







 本文详细探讨了PageRank算法在Hadoop和Spark中的实现,包括实验准备、Hadoop与Spark的具体实现步骤、运行过程及测试对比。通过对网页链接关系的有向图分析,PageRank算法用于衡量网页的重要性。在Hadoop中,通过map-reduce迭代计算,而在Spark中利用RDD的并行计算优势加速迭代。测试以10次迭代为收敛标准,最后比较了两种框架的运行结果。
本文详细探讨了PageRank算法在Hadoop和Spark中的实现,包括实验准备、Hadoop与Spark的具体实现步骤、运行过程及测试对比。通过对网页链接关系的有向图分析,PageRank算法用于衡量网页的重要性。在Hadoop中,通过map-reduce迭代计算,而在Spark中利用RDD的并行计算优势加速迭代。测试以10次迭代为收敛标准,最后比较了两种框架的运行结果。
PageRank是用于解决网页重要性排序的关键技术之一,其基于网页之间链接关系构建一个有向图结构,实现各个网页级别的划分。一个网页的PageRank值(后面简称PR值),取决于其他网页对该网页的贡献和,以公式形式表示为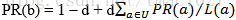
1. 实验准备
由于Hadoop与Spark对于PageRank算法的实现过程不同,这里分别对Hadoop与Spark算法输入文件进行说明。
对于Hadoop输入文件,每行的数据信息包含网页ID、网页初始PR值1.0以及该网页链接的其他网页ID,以制表符隔开,如
A 1 B,C
B 1 C
C 1 A,D
D 1 B,E
E 1 A对于Spark输入文件,以网页ID以及该网页链接的每一个网页ID,作为单独一行保存,如
A B
A C
B C
C A
C D
D B
D E
E A2. Hadoop实现
为了完成后续的迭代计算,map过程需要将链接关系图和对其他网页的贡献值分别传递给reduce端。
reduce过程根据key将最终计算的PR值与链接关系图合并输出,用于下次迭代的map端。
测试以10次为收敛标准迭代进行,具体代码实现如下:
package org.hadoop.test;
import java.io.IOException;
import java.util.StringTokenizer;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
public class PageRank {
private static final double d =  最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 2022
2022

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









