







一. 界面认识与矩阵表操作
1.获取excel数据
菜单栏获取数据/首页从Excel导入数据 -> 选中表 -> 如果数据已清洗完毕可直接点加载,如果没有可点击转换数据进入PowerQuery数据清洗)
左侧菜单栏分别是:报表(可视化)、表格(查看表格内容)、模型
![]()
e.g.视觉对象选中饼图,姓名拖放到图例,分数拖放到值


2.菜单按钮
主页常用按钮:获取数据
建模常用按钮:

3.可视化常用的矩阵表(数据透视表)
e.g.行上放班级和姓名,列上放科目,值上放分数


选中报表 -> 点击设置视觉对象格式
#1 放大字体

#2 设置行高

#3 设置自动列宽

#4 筛选
筛选器拖放字段按需进行筛选
#5 居中显示
行标题对齐方式选择居中;特定列 -> 值,对齐方式选择居中
#6 层级加号显示
搜索"+"

#7 行标题缩进
搜索“缩进”

#8 层级分列展示
搜索“渐变”,关闭渐变布局按钮

效果:

#9 行小计和列小计
可选择关闭行小计或列小计,以及修改小计名称

关闭行小计效果:

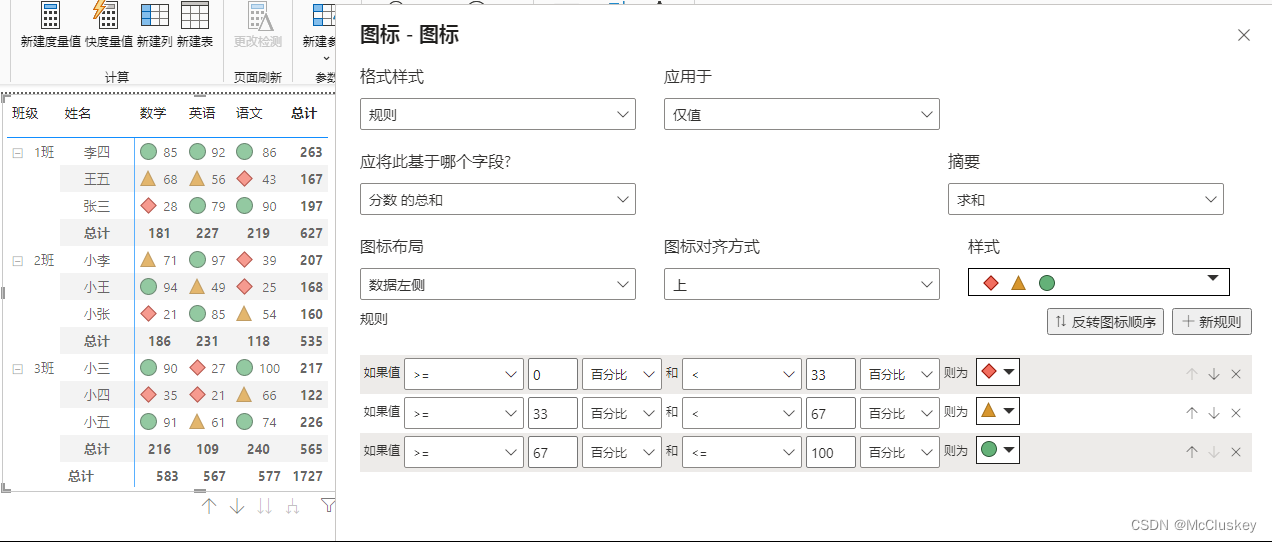
#10 单元格元素(旧版名称:条件格式)
最常用的是“数据条”,比如可用于制作销售占比、销售金额时,效果:

“图标按钮”效果:
二. 运算符和新建列
1.运算符
| 运算符 | 含义 | 运算符 | 含义 | 运算符 | 含义 | ||
| + | 加 | = | 等于 | && | 与 | ||
| - | 减 | > | 大于 | || | 或 | ||
| * | 乘 | < | 小于 | not | 非 | ||
| / | 除 | >= | 大于等于 | & | 字符串连接 | ||
| ^ | 幂 | <= | 小于等于 | in | 包含 | ||
| <> | 不等于 | not in | 不包含 |
2.新建列
打开表格,可以在表工具新建列,也可以在主页找到“新建列”按钮

新建列 -> 新列命名 -> 新列表达式(英文输入法输入单引号即可引用表字段)
引用列的方式:
除了输入单引号,也可以输入中括号。
新的销售量 = [销售数量]*10
新的销售量 = '销售表'[销售数量]*10
两种方法功能相同,什么时候引用列的时候必须带表名呢?
销售金额 = [销售数量]*RELATED('商品'[进价])
=> 在销售表新建销售金额列,[销售数量]来自销售表,[进价]来自商品表,不指明的话,不指明的话表达式不知道去哪张表取[进价]
总结:新建列的时候,当另一个需要计算的列来自其他表时,一定要指明表名。
为了避免出错,以后都采用单引号的方式引用列,在任何情况下都指明表名。
三. 建模与关系函数
1.建模
导入多张表的时候要考虑模型:
-- 连线时建议把1端的表放上面,多端的表放下面
1对多的关系:一个商品只会有一种进价,但是会有多笔销售记录
箭头方向(传递方向):商品表指向销售表,代表商品表可以筛选销售表,销售表可以向商品表索取内容
=> SQL中的表关联
2.LOOKUPVALUE函数
-- 就是VLOOKUP
语法:LOOKUPVALUE(把哪张表的哪个列拿过来, 找那张表上的谁, 找自己表里的谁)
LOOKUPVALUE('A'[c], 'A'[a], 'B'[b])
-- 通过B表的b列关联A表的a列,从而获取A表中a对应的c列值
-- 通常用多端的表去V1端的表
e.g. 单价 = LOOKUPVALUE('商品表'[进价], '商品表'[品名], '销售表'[商品名称])
删除列:
右键列名,选择删除
3.RELATED函数和RELATEDTABLE函数
(1) RELATED函数:(多端找一端)(事实表找维度表)(数据表找基础表)
销售成本 = '销售表'[销售数量]*RELATED('商品表'[进价])
-- 销售数量来自销售表,销售表是多端;进价来自商品表,商品表是1端;销售表向商品表索取[进价]
e.g.实现商品表筛选销售表,比如查看商品表中的商品各卖了多少笔记录
订单数量 = COUNTROWS(RELATEDTABLE('销售表'))
使用RELATEDTABLE效果:
-- 每一个品名对应2笔订单
RELATED是多端找一端的引路人,RELATEDTABLE是一端找多端的引路人。
四. 度量值、CALCULATE引擎、CALCULATETABLE筛选表
1.度量值
新建度量值:
度量值体现筛选功能:
矩阵表 -> 行放日期(下拉选择日期,取消日期层次结构) -> 值放总销量
-- 度量值是不占内存的,需要的时候拿出来用;如果是新建列,数据量大的话很占内存
-- 度量值最大的优点是自带筛选功能;新建列是没有筛选功能的
-- 度量值在引擎中可以循环使用
2.筛选引擎CALCULATE
CALCULATE(表达式,[筛选器1],…)
在筛选器修改的上下文中对表表达式进行求值
-- 第一个参数是计算器,第二个参数是筛选器,筛选器可缺省
销售表新建3个度量值:
总销量 = SUM('销量表'[销售数量])
A产品销量1 = CALCULATE([总销量],'商品表'[品名]="A")
A产品销量2 = CALCULATE([总销量],'销售表'[商品名称]="A")
可视化界面查看:
矩阵表 -> 行上放商品表的品名,值上放销售表的总销量、A产品销量1、A产品销量2
-- 表达式使用销售表的商品名称时显示正确
-- 原因是商品表1对多指向销售表,商品表筛选销售表;所以行上放商品表时,筛选器要用销售表作为条件;如果筛选器想用商品表品名作为条件,则行上换成销售表的商品名称,同样可以实现功能
3.多条件CALCULATE与筛选表
(1)多条件筛选CALCULATE
-- 不同列
多条件 = CALCULATE([总销量],'商品表'[品名] = "A",'商品表'[进价] = 0.1)
-- 相同列
多条件1 = CALCULATE([总销量],'商品表'[品名] in {"A","B","C"})
多条件2 = CALCULATE([总销量],not '商品表'[品名] in {"A","B","C"})
(2)筛选表
CALCULATETABLE(表,筛选条件)
-- 与CALCULATE区别在于,可以多表运作筛选,最终返回一张表
e.g.
新表 = CALCULATETABLE('销售表','商品表'[品名]="A",'商品表'[进价]=0.1)
-- 返回销售表的内容,根据商品表的条件去筛选它
-- 新建表会出现在模型视图
4.度量值的存放
-- 不建议在每张表到处建,会很乱,建议存放在统一的地方
主页 -> 输入数据 -> 修改名称为“度量值”-> 加载 -> 在“度量值”表格中新建度量值 -> 表格里有度量值之后删除空列
五. 高级筛选器FILTER与VALUES人工造表
-- 返回一个表,用于表示另一个表或表达式的子集,不能单独使用
FILTER函数对筛选的表进行横向的逐行扫描,这样的函数叫迭代函数。
FILTER是一个表函数,以后如果遇到表函数不知道怎么用的话,可以先放到新建表里测试一下,FILTER效果:
使用举例:
COUNTROWS(FILTER(表,筛选条件))
CALCULATE(表达式(度量值),FILTER(表,筛选条件))
-- 导入课件材料后发现“花名册”的列名都是“COLUMN”,第一行数据才是可识别的列名
右键“花名册” -> 编辑查询 -> 将第一行提作标题 -> 关闭并应用
由于两张表都有列名“学号”,所以在模型视图自动建立了连接
1.效果相同,为什么使用FILTER函数
总分 = SUM('成绩表'[分数])
1班男生1 = CALCULATE('度量值'[总分],'花名册'[班级]="1班",'花名册'[性别]="男")
1班男生2 = CALCULATE('度量值'[总分],FILTER('花名册','花名册'[班级]="1班"&&'花名册'[性别]="男"))
报表视图选择矩阵表,值上放“1班男生1”和“1班男生2”效果:
-- 两个公式效果是等价的
2.什么时候使用FILTER函数
在CALCULATE函数中的直接筛选条件里,我们只能输入:
'表'[列] = 固定值 (或>, <, >=, <=, <>, in, not in固定值)
但是遇到如下情况,就要使用FILTER函数:
[列]=[度量值]、[列]=[公式]、[列]=[列]
[度量值]=[度量值]、[度量值]=[公式]、[度量值]=固定值
举例:总分大于250分的学生一共考了多少分?
FILTER总分1 = CALCULATE('度量值'[总分],FILTER('花名册','度量值'[总分]>250))
FILTER总分2 = CALCULATE('度量值'[总分],FILTER('成绩表','度量值'[总分]>250)) --错误
矩阵表行上放姓名,值上放“FILTER总分1”和“FILTER总分2”效果:
“FILTER总分2”错误原因:
FILTER有一个严格要求,FILTER第一参数的表必须是唯一值的表,不能是多端数据的表
如果我只有一张表怎么办?我没有唯一表,只有数据表!那就自己造一张表!
=> VALUES人工造表
3.VALUES人工造表
FILTER总分3 = CALCULATE('度量值'[总分],FILTER(VALUES('成绩表'[学号]),'度量值'[总分]>250))
VALUES也是表函数,拿到新建表里做测试:
-- 提取出了成绩表中“学号”的唯一值
矩阵表值上加上“FILTER总分3”效果:
-- 效果和“FILTER总分1”一致
经典语句:CALCULATE([度量值],FILTER(VALUES('表'[列名]),筛选条件))
六. 被翻译耽误的上下文
1.上下文
同样一个公式,写在[新建列]和[度量值]中效果不一样。
-- 新建度量值
总分 = SUM('成绩表'[分数])
矩阵表行放[学号],值放[总分]效果:
-- 每个人都可以实现筛选功能
-- 在成绩表新建列
总分列 = SUM('成绩表'[分数])
-- 每一行都显示新建列表达式的结果,即整张成绩表的总分
这就是上下文,新建列是行上下文(逐行扫描,数求出来之后每一行都显示这个数),而度量值是筛选上下文(数值上可以进行筛选)。
如果想让新建列实现筛选功能需要套上CALCULATE:
总分列2 = CALCULATE(SUM('成绩表'[分数]))
总结:
(1) 度量值天生具有筛选功能
(2) 新建列是行上下文,行上下文没有筛选功能
(3) 想让行上下文实现筛选功能就要在外面套一个CALCULATE
2.FILTER与上下文
FILTER总分1 = CALCULATE('度量值'[总分],FILTER('花名册','度量值'[总分]>250)) #正确
FILTER总分4 = CALCULATE('度量值'[总分],FILTER('花名册',SUM('成绩表'[分数])>250)) #错误
矩阵表行上放班级,值上放“FILTER总分1”和“FILTER总分4”,效果:
-- FILTER4显示的是1班所有人的成绩、2班所有人的成绩、3班所有人的成绩以及总累计
-- 原因是SUM('成绩表'[分数])不是度量值,它只是一个聚合函数,只起到了计算的功能,不具备筛选功能
如果一定要采取公式的写法实现筛选功能,套上CALCULATE:
FILTER总分5 = CALCULATE('度量值'[总分],FILTER('花名册',CALCULATE(SUM('成绩表'[分数]))>250))
所谓的筛选上下文,就是度量值,度量值自带天然的CALCULATE函数;
没有筛选功能的新建列就是行上下文,如果行上下文向转成筛选上下文,它是不会自动转的,要手动套上一个CALCULATE函数。
七. ALL函数、ALLEXCEPT函数、ALLSELECTED函数
ALL函数
作用:清除筛选 => 指的是清除度量值的筛选功能,因为度量值天生就具备筛选功能
返回:清除筛选后的表格或列
语法:
ALL(表)
ALL(表[列])
新建度量值:
商品表中商品总数 = COUNTROWS('商品表')
销售表中商品数量 = CALCULATE(COUNTROWS('商品表'),'销售表')
-- 注意,此处CALCULATE的第二参数是表,表示从商品表中筛选出销售表中的商品;销售表的商品是包含在商品表里的,此处计算器计算商品总数,筛选条件是销售表

不能筛选的总数 = COUNTROWS(ALL('商品表'))

矩阵表行上放“商品编码”,值上放“商品表中商品总数”、“销售表中商品总数”、“不能筛选的总数”,效果:

如果行上放了“商品编码”,想要计算销售表的商品数量占商品表商品总数量的占比(虽然没有意义,要么1/26要么0/26),去除以“商品表中商品总数”是无法实现的,因为度量值自带筛选功能,每行的“商品表中商品总数”会根据“商品编码”筛选计算出来都是1,最终占比要么1/1要么0/1。“不能筛选的总数”使用ALL清除度量值的筛选功能,才能得到正确的占比。
占比 = '度量值'[销售表中商品数量]/'度量值'[不能筛选的总数]

案例一【应用于表】:计算销售表中每个商品的占比
总销量 = SUM('销售表'[销售数量])
禁止筛选的总销量 = CALCULATE('度量值2'[总销量],ALL('销售表'))
每个商品的占比 = '度量值2'[总销量]/'度量值2'[禁止筛选的总销量]
矩阵表行上放'销售表'[商品编码]:

-- ALL函数用得最多的地方就是计算占比的时候
报表视图添加切片器,筛选字段选择'销量表'[日期],设置日期区间为12.1-12.1,效果:
-- 切片器:用于过滤数据,实现数据动态展示
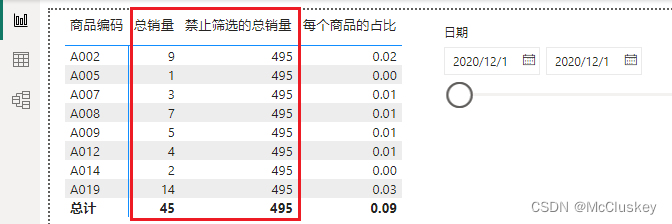
-- “总销量”仅展示12.1各产品销量汇总,“禁止筛选的总销量”还是展示的12.1+12.2的全产品总销量
-- 现希望总计占比保持100%
总结:
当ALL函数参数为表时,忽略所有的筛选条件,无论是该图表内还是外部切片器。
ALLSELECTED函数替换ALL函数解决占比问题:
-- 将“禁止筛选的总销量”表达式中ALL替换为ALLSELECTED
禁止筛选的总销量 = CALCULATE('度量值2'[总销量],ALLSELECTED('销售表'))

-- 替换后切片器的筛选对“禁止筛选的总销量”生效,仅展示12.1的全产品总销量
-- ALLSELECTED除了保留来自外部的筛选器,和ALL没有任何区别,多用于显示百分比的时候
以上图例中,行上放的是'销售表'[商品编码],如果想放商品名称,换成'商品表'[商品名称]:

-- 部分产品如A在销售表是没有销量的,但是因为ALL函数是不受内部筛选影响的,所以“禁止筛选的总销量”列都显示了值
解决方法有2种:
(1) 清除矩阵表值上的“禁止筛选的总销量”
(2) 到销售表里把商品表的商品名称VLOOKUP过来
销售表新建列:
商品名称 = LOOKUPVALUE('商品表'[商品名称],'商品表'[商品编码],'销售表'[商品编码])

报表视图矩阵表行上放'销售表'[商品名称]:

案例二【应用于列】:
-- 由于销售表中没有大类这个列,我们先把大类V过来再测试
【销售表新建列】
大类 = LOOKUPVALUE('商品表'[大类],'商品表'[商品编码],'销售表'[商品编码])
【销售表新建列】
规格 = LOOKUPVALUE('商品表'[规格],'商品表'[商品编码],'销售表'[商品编码])
【度量值】
取消列筛选 = CALCULATE('度量值2'[总销量],ALL('销售表'[规格]))
报表视图行上放'销售表'[大类],值上放'度量值2'[总销量]、'度量值2'[取消列筛选];添加切片器,字段添加'销售表'[日期](视觉对象格式 -> 切片器设置 -> 选项 -> 样式选为垂直列表);添加切片器,字段添加'销售表'[规格]:

-- 用“日期”筛选时,“取消列筛选”值发生变化,即外部筛选器生效

-- 用“规格”筛选时,“取消列筛选”值保持不变,即外部筛选器不生效

总结:
当ALL函数参数为列时,忽略该列筛选,图表内部其他字段或外部筛选其他字段会产生作用。
注意:
ALL函数在引用列的时候,必须与矩阵表的行和列在同一张表。
比如矩阵表的行和列都来自于销售表,那么ALL函数引用列的时候,也必须引用销售表的列,like ALL('销售表'[规格]),不能从商品表拿规格,必要时使用LOOKUPVALUE先把需要的字段V过来。
ALL函数引用列的使用场景:
【新建度量值】
占比 = '度量值2'[总销量]/'度量值2'[取消列筛选]
矩阵表行上放'销售表'[大类]、'销售表'[规格],值上加上'度量值2'[占比]:

-- 展示袋装占比、盒装占比 -> 可用于计算分类占比
ALLEXCEPT函数:除…之外
语法:ALLEXCEPT('表名'[列名])
-- 除了参数列以外的列,全部取消筛选
-- 等同于ALL('表名'[列名1],'表名'[列名2],'表名'[列名3],…)
八. ALLNOBLANKROW核对数据
-- 返回表中除空白行以外的所有行或列中的所有值
【新建表】
测试表1 = ALLNOBLANKROW('子表')

-- 子表中无重复的行或空白行,所以全部返回
测试表2 = ALLNOBLANKROW('子表'[姓名])

-- 返回子表中去重后的所有姓名
-- 返回:去重(即便只有一列,它也是表)
【新建度量值】
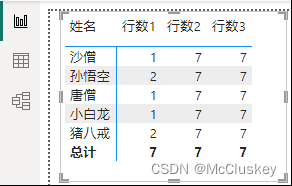
行数1 = COUNTROWS('子表')
行数2 = COUNTROWS(ALL('子表'))
行数3 = COUNTROWS(ALLNOBLANKROW('子表'))
矩阵表行上放'子表'[姓名],值上放'度量值2'[行数1]、'度量值2'[行数2]、'度量值2'[行数3]:
把行换成'父表'[姓名]:
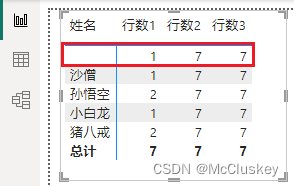
-- 出现空行,因为父表里没有唐僧
【案例】
【新建度量值】
总销量 = SUM('销售表'[销售数量])
ALL总销量 = CALCULATE('度量值'[总销量],ALL('商品表'))
ALLNOBLANKROW总销量 = CALCULATE('度量值'[总销量],ALLNOBLANKROW('商品表'))
矩阵表行上放'销售表'[名称],值上放3个度量值:

-- 键盘存在于销售表中,但不存在于商品表中,通过ALLNOBLANKCOUNT一眼看出哪些东西是商品表没有但是被卖出去的
-- 一般人工造出来的数据才会发生这种情况,计算机记录的数据是不会发生的
九. 聚合函数和迭代函数
1.聚合函数
语法:

-- 参数是物理列
总钱数 = SUM('表'[捡钱])
平均钱数 = AVERAGE('表'[捡钱]) -- 算出平均值

-- AVERAGE是数值总和除以数值的个数,AVERGAEA是数值总和除以项数
最大值 = MAX('表'[捡钱])
最小值 = MIN('表'[捡钱])
记录数 = COUNTROWS('表')
人数 = DISTINCTCOUNT('表'[姓名]) -- 去重计数
COUNTA函数:计算列中单元格不为空的数目
COUNTBLANK函数:计算列中单元格为空的数目
PRODUCT函数:计算列中单元格乘积
2.迭代函数
【新建列】
净值 = '表'[捡钱]-'表'[丢钱]
列 = SUMX('表','表'[捡钱]-'表'[丢钱])
列 2 = CALCULATE(SUMX('表','表'[捡钱]-'表'[丢钱]))

计算过程:
对每一行逐行扫描,比如
第一行,1-0.1=0.9
第二行,2-0.9=1.1
…
第五行,5-0.8=4.2
将所有值求和。因为新建列是行上下文,不具备筛选功能,所以上图所有行对应的[列]都是最后的的总和12.8。
如果没有SUMX函数:
净值 = '捡钱'-'丢钱'
求和 = SUM('净值')
语法:SUMX(表,算术表达式)
解释:将每一行按算术表达式计算后,再将计算结果求和。
AVERAGEX、MAXX、MINXX、COUNTX、COUNTAX、PRODUCTX……它们和FILTER函数一样都是行上下文函数
十. EARLIER函数【当前行】
案例一:计算下一个订单日期
【新建列】
下个订单日期 = SUMX(FILTER('表','表'[序号]=EARLIER('表'[序号])+1),'表'[销售日期])
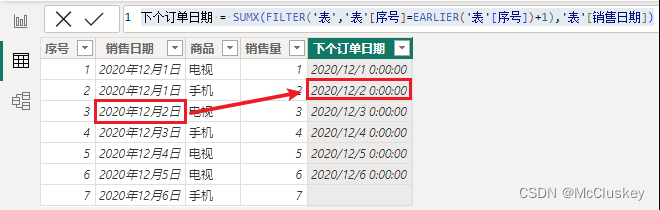
分析:
EARLIER('表'[序号])+1
-- 当前行序号+1
FILETER('表','表'[序号]=EARLIER('表'[序号])+1)
-- 将“序号等于当前行序号+1”的表筛选出来
SUMX(FILETER('表','表'[序号]=EARLIER('表'[序号])+1),'表'[销售日期])
-- 这里用哪个迭代函数都可以,没有求和求平均的操作,仅用来迭代返回销售日期(不理解)
案例二:累计求和
累计求和 = SUMX(FILTER('表','表'[序号]<=EARLIER('表'[序号])),'表'[销售量])

分析:
将“序号小于等于当前行序号”的表筛选出来,因为肯定不止一行,所以用SUMX迭代求和。
案例三:分组累计求和
商品累计求和 = SUMX(FILTER('表','表'[序号]<=EARLIER('表'[序号])&&'表'[商品]=EARLIER('表'[商品])),'表'[销售量])

分析:
将“序号小于等于当前行序号”且“商品等于当前行商品”的表筛选出来,求和。
表中没有序号,可以用日期,比如:累计计算电视每天的累加值,手机每天的累计值:
商品累计求和 = SUMX(FILTER('表','表'[销售日期]<=EARLIER('表'[销售日期])&&'表'[商品]=EARLIER('表'[商品])),'表'[销售量])
案例四:累计购买次数
第几次购买 = COUNTROWS(FILTER('表1','表1'[姓名]=EARLIER('表1'[姓名])&&'表1'[序号]<=EARLIER('表1'[序号])))

分析:
将“序号小于等于当前行序号”且“姓名等于当前行姓名”的表筛选出来,计算行数。
十一. VALUES与DISTINCT区别
1.VALUES函数
VALUES(表[列]):
表1 = VALUES('表'[姓名]) -- 把姓名不重复的列提取出来,形成一个单列的表;人造基础表(单列)
VALUES(表):
表2 = VALUES('表') -- 返回表的所有行,就是复制一张表;人造虚拟表,建立虚拟关系的时候用到
2.DISTINCT函数
DISTINCT(表名[字段名]) -- 返回:去重后,唯一值的列
DISTINCT(表名) -- 返回:只包含非重复行的表
DISTINCT(返回表的表达式)
表 2 = DISTINCT(FILTER('表1','表1'[性别]="男"))

3.区别
(1) 对于空白行的处理上,VALUES包括没有匹配的空白行,DISTINCT不返回没有匹配的空白行
空白行的专业术语:参照完整性不匹配
=> 说人话:销售表上有的数据,基础表上没有;比如销售表卖出了A04商品,商品表没有A01(现实中不可能发生)
【新建度量值】
行数 = COUNTROWS('商品表')
VALUES编码 = COUNTROWS(VALUES('商品表'[商品编码]))
DISTINCT编码 = COUNTROWS(DISTINCT('商品表'[商品编码]))
VALUES进价 = COUNTROWS(VALUES('商品表'[进价]))
DISTINCT进价 = COUNTROWS(DISTINCT('商品表'[进价]))
矩阵表值上放5个度量值:

-- VALUES出现了空白行,DISTINCT正确
-- 因为在模型视图中,商品表和销售表建立了关系,A04不在商品表里,但在销售表里,VALUES也会把它算作一行;DISTINCT排除该问题,不返回
(2) DISTINCT函数允许列名或任何有效的表表达式作为其参数,但VALUES函数仅接受列名或表名作为参数
十二. 条件判断函数【基础】
1.IFERROR【遇到错误时使用指定数值替换】

销售金额 = IFERROR('例1'[销售数量]*'例1'[单价],BLANK())
-- 如果表达式遇到错误则返回空

销售金额 = IFERROR('例1'[销售数量]*'例1'[单价],"不能计算") 错误!!!
-- IFERROR只能返回空或者数值

销售金额 = IFERROR('例1'[销售数量]*'例1'[单价],0)

2.IF条件判断
IF(条件, A, [B])
检查是否满足条件,如果为 TRUE 则返回A,如果为 FALSE 则返回B;
B可以省略不写,省略时返回为空,比如满足某个分数时返回“优秀”,不满足的时候不写。
IF适合条件比较少的时候使用,如果条件太多,嵌套太多,不方便使用。
案例一:
【新建列】
称呼 = IF('例2'[性别]="男","先生","女士")

案例二:
间隔 = IF('例5'[取款日期]=BLANK(),BLANK(),'例5'[取款日期]-'例5'[存款日期])
-- 默认返回日期类型,列工具 -> 数据类型 -> 整数,即可显示为整数

3.SWITCH多项条件判断
SWITCH(表达式, 值1, 结果1, 值2, 结果2, ..., [else])
根据表达式的值返回不同结果;最后一个参数可以省略不写,代表以上值都不满足会返回什么,省略时返回为空。
案例:
月份 = SWITCH('例3'[月],
1, "1月", 2, "2月",
3, "3月", 4, "4月",
5, "5月", 6, "6月",
7, "7月", 8, "8月",
9, "9月", 10, "10月",
11, "11月", 12, "12月",
"未能识别")

SWITCH特殊用法:
使用TRUE作为第一参数的作用是,返回条件判断列表中第一个为TRUE的结果。
-- 如果是多个字段同时判断:'例4'[年龄]<30 && '例4'[性别]="男"
年龄段 = SWITCH(TRUE(),
'例4'[年龄]<30,"30岁以下",
'例4'[年龄]<40,"30-40岁",
'例4'[年龄]<50,"40-50岁",
"50岁以上")

-- 比如35,第一个为TRUE是在判断<40的时候,所以返回“30-40岁”,后面的条件不看了
十三. 安全除法DIVIDE与按层级计算ISINSCOPE函数
1.安全除法
语法:DIVIDE(分子,分母,[替换结果])
替换结果可以省略不写,省略时返回为空。
除法 = [分子]/[分母]

-- 分母为0 时返回无穷大
安全除法 = DIVIDE(分子,分母,BLANK())
安全除法 = DIVIDE(分子,分母,0)
2.按层级计算ISINSCOPE函数
ISINSCOPE函数的意思:是否在范围内
官方释义:当指定的列是级别层次结构中的级别时,返回true。
【新建度量值】
层级占比 = SWITCH(TRUE(),
ISINSCOPE('商品表'[商品名称]),DIVIDE('度量值'[总金额],CALCULATE('度量值'[总金额],ALL('商品表'[商品名称]))),
ISINSCOPE('商品表'[产品类别]),DIVIDE('度量值'[总金额],CALCULATE('度量值'[总金额],ALL('商品表'[产品类别]))),
DIVIDE('度量值'[总金额],CALCULATE('度量值'[总金额],ALL('商品表'[商品名称])))
)
矩阵表行上放('商品表'[产品类别]、'商品表'[商品名称]) -> 产生了层级关系,值上放'度量值'[层级占比]:

-- 判断当前行是否属于[产品类别]层级,如果是,则计算该产品类别总销量占所有产品类别总销量的占比;比如:手机类总销量占所有产品类别总销量的46%
-- 判断当前行是否属于[产品名称]层级,如果是,则计算该产品名称总销量占其父层级下所有产品总销量的占比;比如:小米10占手机类产品总销量的7%
-- 如果既不是[产品名称]级别,又不是[产品类别]级别,则直接计算(可以不写,如果不写,总计行为空)
-- 层级关系跟数据源表没有关系,主要取决于拉矩阵的时候行那一栏怎么放
十四. ISCROSSFILTERED函数和ISFILTERED函数的区别
语法:
ISFILTERED(TableNameOrColumnName)
在存在针对指定列的直接筛选器时,返回 true。
-- 只有对指定列筛选时才返回true
ISCROSSFILTERED(TableNameOrColumnName)
在对指定表或列进行交叉筛选时,返回 true。
-- 对表中任意列进行筛选都会返回true
【新建表】
日期表 = ADDCOLUMNS(
CALENDAR(DATE(2019,1,1),DATE(2021,12,31)),
"年",YEAR([Date]),
"月",MONTH([Date]),
"周",WEEKNUM([Date]),
"年季度",YEAR([Date])&"Q"&ROUNDUP(MONTH([Date])/3,0),
"年月",YEAR([Date])*100+MONTH([Date]),
"年周",YEAR([Date])*100+WEEKNUM([Date]),
"星期几",WEEKDAY([Date])
)

【新建度量值】
ISFILTERED测试 = ISFILTERED('日期表'[Date])
ISCROSSFILTERED测试 = ISCROSSFILTERED('日期表'[Date])
报表视图添加切片器,字段使用'日期表'[年月];添加矩阵表,值上放2个度量值:
-- 不筛选年月

-- 筛选年月

# 因为没有对指定的'日期表'[Date]做筛选,所以“ISFILTERED测试”为FALSE
# 因为对'日期表'做了筛选,所以“ISCROSSFILTERED”为TRUE
案例:实现切片器筛选日期后,展示指定日期倒推12个月的销量数据
【日期表新建列】
年月序号 = SWITCH(
TRUE(),
'日期表'[年]=2019,0+'日期表'[月],
'日期表'[年]=2020,12+'日期表'[月],
'日期表'[年]=2021,24+'日期表'[月]
)

【新建度量值】
前12个月 = IF(
ISCROSSFILTERED('日期表'[年月]),
CALCULATE(VALUES('表'[年月]),FILTER('表','表'[年月序号]<=MAX('日期表'[年月序号])&&'表'[年月序号]>MAX('日期表'[年月序号])-12)),
1
)
-- CALCULATE第一参数可以是一张表,表是计算器,后面筛选这张表的条件就是筛选器
-- VALUES('表'[年月])得到表里年月不重复的值
-- 使用FILTER的原因是需要列和列的比较,CALCULATE默认的筛选器只支持和固定值的比较
-- 不理解这里MAX的作用,尝试不使用MAX直接和'日期表'[年月序号]比较,发现Power BI无法找到'日期表'及其字段(原因未知),且手动输入后报错:

-- 不能直接对比的原因:[年月]在'日期表'中不是唯一值,即使'日期表'过滤出一个[年月]值,还是会对应多个[年月序号](比如选择201901,在日期表中对应了多行数据,也就意味着有多个年月序号,虽然它们的[年月序号]相同,都是1),公式无法确定单个值。
-- MAX换成MIN、AVERAGE是一样的效果
报表视图添加切片器,字段使用'日期表'[年月];添加矩阵表,行上放'表'[年月](只能放'表'里的,不能放'日期表'里的,因为两张表没有连线),值上放'表'[销售金额];选中矩阵表 -> 将'度量值'[前12个月]放到筛选器里 -> 条件为“不为空” -> 应用筛选器:


-- 外部筛选器[前12个月]条件设置成“不为空”:切片器选择201903,则矩阵表值显示201901-201903的销量数据,不满足范围的就不显示
十五. FIRSTNONBLANK与LASTNONBLANK函数
-- FIRSTNONBLANK函数与LASTNONBLANK函数属于表函数,有些时候也可以作为值函数使用
语法:
FIRSTNONBLANK(<列>,<表达式>)
返回列中表达式具有非空白值的第一个值
LASTNONBLANK(<列>,<表达式>)
返回列中表达式具有非空白值的最后一个值
<列>:任何列,或者具有单列的表,也可以是表达式
<表达式>:计算空值的表达式,也就是判定条件
返回结果:单列的表,只有一行数据(也就是只有一个返回值,只不过这个值在表中)
案例一:应用于表函数
【新建表】
表 2 = FIRSTNONBLANK('表'[日期],CALCULATE(SUM('表'[销售])))

-- 求出产生第一笔销售额的日期
-- 表达式可以用度量值或者嵌套CALCULATE,否则会导致计算忽略计算筛选上下文,只考虑行上下文,那么呈现的结果将是2020年1月1日(最小的日期);即不套CALCULATE,每一行对应的表达式值就都是SUM起来的总销售,不是根据日期和姓名筛选后的了
总结:第二个参数的表达式要具备筛选功能
案例二:应用于值函数
-- 求出每个人第一笔销售的销售额

【新建度量值】
每个人第一个不为空的销售 = CALCULATE(
SUM('表'[销售]),
FIRSTNONBLANK('表'[日期],CALCULATE(SUM('表'[销售])))
)
-- 将案例一的表放到CALCULATE筛选器里,用于筛选每个人第一个有销售的日期所产生的销售额
矩阵表行上放'表'[姓名],值上放'度量值'[每个人第一个不为空的销售]

十六. 进阶条件判断函数
1.HASONEFILTER函数【判断是否被筛选】
语法:HASONEFILTER(列名)
HASNOFILTER是被直接筛选影响的。
当指定的列有且只有一个由直接筛选产生的值时,返回true。参数必须使用物理列(表里有什么列就用什么列,可以新建列),不支持表达式。
案例一:
【新建度量值】
总分 = SUM('案例1'[成绩])
HASONEFILTER总成绩 = IF(HASONEFILTER('案例1'[姓名]),[总分],BLANK())

矩阵表行上放'案例1'[姓名],值上放'案例1'[成绩];切片器字段上放'案例1'[姓名];新矩阵表行上放'案例1'[老师],值上放'案例1'[HASONEFILTER总成绩]

-- 指定的列有且只有一个由直接筛选产生的值,HASONEFILTER返回true,IF语句返回总分

-- 指定的列有多个由直接筛选产生的值,HASONEFILTER返回false,IF语句返回BLANK()
案例二:
【新建度量值】
总金额 = SUM('案例2'[销售金额])
-- 如果'案例2'[销售金额]是外汇
外汇转人民币 = IF(HASONEFILTER('汇率'[货币]),FIRSTNONBLANK('汇率'[汇率],1)*'案例2'[总金额],BLANK())
-- 此处的FIRSTNONBLANK函数由于只需要取第一个不为空的值,不牵涉表达式,这种情况第二个参数可以写1,也可以写两个英文双引号"",都代表第二个条件不要,什么都不做,只取汇率里面的第一个
-- 效果:只可以选择一种货币类型进行汇率转换,如果同一个货币类型有多个汇率值,则取第一个;不支持选择多种货币类型进行汇率转换,如果选了多个,则返回空
切片器字段上放'汇率'[货币]用于筛选,矩阵表行上放'案例2'[日期](下拉选择日期,取消层次结构),值上放'案例2'[总金额]、'案例2'[外汇转人民币]


-- -- 如果'案例2'[销售金额]是人民币
人民币转外汇 = IF(HASONEFILTER('汇率'[货币]),DIVIDE('案例2'[总金额],FIRSTNONBLANK('汇率'[汇率],1)),BLANK())

2.HASONEVALUE函数【判断是否只有一行数据】
语法:HASONEVALUE(列名)
通常和IF函数搭配使用,判断某列是否只有一行数据。
经典语句:IF(HASONEVALUE('表名'[列名]),[度量值],BALNK())
案例:
-- 只有一个学生的老师,他们的学生考了多少分
【新建度量值】
总分 = SUM('案例1'[成绩])
姓名唯一的人的分数 = IF(HASONEVALUE('案例1'[姓名]),'案例1'[总分],BLANK())

矩阵表行上放'案例2'[老师],值上放'案例2'[姓名唯一的人的分数]

-- 因为李小龙和叶问这两个老师是唯一的没有重复的,只对应一个学生,所以只显示他们的分数
-- 总计不显示,一般当不想要总计的时候,才会用HASONEVALUE函数,平时用不到
【扩展知识】DATATABLE人工建表
手工建表 - 菜单栏“输入数据“

参数表1 = DATATABLE("字段名",数据类型,{{数据1},{数据2}})
数据类型:INTEGER、DOUBLE、STRING、BOOLEAN、CURRENCY、DATETIME

多字段这样写:
参数表2 = DATATABLE("字段名1",数据类型1,"字段名2",数据类型2,{{数据11,数据12},{数据21,数据22}})
-- 数据11和数据22分别是字段1和字段2的值,以行显示;数据11和数据12是第一行,数据21和数据22是第二行

3.SELECTEDVALUE函数
当指定列只有一个值时返回该值,否则返回替代结果,省略替代结果时返回空值
语法:
SELECTEDVALUE('表名'[列名],[替代结果(省略返回空)])

案例:
-- 实现切片器选择销售量时,报表显示销售量;切片器选择销售额时,报表显示销售额
【新建表】
参数表 = DATATABLE("字段名",STRING,{{"销售量"},{"销售额"}})
切片器字段上放'参数表'[字段名],簇状柱形图X轴放'案例3'[商品名称],Y轴放'案例3'[销售量]、'案例3'[销售金额]
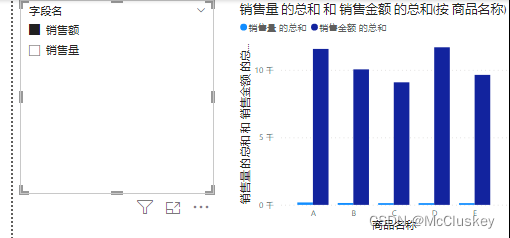
-- 此时切片器选择销售额,柱形图依旧同时显示销售额和销售量
【新建度量值】
值 = SWITCH(SELECTEDVALUE('参数表'[字段名]),"销售额",SUM('案例3'[销售金额]),"销售量",SUM('案例3'[销售量]))
簇状柱形图Y轴换成'案例3'[值]:




十七. 转换函数
1.CURRENCY函数【数字转货币】
作用:将表达式结果转换为货币类型


【新建列】
列 = CURRENCY('CURRENCY'[数值1])


-- "文本1"数据类型改成文本,"日期"数据类型改成日期
2.INT函数【向下舍入】
作用:将表达式转换为整数(向下舍入)
说人话:
当数值为正数时,取整数抹
当数值为负数时,凑零补整
【新建列】
列 = INT('INT'[数值])

3.TRUNC函数【直接取整】
【新建列】
列 = TRUNC('TRUNC'[数值])

4.ROUND函数【四舍五入】
语法:
ROUND(数值,保留小数点的位数)
【新建列】
列 = ROUND('ROUND'[数值],4)

5.MROUND函数【取数值的倍数】
语法:
MROUND(数值,哪个数的倍数)
-- 两个参数的小数点位数必须一致
-- 符号必须一致
MROUND(1.3,0.2) => 1.4
-- 从1.3开始往上找0.2的倍数,最近的是1.4
MROUND(-10,-3) => -9
-- 从-10开始往上找-3的倍数,最近的是-9
MROUND(5,-2) => ERROR
【新建列】
列 = MROUND('MROUND'[数值],5.00)

-- 在6.05附近找2.00的倍数,最近的是6;在7.05附近找2.00的倍数,最近的是8???
6.日期和时间的转换
DATE(年,月,日)
TIME(小时,分钟,秒)
【新建列】
列 = DATE('Date'[年],'Date'[月],'Date'[日])

-- 数据类型选择日期
列 = TIME('Time'[时],'Time'[分],'Time'[秒])

7.CONVERT函数【转换为指定数据类型】
语法:
CONVERT(表达式,数据类型)
数据类型:
INTEGER整型、DOUBLE双精度、STRING字符、BOOLEAN布尔、CUREENCY货币、DATETIME日期时间
【新建列】
列 = CONVERT('CONVERT'[销售数量]*'CONVERT'[单价],STRING)

8.DATEVALUE函数【文本格式的日期转成日期时间格式的日期】
【新建列】
列 = DATEVALUE('DATEVALUE'[文本日期])

-- 数据类型改成日期,否则带时间,因为默认转成日期时间格式
9.TIMEVALUE函数【文本格式的时间转成日期时间格式的时间】
【新建列】
列 2 = TIMEVALUE('Time'[列]

-- 为了测试,列的数据类型改成文本
-- 列2数据类型改成日期,否则带日期,因为默认转成日期时间格式
10.VALUE函数【文本转数值】
语法:
VALUE(<文本>)
返回结果:数值类型,十进制数字
-- 如果文本不是数字、日期或时间格式,则返回错误。
【新建列】
列6 = VALUE('CURRENCY'[文本1])

十八. FORMAT函数【格式化】
语法:
FORMAT(数值或日期,格式)
将值转换为指定格式的文本,通常与DATETIME格式一起使用
【新建列】
列 = FORMAT(DATE('Date'[年],'Date'[月],'Date'[日]),"yyyy年mm月dd日")

具体格式详见官方文档:
FORMAT 函数 (DAX) - DAX | Microsoft Learn
注意几个特殊情况:
1.在格式中输入的字符串要加两个双引
列 = FORMAT(DATE('Date'[年],'Date'[月],'Date'[日]),"""孙兴华"" yyyy")

2.转义字符
列 = FORMAT(DATE('Date'[年],'Date'[月],'Date'[日]),"yyyy \Qq")
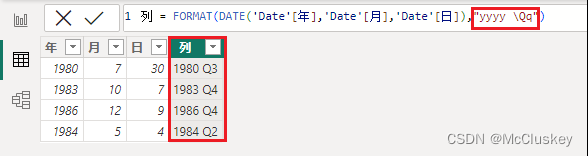
-- Q代表季度,属于格式关键字,想要显示"Q"需要加转义字符反斜杠\,否则Qq会显示两遍季度
3.自定义格式
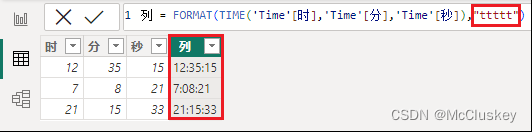
列 = FORMAT(DATE('Date'[年],'Date'[月],'Date'[日]),"dd/mm/yyyy")

列 = FORMAT(TIME('Time'[时],'Time'[分],'Time'[秒]),"h:nn:ss")



十九. 日期时间函数【非智能函数】
1.提取年月日时分秒、季度、当前时间
【新建列】
年 = YEAR('表'[时间日期])
月 = MONTH('表'[时间日期])
日 = DAY('表'[时间日期])
时 = HOUR('表'[时间日期])
分 = MINUTE('表'[时间日期])
秒 = SECOND('表'[时间日期])
季度 = QUARTER('表'[时间日期])
当前日期和时间 = NOW()
当前日期 = TODAY()
-- 可修改当前日期的数据类型为“日期”

2.星期和周
【新建列】
当周的第几天 = WEEKDAY('表'[时间日期],2)

-- 从星期一开始算做一周的开始
不同国家对周几算当周的开始有不同的规定:
-- 第二个参数 = 1
![]()
-- 第二个参数 = 2
![]()
-- 第二个参数 = 3
【新建列】
当年的第几周 = WEEKNUM('表'[时间日期],2)

-- 第二个参数和WEEKDAY类似,用于规定哪天算一周的开始
3.平移指定月份
EDATE(日期,平移月数)
-- 返回按指定月份平移后的日期;正数向后,负数向前
EOMONTH(日期,平移月数)
-- 返回按指定月数平移后的月份的最后一天
举例:
EOMONTH(TODAY(),-1) -- 代表今天的日期向前推一个月的月末日期
【新建列】
平移月份 = EDATE('表'[时间日期],2)
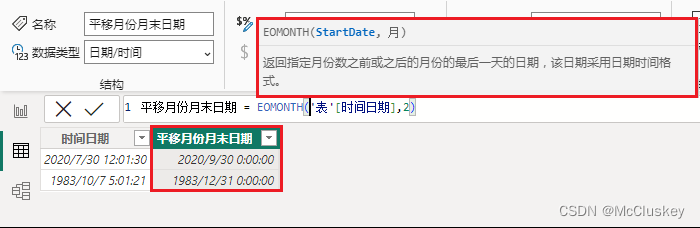
平移月份月末日期 = EOMONTH('表'[时间日期],2)

4.DATEDIFF间隔日期时间
DATEDIFF(起始日期, 结束日期, 间隔单位)
【新建列】
列 = DATEDIFF('表2'[起始日期],'表2'[结束日期],YEAR)

-- Tips: 如果计算保质期要+1,因为生产日期当天就算第一天了
5.YEARFRAC函数
-- 也是用来计算时间间隔的,比DATEDIFF更精确,比如可用于计算工龄
YEARFRAC(起始日期, 结束日期, <计算标准>)
【新建列】
列 = YEARFRAC('表2'[起始日期],TODAY(),0)

-- 自行设置小数点位数
第二个参数:
-- 0

-- 1
![]()
-- 2
![]()
-- 3
![]()
-- 4
![]()
二十. 文本函数
1.CONCATENATE【将两个字符串连接】
语法:
CONCATENATE(<文本1 或 数字1>, <文本2 或 数字2>)
【新建列】
列 = CONCATENATE('CONCATENATE'[文本1], 'CONCATENATE'[文本2])
列 = CONCATENATE('CONCATENATE'[数字1], 'CONCATENATE'[数字2])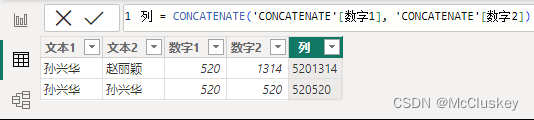
2.EXACT【判断字符是否相同】
语法:
EXACT(<文本1 或 数字1>, <文本2 或 数字2>)
【新建列】
列 = EXACT('CONCATENATE'[文本1], 'CONCATENATE'[文本2])
列 = EXACT('CONCATENATE'[数字1], 'CONCATENATE'[数字2])
应用场景举例:
配合IF语句,如果这两列内容一样返回什么,否则返回什么
3.FIND【找字符串在另一个字符串的起始位置】
返回一个文本字符串在另一个文本字符串中的起始位置;区分大小写;不支持通配符
语法:
FIND(<待查找内容>, <查找范围>, [<起始位置>], [<备选结果>])
[<起始位置>]:开始搜索的位置;如果省略,则起始位置为1,即从第一个字符开始找
[<备选结果>]:未找到文本时返回的值,可设为0、-1或BILANK();如果省略,则找不到时返回错误
【新建列】
列 = FIND('find'[子串], 'find'[字符串])
-- 将excel子串列的VBA改成小写,保存并刷新数据(PowerBI会重新加载数据),表达式报错

-- 传入<起始位置>和<备选结果>
列 = FIND('find'[子串], 'find'[字符串], 6, BLANK())
4.SEARCH【找字符串在另一个字符串的起始位置;不区分大小写;可用通配符】
语法:
SEARCH(<待查找内容>, <查找范围>, [<起始位置>], [<备选结果>])
-- 语法和FIND相同
通配符:?代表一个字符,*代表多个字符
-- 不区分大小写
列 = SEARCH('find'[子串], 'find'[字符串])
-- 使用通配符
列 = SEARCH("孙?华", 'find'[字符串])
5.截取函数
语法:
LEFT([字段名], 取几个字符) -- 从左向右取
RIGHT([字段名], 取几个字符) -- 从右向左取
MID([字段名], 从第几个取, 取几个) -- 从中间开始取
LEN([字段名]) -- 长度
【新建列】
列 = LEFT([字符串], 3)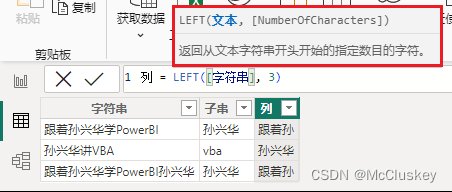
列 = RIGHT([字符串], 3)
列 = MID([字符串], 3, 3)
列 = LEN([字符串])
6.FIXED【数值转字符;按指定小数位四舍五入】
将数值舍入到指定的小数位数,并将结果返回为文本;可以指定返回的结果是否包含千分符
语法:
FIXED(<数字>, [<小数位数>], [<逻辑值>])
[<逻辑值>]:如果为1,则不在返回的文本中显示千分符;如果为0或省略,则在返回的文本中显示千分符
【新建列】
列 = FIXED([数值], 3)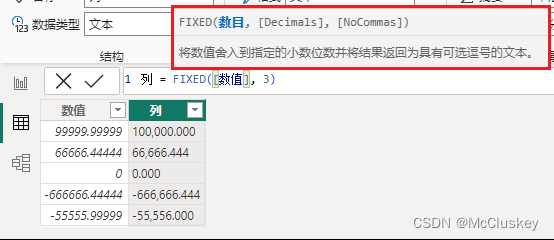
列 = FIXED([数值], 3, 1)
7.大小写转换
语法:
LOWER(<文本>) -- 将文本字符串中的所有字母都转换成小写
UPPER(<文本>) -- 将文本字符串中的所有字母都转换成大写
8.删除空格
删除文本前后的所有空格和单词之间多于一个的空格,保留单词之间的单个空格
语法:
TRIM(<文本>)
【新建列】
列 = TRIM([字符串])
如果要删除特定的空格,可以搭配截取函数LEFT()、RIGHT()、MID()并配合LEN()函数
9.重复字符串
语法:
REPT(<文本>, <重复次数>) -- 按给定的次数重复文本
如果重复次数为0,REPT()返回空白;REPT()函数的结果不能超过32767个字符,否则将返回错误。
【新建列】
列 = REPT([字符串], 2)
列 = REPT([字符串], 0)
二十一. 替换函数
1.REPLACE【按指定位置替换字符串】
将指定位置的字符串转换为新的字符串
语法:
REPLACE(<文本>, <起始位置>, <替换长度>, <新内容>)
如果<替换长度>为空,或者引用包含空值的列,则新内容字符串插入到起始位置,不替换任何字符。
【新建列】
列 = REPLACE('REPLACE'[字符串], 3, 3, "孙兴华")

2.SUBSTITUTE【按指定内容替换字符串】
将指定的字符串替换为新的字符串;区分大小写
语法:
SUBSTITUTE(<文本>, <被替换内容>, <新内容>, [<匹配项>])
[<匹配项>]:代表替换第几个<被替换内容>,如果省略,则会替换所有找到的<被替换内容>
【新建列】
列 = SUBSTITUTE('SUBSTITUTE'[字符串], "孙兴华", "小孙")

二十二. 三角、数学、信息函数【不常用】
找一下老师的笔记
MOD【取余数】
返回指定数字被整除后的余数
语法:
MOD(<被除数>, <除数>)

二十三. 分组与连接函数
1.SUMMARIZECOLUMNS
是一种更灵活、更高效的SUMMARIZE实现方式。在编紫萼查询的时候,可以优先考虑SUMMARIZECOLUMNS。
语法:
SUMMARIZECOLUMNS(<groupBy_columnName1>, [<groupBy_columnName2>], …, [<filterTable>], …, [<name>, <expression>], …)
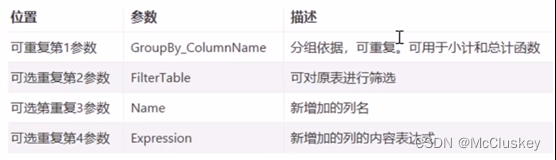
-- GroupBy_columnName参数描述里的可重复代表可以有多个分组依据
案例一:返回不重复姓名
原表:

【新建表】
不重复姓名 = SUMMARIZECOLUMNS('重复姓名'[姓名])

案例二:返回多列不重复
原表:

【新建表】
多列不重复 = SUMMARIZECOLUMNS('多列重复'[年份], '多列重复'[姓名])

注:可以不是同一张表,但是必须有关系的多张表。
案例三:返回汇总表【分组求和;使用第1、3、4参数】
【新建表】
汇总表 = SUMMARIZECOLUMNS('分组求和'[年份], '分组求和'[姓名], "总分", SUM('分组求和'[成绩]))

案例四:返回带筛选功能的汇总表【第二参数】
汇总表筛选 = SUMMARIZECOLUMNS('分组求和'[年份], '分组求和'[姓名], FILTER('分组求和', '分组求和'[科目] = "数学"), "数学", SUM('分组求和'[成绩]))

-- 相当于把原表筛成数学后对其进行
注意:
SUMMARIZECOLUMNS只适合新建表,不能在度量值中使用。
如果需要在度量值中执行分组和新建列时,最可靠的方式是SUMMARIZE+ADDCOLUMNS。
2.ADDMISSINGITEMS【就是一个开关】
语法:
ADDMISSINGITEMS([<展示列>, …], <汇总列>, [<分组列>, …], <筛选条件>)
展示列:需要展示出来的列;可缺省;可多个
汇总列:经过筛选处理之后的表
分组列:用来分组的列;可缺省;可多个
例如:
SUMMARIZE不显示"成绩"为空白的人员
-- 原表

-- 汇总表(不显示孙兴华)

ADDMISSINGITEMS+SUMMARIZE可以显示(这个组合与单独使用SUMMARIZE出来的效果是一样的)
【新建表】
汇总表2 = ADDMISSINGITEMS('分组求和'[年份], '分组求和'[姓名], SUMMARIZECOLUMNS('分组求和'[年份], '分组求和'[姓名], "总分", SUM('分组求和'[成绩])), '分组求和'[年份], '分组求和'[姓名])
第一参数:和SUMMARIZECLOLUMNS相同的分组列
第二参数:SUMMARIZECLOLUMNS表达式
第三参数:和SUMMARIZECLOLUMNS相同的分组列

套ADDMISSINGCOLUMNS开关的场景:想显示空值记录的时候
3.INTERSECT、EXCEPT、UNION
INTERSECT(A, B) - 交集
EXCEPT(A, B) - 差集
UNION(A, B) - 并集
【新建表】
刺杀且死亡名单 = INTERSECT('刺杀名单', '死亡名单')

刺杀未死亡名单 = EXCEPT('刺杀名单', '死亡名单')

刺杀名单和死亡名单并集 = UNION('刺杀名单', '死亡名单')

4.CROSSJOIN笛卡尔积
表1:

表2:

【新建表】
笛卡尔积 = CROSSJOIN('表1', '表2')

二十四. 查找匹配函数
1.CONTAINS【多条件查找】
CONTAINS为简单筛选提供了更好的性能,而CALCULATETABLE适用于复杂的筛选表达式。
【新建度量值】
是否购买过 = CONTAINS('表', '表'[日期], DATE(2020, 12, 2), '表'[姓名], "李四")
-- CONTAINS返回的是布尔值


2.TREATAS【无关系情况下查找匹配】
TREATAS函数时无关系情况下执行查找匹配的最佳选择。
语法:
TREATAS(<table_expression>, <column>[,[column]…])
作用:把什么当做什么
解释:把一参当做二参的筛选器,通过一参筛选二参
注意:一参是唯一值的表
案例一:单列筛选(求各月份的销售目标)
【新建表】
日期表 = ADDCOLUMNS(
CALENDAR(DATE(2020,1,1),DATE(2021,12,31)),
"年",YEAR([Date]),
"月",MONTH([Date]),
"周",WEEKNUM([Date]),
"年季度",YEAR([Date])&"Q"&ROUNDUP(MONTH([Date])/3,0),
"年月",YEAR([Date])*100+MONTH([Date]),
"年周",YEAR([Date])*100+WEEKNUM([Date]),
"星期几",WEEKDAY([Date])
)
"销售目标"表中没有详细日期,无法与"日期表"建立直接的关系。

现在想用日期表筛选销售目标表,比如用'日期表'.[月]筛选'销售目标'.[销售目标]。把日期表的[月]用作筛选条件(一参),而销售目标表的[月份]则是被一参筛选的列(二参)。
【新建度量值】
月度销售目标 = CALCULATE(SUM('销售目标'[销售目标]), TREATAS(VALUES('日期表'[月]), '销售目标'[月份]))
矩阵表行上放日期表的[月],值上放[月销售目标]

案例二:多列筛选(求各年份月份的销售目标)
【新建度量值】
年月销售目标1 = CALCULATE(SUM('销售目标'[销售目标]), TREATAS(VALUES('日期表'[年]), '销售目标'[年份]), TREATAS(VALUES('日期表'[月]), '销售目标'[月份]))
矩阵表行上放日期表的[年],列上放日期表[月],值上放[年月销售目标1]

多条件筛选时,如果数据量比较大,考虑速度问题,可以使用SUMMARIZE进行优化
年月销售目标2 = CALCULATE(SUM('销售目标'[销售目标]), TREATAS(SUMMARIZE('日期表', '日期表'[年], '日期表'[月]), '销售目标'[年份], '销售目标'[月份]))

-- SUMMARIZE和SUMMARIZECOLUMNS的唯一区别就是,前者要先指明是哪个表,然后在指明分组的列,而后者直接指明是哪个表的哪个列;SUMMARAIZECOLUMNS不能写在度量值里,会报错
3.ROW函数【返回一个单行表,其中包含由DAX表达式指定的新列】
语法:
ROW(<Name>, <Expression>, [<Name>, <Expression>], […])
说人话:就是创建一张表
ROW("新列名", 创建这个新列用什么表达式)
案例:
【新建表】
测试表 = ROW("总销量", SUM('Row'[销售量]), "总金额", SUM('Row'[销售金额]))

4.综合案例分析:利用TREATAS函数自由切换坐标轴
(1)利用笛卡尔积做表
思路分析:



【新建表】
坐标轴 =
UNION(
UNION(
CROSSJOIN(ROW("坐标轴", "城市"), VALUES('案例'[城市])),
CROSSJOIN(ROW("坐标轴", "产品"), VALUES('案例'[产品]))
),
CROSSJOIN(ROW("坐标轴", "年份"), VALUES('案例'[年份]))
)
-- UNION一次只能连接2张表,所以要使用两次UNION

-- UNION用第一张表的列名作为合并表的列名,可以手工改一下列名(双击列名),更好理解

(2)第二个切片器
【新建表】
切换 = UNION(ROW("结果", "销量"), ROW("结果", "销售金额")

(3)把两个总度量值写出来
【新建度量值】
总销量 = SUM('案例'[销量])
总金额 = SUM('案例'[销售金额])
(4)分别写显示销量与显示销售金额的度量值
【新建度量值】
显示销量 = SWITCH(
SELECTEDVALUE('坐标轴'[坐标轴]),
"城市", CALCULATE('案例'[总销量], TREATAS(VALUES('坐标轴'[类别]), '案例'[城市])),
"产品", CALCULATE('案例'[总销量], TREATAS(VALUES('坐标轴'[类别]), '案例'[产品])),
"年份", CALCULATE('案例'[总销量], TREATAS(VALUES('坐标轴'[类别]), '案例'[年份]))
)
-- 当切片器单选的时候,如果选"城市",显示各城市销量;如果选"产品",显示各产品销量;如果选"年份",显示各年份销量
显示金额 = SWITCH(
SELECTEDVALUE('坐标轴'[坐标轴]),
"城市", CALCULATE('案例'[总金额], TREATAS(VALUES('坐标轴'[类别]), '案例'[城市])),
"产品", CALCULATE('案例'[总金额], TREATAS(VALUES('坐标轴'[类别]), '案例'[产品])),
"年份", CALCULATE('案例'[总金额], TREATAS(VALUES('坐标轴'[类别]), '案例'[年份]))
)
(5)最后把结果做出来
OK = SWITCH(SELECTEDVALUE('切换'[结果]), "销量", '案例'[显示销量], "销售金额", '案例'[显示金额])
切片器1字段上放'坐标轴'[坐标轴],切片器2字段上放'切换'[结果],簇状柱形图X轴放'坐标轴'[类别],Y轴放'案例'[OK]




5.VAR声明变量
接上节课案例:
显示金额和显示销售我们做了两个度量值,又做了一个OK的度量值。
用VAR一步搞定
【新建度量值】
度量值 =
VAR xiaoliang = SWITCH(
SELECTEDVALUE('坐标轴'[坐标轴]),
"城市", CALCULATE('案例'[总销量], TREATAS(VALUES('坐标轴'[类别]), '案例'[城市])),
"产品", CALCULATE('案例'[总销量], TREATAS(VALUES('坐标轴'[类别]), '案例'[产品])),
"年份", CALCULATE('案例'[总销量], TREATAS(VALUES('坐标轴'[类别]), '案例'[年份]))
)
VAR jine = SWITCH(
SELECTEDVALUE('坐标轴'[坐标轴]),
"城市", CALCULATE('案例'[总金额], TREATAS(VALUES('坐标轴'[类别]), '案例'[城市])),
"产品", CALCULATE('案例'[总金额], TREATAS(VALUES('坐标轴'[类别]), '案例'[产品])),
"年份", CALCULATE('案例'[总金额], TREATAS(VALUES('坐标轴'[类别]), '案例'[年份]))
)
RETURN SWITCH(SELECTEDVALUE('切换'[结果]), "销量", xiaoliang, "销售金额", jine)
簇状柱形图Y轴换成'案例'[度量值],效果和'案例'[OK]一致

除了可以定义度量值,还可以定义新建列:
【新建列】
评价 =
VAR zongfen = '案例2'[数学] + '案例2'[英语] + '案例2'[语文]
RETURN IF(zongfen >= 270, "优秀", "一般")
-- 评价三门科目总分

等同于:
评价 = IF('案例2'[数学] + '案例2'[英语] + '案例2'[语文] >= 270, "优秀", "一般")
【实战案例】模糊查找
【新建度量值】
查询类型 =
VAR a = VALUES('查询表'[类型])
VAR b = MAX('销售表'[类型])
RETURN
IF(
COUNTROWS(FILTER(a, SEARCH('查询表'[类型], b, 1, 0) > 0)) > 0,
b,
BLANK()
)
-- MAX('销售表'[类型]):借助聚合函数返回[类型]的值,这里的作用单纯是为了将[类型]列进行聚合,否则无法在查询函数中使用,用MIN也可以
-- 通过IF语句进行判断,符合条件显示,否则显示为空;内部利用FILTER进行上下文传递,将原本没有联系的维度和事实表连接在一起
矩阵表值上放'查询表'[查询类型],行上放'销售表'[电影],切片器字段上放'查询表'[类型]


6.检查字符串是否被包含
FIND和SEARCH函数都可以查找指定字符串所在的位置,如果只需要检查字符串是否被包含,可以使用CONTAINSSTRING和CONTAINSSTRINGEXACT,它们只进行逻辑判断,计算效率更高。
(1) CONTAINSSTRING 支持通配符,不区分大小写
CONTAINSSTRING(<WITHINTEXT>, <FINDTEXT>)
列 = CONTAINSSTRING("跟着孙兴华学VBA", "孙?华")
如果一个文本字符串包含另一个文本字符串,则返回TRUE。
CONTAINSSTRING支持通配符,不区分大小写,可以执行模糊匹配,使用时注意它的参数顺序。
问号(?):问号匹配任何单个字符
星号(*):星号匹配任何字符序列
如果想找到的是问号或星号本身,请在字符前键入一个波浪号(~) --即转义字符
(2) CONTAINSSTRINGEXACT 不支持通配符,区分大小写
CONTAINSSTRING(<WITHINTEXT>, <FINDTEXT>)
列 = CONTAINSSTRING("跟着孙兴华学VBA", "孙兴华")
如果一个文本字符串包含另一个文本字符串,则返回TRUE。
CONTAINSSTRINGEXACT不支持通配符,区分大小写,使用时注意它的参数顺序。
二十五. 排名函数
1.RANKX排名
语法:
RANKX(<table>, <expression>, [<value>], [<order>], [<ties>])
第一参<table>:表,也可以是用函数生成的表
第二参<expression>:表达式,聚合表达式或写好的度量值
第三参<value>:值,可选,可以是个聚合表达式,也可以是直接的数值;当<value>省略时,用<expression>代替
第四参<order>:排序,ASC或DESC,升序或降序
第五参<ties>:排序方法,skip国际排序(下一名的排序等于之前所有排序的数量+1),dense中国式排序(只累加排序,不考虑数量)-- 看PowerQuery S01E11排名
【新建度量值】
总金额 = SUM('销售表'[销售金额])
排名 = RANKX(ALL('销售表'), '销售表'[总金额])
矩阵表行上放'销售表'[商品编码],值上放'销售表'[总金额]、'销售表'[排名]

两个问题:总计的排名列不应该显示、A007和A008的排名不应该显示
想要让总计不显示,通用方法:IF + HASONEVALUE
【新建度量值】
排名优化1 = IF(HASONEVALUE('销售表'[商品编码]), RANKX(ALL('销售表'), '销售表'[总金额]), BLANK())
矩阵表值上加上'销售表'[排名优化1]
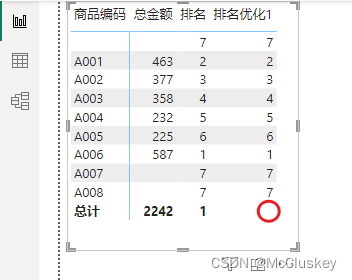
去掉A007和A008
AND(TRUE, TRUE)才返回TRUE
AND(TRUE, FALSE)就返回TRUE
【新建度量值】
排名优化2 = IF(AND(HASONEVALUE('销售表'[商品编码]), '销售表'[总金额] >0), RANKX(FILTER(ALL('销售表'), '销售表'[总金额] > 0), '销售表'[总金额], , DESC), BLANK())
矩阵表值上只放'销售表'[排名优化2]

ALL函数是绝对排名的用法,如果是相对排名,可以自行替换成ALLSELECTED。
如果不输入第三参,第二参也是第三参,一旦输入第三参,结果显示的是第三参按照第二参排名的位置。
假如有一份普通中学学生成绩的分数,和一份重点中学成绩排名,向看看普通中学的学生在重点中学能排第几,这就是实际第三参的用途。
-- 第三参没有展开讲,需看官方文档
【进阶】RANKX进行明细级别的排名
【新建列】
单品销售排名 = RANKX(FILTER('案例2', '案例2'[品种] = EARLIER('案例2'[品种])), '案例2'[销售金额])

2.TOPN【返回满足条件的前N行记录】
RANKX适合计算明细的名次数据,TOPN则可以批量返回结果,从一张表中返回所有满足条件的前N行记录。
它的特点是返回的不是值,而是前N行的表。
语法:
TOPN(N值, 表, [表达式], [顺序可选项])
N值:排名前N位
表:想要提取的表
[表达式]:用来排序的度量值或表达式
[顺序可选项]:排序方式,0/FALSE/DESC降序,1/TRUE/ASC升序
【新建表】
查询销售前2名的记录 = TOPN(2, 'TOPN', 'TOPN'[销售金额], DESC)

-- 求前2名的销售金额之和
前2名的销售金额之和 = SUMX(TOPN(2, 'TOPN', 'TOPN'[销售金额], DESC), 'TOPN'[销售金额])

-- 因为新建列是行上下文,不具备筛选功能,可以建成度量值或套上CALCULATE,但是在此例中没有意义,所以就不套了
注意,当销售金额有重复值时,TOPN拿到的不一定是前两名,并列的也会算在里面占用名额。在实际分析中,通常不是配合SUMX使用,而是配合AVERAGEX使用计算平均值。
案例:
-- 计算销售量前3名共卖了多少
【新建度量值】
销售额 = SUM('TOPN'[销售金额])
【新建表】
测试表 = TOPN(3, ALL('TOPN'), 'TOPN'[销售额], DESC)

【新建度量值】
销售量前3名共卖了多少 = CALCULATE('TOPN'[销售额], TOPN(3, ALL('TOPN'), 'TOPN'[销售额], DESC)
卡片图字段放'TOPN'[销量表前3名共卖了多少]

-- 计算销售量前3名的店铺共卖了多少:找出销售额最高的3家店铺,然后把金额加在一起
【新建表】(把TOP3的店号取出来)
测试表2 = TOPN(3, ALL('TOPN'[店号]), 'TOPN'[销售额], DESC)

【新建度量值】(通过TOP3店号筛选'TOPN'表,从而计算TOP3店铺的总销售额)
销售量前3名的店铺共卖了多少 = CALCULATE('TOPN'[销售额], TOPN(3, ALL('TOPN'[店号]), 'TOPN'[销售额], DESC))
卡片图字段放'TOPN'[销售量前3名的店铺共卖了多少]

【新建度量值】
前3名的店铺销售占比 = DIVIDE('TOPN'[销售量前3名的店铺共卖了多少], CALCULATE('TOPN'[销售额], ALL('TOPN'[店号])))
-- 这里ALL函数的参数也可以是'TOPN'表,效果是一样的,都是计算整张表的总销售额
卡片图字段放'TOPN'[前3名的店铺销售占比]

3.CONCATENATEX【将多个值连接到一起,以文本的形式输出】
语法:
CONCATENATEX(<Table>, <Expression>, [Delimiter], [OrderBy_Expression], [Order1], …)
第一参<Table>:用于表达式每行计值的表;第一参数必须是唯一值的表
第二参<Expression>:用于逐行计算的表达式
第三参[Delimiter]:连接表达式结果的连接符
第四参[OrderBy_Expression]:排序使用的表达式
第五参[Order1]:排序逻辑
案例一:
【新建度量值】
三部曲 = CONCATENATEX(VALUES('CONCATENATEX'[人物]), 'CONCATENATEX'[人物], ",", 'CONCATENATEX'[人物], DESC)
矩阵表行上放'CONCATENATEX'[小说],值上放'CONCATENATEX'[三部曲]

-- 按人物姓名首字母降序排
案例二:对结果进行排序(查询每个人哪天买了东西)

【新建度量值】
度量值1 = CONCATENATEX(VALUES('流水'[购物日期]), FORMAT('流水'[购物日期], "yyyy/mm/dd"), "、", '流水'[购物日期], ASC)
矩阵表行上放'花名册'[姓名],值上放'花名册'[度量值1]

等效表达式:
度量值1 = CONCATENATEX(RELATEDTABLE('流水'), FORMAT('流水'[购物日期], "yyyy/mm/dd"), "、", '流水'[购物日期], ASC)
-- 花名册找流水表,一端找多端,用RELATEDTBALE引路人
案例三:CONCATENATEX综合案例
-- 原数据

Step1. 利用CONCATENATEX函数将多个值连接在一起
【新建度量值】
购买商品 = CONCATENATEX(VALUES('补充案例'[商品]), '补充案例'[商品], "、")
Step2. 让总计栏显示为空(通用方法:IF + HASONEVALUE)
【修改度量值】
购买商品 = IF(HASONEVALUE('补充案例'[买家昵称]), CONCATENATEX(VALUES('补充案例'[商品]), '补充案例'[商品], "、"))
矩阵表行上放'补充案例'[卖家昵称],值上放'补充案例'[购买商品]

Step3. 计算购买数量和金额
购买数量 = SUM('补充案例'[销售数量])
消费金额 = SUMX('补充案例', '补充案例'[单价] * '补充案例'[购买数量])
-- SUM函数的参数只能是物理列,不能是表达式;可以先在表中新建列计算乘积,再到度量值里SUM,但是数据量大的情况下耗费内存;最好的方法是直接在度量值里用SUMX,一步搞定计算表达式及求和

矩阵表值上加'补充案例'[购买数量]和'补充案例'[消费金额]

Step4. 计算客户等级
【新建度量值】
客户等级 = IF(HASONEVALUE('补充案例'[买家昵称]), SWITCH(
TRUE(),
'补充案例'[消费金额] >= 3000, "金牌客户",
'补充案例'[消费金额] >= 1000, "银牌客户",
"铜牌客户"
))
-- SWITCH函数第一参数为TRUE()的效果:返回条件判断列表中第一个为TRUE的结果
矩阵表值上加'补充案例'[客户等级]

二十六. 人工造表最终方案
ADDCOLUMNS 从指定的表开始添加列
SELECTCOLUMNS 从空表开始添加列
1.ADDCOLUMNS
语法:
ADDCOLUMNS(<表>, <名称1>, <表达式1>, …) 返回具有DAX表达式指定的新列的表
【新建表】
日期表 = ADDCOLUMNS(
CALENDAR(DATE(2019,1,1),DATE(2021,12,31)),
"年",YEAR([Date]),
"季度",ROUNDUP(MONTH([Date])/3, 0),
"月",MONTH([Date]),
"周",WEEKNUM([Date]),
"年季度",YEAR([Date])&"Q"&ROUNDUP(MONTH([Date])/3,0),
"年月",YEAR([Date])*100+MONTH([Date]),
"年周",YEAR([Date])*100+WEEKNUM([Date]),
"星期几",WEEKDAY([Date])
)
解析:
(1) CALENDAR(<开始日期>, <结束日期>) 创建一张开始日期和节数日期之间的日期表

(2) 季度
ROUNDUP(<数目>, <[NumberOfDigits]>) 从零开始,向上舍入数值
e.g.
ROUNDUP(1.88) 向上取整数,返回2
ROUNDUP(1.88, 1) 保留一位小数向上取,返回1.9
数学题:
1/3=0.3333,向上舍入保留0位小数点,就是1
2/3=0.6667,向上舍入保留0位小数点,就是1
4/3=1.3333,向上舍入保留0位小数点,就是2
案例:
向'表'添加两列,分别是各班级总分和平均分
【新建表】
表2 = ADDCOLUMNS('表', "总分", CALCULATE(SUM('数据'[分数])), "平均分", CALCULATE(AVERAGE('数据'[分数])))
-- 因为要筛选,所以要套CALCULATE,也可以写度量值

【修改表】筛选出平均分小于50的
表2 = FILTER(ADDCOLUMNS('表', "总分", CALCULATE(SUM('数据'[分数])), "平均分", CALCULATE(AVERAGE('数据'[分数]))), [平均分] < 50)
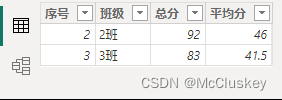
2.SELECTCOLUMNS
语法:
SELECTCOLUMNS(<表>, <名称1>, <表达式1>, …) 返回具有从表中选择的列以及DAX表达式指定的新列的表
第1参<表>:从中选择列的表
第2参<名称>:要添加的新列的名称,可重复
第3参<表达式>:要添加的新列的表达式,可重复
案例:

【新建表】
表3 = SELECTCOLUMNS('销售表',
"销售日期", '销售表'[日期],
"商品名称", RELATED('商品表'[名称]),
"销售数量", '销售表'[销售量],
"销售金额", '销售表'[销售量] * RELATED('商品表'[进价])
)
-- RELATED:销售表找商品表,多端找一端,使用RELATED引路人

二十七. 日期时间函数【智能函数】
27.1 计算累计值
计算累计有2类常用的时间智能函数:
以DATESYTD为代表的返回日期值的表函数、以TOTALYTD为代表的返回标量值的函数
YTD:计算本年的年初至今
QTD:季初至今
MTD:月初至今
1.DATESYTD类【已淘汰】
语法:
DATESYTD(<Dates>, <[YearEndDate]>) 返回此年度中截至当前日期的一组日期
第1参数:日期格式的列或返回单列的表达式,通常使用日期表的日期列
第2参数:年截止日,日期字符串,忽略年
-- 以表中最大日期作为本年
原始表:

【新建表】
测试表 = DATESYTD('表'[日期])
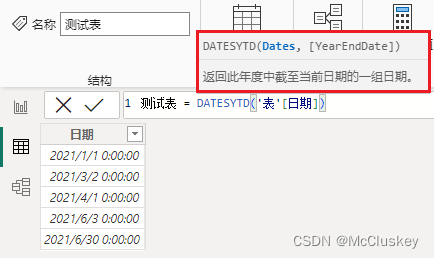
-- 原始表最大日期是2021年的,所以返回2021年的年初至今日期
测试表 = DATESQTD('表'[日期])

测试表 = DATESMTD('表'[日期])

总结:
返回的是一张表
(1) DATESYTD(年初至今)
根据日期数据决定,相当于把日期数据排序,找到最大的年,再求年至今。如果数据中最大的年是2021年,那就计算2021年;如果数据中最大的年是2030年,那就计算2023年
(2) DATESQTD(季初至今)
先找到最大年,再找最大月,确定最大月所在季度后,将这个时间表拿出来
(3) DATESMTD(月初至今)
先找到最大年,再找最大月,将这个时间表拿出来
案例:计算年初至今的销售量
【新建度量值】
总销售 = SUM('表'[销售])
年初至今 = CALCULATE('测试表'[总销售], DATESYTD('表'[日期]))
卡片图字段上放'表'[年初至今]

-- TOTALYTD类函数可以代替CALCULATE+DATESYTD这样的组合。
2.TOTALYTD类【推荐】
【修改度量值】
年初至今 = TOTALYTD('测试表'[总销售], '表'[日期])

语法:
TOTALYTD(<表达式>, <日期列>, <[筛选器]>, <[截止日期]>)
第1参<表达式>:返回标量值的表达式
第2参<日期列>:包含日期的列
第3参<[筛选器]>:可选,应用于当前上下文的筛选器参数,可以使布尔表达式或表表达式;即先把表筛选完之后再去算YTD
第4参<[截止日期]>:带有日期的文本字符串,用于定义年末日期,默认值为12月31日
TOTALYTD:计算本年的年初至今
TOTALQTD:季初至今
TOTALMTD:月初至今
【新建度量值】
年初至今1 = TOTALYTD('测试表'[总销售], '表'[日期], FILTER('表', '表'[销售] < 50))

年初至今2 = TOTALYTD('测试表'[总销售], '表'[日期], FILTER('表', '表'[销售] < 50), "03/31")
-- 3.31定义为年末日期,则从4.1开始算作一年的开始

通常6月30日是财务年度的结束日期,每年的7月1日是财务年的开始日:
TOTALYTD([总销量], '表'[日期], "06-30")
27.2 同比与环比
同比率 = (本期 - 去年同期) / 去年同期 * 100%
环比率 = (本期 - 上期) / 上期 * 100%
上期可以是上季度、上月、上周,甚至上一日

1.同比推荐:SAMEPERIODLASTYEAR【前一年】
语法:
SAMEPERIODLASTYEAR(<日期列>)
官方:返回当前筛选上下文中前一年的一组日期
说人话:在表中找到日期列最大的年、月、日,找到它的同比时间
原始表:

【新建表】测试
前一年 = SAMEPERIODLASTYEAR('表'[日期])

-- 先确定好哪个是今年,然后再找到去年;时间区间相同,今年1.1~6.30对应去年1.1~6.30
【新建度量值】计算同比
总销售 = SUM('表'[销售])
同比销售金额 = CALCULATE([总销售], SAMEPERIODLASTYEAR('表'[日期]))
卡片图字段上放'表'[同比销售金额]

-- 结果:1+0+2+3+4+5 = 15
2.环比:DATEADD
语法:
DATEADD(<日期列>, <偏移量>, <偏移单位>)
第1参<日期列>:包含日期的列
第2参<偏移量>:一个整数,从日期列中添加或减去的时间间隔数
第3参<偏移单位>:偏移量使用的单位,DAY/MONTH/QUARTER/YEAR
-- 返回的是一张表
原始表:
【新建表】测试
返回的是一张表 = DATEADD('DATEADD'[日期], 0, YEAR)

返回的是一张表 = DATEADD('DATEADD'[日期], 1, YEAR)

返回的是一张表 = DATEADD('DATEADD'[日期], -1, YEAR)

【新建度量值】测试
总销售 = SUM('DATEADD'[销售])
上年 = CALCULATE([总销售], DATEADD('DATEADD'[日期], -1, YEAR)
矩阵表行上放'DATEADD'[日期],值上放'DATEADD'[总销售]、'DATEADD'[上年]

案例:
原始表:

【新建度量值】
总销售 = SUM('表2'[销售])
上年 = CALCULATE('表2'[总销售], DATEADD('表2'[日期], -1, YEAR))
上月 = CALCULATE('表2'[总销售], DATEADD('表2'[日期], -1, MONTH))
上季 = CALCULATE('表2'[总销售], DATEADD('表2'[日期], -1, QUARTER))
矩阵表行上放'表2'[日期],值上放'表2'[上年]、'表2'[上月]、'表2'[上季]
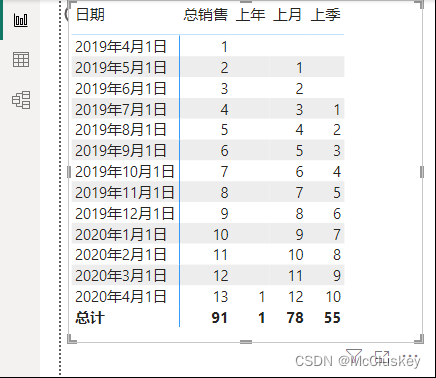
-- 7月的上季销售就是上季度第1个月的销售,即4月的销售;同理,8月的上季销售就是上季度第2个月的销售,即5月的销售
【新建度量值】算环比
本月销售 = TOTALMTD('表2'[总销售], '表2'[日期])
上月销售 = TOTALMTD('表2'[总销售], DATEADD('表2'[日期], -1, MONTH))
卡片图字段上放'表2'[本月销售],卡片图字段上放'表2'[上月销售]


和原始表一致:

3.利用时间计算累积值:PARALLELPERIOD
区别:
(1)PARALLELPERIOD函数返回的是完整的时间范围,而DATEADD函数返回的结果是可以间断的
(2)PARALLELPERIOD函数针对的是一段范围的数据汇总;DATEADD函数通常用来计算同比环比问题,针对的是某一个点
语法:
PARALLELPERIOD(<日期列>, <偏移量>, <偏移单位>)
第1参<日期列>:包含日期的列
第2参<偏移量>:一个整数,从日期列中添加或减去的时间间隔数
第3参<偏移单位>:偏移量使用的单位,DAY/MONTH/QUARTER/YEAR
【新建度量值】测试
总销售 = SUM('表2'[销售])
DATEADD = CALCULATE('表2'[总销售], DATEADD('表2'[日期], -1, QUARTER))
PARALLELPERIOD = CALCULATE('表2'[总销售], PARALLELPERIOD('表2'[日期], -1, QUARTER))

矩阵表行上放'表2'[日期],值上放'表2'[DATEADD]、'表2'[PARALLELPERIOD]

-- '表2'[PARALLELPERIOD]返回的是上个季度销售的总和
案例:
【新建度量值】
本季销售 = CALCULATE('表2'[总销售], PARALLELPERIOD('表2'[日期], 0, QUARTER))
上季销售 = CALCULATE('表2'[总销售], PARALLELPERIOD('表2'[日期], -1, QUARTER))
切片器字段上放'表2'[日期];折线图X轴上放'表2'[日期],Y轴上放'表2'[本季销售]、'表2'[上季销售]

-- 一般用于图表中,而不是计算环比值
27.3 计算移动总计
1.DATESINPERIOD
语法:
DATESINPERIOD(<日期列>, <起始日期>, <偏移量>, <偏移单位>)
返回给定区间中的所有日期组成的单列形式的表。
第1参<日期列>:包含日期的列
第2参<起始日期>:日期表达式
第2参<偏移量>:一个整数,从日期列中添加或减去的时间间隔数
第3参<偏移单位>:偏移量使用的单位,DAY/MONTH/QUARTER/YEAR
案例1:统计数据表中最后一天倒推最近12个月的销售额
原始表:

【新建表】测试
测试表 = DATESINPERIOD('表3'[日期], MAX('表3'[日期]), -1, YEAR)

【新建度量值】
测试 = CALCULATE(SUM('表3'[销售]), DATESINPERIOD('表3'[日期], MAX('表3'[日期]), -1, YEAR))
卡片图字段上放'表3'[测试]

案例2:求最近30天的移动平均
原始表:

【新建表】测试
测试表 = DATESINPERIOD('表4'[日期], MAX('表4'[日期]), -30, DAY)

【新建度量值】
移动平均 = CALCULATE(SUM('表4'[销量]), DATESINPERIOD('表4'[日期], MAX('表4'[日期]), -30, DAY)) / 30
卡片图字段上放'表3'[移动平均]

案例3:从上月算起,过去的3个月的日期
【新建表】
表 = DATESINPERIOD('表4'[日期], EOMONTH(MAX('表4'[日期]), -1), -3, MONTH)
-- EOMONTH函数用于平移指定月份(笔记19.03)

补充拓展知识1:LASTDATE与MAX的区别
LASTDATE返回的是一个表,MAX返回的是一个值。

在这里,使用MAX和LASTDATE都可以,等效表达式:
测试表 = DATESINPERIOD('表4'[日期], LASTDATE('表4'[日期]), -30, DAY)

但在有的情况下,这两个函数是有区分的,因为它们的返回值类型不同:
CALCULATE([度量值], LASTDATE('某张表'[日期列]))
CALCULATE([度量值], FILTER('某张表', '某张表'[日期列] = MAX('某张表'[日期列])))
当用于CALCULATE或CALCULATETABLE筛选器时,习惯用LASTDATE或FIRSTDATE而不是MAX或MIN。
补充拓展知识2:动态日期表
【新建表】
日期表 = ADDCOLUMNS(
CALENDAR(FIRSTDATE('表4'[日期]),LASTDATE('表4'[日期])),
"年",YEAR([Date]),
"季度",ROUNDUP(MONTH([Date])/3, 0),
"月",MONTH([Date]),
"周",WEEKNUM([Date]),
"年季度",YEAR([Date])&"Q"&ROUNDUP(MONTH([Date])/3,0),
"年月",YEAR([Date])*100+MONTH([Date]),
"年周",YEAR([Date])*100+WEEKNUM([Date]),
"星期几",WEEKDAY([Date])
)
-- 使用FIRSTDATE和LASTDATE函数自动生成数据表的日期表,而无需手动填入日期

2.ENDOFMONTH与STARTOFMONTH
语法:
ENDOFMONTH(<日期列>) 返回当月最后一天
STARTOFMONTH(<日期列>) 返回当月第一天
季度:
ENDOFQUARTER(<日期列>) 返回当季度最后一天
STARTOFQUARTER(<日期列>) 返回当季度第一天
年:
ENDOFYEAR(<日期列>, <[年度截止日期]>)
返回当年最后一天;<[年度截止日期]>:包含日期的文本字符串,用于定义年末日期,默认值为12月31日
STARTOFYEAR(<日期列>, <[年度截止日期]>)
返回当年第一天;<[年度截止日期]>:包含日期的文本字符串,用于定义年末日期,默认值为12月31日
【新建度量值】
每月最后3天销量 = CALCULATE(SUM('表4'[销量]), DATESINPERIOD('表4'[日期], ENDOFMONTH('表4'[日期]), -3, DAY))
矩阵表行上放'表4'[日期]层级的月份(都是2020年的),值上放'表4'[每月最后3天销量]
每月前3天销量 = CALCULATE(SUM('表4'[销量]), DATESINPERIOD('表4'[日期], STARTOFMONTH('表4'[日期]), -3, DAY))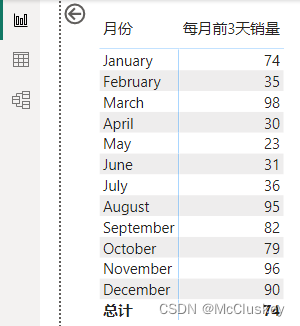
进阶:返回当前上下文中最后一个日期或第一个日期
【新建表】
ENDOFMONTH('表4'[日期]) 返回当前上下文中最后一个日期,类似MAX或LASTDATE函数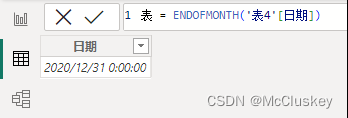
STARTDOFMONTH('表4'[日期]) 返回当前上下文中第一个日期,类似MIN或FIRSTDATE函数
3.DATESBETWEEN区间日期
语法:
DATEDBETWEEN('表'[日期], 开始日期, 结束日期) 返回两个给定日期之间的日期
【新建表】测试
测试表 = DATESBETWEEN('表4'[日期], DATE(2020, 1, 1), DATE(2020, 1, 2))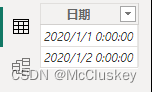
注意,如果开始日期大于结束日期,结果为空。
【新建度量值】
区间销量 = CALCULATE(SUM('表4'[销量]), DATESBETWEEN('表4'[日期], DATE(2020, 1, 1), DATE(2020, 1, 2)))
卡片图字段上放'表4'[区间销量]
27.4 NEXT系列函数
1.NEXT系列函数【下一个】
表函数:
NEXTDAY【下一天】、NEXTMONTH【下一月】、NEXTDAY【下一季】、NEXTDAY【下一年】
例如:
DATESBETWEEN('表'[日期], DATE(2020, 1, 1), DATE(2020, 3, 10))
返回2020/1/1至2020/3/10这个期间的日期,如果在最外层套上NEXTDAY,就得到了2020/3/11这个日期的表。
案例:NEXTDAY实现错位值
原始表:

【新建度量值】
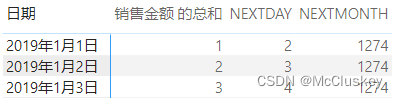
NEXTDAY = CALCULATE(SUM(NEXT[销售金额]), NEXTDAY('NEXT'[日期]))
矩阵表行上放'NEXT'[日期],值上放'NEXT'[销售金额]、'NEXT'[NEXTDAY]

例如:
DATESBETWEEN('表'[日期], DATE(2020, 1, 1), DATE(2020, 3, 10))
返回2020/1/1至2020/3/10这个期间的日期,如果在最外层套上NEXTMONTH,就得到了2020/4/1至2020/4/30这个日期的表。
案例:NEXTMONTH实现下个月销售的总计
【新建度量值】
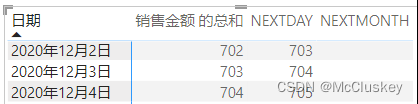
NEXTMONTH = CALCULATE(SUM(NEXT[销售金额]), NEXTMONTH('NEXT'[日期]))
矩阵表值上加'NEXT'[NEXTMONTH]

2.PREVIOUS系列函数【上一个】
表函数:
PREVIOUSDAY【上一天】
PREVIOUSMONTH【上一月】
PREVIOUSDAY【上一季】
PREVIOUSDAY【上一年】
27.5 OPENINGBALANCE系列【期初库存】
值函数:
OPENINGBALANCEMONTH函数
OPENINGBALANCEQUARTER函数
OPENINGBALANCEYEAR函数
用途:计算月/季度/年的期初库存
注意,所谓月初库存就是上月底最后一天的库存。
语法:
OPENINGBALANCE函数(<表达式>, <日期>, <[筛选器]>)

案例:
原始表:

【新建度量值】
月初库存 = OPENINGBALANCEMONTH(SUM('期初'[库存]), '期初'[日期])
矩阵表行上放'期初'[日期],值上放'期初'[月初库存]


和原始表一致:
![]()
![]()
二十八. 筛选器函数
是“筛选”函数,其本身不属于表函数,也不属于值函数,仅作为CALCULATE函数的调节器使用。
我们之前接触的函数,要么是返回表,要么是返回值。
28.1 REMOVEFILTERS【不推荐】
REMOVEFILTERS:移除筛选
-- 和ALL函数功能一样,但是ALL函数可以用来返回一张表,也可以放到筛选器里;而REMOVEFILTER只能放到CALCULATE的筛选器里,它是“筛选”函数。
REMOVEFILTERS函数与ALL函数特性相同(【注意ALL函数特性】):
(1)当ALL参数为表时,忽略所有的筛选条件,无论是该图表内还是外部切片器
(2)当ALL参数为列时,忽略该列筛选,其他图表字段或外部筛选对其产生作用
(3)ALL函数在引用列的时候,必须与矩阵的行和列在同一张表
案例:
原始表: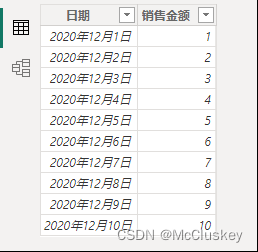
【新建度量值】
总销售 = SUM('REMOVEFILTERS'[销售金额])
ALL = CALCULATE('REMOVEFILTERS'[总销售], ALL('REMOVEFILTERS'))
REMOVEFILTERS = CALCULATE('REMOVEFILTERS'[总销售], REMOVEFILTERS('REMOVEFILTERS'))
矩阵表行上放'REMOVEFILTERS'[日期],值上放'REMOVEFILTERS'[总销量]、'REMOVEFILTERS'[ALL]、'REOVEFILTERS'[REMOVEFILTERS]
度量值 = CALCULATE('REMOVEFILTERS'[总销售], REMOVEFILTERS('REMOVEFILTERS'[日期]))
推荐直接使用ALL函数
28.2 KEEPFILTERS【追加筛选】
案例:
原始表:
【新建度量值】
总金额 = SUM('KEEPFILTERS'[销售金额])
A商品销售 = CALCULATE('KEEPFILTERS'[总金额], 'KEEPFILTERS'[商品] = "A")
矩阵表行上放'KEEPFILTERS'[日期],值上放'KEEPFILTERS'[总金额]、'KEEPFILTERS'[A商品销售]
矩阵表行上换成'KEEPFILTERS'[产品]
-- 'KEEPFILTERS'[A商品销售]显示异常,B和C行不应该显示值;原因是表达式并没有告诉图表可以用商品进行筛选(没懂)
解决方法:
(1)【修改度量值】
A商品销售 = CALCULATE('KEEPFILTERS'[总金额], 'KEEPFILTERS'[商品] = "A", VALUES('KEEPFILTERS'[商品]))
-- 实现用商品进行筛选

(2)【新建度量值】
A商品销售KEEP = CALCULATE('KEEPFILTERS'[总金额], KEEPFILTERS('KEEPFILTERS'[商品] = "A"))
解析:
总结:
KEEPFILTERS是表达式内部筛选条件与外部筛选(比如图表中的字段筛选)取交集,在这里就是[商品] = "A"和矩阵表行上放[商品](度量值自动根据行筛选)两个筛选取交集;
CALCULATE自带的筛选器是表达式内部筛选条件取交集,在这里就是[商品] = "A"和VALUES([商品])两个筛选条件取交集,不涉及外部
28.3 CROSSFILTERS【交叉筛选】
语法:
CROSSFILTER(多端固定列名, 一端固定列名, 方向)
-- 必须是固定列名,不能是表达式生成的
方向:
Oneway - 单向筛选(一端只能筛选多端,多端只能向一端索取数据)
Both - 双向筛选(两张表之间既可以筛选,也可以索取)
None - 无交叉筛选
功能一:改变筛选方向
-- 一端可以筛选多端,多端可以向一端索取数据
现在要实现多端筛选一端(通过销售表筛选出商品表中的商品数量):
【新建度量值】
商品数量 = COUNTROWS(RELATEDTABLE('商品表'))
矩阵表行上放'销售表'[商品编码],值上放'商品表'[商品数量]
-- 显示错误,商品表中每个商品应该只有1个
改变方向 = CALCULATE('商品表'[商品数量], CROSSFILTER('销售表'[商品编码], '商品表'[商品编码], Both))
-- CROSSFILTER函数的一参和二参是用来告诉表达式两张表是通过什么字段连接的
-- Both实现双向筛选,从而使销售表可以筛选商品表
矩阵值上加'商品表'[改变方向]
-- 此例没有实际意义,只是演示CROSSFILTER可以改变筛选方向
功能二:使用模型关系筛选时,数据量过大会导致模型运载变慢,此时可以使用CROSSFILTER函数进行优化
【新建度量值】
销售表数量 = COUNTROWS('销售表')
矩阵表行上放'销售表'[商品编码],值上放'商品表'[销售表数量]
【新建度量值】
改变连接方向后 = CALCULATE('商品表'[销售表数量], CROSSFILTER('销售表'[商品编码], '商品表'[商品编码], OneWay))
矩阵表值上加'销售表'[改变连接方向后]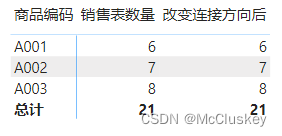
-- 结果和直接计算是一致的,但是数据量大时,速度比直接计算快很多
注意事项:
1、如果模型关系是一对一的情况,使用ONEWAY和BOTH没区别
2、如果多端列和一端列位置反了,函数本身会自我修正
3、此函数只能在接受筛选器作为参数的函数中使用
目前涉及的有CALCULATE、CALCULATETABLE、TOTALYTD、TOTALQTD、TOTALMTD,其他没有讲
4、CROSSFILTER函数会覆盖任何现有筛选关系
5、如果两个参数没有任何连接关系,那么返回结果会报错
6、如果使用多个CROSSFILTER,最内层的会覆盖外面的
28.4 USERELATIONSHIP
用途:
1、用来激活指定的关系
2、适用于做关联分析

案例一:
处理订单数量与收货数量
原始表:

【新建表】动态日期表
日期表 = ADDCOLUMNS(
CALENDAR(FIRSTDATE('某宝'[订单日期]), LASTDATE('某宝'[收货日期])),
"年", YEAR([Date]),
"季度", QUARTER([Date]),
"月", MONTH([Date]),
"周", WEEKNUM([Date]),
"年季度", YEAR([Date]) & "Q" & QUARTER([Date]),
"年月", YEAR([Date]) * 100 + MONTH([Date]),
"年周", YEAR([Date]) * 100 + WEEKNUM([Date]),
"星期几", WEEKDAY([Date])
)
【模型视图创建连接】
'日期表'[Date]分别连'某宝'[订单日期]、'某宝'[收货日期]

-- [订单日期]为主,是实线;
-- [收货日期]为辅,是虚线,为虚拟关系(不可用的关系)
【新建度量值】
下单数量 = SUM('某宝'[销售数量])
送达数量 = CALCULATE('某宝'[下单数量], USERELATIONSHIP('某宝'[收货日期], '日期表'[Date]))
-- 使用USERELATIONSHIP函数让'某宝'[收货日期]和'日期表'[Date]建立真的连接关系,这样就可以作为筛选条件,筛选出已经送达的日期
矩阵表行上放'日期表'[月],值上放'某宝'[下单数量]、'某宝'[送达数量]

-- 14个已送达,11个未送达
筛选器[月]显示条件改为“不为空”-> 应用筛选器,可隐藏未送达的


案例二:
-- 目的:创建两个维度(e.g.2个[名称])的切片器,使两者都可以对事实表('圣斗士')进行筛选且互不影响;图表左侧显示切片器1的结果,右侧显示切片器2的结果
-- 目标效果:

原始表:

【新建表】
-- 为了在切片器中使用
名称1 = VALUES('圣斗士'[名称])
名称2 = VALUES('圣斗士'[名称])

【模型视图创建连接】
-- 如果用[名称1]'名称'和'名称2'[名称]都分别直接去连接'圣斗士'[名称],那么2个切片器的筛选结果会互相影响

将'名称2'和'圣斗士'之间的连线改为虚线(使关系不可用):右击连线 -> 属性 -> 取消勾选“使此关系可用” -> 确定


【新建度量值】
总年龄A = SUM('圣斗士'[年龄])
总年龄B = CALCULATE('圣斗士'[总年龄A], ALL('名称1'[名称]), USERELATIONSHIP('圣斗士'[名称], '名称2'[名称]))
-- ALL('名称1'[名称]):在使用'名称2'做筛选时,不希望'名称1'的筛选对计算产生影响
-- SUM仅是示例使用,在此例[年龄]字段上中不具备意义,在实际使用中多会使用,比如计算销售额累计等
切片器1字段上放'名称1'[名称];矩阵表行上放'圣斗士'[名称],值上放'圣斗士'[总年龄A]、'圣斗士'[总年龄B];切片器2字段上放'名称2'[名称]

-- 虽然能实现独立筛选,但不是目标效果
【新建表】这里手工建了
主页- > 输入数据 -> 输入行列信息 -> 加载


【新建度量值】
左 =
VAR A = SELECTEDVALUE('表'[序号])
VAR B =
SWITCH(
TRUE(),
A = 1, SELECTEDVALUE('名称1'[名称]),
A = 2, '圣斗士'[总年龄A]
)
RETURN
B
右 =
VAR A = SELECTEDVALUE('表'[序号])
VAR B =
SWITCH(
TRUE(),
A = 1, SELECTEDVALUE('名称2'[名称]),
A = 2, '圣斗士'[总年龄B]
)
RETURN
B
-- 通用模板,以后遇到文本显示用SELECTEDVALUE,遇到数值计算用度量值或SUM等,添加其他字段显示就换行继续A = 3…
将报表视图中的矩阵表换成表,可以调整字段位置;表的列上先后依次放'圣斗士'[左]、'表'[项目]、'圣斗士'[右];最终实现效果:

二十九. 中文排序
案例1
原表:

报表视图矩阵表行上放[季节],值上放[销量]

-- 季节不是按照春夏秋冬排序的,而是按照拼音首字母
右键表 -> 编辑查询 -> 添加列 -> 索引列 -> 从1 -> 关闭并应用
![计算机生成了可选文字: , 〕 2 ] . 以 量](https://img-home.csdnimg.cn/images/20230724024159.png?origin_url=file%3A%2F%2F%2FC%3A%2FUsers%2Fjhon%2FAppData%2FLocal%2FPackages%2Fmicrosoft.office.onenote_8wekyb3d8bbwe%2FAC%2FTemp%2F%257B21779EAF-2E41-495C-A187-28E162F7356F%257D.tmp&pos_id=24pMtLvi)
表格视图选中季节列 -> 列工具 -> 按列排序 -> 索引

回到报表视图

-- 已按照春夏秋冬排序
案例2
原表:
-- 不是按照目标顺序排好序的

报表视图矩阵表行上放'表2'[月份],值上放'表2'[销量]

主页 -> 输入数据 -> 根据排序要求创建月份表

查看模型视图
-- 已通过月份自动连线

表格视图月份表选中月份列 -> 列工具 -> 按列排序 -> 索引

-- 因为两张表的月份存在连接关系,月份表按照索引排序,在表2也会生效
报表视图矩阵表行上换成'月份表'[月份]















 7084
7084











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









