






1、
题目:宿舍内有五个童鞋一起玩对战游戏,每场比赛有一些人作为红方,另外一些人作为蓝方,请问至少需要多少场比赛才能使得任意两个人之间有一场红方对蓝方和一场蓝方对红方的比赛,请写出思路。
分析:更具一般性而言,舍有n个人玩对战游戏好喽,要使得任意两个人之间都发生过两种关系(虽然不雅,这里暂时称作“发生关系”)。那么要使得总的比赛次数尽可能小,则每场比赛就要使得尽量多的新的关系产生,比如,第一场比赛,假设红方有m个人,蓝方放了n-m个人,则总共产生m*(n-m)个关系,其中1<=m<=n-1,由简单二次函数性质可得,m为n/2的向上或者向下取整(由于对称性,这两种解其实是一致的),第二场比赛的话,则很显然是将第一场双方调换方为最优。两场比赛结束后,剩下要处理的,则是m和n-m这两拨人内部怎样在最少比赛次数内相互发生关系。。。。。。
由于比赛人数不受限制,所以,这两拨人内部发生新关系这一棘手的问题可以一起处理,比如说a,b,c,d四个人,刚开始ab和cd交叉发生关系,然后轮到解决a和b,c和d的问题时,可以把a,c放在一边,b,d放在一边,这样再搞两场,该发生的关系都会发生完了。。。。。。
也就是说,人数为m的那一拨人内部发生关系和n-m那拨人内部发生关系可以共同处理,根本不受对方影响。。。。。。于是,其实两拨人最终最优的所需场次数就和人数多的那拨人相关,鉴于上述阐述,得到递归式如下:
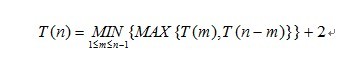
此递归式简化得:
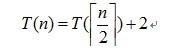
所以T(5)=T(3)+2=T(2)+4=T(1)+6,T(1)=0;
T(5)=6;
题目:两个单向链表,找出它们的第一个公共结点。
链表的结点定义为:
struct ListNode
{
int m_nKey;
ListNode* m_pNext;
};
分析:这是一道微软的面试题。微软非常喜欢与链表相关的题目,因此在微软的面试题中,链表出现的概率相当高。
如果两个单向链表有公共的结点,也就是说两个链表从某一结点开始,它们的m_pNext都指向同一个结点。但由于是单向链表的结点,每个结点只有一个m_pNext,因此从第一个公共结点开始,之后它们所有结点都是重合的,不可能再出现分叉。所以,两个有公共结点而部分重合的链表,拓扑形状看起来像一个Y,而不可能像X。
看到这个题目,第一反应就是蛮力法:在第一链表上顺序遍历每个结点。每遍历一个结点的时候,在第二个链表上顺序遍历每个结点。如果此时两个链表上的结点是一样的,说明此时两个链表重合,于是找到了它们的公共结点。如果第一个链表的长度为m,第二个链表的长度为n,显然,该方法的时间复杂度为O(mn)。
接下来我们试着去寻找一个线性时间复杂度的算法。我们先把问题简化:如何判断两个单向链表有没有公共结点?前面已经提到,如果两个链表有一个公共结点,那么该公共结点之后的所有结点都是重合的。那么,它们的最后一个结点必然是重合的。因此,我们判断两个链表是不是有重合的部分,只要分别遍历两个链表到最后一个结点。如果两个尾结点是一样的,说明它们用重合;否则两个链表没有公共的结点。
在上面的思路中,顺序遍历两个链表到尾结点的时候,我们不能保证在两个链表上同时到达尾结点。这是因为两个链表不一定长度一样。但如果假设一个链表比另一个长l个结点,我们先在长的链表上遍历l个结点,之后再同步遍历,这个时候我们就能保证同时到达最后一个结点了。由于两个链表从第一个公共结点考试到链表的尾结点,这一部分是重合的。因此,它们肯定也是同时到达第一公共结点的。于是在遍历中,第一个相同的结点就是第一个公共的结点。
在这个思路中,我们先要分别遍历两个链表得到它们的长度,并求出两个长度之差。在长的链表上先遍历若干次之后,再同步遍历两个链表,知道找到相同的结点,或者一直到链表结束。此时,如果第一个链表的长度为m,第二个链表的长度为n,该方法的时间复杂度为O(m+n)。
基于这个思路,我们不难写出如下的代码:
///
// Find the first common node in the list with head pHead1 and
// the list with head pHead2
// Input: pHead1 - the head of the first list
// pHead2 - the head of the second list
// Return: the first common node in two list. If there is no common
// nodes, return NULL
///
ListNode* FindFirstCommonNode( ListNode *pHead1, ListNode *pHead2)
{
// Get the length of two lists
unsigned int nLength1 = ListLength(pHead1);
unsigned int nLength2 = ListLength(pHead2);
int nLengthDif = nLength1 - nLength2;
// Get the longer list
ListNode *pListHeadLong = pHead1;
ListNode *pListHeadShort = pHead2;
if(nLength2 > nLength1)
{
pListHeadLong = pHead2;
pListHeadShort = pHead1;
nLengthDif = nLength2 - nLength1;
}
// Move on the longer list
for(int i = 0; i < nLengthDif; ++ i)
pListHeadLong = pListHeadLong->m_pNext;
// Move on both lists
while((pListHeadLong != NULL) &&
(pListHeadShort != NULL) &&
(pListHeadLong != pListHeadShort))
{
pListHeadLong = pListHeadLong->m_pNext;
pListHeadShort = pListHeadShort->m_pNext;
}
// Get the first common node in two lists
ListNode *pFisrtCommonNode = NULL;
if(pListHeadLong == pListHeadShort)
pFisrtCommonNode = pListHeadLong;
return pFisrtCommonNode;
}
///
// Get the length of list with head pHead
// Input: pHead - the head of list
// Return: the length of list
///
unsigned int ListLength(ListNode* pHead)
{
unsigned int nLength = 0;
ListNode* pNode = pHead;
while(pNode != NULL)
{
++ nLength;
pNode = pNode->m_pNext;
}
return nLength;
}
3、linux 下查看系统资源和负载,以及性能监控
- int rand7()
- {
- return rand()%7+1;
- }
- int rand10()
- {
- int x=0;
- do
- {
- x=(rand7()-1)*7+rand7();
- }
- while(x>40);
- return x%10+1;
- }
int rand7()
{
return rand()%7+1;
}
int rand10()
{
int x=0;
do
{
x=(rand7()-1)*7+rand7();
}
while(x>40);
return x%10+1;
} 下面说明为什么(rand7()-1)*7+rand7()可以构造出均匀分布在1-49的随机数:
首先rand7()-1得到一个离散整数集合{0,1,2,3,4,5,6},其中每个整数的出现概率都是1/7。那么(rand7()-1)*7得到一个离散整数集合A={0,7,14,21,28,35,42},其中每个整数的出现概率也都是1/7。而rand7()得到的集合B={1,2,3,4,5,6,7}中每个整数出现的概率也是1/7。显然集合A和B中任何两个元素组合可以与1-49之间的一个整数一一对应,也就是说1-49之间的任何一个数,可以唯一确定A和B中两个元素的一种组合方式,反过来也成立。由于A和B中元素可以看成是独立事件,根据独立事件的概率公式P(AB)=P(A)P(B),得到每个组合的概率是1/7*1/7=1/49。因此(rand7()-1)*7+rand7()生成的整数均匀分布在1-49之间,每个数的概率都是1/49。
ps:用while(x>40)而不用while(x>10)呢?原因是如果用while(x>10)则有40/49的概率需要循环while,很有可能死循环了。















 997
997

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









