







挑战
多模态聚类是指同时利用多种类型的数据(例如,文本、音频、视觉等)进行聚类分析的方法。在发现话语语义(即理解句子或对话的意义)时,现有的多模态聚类方法不足,这带来了两个主要挑战:
如何利用非语言模态的信息来补充文本模态的聚类: 例如,在理解对话时,不仅要分析对话内容(文字),还要考虑语音语调、面部表情、手势等非语言信息,这样才能更准确地理解对话的意义。
如何充分利用未标注的多模态数据来学习有利于聚类的表示: 未标注的数据是指没有被明确分类或解释的数据。例如,如何在没有预先标注的多模态数据(如没有标签的文本、音频、视频等)中,找到有助于聚类的特征或表示。
论文总结
这篇论文提出了一种新的无监督多模态聚类方法(UMC),用于在多模态话语中发现语义。该方法通过构建多模态数据的增强视图进行预训练,以获得良好的初始化表示,然后进行聚类。UMC方法在多模态意图识别和对话行为识别任务中表现出色,相较于现有方法在标准聚类指标上提高了2-6%。
数学公式解释
-
公式 (1):
z M = Transformer ( f M ( x M ) ) [ − 1 ] z_M = \text{Transformer}(f_M(x_M))[-1] zM=Transformer(fM(xM))[−1]
这个公式表示将非言语模态(音频或视频)的特征 x M x_M xM 通过线性层 f M f_M fM 和Transformer编码器处理,提取最后一个时间步的特征作为句子级表示 z M z_M zM。 -
公式 (2):
z T A V = F ( Concat ( z T , z A , z V ) ) z_{TAV} = F(\text{Concat}(z_T, z_A, z_V)) zTAV=F(Concat(zT,zA,zV))
这个公式将文本、音频和视频的表示 z T , z A , z V z_T, z_A, z_V zT,zA,zV进行拼接,然后通过非线性融合层 F F F 得到综合表示 z T A V z_{TAV} zTAV。 -
公式 (3):
L mucl i , j = − log exp ( sim ( ϕ 1 ( z i ) , ϕ 1 ( z j ) ) / τ 1 ) ∑ k ≠ i exp ( sim ( ϕ 1 ( z i ) , ϕ 1 ( z k ) ) / τ 1 ) L_{\text{mucl}}^{i,j} = -\log \frac{\exp(\text{sim}(\phi_1(z_i), \phi_1(z_j))/\tau_1)}{\sum_{k \neq i} \exp(\text{sim}(\phi_1(z_i), \phi_1(z_k))/\tau_1)} Lmucli,j=−log∑k=iexp(sim(ϕ1(zi),ϕ1(zk))/τ1)exp(sim(ϕ1(zi),ϕ1(zj))/τ1)
这是多模态无监督对比学习损失函数,用于拉近正样本对的距离,同时推远负样本对的距离。其中 t e x t s i m text{sim} textsim 是两个向量的点积, ϕ 1 \phi_1 ϕ1是对比头, τ 1 \tau_1 τ1 是温度参数。 -
公式 (4):
t = t 0 + Δ ⋅ iter t = t_0 + \Delta \cdot \text{iter} t=t0+Δ⋅iter
这个公式用于更新高质量样本选择的阈值 ( t ),随着训练迭代次数的增加而线性增加。 -
公式 (5):
ρ i = 1 1 K near ∑ j = 1 K near d i j \rho_i = \frac{1}{\frac{1}{K_{\text{near}}} \sum_{j=1}^{K_{\text{near}}} d_{ij}} ρi=Knear1∑j=1Kneardij1
这个公式计算样本 ( i ) 的密度,作为其在聚类中的质量指标。密度是样本与其最近 K near K_{\text{near}} Knear个邻居的平均距离的倒数。 -
公式 (6):
Idx C k = argsort ( [ ρ 1 , ρ 2 , … , ρ n ] ) \text{Idx}C_k = \text{argsort}([\rho_1, \rho_2, \ldots, \rho_n]) IdxCk=argsort([ρ1,ρ2,…,ρn])
这个公式对聚类 ( C_k ) 中的样本按密度进行排序,以便选择高质量样本。 -
公式 (7):
K near , q = ⌊ ∣ C k ∣ ⋅ ( L + Δ ′ ⋅ ( q − 1 ) ) ⌋ K_{\text{near},q} = \lfloor |C_k| \cdot (L + \Delta' \cdot (q-1)) \rfloor Knear,q=⌊∣Ck∣⋅(L+Δ′⋅(q−1))⌋
这个公式用于为每个聚类自动选择最优的 K near K_{\text{near}} Knear,基于聚类大小和候选集的均匀采样。 -
公式 (8) 和 (9):
coh ( C q k ) = 1 m ∑ i = 1 m coh ( C q k , i ) \text{coh}(C_q^k) = \frac{1}{m} \sum_{i=1}^m \text{coh}(C_q^k,i) coh(Cqk)=m1i=1∑mcoh(Cqk,i)
coh ( C q k , i ) = 1 m − 1 ∑ j = 1 , j ≠ i m d ( z T A V ( Idx C q k , i ) , z T A V ( Idx C q k , j ) ) \text{coh}(C_q^k,i) = \frac{1}{m-1} \sum_{j=1, j \neq i}^m d(z_{TAV}(\text{Idx}C_q^k,i), z_{TAV}(\text{Idx}C_q^k,j)) coh(Cqk,i)=m−11j=1,j=i∑md(zTAV(IdxCqk,i),zTAV(IdxCqk,j))
这些公式定义了聚类的内聚度,用于评估聚类的质量。内聚度越高,表示聚类中的样本越相似。 -
公式 (10):
q opt = arg max q coh ( C q k ) q_{\text{opt}} = \arg\max_q \text{coh}(C_q^k) qopt=argqmaxcoh(Cqk)
这个公式选择具有最高内聚度的候选 K near K_{\text{near}} Knear 作为最优值。 -
公式 (11):
L mscl i = − 1 ∣ P ( i ) ∣ ∑ p ∈ P ( i ) log exp ( sim ( l i , l p ) / τ 2 ) ∑ j ≠ i exp ( sim ( l i , l j ) / τ 2 ) L_{\text{mscl}}^i = -\frac{1}{|P(i)|} \sum_{p \in P(i)} \log \frac{\exp(\text{sim}(l_i, l_p)/\tau_2)}{\sum_{j \neq i} \exp(\text{sim}(l_i, l_j)/\tau_2)} Lmscli=−∣P(i)∣1p∈P(i)∑log∑j=iexp(sim(li,lj)/τ2)exp(sim(li,lp)/τ2)
这是多模态监督对比学习损失函数,用于高质量样本的学习,以捕捉样本对之间的高级相似性关系。
图片解释
-
图 1:展示了仅依赖文本信息的聚类结果与真实多模态聚类分配的偏差,强调了多模态信息在语义发现中的重要性.
-
图 2:展示了UMC算法的总体框架,包括多模态数据的预训练、聚类和高质量样本选择、以及多模态表示学习的步骤.
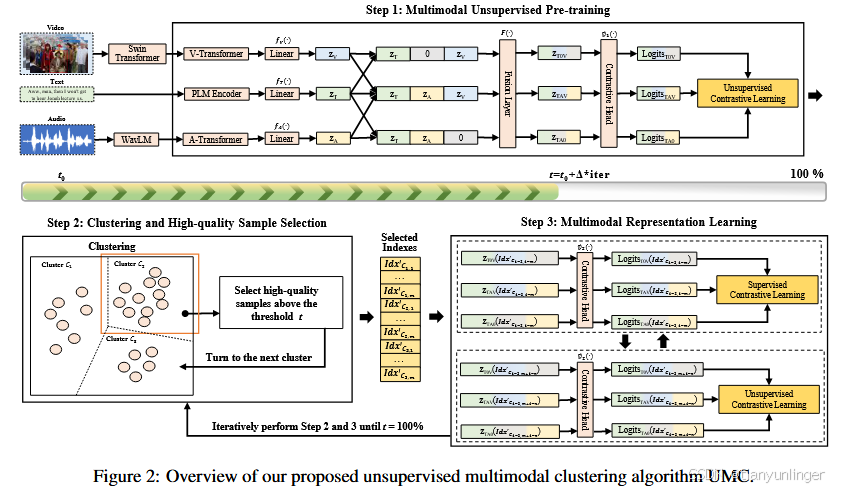
-
图 3:展示了高质量样本选择机制的流程,包括密度计算和高质量样本的选择与评估.
-
图 4:比较了自动选择 K near K_{\text{near}} Knear 策略与固定 K near K_{\text{near}} Knear策略的性能.
-
图 5:使用t-SNE可视化了IEMOCAP-DA数据集上的表示,展示了不同方法的聚类效果.
-
图 6:展示了不同初始阈值 t 0 t_0 t0 对聚类性能的影响.
-
图 7:展示了关键超参数 τ 1 , τ 2 , τ 3 \tau_1, \tau_2, \tau_3 τ1,τ2,τ3 的敏感性分析结果.
-
图 8:展示了MIntRec数据集上的混淆矩阵,分析了不同意图类别的聚类准确性.
-
图 9 和 10:分别展示了MIntRec和MELD-DA数据集上的表示可视化结果,比较了不同方法的聚类效果.
对比学习
在公式 (3) 中,对比头(contrastive head)和温度参数(temperature parameter)是对比学习框架中的两个关键概念。
-
对比头(contrastive head):
- 对比头通常是一个非线性层,用于将特征向量转换为对比学习空间中的表示。在对比学习中,我们希望正样本对(相似的样本)在该空间中的距离更近,而负样本对(不相似的样本)的距离更远。对比头通过非线性变换,有助于模型学习到更具有区分性的特征表示。
- 在公式 (3) 中,对比头由函数 ϕ 1 \phi_1 ϕ1 表示,它对特征向量 z i z_i zi 和 z j z_j zj 进行变换,以便计算它们之间的相似度。
-
温度参数(temperature parameter):
- 温度参数 τ 1 \tau_1 τ1 是一个超参数,用于控制对比学习中相似度计算的“锐度”。温度参数越小,相似度分布越尖锐,即相似的样本对的相似度会更高,而不相似的样本对的相似度会更低;温度参数越大,相似度分布越平滑,即所有样本对的相似度都会相对较高。
- 在公式 (3) 中,温度参数 τ 1 \tau_1 τ1 用于调整点积相似度的尺度,即 sim ( ϕ 1 ( z i ) , ϕ 1 ( z j ) ) / τ 1 \text{sim}(\phi_1(z_i), \phi_1(z_j))/\tau_1 sim(ϕ1(zi),ϕ1(zj))/τ1。通过调整 τ 1 \tau_1 τ1,可以影响模型对正负样本对的区分能力。
综上所述,对比头和温度参数在对比学习中起着至关重要的作用,它们共同影响着模型学习到的特征表示的质量和聚类的性能。
总结
多模态语义发现任务的首次探索:
实现方式:论文提出了一种新的无监督多模态聚类方法(UMC),通过构建多模态数据的增强视图进行预训练,以获得良好的初始化表示,然后进行聚类。该方法特别强调了非言语模态(如视频和音频)在语义发现中的重要性,并通过动态选择高质量样本来指导表示学习.
具体实现:通过将文本、视频和音频模态的特征进行融合,并使用Transformer编码器捕捉这些特征之间的深层语义关系。在预训练阶段,通过掩蔽非言语模态来生成正样本增强视图,从而促进模型学习模态间的互补信息.
高质量样本选择策略:
实现方式:提出了一种基于样本密度的动态选择机制,通过计算每个样本在其聚类中的密度来选择高质量样本,并逐步调整选择阈值以纳入更多的高质量样本.
具体实现:在每次迭代中,根据样本的密度进行排序,并选择密度最高的一定比例的样本作为高质量样本。这些样本用于监督对比学习,以促进更好的表示学习.
迭代表示学习方法:
实现方式:结合高质量样本的监督对比学习和低质量样本的无监督对比学习,通过迭代过程不断优化多模态表示.
具体实现:首先利用高质量样本进行监督对比学习,学习模态间的相似性关系;然后对低质量样本应用无监督对比学习,以增强特征的区分度和聚类友好性.
个人总结
就是多模态加无监督,然后基于密度来优化对比学习



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









