









最近在研究生活圈,或者说是等时圈,正好结合lbs提供的路线规划接口做一些工作
1、确定坐标系
因为要使用高德的lbs,所以所有的球坐标系都使用GCJ02坐标,同时在arcgis中设置好wmts服务,方便加载底图。
2、建立底图
arcgis中创建两个点图层,origin_pt_gcj02.shp 和 target_pt_gcj02.shp(源点和目标点),其中源点坐标是天津规划院:P。
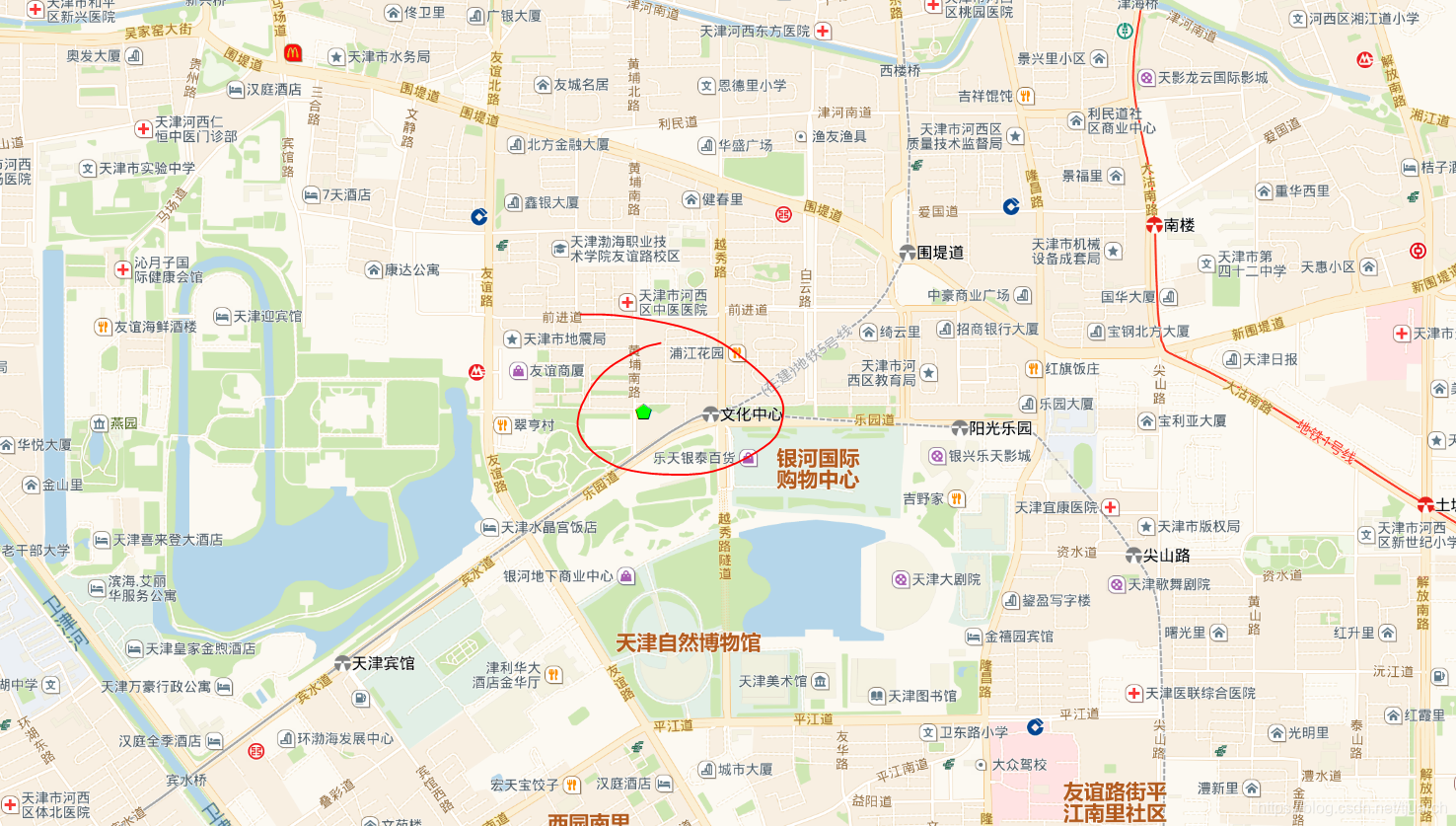 目标点坐标的思路是这样:以源点为圆心,做一个1000米的缓冲区,然后在缓冲区中以20x20米建立格网,同时建立格网中心点。
目标点坐标的思路是这样:以源点为圆心,做一个1000米的缓冲区,然后在缓冲区中以20x20米建立格网,同时建立格网中心点。
选取缓冲区范围内的格网和中心点,分别为net_gcj02.shp, target_pt_gcj02.shp。
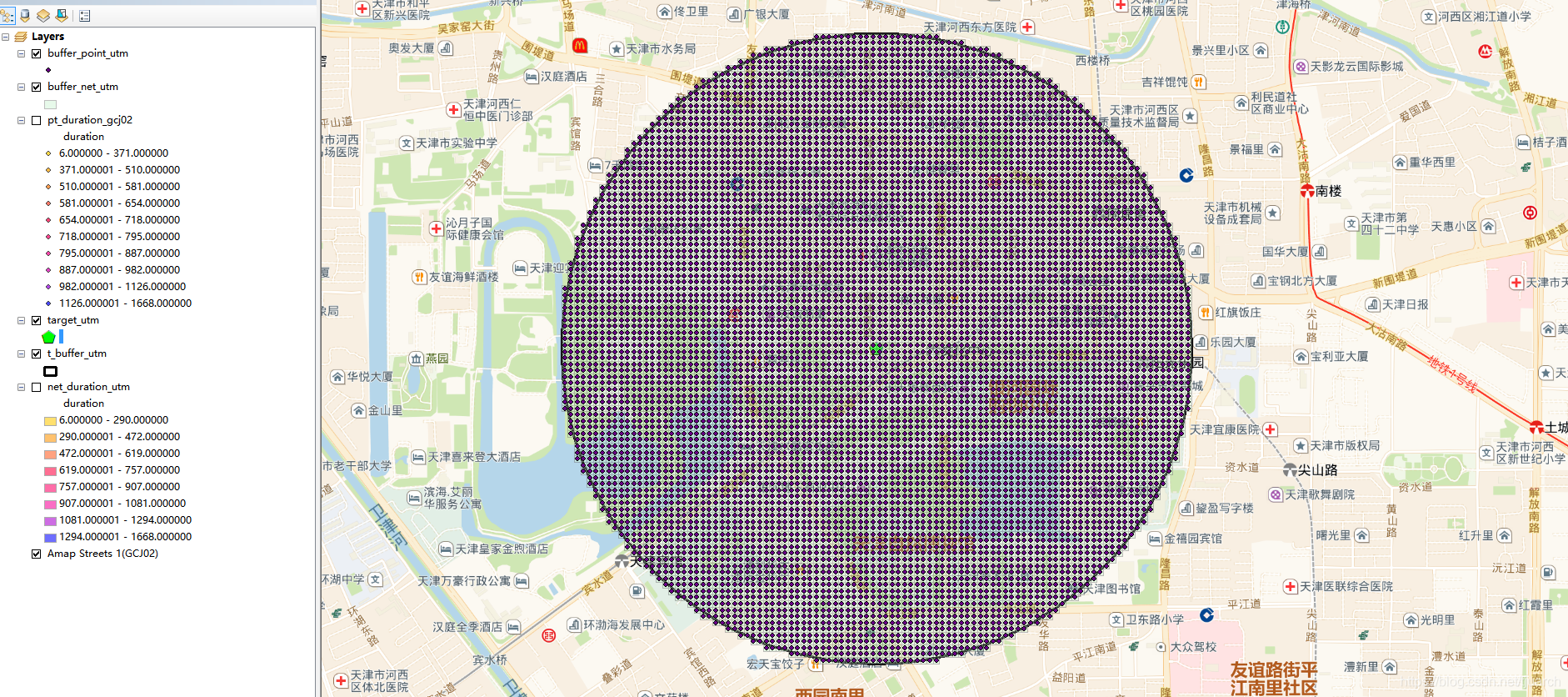 把两个点要素文件转成投影坐标,天津记得选51N带,分别为origin_pt_utm.shp 和 target_pt_utm.shp
把两个点要素文件转成投影坐标,天津记得选51N带,分别为origin_pt_utm.shp 和 target_pt_utm.shp
好,基本的地图已经完成了。
3、使用高德lbs查询
这一块的思路就是,通过lbs,返回每个目标点和源点之间的步行时间(考虑道路实际情况,因为是步行,不考虑路况),然后赋值给点shp文件,用来做进一步可视化和分析处理。
(1)dbf转csv
由于shp文件的数据用dbf文件格式存储,为了方便在pandas中使用,我把他们转成csv格式的文件。
这一步上卡了很久,网上建议使用geopandas,但是我用的是win10系统,pip安geopandas所需的包文件好多都没有win64版本的,包括shapely、fiona啥的。在大牛网站https://www.lfd.uci.edu/~gohlke/pythonlibs/上找到的for win64的wheel文件,各个包单独安装倒是能安上,但是导入包的时候就是各种出错。
由于正规的dbf文件读写涉及sql操作,这是俺的短板,所以先绕着走…回头再改进。
所以我建议老老实实使用dbfread,虽然会出现编码问题,但是提前在读取的时候解决掉,就没问题了,无非是gbk或者utf-8。
# -*- coding: utf-8 -*-
import pandas as pd
from dbfread import DBF
def dbf2csv(filepath):
path = '/'.join(filepath.split('/')[:-1])
name = filepath.split('/')[-1]
table = DBF(filepath)
df = pd.DataFrame()
for record in table:
df = df.append(record, ignore_index=True) # 这里record是一个ordered dict所以能直接append
filename = name.split('.')[0] + '.csv'
newpath = path + '/' + filename
df.to_csv(newpath, index=False)

上面的函数原位把dbf另存成csv文件。
(2)连接lbs,获得目标时间
这里整个数据获取的核心,先贴代码。
# -*- coding: utf-8 -*-
import pandas as pd
import requests
import time
def getduration(df):
columns=['lng_x', 'lat_y', 'duration']
newdf = pd.DataFrame(columns=columns)
counts = len(df)
for i in range(counts):
lng_x = df.iloc[i].lng_x
lat_y = df.iloc[i].lat_y
print(f"{i} / {counts}")
param = {
"key": "your key", # 换成你自己的key
"origin": f"{origin[0]},{origin[1]}",
"destination": f"{lng_x},{lat_y}"
}
try:
r = requests.get(url, param)
res = r.json()
duration = int(res['route']['paths'][0]['duration']) # 只要时长这一项
data = {columns[0]: lng_x,
columns[1]: lat_y,
columns[2]: duration,
}
newdf = newdf.append(data, ignore_index=True)
except Exception:
continue
return newdf
def writetocsv(df):
outcsv = f"../data/outfile{time.time}.csv"
df.to_csv(outcsv, index=False)
def main(df):
newdf = getduration(df)
writetocsv(newdf)
if __name__ == "__main__":
url = r"https://restapi.amap.com/v3/direction/walking?"
bufferpath = r"../data/buffer_point_gcj02.csv"
originpath = r"../data/target_gcj02.csv"
t = pd.read_csv(originpath)
origin = [round(t.lng_x[0], 6), round(t.lat_y[0], 6)] # origin point
df = pd.read_csv(bufferpath)
main(df)
这里偷了个懒,直接把dbf转成csv就直接用了,可以写在脚本中的。
getduration()函数干的就是从网站获取信息,记得加try,以防网络突然挂掉,留个后手。然后通过writetocsv()把数据框架写入csv文件保存。
4、arcgis中加载带有时间信息的点
常规操作了,把生成的csv文件加载进arcgis,然后显示xy,再通过spatial join把信息附加在格网上,记得对应坐标系。
调整显示效果,获得一张天津规划院周边1000米范围的步行等时圈图。

5、总结
缺点:
十分耗费配额,这一个圈,就用了8000多个配额,每天才三万,用不起,用不起。
优点:
快速建立等时圈,不用再费力气构造拓扑网络
可以应用在居住区配套设施生活圈评估、地铁站点周边步行条件评估等其他场景
矢量化数据,可以为后续的可视化或者进一步分析提供比较好的基础
整改:
改进算法,减少目标点,降低lbs耗费
后续进行更大范围的车行等时圈提前研究
完毕。

















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









