






虚拟磁链,直接功率控制simulink仿真,vf-dpc,整流器仿真,逆变器仿真虚拟磁链仿真,MATLAB仿真,参考文献,

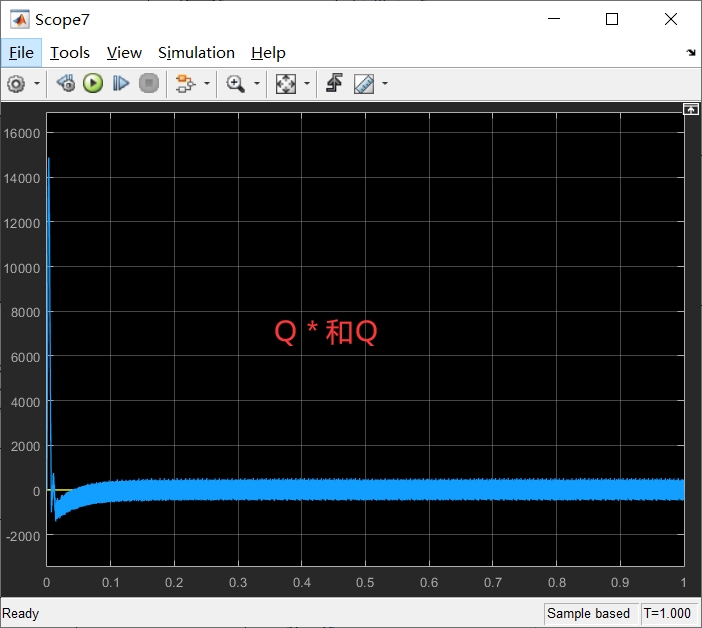
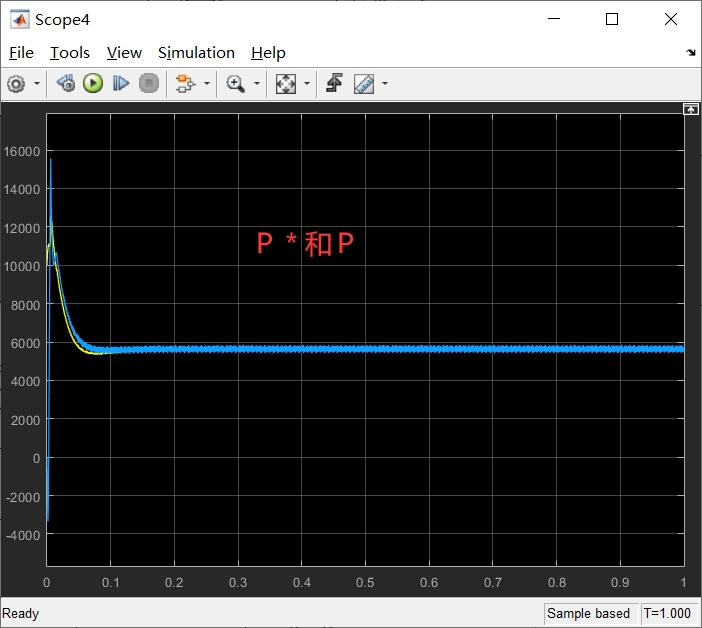
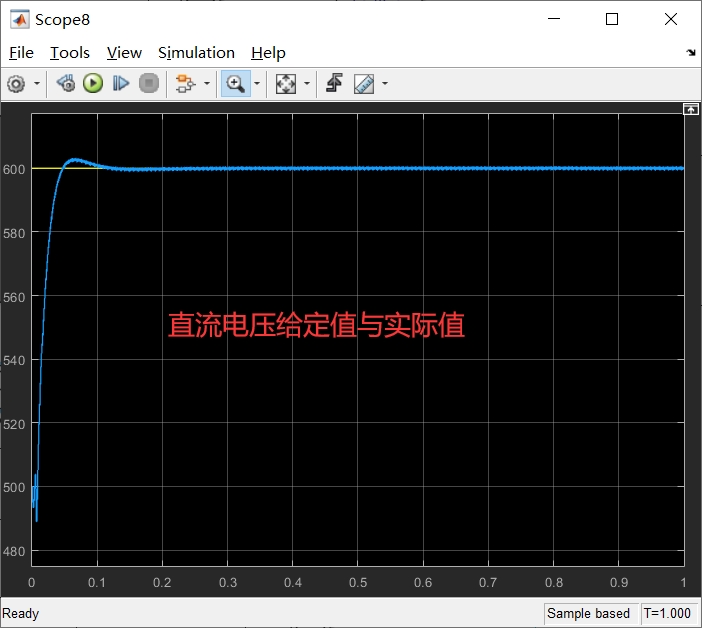
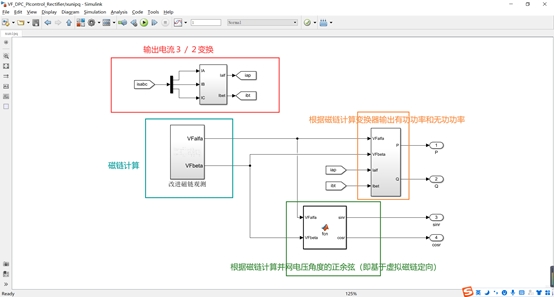
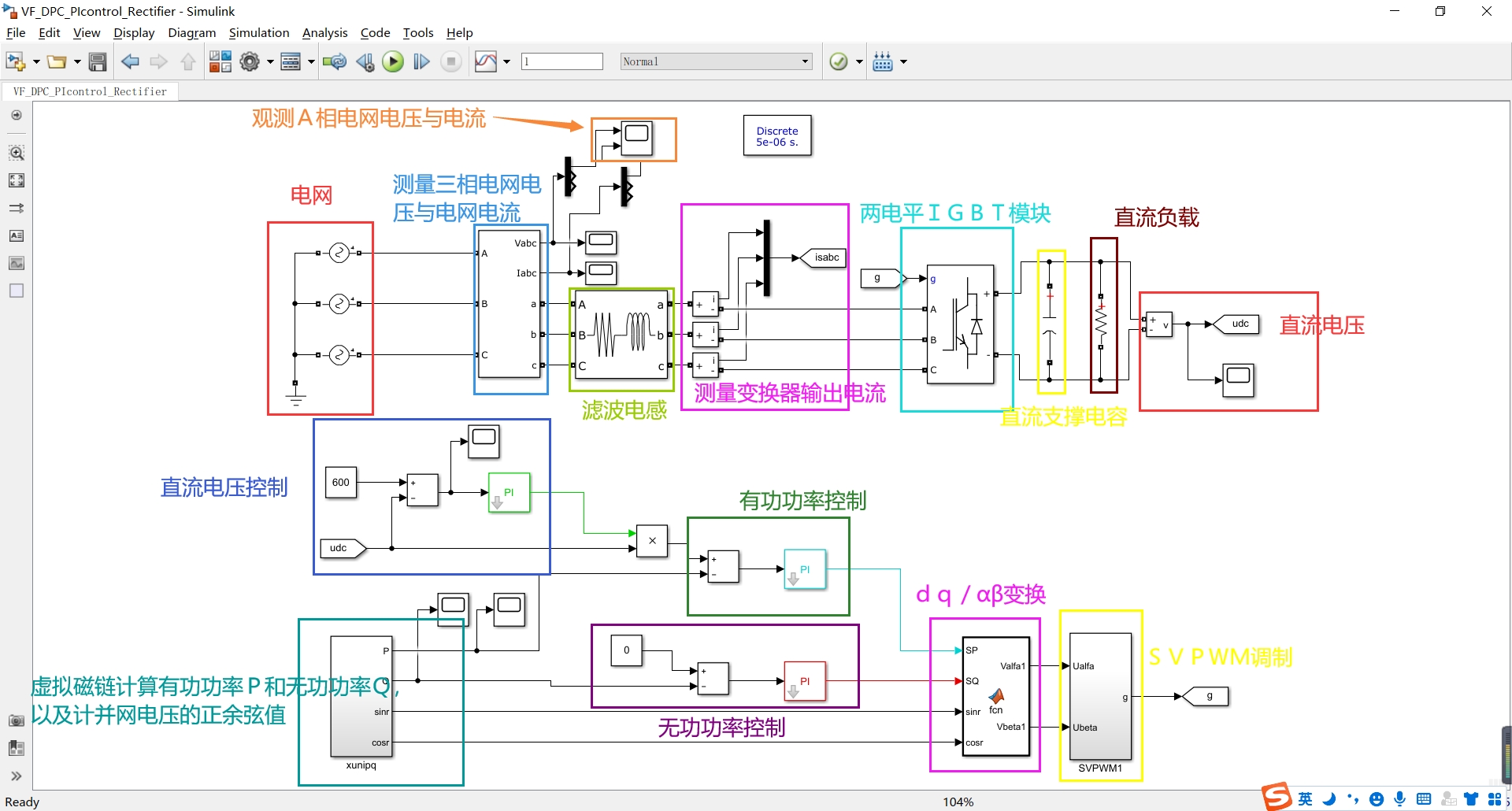
虚拟磁链是一种在电力电子领域中广泛应用的技术,它可以提供高效的功率转换和控制。本文将围绕虚拟磁链技术展开讨论,并结合直接功率控制(Direct Power Control, DPC)在Simulink仿真环境中的应用,深入探讨虚拟磁链技术在整流器和逆变器仿真中的应用。
首先,我们将介绍虚拟磁链技术的原理和基本概念。虚拟磁链是通过对电压和电流进行变换和控制,实现对功率的精确调节和控制。在电力电子系统中,使用虚拟磁链技术可以提高系统的效率和稳定性。我们将详细介绍虚拟磁链技术的原理,包括磁链功率控制和电流控制等关键内容。
接下来,我们将介绍Simulink仿真环境下的直接功率控制技术。直接功率控制是一种基于虚拟磁链技术的控制策略,它可以通过调节功率因数和电流大小来实现对电力系统的控制。我们将详细介绍直接功率控制技术的原理和步骤,以及在Simulink仿真环境中的实现方法。通过仿真实验,我们可以验证直接功率控制技术的性能和可行性。
同时,本文还将探讨虚拟磁链技术在整流器和逆变器仿真中的应用。整流器和逆变器是电力电子系统中常见的转换设备,它们在能量转换过程中起到关键作用。虚拟磁链技术可以应用于整流器和逆变器的控制中,以提高系统的效率和稳定性。我们将介绍虚拟磁链技术在整流器和逆变器仿真中的具体应用,包括控制策略和参数调节等关键内容。
最后,我们将使用MATLAB仿真工具对虚拟磁链技术进行仿真实验。MATLAB是一种常用的科学计算和仿真工具,它提供了丰富的工具箱和函数库,可以方便地进行电力电子系统的仿真和分析。我们将使用MATLAB进行虚拟磁链技术的仿真实验,验证该技术的性能和可行性。同时,我们还将讨论仿真实验中的参数设置和优化方法,以及结果分析和结论总结等内容。
综上所述,本文围绕虚拟磁链技术展开讨论,并结合Simulink仿真环境中的直接功率控制技术,深入探讨虚拟磁链技术在整流器和逆变器仿真中的应用。通过详细介绍虚拟磁链技术的原理和应用,以及仿真实验的设计和分析,本文旨在为读者提供一个全面了解虚拟磁链技术的机会,并为他们在实际应用中提供一定的参考和指导。
(字数:689)
相关的代码,程序地址如下:http://nodep.cn/673931343094.html
















 521
521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









