







1 设计阶段的优化
1.1 表设计
1.1.1 范式化
数据库设计三范式定义:
1. 第一范式:每个字段只包含最小的信息属性。
例如常见的学号:入学年份+班级+编号,是不符合第一范式的,需要将其拆解为:入学年份、班级、编号。
2. 第二范式:(在满足第一范式基础上)模型含有主键,非主键字段依赖主键。
3. 第三范式:(在满足第二范式基础上)模型非主键字段不能相互依赖。
例如订单表,一般来说订单表的主键是订单号。在此表中,字段下单时间、客户ID是符合第二范式的,而客户姓名这个字段就不满足第二范式,应当放入客户表内,组成客户ID客户姓名。
范式化的设计能有效降低数据冗余,更新方便快速,降低了数据不一致的风险。故常见于联机交易型的数据库。
1.1.2 反范式化
有意不符合范式化的设计,常见于反第二第三范式。
符合三范式的设计在降低冗余的同时也带来了问题。如果需要对数据进行加工处理(例如具有订单表、客户表,需要统计某个年龄的客户的订单总金额)的时候,需要不断进行关联操作。当订单数量极为庞大的时候,这个关联操作所需要消耗的资源将会相当巨大,导致查询性能低下。因此在数据仓库的海量数据的处理中,常使用反范式化的方式进行设计来提高性能,用空间换取时间。例如在订单表内添加上下订单的客户的生日,则只需直接执行筛选即可。
反范式化的设计并没有定势,需要视具体的业务而定,通常是将查询较多或者查询时候关联消耗过大的字段添加进来作为冗余字段。
1.2 索引的设计
1.2.1 索引的原理
索引是一种建立与表外部用于加快表查询速度的数据结构。商业数据库索引的实现常用B-树/B+树的变种,它通常有三层:根、中间层、叶子。其中每一层内包含的节点块都是按照顺序排列的(对于数字按照大小,字符串则从左往右的字符顺序依次进行比较)。每个节点块内包含着指向实际数据地址的指针。
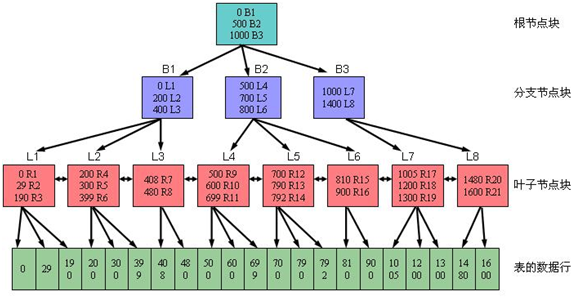
当我们需要进行查询时,会先在索引的树内进行查找,如果是数字,如29,从根节点起往下,寻找最后一个小于他的区间B1,然后再往下L1,R2。在R2内含有指向实际数据地址的指针,数据库再到实际地址获取数据。
如果是字符串,则从左往右,例如ABCDE。从根节点起往下,寻找最后一个小于他的区间B1(A),然后再往下L1(B),R2(CDE)。在R2内含有指向实际数据地址的指针,数据库再到实际地址获取数据。
如果在到实际指针的时候无法定位到具体的哪行,则会对指针指示区域进行行扫描。
组合索引会将字段从左到右拼接起来再进行建立索引。
在我们需要更新数据的时候,数据库在更新表的同时,需要同步更新索引,这样才能保证索引的可用性。
1.2.2 索引的选择原则
由于上述原因,我们在设计表选择索引的时候,首先考虑的是几点:
1. 索引要建立在常用的字段上,以增加使用频率。
2. 索引的建立不是越多越好,过多的索引会占用大量空间,同时更新缓慢。一般3-5个为宜。
3. 索引的字段选择区分度较高的字段。(例如,订单表中订单时间就比订单日期作为索引效率更高)因为分区度较大的索引能够使得索引查询完毕后得到的指针更为精确,不需要继续对表进行一行行扫描。
4. 由于对于组合索引是将字段由左到右进行拼接的。因此,请将区分度较高的字段放置于左侧。(例如性别+客户姓名这个索引效率就比客户姓名+性别低)因为在部分情况下当查询到数据超出前面的字段的限制的时候,那么数据库会自动停止匹配下一个字段,节约索引匹配时间。
1.2.3 索引的维护
同样是根据上述原因当表变化过大的时候,需要重建索引,不然树可能会不平衡,深度过大,降低查询效率。
1.3 分区键
1.3.1 分区键原理
部分数据库具有分区特性,每个分区可以并行执行增加数据处理速度,可以对表进行分区操作,根据分区键内的数据通过特有的散列函数,将数据置于不同的分区内。
散列函数进行数据分区是由一个内置的哈希函数决定的,其接受定义为分区键的列内的值,返回数据库的分区号。
1.3.2 分区键的选择原则
在选择分区键的时候,必须遵循一定原则,较差的分区键设计有可能不仅没有提升数据库性能,反而会由于数据分布不均,频繁跨区操作,大幅降低性能。
1. 列越少越。
2. 效率:整型>字符>小数。
3. 选择分布较为均匀的分区键组合。例如性别、出生月份,像所属省份、出生年份这类就是不适合的。
4. 选择较为常用的字段组合。这个一般数据库会限制分区键必须是主键,比较容易做到。
2 执行阶段的优化
前面讲的是设计的时候的要求,在平时对海量数据进行操作的时候,SQL语句的优化也极为重要。
2.1 语句
很多人喜欢使用一条语句将所有查询和关联动作执行完毕,但是这是不好的习惯,过于复杂的语句会导致优化器在进行优化的时候根据数据库情况自行选择执行计划,有时候会出现较为低效的执行计划;同时代码的可读性也会较差。因此请将复杂语句拆解开来,每一步之间使用临时表进行存储。
2.2 匹配条件
2.2.1 匹配时候不能对字段使用函数
例如:WHERELENGTH(NAME)=5在作为匹配条件的时候会导致索引失效,触发全表扫描。
2.2.2 避免使用子查询匹配
很多人在编写SQL语句的时候经常使用子查询,但是很多时候在数据库SQL优化器解析的时候,会将子查询查询到的每一行结果提取出来转换成次查询,类似于IN语句。在海量数据处理中,当子查询的结果数据量较大的时候,会导致整个执行语句转换为成千上万次查询,效率极低。
因此在遇到使用子查询的时候,请将它转换为JOIN语句。
2.3 关联
由于JOIN可以使用表中的索引分区键,效率较高,因此JOIN在大数据量处理的时候较常用到。如果执行效率过低,需要检查数据库的执行计划,查看数据库优化器是否选择了不恰当的关联方式,根据执行计划修改SQL语句。我们常见的关联方式有几种:
2.3.1 Nested-Loop Join(NL Join)嵌套循环连接
对于被连接的数据子集较小的情况,嵌套循环连接是个较好的选择。在嵌套循环中,内表被外表驱动,外表返回的每一行都要在内表中检索找到与它匹配的行,因此整个查询返回的结果集不能太大,要把返回子集较小表的作为外表,而且在内表的连接字段上一定要有索引。
此时,对于被选择为外表的表来说,外表扫描1遍,内表会被扫描N遍。
2.3.2 Merge-Scan Join(MS Join)排序合并连接
通常情况下散列连接的效果都比排序合并连接要好,然而如果行源已经被排过序,在执行排序合并连接时不需要再排序了,这时排序合并连接的性能会优于散列连接。
2.3.3 Hash Join 哈希连接
散列连接是做大数据集连接时的常用方式,优化器使用两个表中较小的表(或数据源)利用连接键在内存中建立散列表,然后扫描较大的表并探测散列表,找出与散列表匹配的行。
这种方式适用于较小的表完全可以放于内存中的情况,这样总成本就是访问两个表的成本之和。但是在表很大的情况下并不能完全放入内存,这时优化器会将它分割成若干不同的分区,不能放入内存的部分就把该分区写入磁盘的临时段,此时要有较大的临时段从而尽量提高I/O 的性能。
但是Hash连接也有特有的问题,首先连接字段长度一般要求相同,然后不能使用于多个谓词,而且对于排序堆、临时表空间消耗较大。
一般来说会先扫描内表,生成Hash数据,再扫描外表。
2.4 执行顺序
由于越在前面的语句执行成本越低,因此我们尽可能遵循几个策略排列我们的语句
1. 降低数据量越大的操作放在越前面。
2. 越是复杂查询成本越大的语句放在越后面。














 360
360











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









