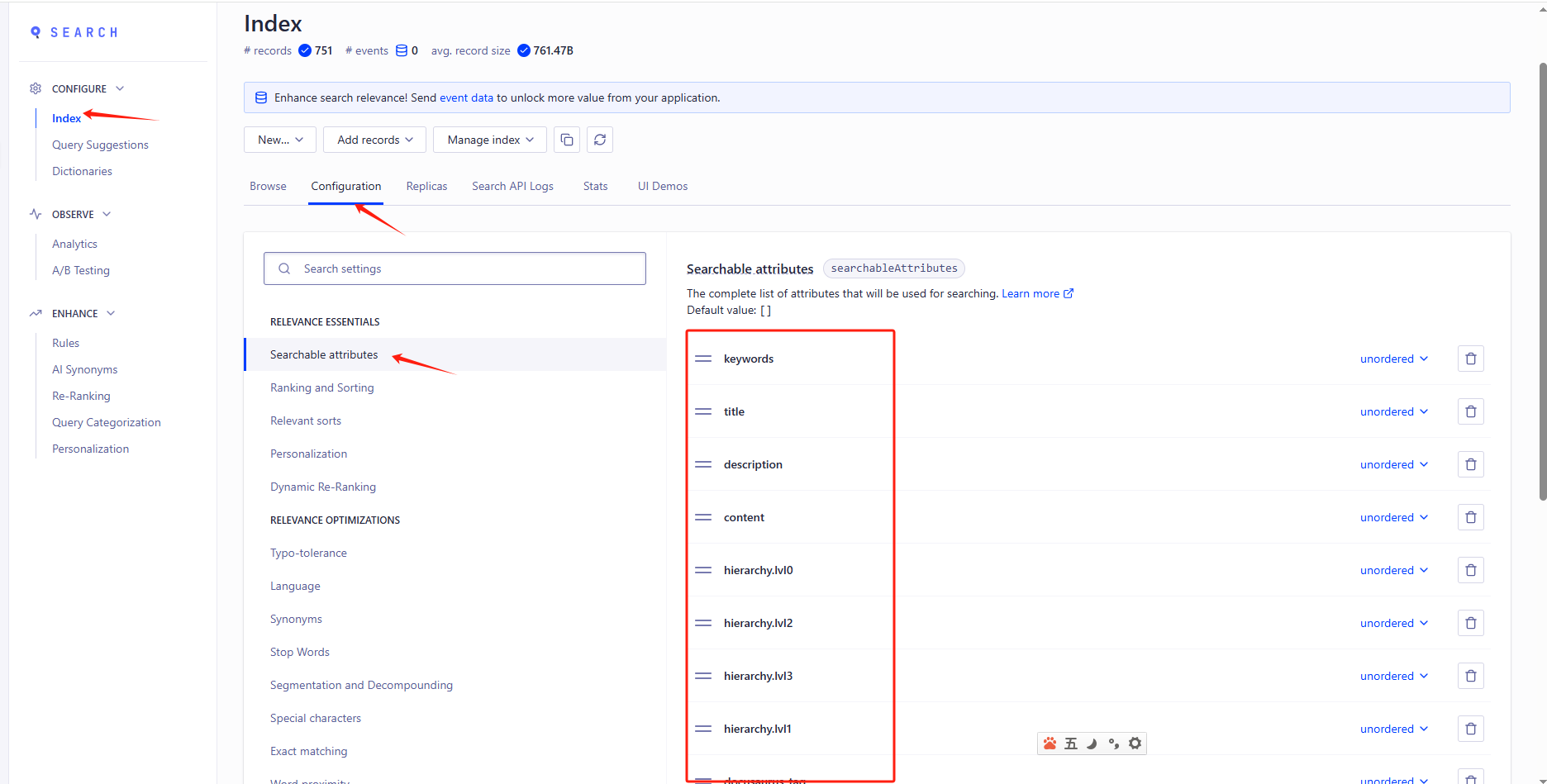
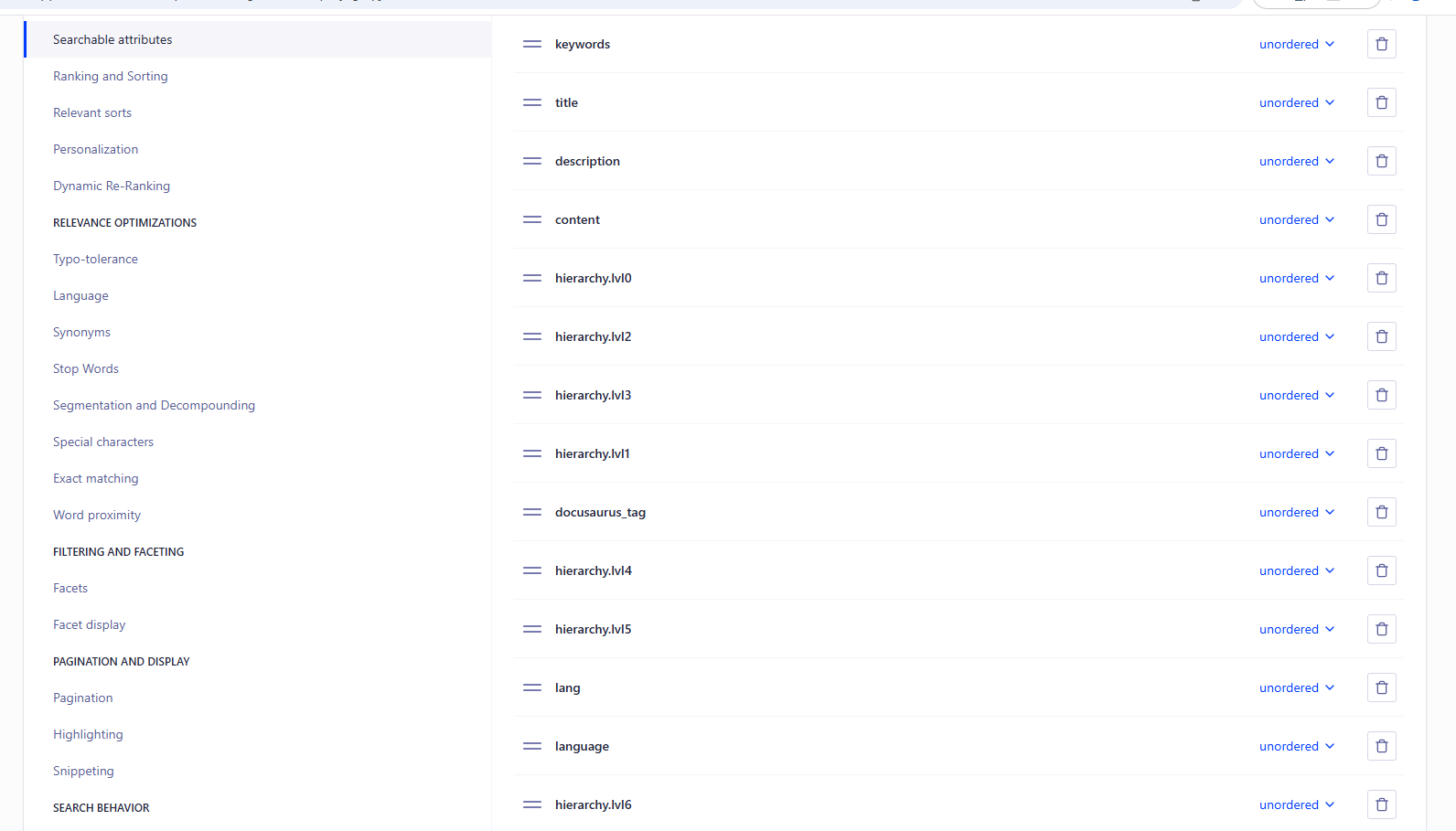
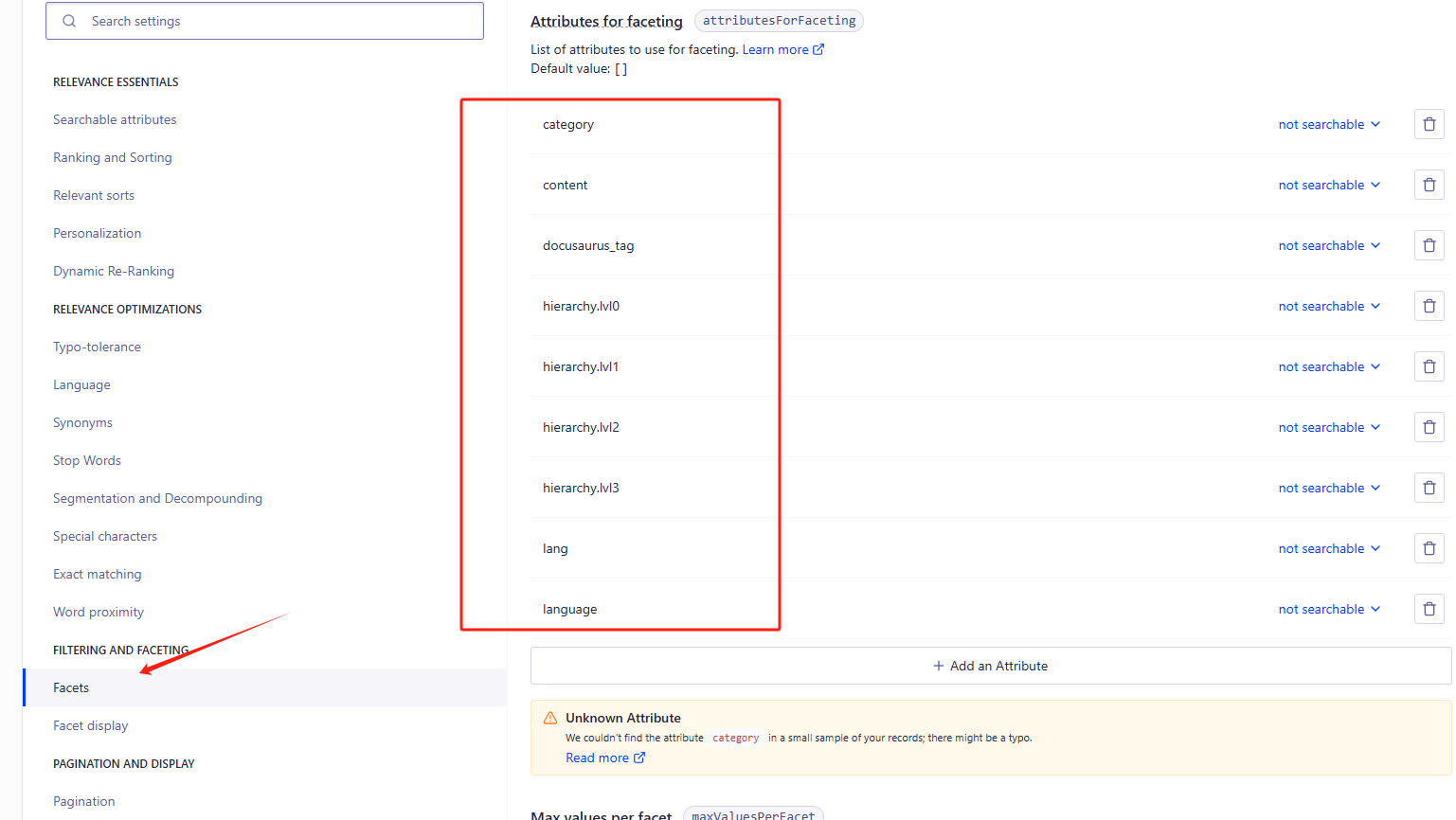
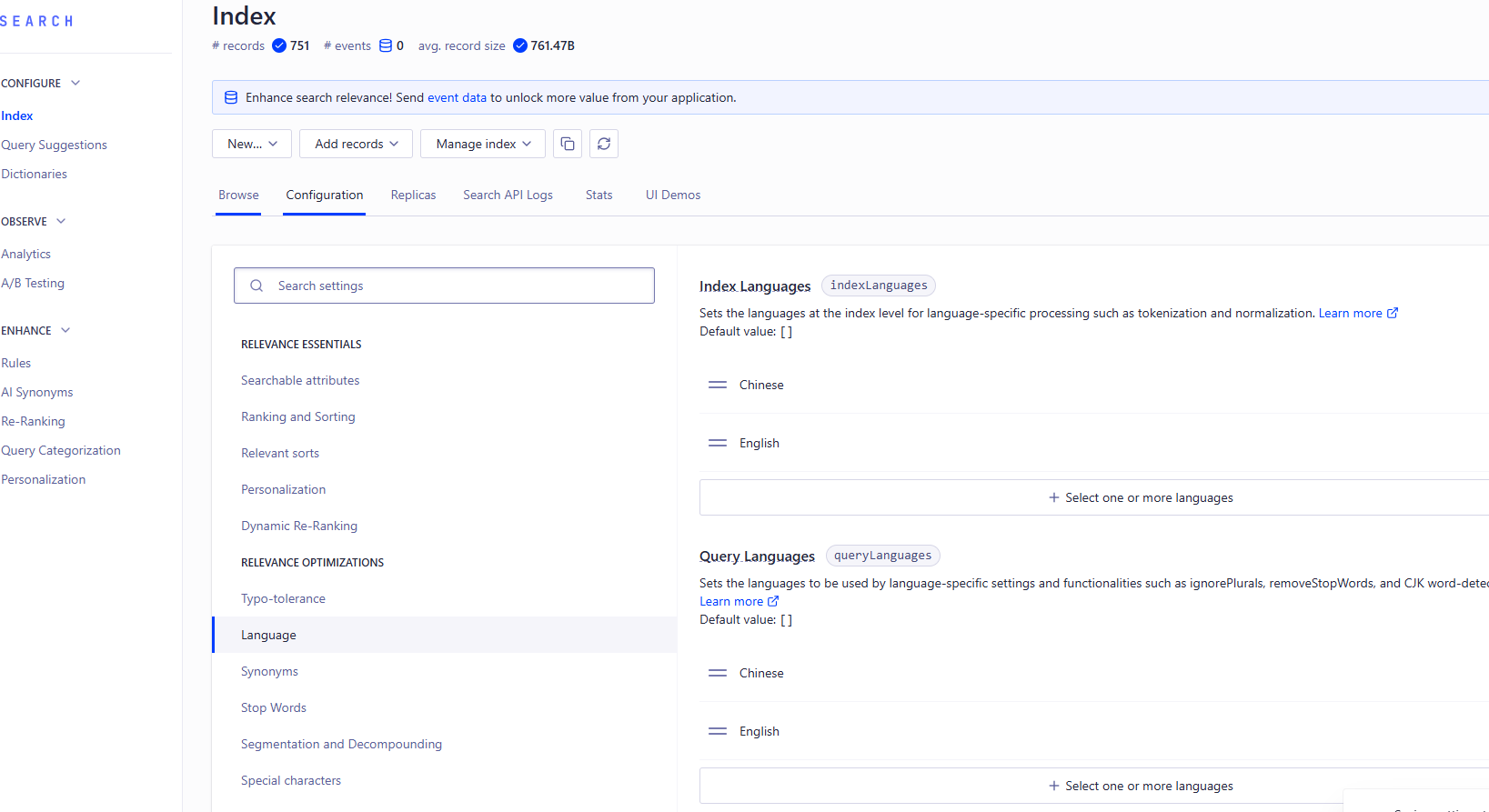
最后有这样的数据出来就大功告成了。



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











