







Hadoop学习路上的那些事儿,继续分享

(图片来自网络)
HDFS命令行
概况的讲,就是通过命令行的手段去操作HDFS,主要是操作的过程中一定要有“本地”和“HDFS云端”的概念,“本地”就相当于个人电脑,“HDFS云端”可以是本机上安装的虚拟机,也可以是云平台上的云主机,也可以是服务器,甚至是容器中的路径等等。
HDFS常用的大部分命令跟Linux差不多,比如ls, mkdir, help, cat, rm等等,有区别的命令有上传文件的put,下载文件的get,合并下载的getmerge等,主要的操作无非就是从本地导入原始数据到HDFS上处理,完了后再从HDFS下载到本地。
本次实验就是掩饰一些常用的HDFS命令,详细的信息可以上官网:https://hadoop.apache.org/docs/stable/hadoop-project-dist/hadoop-common/FileSystemShell.html

实验过程
实验准备:
1. 开通一台云主机,此实验采用的是移动云云主机
2. 确保JDK安装正确,环境变量配置无误
3. 确保Hadoop安装正确,环境变量配置无误
4. 确保HDFS各种配置正确,同时正常启动
5. 通过HDFS dashboard页面,可方便的查看操作结果
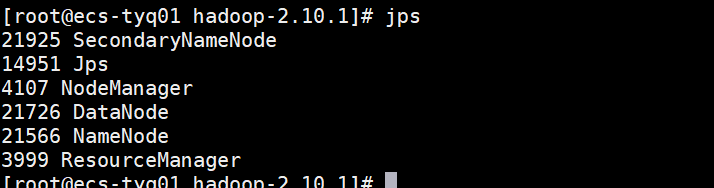
可通过jps命令查看当前HDFS和Yarn启动情况:
打开HDFS dashboard页面,注意端口是50070,浏览器中键入<云主机公网IP>:50070

命令操作演示
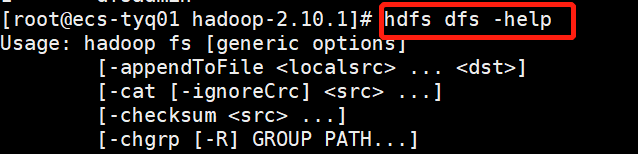
1.查看帮助
hdfs dfs -help
2.查看当前路径下的文件信息
hdfs dfs -ls /

3.创建文件夹
hdfs dfs -mkdir helloworld

4.移动HDFS文件
hdfs dfs -mv input/core-site.xml helloworld/

5.复制HDFS文件
hdfs dfs -cp input/* helloworld/

6.删除HDFS文件
hdfs dfs -rm helloworld/core-site.xml

7.删除HDFS文件夹,-r是递归
hdfs dfs -rm -r helloworld/

8.统计HDFS文件夹中的文件数量
hdfs dfs -count input/

9.本地上传和下载文件
hdfs dfs -put README.txt input/
hdfs dfs -get input/hdfs-site.xml

10.本地剪切文件到HDFS上,可重新命名
hdfs dfs -moveFromLocal zhangsan.txt input/lisi.txt

实验完成后,可以停止yarn,以及dfs进程。
sbin/stop-yarn.sh
sbin/stop-dfs.sh
实验总结
命令行更多是用于运维或者测试使用,后续将会演示通过代码来操作,比如文件流操作等等。















 342
342











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









