






pdfjs是一个js库,可以将pdf文件用canvas重新绘制,从而无需借助pdf读取插件就可以直接预览。
目前chrome内核的浏览器已内置pdf读取插件,但ie浏览器还没有。而我们最近在做的一个项目使用对象是医院,使用的浏览器竟然还是ie。所以我们只能把项目用js重写(当然也可以用jQuery的)。
首先模拟ie浏览器就是个挑战。长期做B端项目被惯坏了,早就忘记还有ie这么个天使了。官网已经不提供ie的下载渠道,搜索了一圈,发现用edge模拟是一个比较好的选择。
在windows11中打开ie浏览器的步骤是:
- 首先,按 Win + R 打开运行窗口
- 接下来,在运行命令框中输入 inetcpl.cpl
- 单击 确定 进入 Internet 属性窗口
- 选择 程序 选项卡,点击 管理加载项 按钮
- 然后,点击窗口底部 了解有关工具栏和扩展的详细信息
这样就打开了可爱的ie浏览器。
原生js获取xhr的主体方法
function Request(){
this.httpRequest = function(obj,successfun, errFun){
var xmlHttp = null;
//创建 XMLHttpRequest 对象,老版本的 Internet Explorer (IE5 和 IE6)使用 ActiveX 对象:xmlhttp=new ActiveXObject("Microsoft.XMLHTTP")
if(window.XMLHttpRequest){
//code for all new browsers()
xmlHttp = new XMLHttpRequest;
}else if(window.ActiveXObject){
//code for IE5 and IE6
xmlHttp = new ActiveXObject("Microsoft.XMLHTTP");
}
//判断是否支持请求
if(xmlHttp == null){
alert("浏览器不支持xmlHttp");
return;
}
//请求方式, 转换为大写
var httpMethod = (obj.method || "Get").toUpperCase();
//数据类型
var httpDataType = obj.dataType || 'json';
//url
var httpUrl = obj.url;
//异步请求
var async = true;
//post请求时参数处理
if(httpMethod == "POST"){
//请求体中的参数 post请求参数格式为:param1=test¶m2=test2
var data = obj.data || {};
var requestData = '';
for(var key in data){
requestData = requestData + key + "=" + data[key] + "&";
}
if(requestData == ''){
requestData = '';
}else{
requestData = requestData.substring(0, requestData.length - 1);
}
}
//请求接口
if(httpMethod == 'GET'){
xmlHttp.open("GET", httpUrl, async);
xmlHttp.send(null);
}else if(httpMethod == "POST"){
xmlHttp.open("POST", httpUrl, async);
xmlHttp.setRequestHeader("Content-Type", "application/x-www-form-urlencoded");
xmlHttp.send(requestData);
}
//onreadystatechange 是一个事件句柄。它的值 (state_Change) 是一个函数的名称,当 XMLHttpRequest 对象的状态发生改变时,会触发此函数。状态从 0 (uninitialized) 到 4 (complete) 进行变化。仅在状态为 4 时,我们才执行代码
xmlHttp.onreadystatechange = function(){
//complete
if(xmlHttp.readyState == 4){
// 此处用了promise替代了请求成功后的回调
if(xmlHttp.status == 200){
var res = JSON.parse(xmlHttp.responseText);
// var res = xmlHttp.responseText;
if (res && res.code == '200') {
//请求成功执行的回调函数
typeof successfun === 'function' &&
successfun(res);
} else {
//请求失败的回调函数
typeof errFun === 'function' &&
errFun(res);
}
} else {
var msg = new Error('出错了')
//请求失败的回调函数
typeof errFun === 'function' &&
errFun(msg);
}
}
}
}
}
var $request = new Request()
数据请求的问题完成了。但是现在pdf文件没有出现在期待的位置,只是在底部出现了一个下载文件的请求提示。查了下,原来是ie没有内置pdf阅读器,所以无法预览,浏览器将pdf文件识别为需要下载。
那么问题来了,解决方法有两个:
1.下载Adobe pdf-reader。
下载地址:https://www.adobe.com/cn/acrobat/pdf-reader.html,还需要再ie浏览器中启用,在管理加载项中修改(管理加载项打开方法见上面那个步骤)
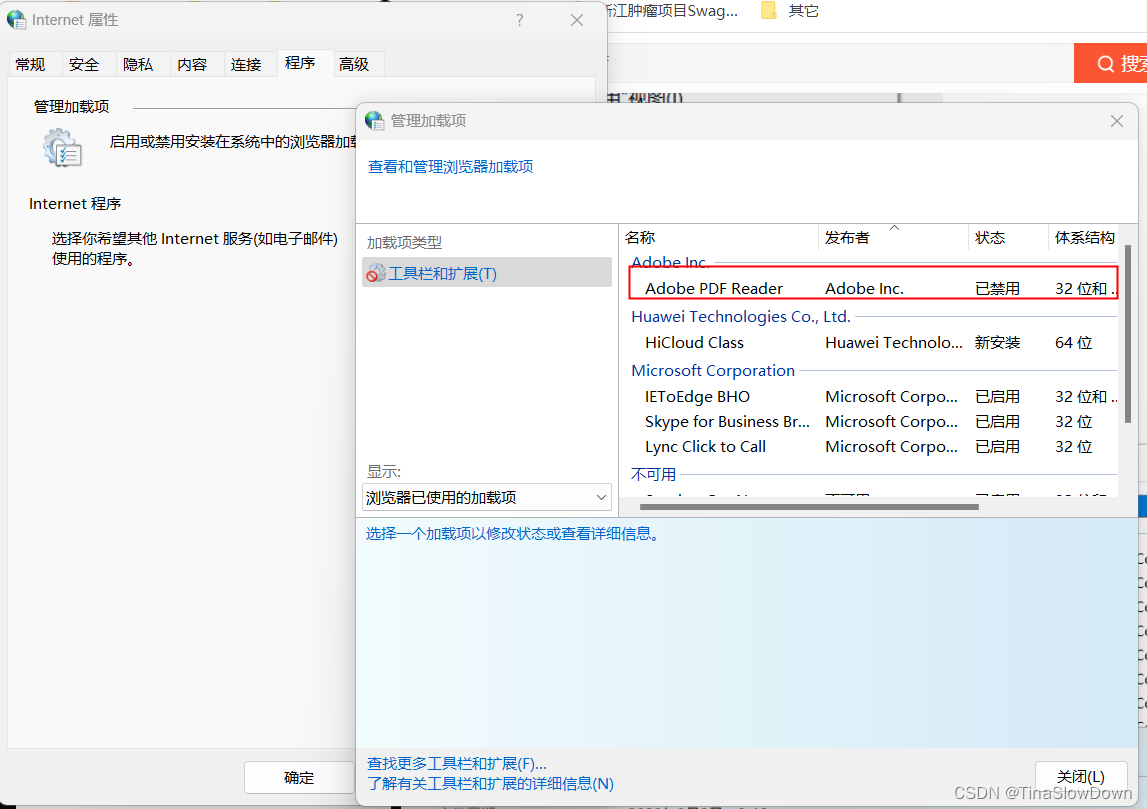
但这个方法也有一个问题,下载插件对用户是有门槛的,用户很可能不愿意这么麻烦。
2.用pdfjs处理pdf文件。
这样用户不需要额外做任何操作。但pdfjs兼容性有限,只能兼容到ie9,更低版本的浏览器就不行了。
综合评估后还是决定用pdfjs处理。如果还有更低版本的就继续下载pdf阅读器。
高版本的pdfjs已放弃对ie的兼容,需要下载旧版本。在官网选择tags,按照对应指示打包。注意打包旧版本时需要保证node在10以下(我本地的node是16.16.0,怪不得昨天一直报错到崩溃)。
当然也可以找别人已经打好的包,参考地址。
要注意把viewer.js中的defaultUrl清空(这个变量的名称可能不同版本不一样,我当时的变量名是DEFAULT_URL,DEFAULT_URL = ‘compressed.tracemonkey-pldi-09.pdf’)。不清空会报错,报“Missing PDF file”。
再把下载下来的文件地址改写为‘./pdfjs/web/viewer.html?file=’+realUrl。
这样先在chrome发现是正常展示的,没有问题,说明方法写地是对的。但是用ie浏览器打开就是一片黑。昨天崩溃了一天,换了很多个pdfjs版本,今天终于意识到应该看看报了什么错。发现控制台报的错是“附加页针对的是文档模式7,部分控制台api和功能可能无法使用”。针对这个报错,一查发现是因为浏览器设置的默认文档模式是7,导致虽然我的浏览器是ie11,但实际是按照ie7来解析网页,而我的网页是不兼容ie7地,这可不就会报错嘛。
查看了相关文章,发现了应该在头文件加上两句声明。
// 如果安装了 Google Chrome Frame (谷歌浏览器 內嵌框架), 则使用 谷歌浏览器 内核模式,否则使用 最新的 IE 模式(浏览器是哪个版本就用哪个ie模式)
<meta http-equiv="X-UA-Compatible" content="IE=edge chrome=1">
// 双核浏览器兼容,使用 Chromium 内核(极速模式)
<meta name="renderer" content="webkit"/>
自己的html文件和pdfjs的viewer.html都要加上。
还发现了一个宝贝,meta标签声明,可以强制在浏览器中用低版本模式打开网页。
<meta http-equiv="X-UA-Compatible" content="IE=7" />
分别变更content中的数字,可以在ie11中分别模拟对应ie版本中的兼容情况。啊啊啊,妈妈再也不用担心我怎样切换ie版本了。
IE模式参考文章。
好了,至此,pdf预览兼容的IE的工作总算完成了。芜湖,为自己鼓掌。














 2605
2605











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









