









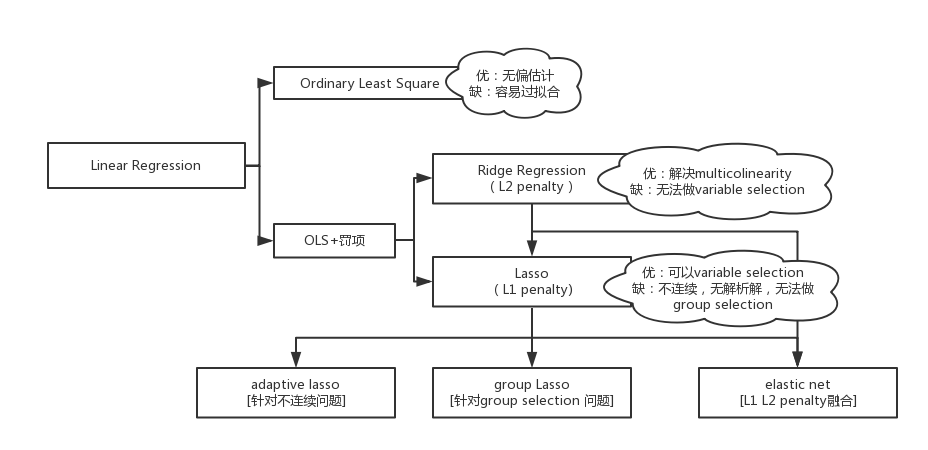
先引出机器学习万变不离其宗的公式:
损失函数+惩罚项
当损失函数为Square Loss时,所对应的模型就是Linear Regression。
预测值
Ordinary Least Square
目标: min||Xw−y||22
优点:无偏估计
缺点:存在ill-condition病态问题,容易发生过拟合
求解方式:
(1)迭代法(这里的 θ 对应上面的 w )
where
In batch gradient descent, each iteration performs the update
其中 α 所乘的项为 ▽J(θ) , −▽J(θ) 称为下降方向
这里采用的方法是最速下降法, α 称为学习率,太小则学习过慢,太大则容易过学习。 [1]
- α 的选取:
尝试法,取0.003,0.01,0.03,0.1,0.3,观察 J(θ) 的曲线下降情况
利用精确搜索(Fibonacci法、黄金分割法和二次插值法)或者不精确法(Wolfe算法)求解 [2]
- 注意点
在用OLS中,遇到变量之间的尺度不同的时候,要用Feature Normalization方法,具体做法如下:
a. Subtract the mean value of each feature from the dataset.
b. After subtracting the mean, additionally scale (divide) the feature values by their respective “standard deviations.” [1]
(2)Normal Equations
对于线性回归而言,是有解析解的,即
w=(XTX)−1XTy
随着样本的数量和变量的种类的增加,计算量也随之增大。 [1]
Ridge Regression
目标: min||Xw−y||22+λ||w||22
优点:解决了multicolinearity
缺点:无法做validable selection,有偏估计
OLS虽然是无偏估计,但是有一个很大的问题,就是会依赖于训练数据而发生过拟合。(也可以从ill-condition角度上理解 [3] )
当 w=(XTX)−1XTy 中 XTX 不是满秩的时候, XTX 不可逆,会存在多个解,如果从许多个解中选取一个的话,可能不是正确的解,容易发生过拟合。
XTX 不是满秩的情况分为两种(1)数据点少于变量的个数(行不满秩) (2)变量间存在高度的相关性(列不满秩)
当加上了L2规则项后, w=(XTX)−1XTy 变成了 w=(XTX+λI)−1XTy ,就可以直接求逆矩阵了。
- λ 的选取
(1)根据岭迹图选取,在各个变量随 λ 达到平稳时的 λ
(2)用GCV(Generalized Cross-Validation)来设置
Lasso
目标: min||Xw−y||22+λ||w||1
优点:可以做validable selection
缺点:不连续,无解析解,不能做group lasso
先来看看正则化项的轮廓。
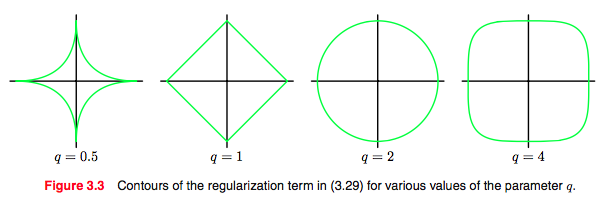
目标函数
min||Xw−y||22+λ||w||1
与
min||Xw−y||22
s.t.||w||1≤t
可以通过Lagrange multipliers相联起来 [4] (Ridge Regression 同)。
可以得到下列图。
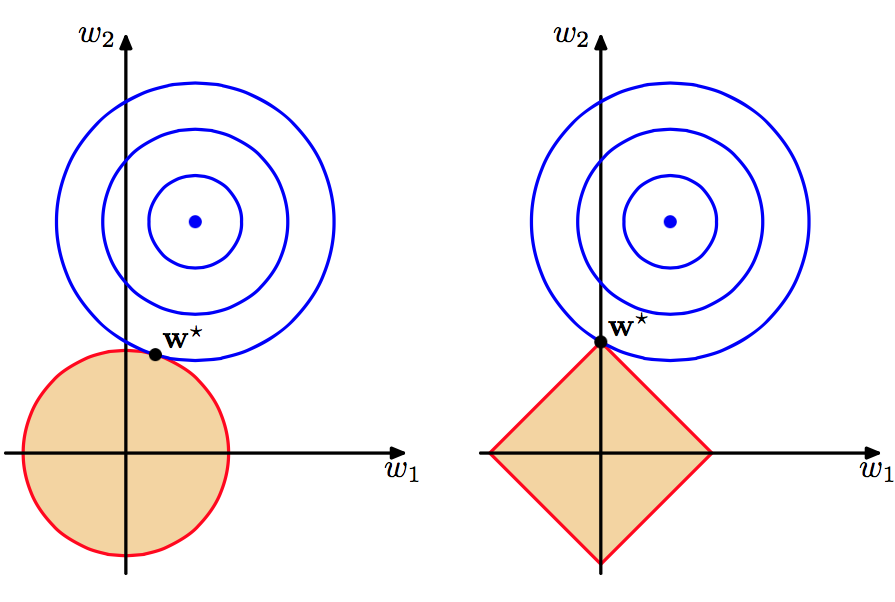
图上蓝色表示变量为2个时的损失函数等高线,越接近中心则损失值越小,黄色表示变量的约束范围。左图是L2范数约束,右图是L1范数约束。圆周/菱形边与等高线的交点为在约束下损失最小的 w1 和 w2 值,可以看到右图的 w1=0 ,即将变量降到1个变量。这是因为L2范数倾向于w的分量取值尽量均衡,即非零分量个数尽量稠密,而L0范数和L1范数则倾向于w的分量尽量稀疏,即非零分量个数尽可能少 [5] 。
Lasso是一种嵌入式特征选择方法
- L1的求解:PGD (Proximal Gradient Descent)
[1] Andrew Ng, Machine Learning course https://www.coursera.org/learn/machine-learning/
[2] 谢可新《最优化方法》
[3] 机器学习中的范数规则化之(一)L0、L1与L2范数 http://blog.csdn.net/zouxy09/article/details/24971995
[4] M.Jordan 《Pattern Recognition and Machine Learning》
[5] 周志华 《机器学习》















 4686
4686

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









