







说实话上学期学完数据结构与算法这门课,接触到了挺多的算法,有难的有简单的,但是当时只是为了交作业硬生生把所有的算法全部都看完背下来,而没有去理解算法的深意以及它的用武之地,正巧这段时间都在看scrapy+redis,过程中了解到了hash的很多在redis(更早是 在Memcached:一个高性能的分布式内存对象缓存系统)中的应用,然后就是各种牛逼,各种应用,我才返回去看到底hash是个什么东西…..
按我现在的理解就是:
哈希值是一段由其他某个值(标识) 映射 成为的一段占用更小的内存更少的数据空间的值。
而哈希表是 根据 指定的某个hash函数H(key),和处理冲突的方法,将一组关键字映射到另一个有限的区间上,映射得到的值(根据算法和解决冲突方法得到) 就可以作为记录在哈希表中的存放的具体位置。
同样的长度,把标识的数据项给压缩了,并且加上冲突处理方法,那就是另 外一串查找起来相当简单同时不会出错的线性表,而且我们是省略了一大堆无用的查找,首先直接找到有可能正确的数据项来比较,那就说明正确的那个项一定就在我们起始找的那个元素的附近,或者就是它,这不就是我们想要的吗?
哈希这种映射的方法将查找数的时间复杂度变成了一个算法常数,无论你查找什么数,先执行指定的hash算法,之后按照解决冲突的方法去查找,这个效率比起线性表和队列这些同为线性数据结构的家伙,那可是快了不只一点点。
输出结果为:
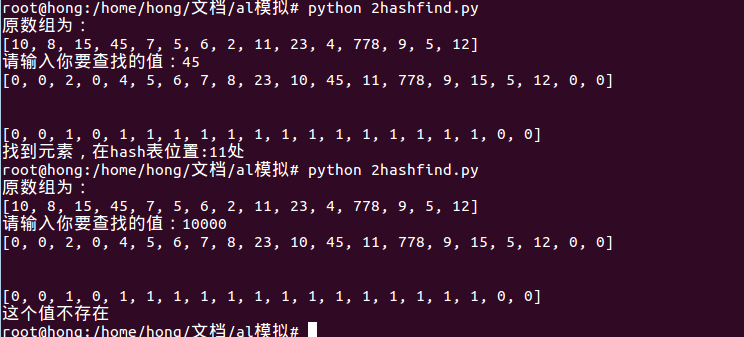
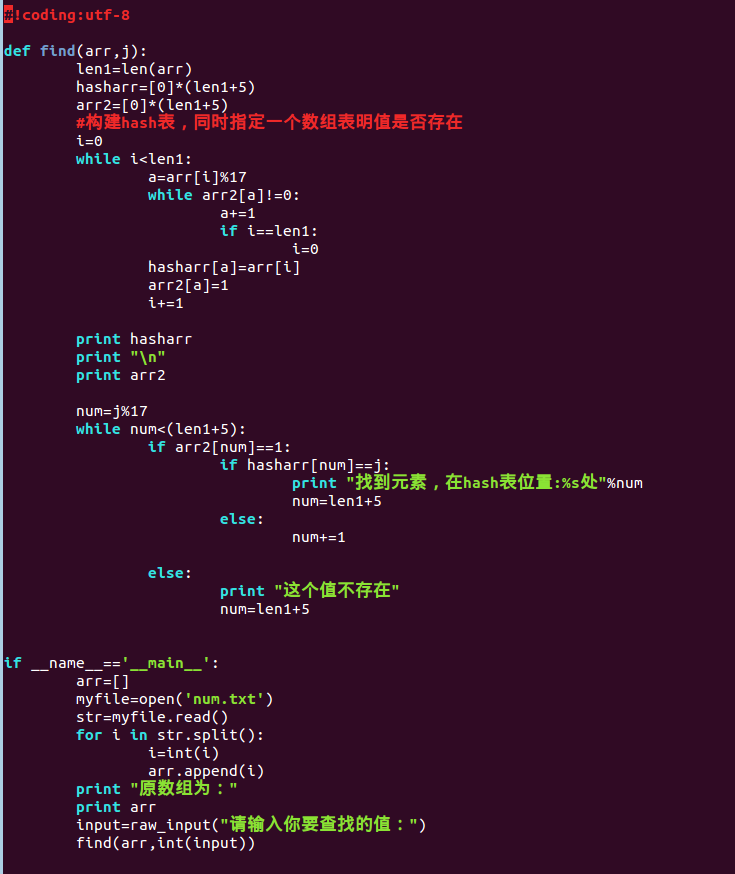
这个哈希算法比较简单的把其设为了一个求余的算法,解决冲突的办法是每次遇上hash值一样的映像,就把映像++,当然真正应用的hash算法不会这么简单。
除了上面提到的应用,hash还广泛应用于加密和数据校验中,hash的128位加密具有不可逆性,像MD5,咱们通常用的WAP/WAP2协议也是应用到了hash技术


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









