







介绍
最近无聊学了一下python,决定打算用python写一个爬虫,既然要写爬虫,就写一个美女爬虫,养眼,哈哈..你们懂的
准备阶段
- 首先我们必须先找到一个有美女的网站,这里我以7kk网站为例子,
进入首页之后,我们在搜索栏里输入”美女”,然后点击搜索,之后往下拉,点击第二页,这时候看浏览器的地址http://www.7kk.com/search?keyword=美女&page=2 - 然后再点击下一页,我们发现链接的地址都是类似于http://www.7kk.com/search?keyword={keyword}&page={page},
其中{keyword}为搜索的关键字,{page}为页数 - 在chrome浏览器中按f12,然后选中其中任意一张图片,
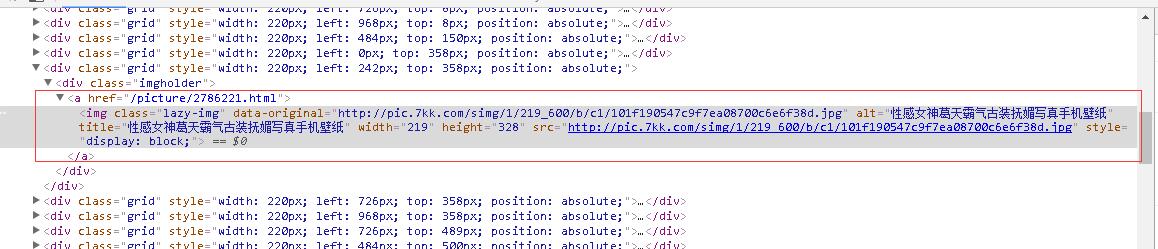
其中图片的地址为http://pic.7kk.com/simg/1/219_600/b/c1/101f190547c9f7ea08700c6e6f38d.jpg,但是我们发现这张图片是缩放图,我们要的是大图,小图清晰图不够,哈哈…. - 我们点击一下图片,进入http://www.7kk.com/picture/2786221.html这个地址其实就是上个截图a标签的href,那么我们就可以通过正则获取到大图的链接
- 在http://www.7kk.com/picture/2786221.html我们再按F12查看一下大图的链接
,其中http://pic.7kk.com/simg/1/995_0/b/c1/101f190547c9f7ea08700c6e6f38d.jpg这个链接正是我们想要的地址
- 准备工作已经做好了,现在开始编码,代码已经放在github上,有需要的自行下载
代码解析
from urllib import request
import re
import os
base_html = 'http://www.7kk.com'
searchPath = '/search?keyword='
keyword = u'美女'
yeshu = 20
path = "e:\\meinv\\美女"
def save_pic(pics):
"""保存图片"""
for p in pics:
fileName = path + os.sep + p.split("/")[-1]
if not os.path.exists(fileName):
with open(fileName, "wb") as fp:
print("正在保存:", fileName)
fp.write(request.urlopen(p).read())
def parse_hrefs():
for i in range(1, yeshu + 1):
# url = base_html + searchPath.replace('page', str(i))
url = (base_html + searchPath + request.quote(keyword.encode("UTF-8"))) + '&page=' + str(i)
print("解析:",url)
page = request.urlopen(url)
html = page.read().decode('UTF-8')
hrefs = re.findall('a href="(/picture/.*?html)"', html, re.S)
print("解析到的hrefs:", hrefs)
parse_pics(hrefs)
def parse_pics(hrefs):
for url in [base_html + item for item in hrefs]:
page = request.urlopen(url)
print("解析:", url)
html = page.read().decode('UTF-8')
# pics.extend(re.findall('a target="_blank" href="(.*?jpg)" class="downpic">下载原图</a>', html, re.S))
pics = re.findall(r'<img src="(http[^\"]*?jpg)" alt=".*?">', html, re.S)
print("解析的图片url:", pics)
save_pic(pics)
def main():
if not os.path.exists(path):
os.mkdir(path)
parse_hrefs()
if __name__ == '__main__':
main()www7kkcom.py
这个程序主要用于爬取www.7kk.com这个网站的图片
全局变量介绍
- base_html 7kk首页网址
- searchPath 查询路径
- keyword 查询的关键词
- yeshu 查询查询的页面
- path 本地存图片的路径
爬虫的完整路径
http://www.7kk.com/search?keyword={keyword}&page={page}
运行
python www7kkcom.py
打赏
如果觉得我的文章写的好的话,有钱就捧个钱场,没钱就给我点个赞

















 2269
2269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言










{kind=link}
{kind=link}