







框架
Apache Hadoop:分布式处理架构,结合了 MapReduce(并行处理)、YARN(作业调度)和HDFS(分布式文件系统);
一.下载Hadoop相关文件1.在Hadoop官网上下载Windows版本的Hadoop文件,这里以Hadoop-2.7.3为例
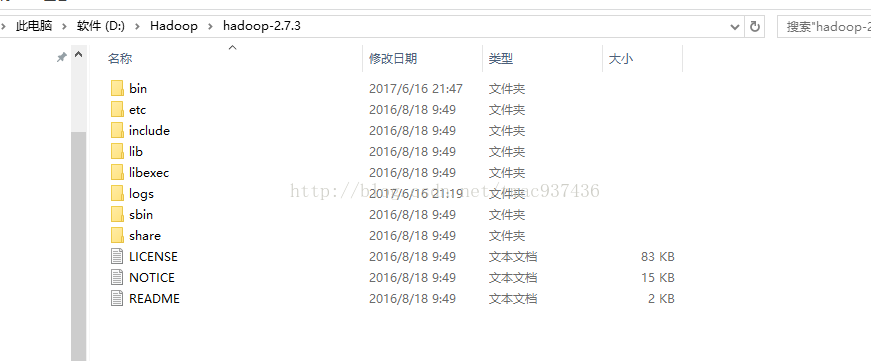
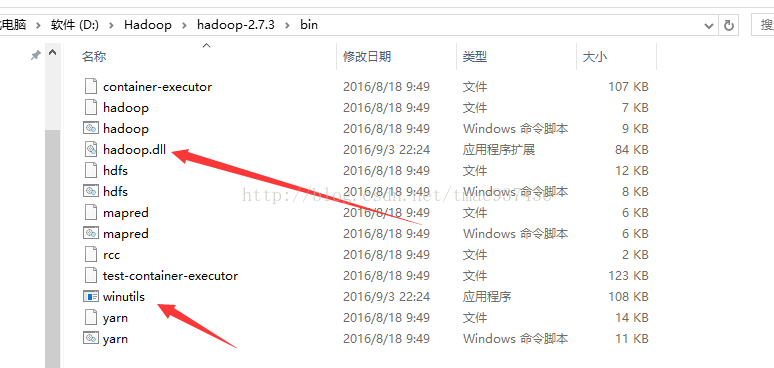
2.然后下载hadoop.dll和winutils.exe并将其放在hadoop文件系统的bin目录下,同时在C:\Windows\System32\文件夹下添加hadoop.dll
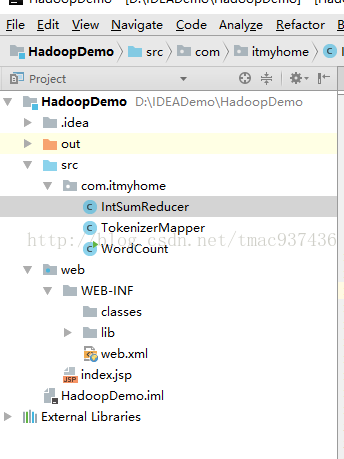
二.在IDEA中进行MapReduce编程模型测试
1.新建一个JavaProject
2.下载相应jar并添加到lib目录下
附:如果缺少jar包,hadoop程序运行时会报异常
3.将要进行测试的系统日志存放在D:\tmp\input.txt文件中
2016-04-18 16:00:00 {"areacode":"浙江省丽水市","countAll":0,"countCorrect":0,"datatime":"4134362","logid":"201604181600001184409476","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966390499\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"100\",\"imei\":\"12345678900987654321\",\"subjectNum\":\"13989589062\",\"imsi\":\"12345678900987654321\",\"queryNum\":\"13989589062\"}","requestip":"36.16.128.234","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"宁夏银川市","countAll":0,"countCorrect":0,"datatime":"4715990","logid":"201604181600001858043208","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966400120\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"1210\",\"imei\":\"A0000044ABFD25\",\"subjectNum\":\"15379681917\",\"imsi\":\"460036951451601\",\"queryNum\":\"\"}","requestip":"115.168.93.87","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果","userAgent":"ZTE-Me/Mobile"}
2016-04-18 16:00:00 {"areacode":"黑龙江省哈尔滨市","countAll":0,"countCorrect":0,"datatime":"5369561","logid":"201604181600001068429609","requestinfo":"{\"interfaceUserName\":\"12345678900987654321\",\"queryNum\":\"\",\"timestamp\":\"1460966400139\",\"sign\":\"4\",\"imsi\":\"460030301212545\",\"imei\":\"35460207765269\",\"subjectNum\":\"55588237\",\"subjectPro\":\"123456\",\"remark\":\"4\",\"channelno\":\"2100\"}","requestip":"42.184.41.180","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"浙江省丽水市","countAll":0,"countCorrect":0,"datatime":"4003096","logid":"201604181600001648238807","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966391025\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"100\",\"imei\":\"12345678900987654321\",\"subjectNum\":\"13989589062\",\"imsi\":\"12345678900987654321\",\"queryNum\":\"13989589062\"}","requestip":"36.16.128.234","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"广西南宁市","countAll":0,"countCorrect":0,"datatime":"4047993","logid":"201604181600001570024205","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966382871\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"1006\",\"imei\":\"A000004853168C\",\"subjectNum\":\"07765232589\",\"imsi\":\"460031210400007\",\"queryNum\":\"13317810717\"}","requestip":"219.159.72.3","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"海南省五指山市","countAll":0,"countCorrect":0,"datatime":"5164117","logid":"201604181600001227842048","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966399159\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"1017\",\"imei\":\"A000005543AFB7\",\"subjectNum\":\"089836329061\",\"imsi\":\"460036380954376\",\"queryNum\":\"13389875751\"}","requestip":"140.240.171.71","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"山西省","countAll":0,"countCorrect":0,"datatime":"14075772","logid":"201604181600001284030648","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966400332\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"1006\",\"imei\":\"A000004FE0218A\",\"subjectNum\":\"03514043633\",\"imsi\":\"460037471517070\",\"queryNum\":\"\"}","requestip":"1.68.5.227","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"四川省","countAll":0,"countCorrect":0,"datatime":"6270982","logid":"201604181600001173504863","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966398896\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"100\",\"imei\":\"12345678900987654321\",\"subjectNum\":\"13666231300\",\"imsi\":\"12345678900987654321\",\"queryNum\":\"13666231300\"}","requestip":"182.144.66.97","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"}
2016-04-18 16:00:00 {"areacode":"浙江省","countAll":0,"countCorrect":0,"datatime":"4198522","logid":"201604181600001390637240","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966399464\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"100\",\"imei\":\"12345678900987654321\",\"subjectNum\":\"05533876327\",\"imsi\":\"12345678900987654321\",\"queryNum\":\"05533876327\"}","requestip":"36.23.9.49","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"000000","responsedata":"操作成功"}
2016-04-18 16:00:00 {"areacode":"江苏省连云港市","countAll":0,"countCorrect":0,"datatime":"4408097","logid":"201604181600001249944032","requestinfo":"{\"sign\":\"4\",\"timestamp\":\"1460966395908\",\"remark\":\"4\",\"subjectPro\":\"123456\",\"interfaceUserName\":\"12345678900987654321\",\"channelno\":\"100\",\"imei\":\"12345678900987654321\",\"subjectNum\":\"18361451463\",\"imsi\":\"12345678900987654321\",\"queryNum\":\"18361451463\"}","requestip":"58.223.4.210","requesttime":"2016-04-18 16:00:00","requesttype":"0","responsecode":"010005","responsedata":"无查询结果"} 4.对输入内容进行Map处理
package com.itmyhome;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* 第一步:input
* 第二步:spilt
* 第三步:map
* 第四步:shuffle
* 第五步:reduce
* 第六步:final result
*/
public class TokenizerMapper extends Mapper<Object, Text, Text, IntWritable> {
private final static IntWritable one = new IntWritable(1);
private Text word = new Text();
private String imei = new String();
private String areacode = new String();
private String responsedata = new String();
private String requesttime = new String();
private String requestip = new String();
// map阶段的key-value对的格式是由输入的格式所决定的,如果是默认的TextInputFormat,则每行作为一个记录进程处理,其中key为此行的开头相对于文件的起始位置,value就是此行的字符文本
// map阶段的输出的key-value对的格式必须同reduce阶段的输入key-value对的格式相对应
public void map(Object key, Text value, Context context
) throws IOException, InterruptedException {
//StringTokenizer itr = new StringTokenizer(value.toString());
int areai = value.toString().indexOf("areacode", 21);
int imeii = value.toString().indexOf("imei", 21);
int redatai = value.toString().indexOf("responsedata", 21);
int retimei = value.toString().indexOf("requesttime", 21);
int reipi = value.toString().indexOf("requestip", 21);
if (areai==-1)
{ areacode=""; }
else
{
areacode=value.toString().substring(areai+11);
int len2=areacode.indexOf("\"");
if(len2 <= 1)
{
areacode="";
}
else
{
areacode=areacode.substring(0,len2);
}
}
if (imeii==-1)
{ imei=""; }
else
{
imei=value.toString().substring(imeii+9);
int len2=imei.indexOf("\\");
if(len2 <= 1)
{
imei="";
}
else
{
imei=imei.substring(0,len2);
}
}
if (redatai==-1)
{ responsedata=""; }
else
{
responsedata=value.toString().substring(redatai+15);
int len2=responsedata.indexOf("\"");
if(len2 <= 1)
{
responsedata="";
}
else
{
responsedata=responsedata.substring(0,len2);
}
}
if (retimei==-1)
{ requesttime=""; }
else
{
requesttime=value.toString().substring(retimei+14);
int len2=requesttime.indexOf("\"");
if(len2 <= 1)
{
requesttime="";
}
else
{
requesttime=requesttime.substring(0,len2);
}
}
if (reipi==-1)
{ requestip=""; }
else
{
requestip=value.toString().substring(reipi+12);
int len2=requestip.indexOf("\"");
if(len2 <= 1)
{
requestip="";
}
else
{
requestip=requestip.substring(0,len2);
}
}
/* while (itr.hasMoreTokens()) {
string tim;
word.set(itr.nextToken());
context.write(word, one);
}*/
if(imei!=""&&areacode!=""&&responsedata!=""&&requesttime!=""&&requestip!="")
{
String wd=new String();
wd=imei+"\t"+areacode+"\t"+responsedata+"\t"+requesttime+"\t"+requestip;
//wd="areacode|"+areacode +"|imei|"+ imei +"|responsedata|"+ responsedata +"|requesttime|"+ requesttime +"|requestip|"+ requestip;
word.set(wd);
context.write(word, one);
}
}
}
package com.itmyhome;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import javax.naming.Context;
import java.io.IOException;
public class IntSumReducer extends Reducer<Text,IntWritable,Text,IntWritable> {
private IntWritable result = new IntWritable();
public void reduce(Text key, Iterable<IntWritable> values,
Context context
) throws IOException, InterruptedException {
int sum = 0;
for (IntWritable val : values) {
sum += val.get();
}
result.set(sum);
context.write(key, result);
}
}
package com.itmyhome;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.File;
public class WordCount {
public static void main(String[] args) throws Exception {
Configuration conf = new Configuration();
// String[] otherArgs = new GenericOptionsParser(conf, args).getRemainingArgs();
deleteDir(new File("D:\\tmp\\output"));
String[] otherArgs=new String[]{"file:///D:\\tmp\\input.txt","file:///D:\\tmp\\output"};
if (otherArgs.length != 2) {
System.err.println("Usage: wordcount <in> <out>");
System.exit(2);
}
//Job job = new Job(conf, "word count");
Job job = Job.getInstance(conf);
job.setJarByClass(WordCount.class);
job.setMapperClass(TokenizerMapper.class);
job.setCombinerClass(IntSumReducer.class);
job.setReducerClass(IntSumReducer.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
FileInputFormat.addInputPath(job, new Path(otherArgs[0]));
FileOutputFormat.setOutputPath(job, new Path(otherArgs[1]));
System.exit(job.waitForCompletion(true) ? 0 : 1);
}
//如果输出目录不为空,将目录及其目录中的文件全部删除
private static boolean deleteDir(File dir) {
if (dir.isDirectory()) {
System.out.println("输出目录不为空");
String[] children = dir.list();//递归删除目录中的子目录下
for (int i=0; i<children.length; i++) {
boolean success = deleteDir(new File(dir, children[i]));
if (!success) {
return false;
}
}
}
System.out.println("输出目录删除完成");
// 目录此时为空,可以删除
return dir.delete();
}
}
7.控制台输入展示
SLF4J: Class path contains multiple SLF4J bindings.
SLF4J: Found binding in [jar:file:/D:/IDEADemo/HadoopDemo/web/WEB-INF/lib/slf4j-log4j12-1.7.5.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: Found binding in [jar:file:/D:/IDEADemo/HadoopDemo/web/WEB-INF/lib/avro-tools-1.7.7.jar!/org/slf4j/impl/StaticLoggerBinder.class]
SLF4J: See http://www.slf4j.org/codes.html#multiple_bindings for an explanation.
SLF4J: Actual binding is of type [org.slf4j.impl.Log4jLoggerFactory]
2017-06-17 19:34:10,047 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - session.id is deprecated. Instead, use dfs.metrics.session-id
2017-06-17 19:34:10,055 INFO [main] jvm.JvmMetrics (JvmMetrics.java:init(76)) - Initializing JVM Metrics with processName=JobTracker, sessionId=
2017-06-17 19:34:11,900 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(149)) - Hadoop command-line option parsing not performed. Implement the Tool interface and execute your application with ToolRunner to remedy this.
2017-06-17 19:34:11,905 WARN [main] mapreduce.JobSubmitter (JobSubmitter.java:copyAndConfigureFiles(258)) - No job jar file set. User classes may not be found. See Job or Job#setJar(String).
2017-06-17 19:34:11,949 INFO [main] input.FileInputFormat (FileInputFormat.java:listStatus(287)) - Total input paths to process : 1
2017-06-17 19:34:12,196 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:submitJobInternal(394)) - number of splits:1
2017-06-17 19:34:12,283 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - user.name is deprecated. Instead, use mapreduce.job.user.name
2017-06-17 19:34:12,285 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.output.value.class is deprecated. Instead, use mapreduce.job.output.value.class
2017-06-17 19:34:12,286 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.combine.class is deprecated. Instead, use mapreduce.job.combine.class
2017-06-17 19:34:12,286 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.map.class is deprecated. Instead, use mapreduce.job.map.class
2017-06-17 19:34:12,287 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapreduce.reduce.class is deprecated. Instead, use mapreduce.job.reduce.class
2017-06-17 19:34:12,287 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.input.dir is deprecated. Instead, use mapreduce.input.fileinputformat.inputdir
2017-06-17 19:34:12,287 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.output.dir is deprecated. Instead, use mapreduce.output.fileoutputformat.outputdir
2017-06-17 19:34:12,288 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.map.tasks is deprecated. Instead, use mapreduce.job.maps
2017-06-17 19:34:12,288 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.output.key.class is deprecated. Instead, use mapreduce.job.output.key.class
2017-06-17 19:34:12,289 INFO [main] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.working.dir is deprecated. Instead, use mapreduce.job.working.dir
2017-06-17 19:34:12,848 INFO [main] mapreduce.JobSubmitter (JobSubmitter.java:printTokens(477)) - Submitting tokens for job: job_local411743219_0001
2017-06-17 19:34:13,120 WARN [main] conf.Configuration (Configuration.java:loadProperty(2172)) - file:/tmp/hadoop-TracyMcGrady/mapred/staging/TracyMcGrady411743219/.staging/job_local411743219_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
2017-06-17 19:34:13,121 WARN [main] conf.Configuration (Configuration.java:loadProperty(2172)) - file:/tmp/hadoop-TracyMcGrady/mapred/staging/TracyMcGrady411743219/.staging/job_local411743219_0001/job.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
2017-06-17 19:34:13,885 WARN [main] conf.Configuration (Configuration.java:loadProperty(2172)) - file:/tmp/hadoop-TracyMcGrady/mapred/local/localRunner/TracyMcGrady/job_local411743219_0001/job_local411743219_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.retry.interval; Ignoring.
2017-06-17 19:34:13,885 WARN [main] conf.Configuration (Configuration.java:loadProperty(2172)) - file:/tmp/hadoop-TracyMcGrady/mapred/local/localRunner/TracyMcGrady/job_local411743219_0001/job_local411743219_0001.xml:an attempt to override final parameter: mapreduce.job.end-notification.max.attempts; Ignoring.
2017-06-17 19:34:13,951 INFO [main] mapreduce.Job (Job.java:submit(1272)) - The url to track the job: http://localhost:8080/
2017-06-17 19:34:13,951 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1317)) - Running job: job_local411743219_0001
2017-06-17 19:34:13,967 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(323)) - OutputCommitter set in config null
2017-06-17 19:34:14,029 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:createOutputCommitter(341)) - OutputCommitter is org.apache.hadoop.mapreduce.lib.output.FileOutputCommitter
2017-06-17 19:34:14,435 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:run(389)) - Waiting for map tasks
2017-06-17 19:34:14,435 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(216)) - Starting task: attempt_local411743219_0001_m_000000_0
2017-06-17 19:34:14,670 INFO [LocalJobRunner Map Task Executor #0] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(129)) - ProcfsBasedProcessTree currently is supported only on Linux.
2017-06-17 19:34:14,873 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:initialize(581)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@228376a9
2017-06-17 19:34:14,889 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:runNewMapper(732)) - Processing split: file:/D:/tmp/input.txt:0+5679
2017-06-17 19:34:14,936 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:createSortingCollector(387)) - Map output collector class = org.apache.hadoop.mapred.MapTask$MapOutputBuffer
2017-06-17 19:34:15,024 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1338)) - Job job_local411743219_0001 running in uber mode : false
2017-06-17 19:34:15,269 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:setEquator(1183)) - (EQUATOR) 0 kvi 26214396(104857584)
2017-06-17 19:34:15,269 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(975)) - mapreduce.task.io.sort.mb: 100
2017-06-17 19:34:15,269 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 0% reduce 0%
2017-06-17 19:34:15,269 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(976)) - soft limit at 83886080
2017-06-17 19:34:15,271 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(977)) - bufstart = 0; bufvoid = 104857600
2017-06-17 19:34:15,271 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:init(978)) - kvstart = 26214396; length = 6553600
2017-06-17 19:34:15,365 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(513)) -
2017-06-17 19:34:15,365 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1440)) - Starting flush of map output
2017-06-17 19:34:15,366 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1459)) - Spilling map output
2017-06-17 19:34:15,366 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1460)) - bufstart = 0; bufend = 989; bufvoid = 104857600
2017-06-17 19:34:15,366 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:flush(1462)) - kvstart = 26214396(104857584); kvend = 26214360(104857440); length = 37/6553600
2017-06-17 19:34:15,486 INFO [LocalJobRunner Map Task Executor #0] mapred.MapTask (MapTask.java:sortAndSpill(1648)) - Finished spill 0
2017-06-17 19:34:15,528 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:done(995)) - Task:attempt_local411743219_0001_m_000000_0 is done. And is in the process of committing
2017-06-17 19:34:15,685 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(513)) - map
2017-06-17 19:34:15,685 INFO [LocalJobRunner Map Task Executor #0] mapred.Task (Task.java:sendDone(1115)) - Task 'attempt_local411743219_0001_m_000000_0' done.
2017-06-17 19:34:15,685 INFO [LocalJobRunner Map Task Executor #0] mapred.LocalJobRunner (LocalJobRunner.java:run(241)) - Finishing task: attempt_local411743219_0001_m_000000_0
2017-06-17 19:34:15,685 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:run(397)) - Map task executor complete.
2017-06-17 19:34:15,731 INFO [Thread-3] util.ProcfsBasedProcessTree (ProcfsBasedProcessTree.java:isAvailable(129)) - ProcfsBasedProcessTree currently is supported only on Linux.
2017-06-17 19:34:15,838 INFO [Thread-3] mapred.Task (Task.java:initialize(581)) - Using ResourceCalculatorProcessTree : org.apache.hadoop.yarn.util.WindowsBasedProcessTree@5a65f5e
2017-06-17 19:34:15,846 INFO [Thread-3] mapred.Merger (Merger.java:merge(568)) - Merging 1 sorted segments
2017-06-17 19:34:15,973 INFO [Thread-3] mapred.Merger (Merger.java:merge(667)) - Down to the last merge-pass, with 1 segments left of total size: 819 bytes
2017-06-17 19:34:15,974 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(513)) -
2017-06-17 19:34:15,987 INFO [Thread-3] Configuration.deprecation (Configuration.java:warnOnceIfDeprecated(840)) - mapred.skip.on is deprecated. Instead, use mapreduce.job.skiprecords
2017-06-17 19:34:15,992 INFO [Thread-3] mapred.Task (Task.java:done(995)) - Task:attempt_local411743219_0001_r_000000_0 is done. And is in the process of committing
2017-06-17 19:34:15,995 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(513)) -
2017-06-17 19:34:15,995 INFO [Thread-3] mapred.Task (Task.java:commit(1156)) - Task attempt_local411743219_0001_r_000000_0 is allowed to commit now
2017-06-17 19:34:16,000 INFO [Thread-3] output.FileOutputCommitter (FileOutputCommitter.java:commitTask(439)) - Saved output of task 'attempt_local411743219_0001_r_000000_0' to file:/D:/tmp/output/_temporary/0/task_local411743219_0001_r_000000
2017-06-17 19:34:16,002 INFO [Thread-3] mapred.LocalJobRunner (LocalJobRunner.java:statusUpdate(513)) - reduce > reduce
2017-06-17 19:34:16,002 INFO [Thread-3] mapred.Task (Task.java:sendDone(1115)) - Task 'attempt_local411743219_0001_r_000000_0' done.
2017-06-17 19:34:16,300 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1345)) - map 100% reduce 100%
2017-06-17 19:34:16,301 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1356)) - Job job_local411743219_0001 completed successfully
2017-06-17 19:34:16,356 INFO [main] mapreduce.Job (Job.java:monitorAndPrintJob(1363)) - Counters: 27
File System Counters
FILE: Number of bytes read=12555
FILE: Number of bytes written=385307
FILE: Number of read operations=0
FILE: Number of large read operations=0
FILE: Number of write operations=0
Map-Reduce Framework
Map input records=10
Map output records=10
Map output bytes=989
Map output materialized bytes=911
Input split bytes=87
Combine input records=10
Combine output records=9
Reduce input groups=9
Reduce shuffle bytes=0
Reduce input records=9
Reduce output records=9
Spilled Records=18
Shuffled Maps =0
Failed Shuffles=0
Merged Map outputs=0
GC time elapsed (ms)=0
CPU time spent (ms)=0
Physical memory (bytes) snapshot=0
Virtual memory (bytes) snapshot=0
Total committed heap usage (bytes)=391118848
File Input Format Counters
Bytes Read=5679
File Output Format Counters
Bytes Written=885三.总结
Map端:
1.每个输入分片会让一个map任务来处理,默认情况下,以HDFS的一个块的大小(默认为64M)为一个分片,当然我们也可以设置块的大小。map输出的结果会暂且放在一个环形内存缓冲区中(该缓冲区的大小默认为100M,由io.sort.mb属性控制),当该缓冲区快要溢出时(默认为缓冲区大小的80%,由io.sort.spill.percent属性控制),会在本地文件系统中创建一个溢出文件,将该缓冲区中的数据写入这个文件。
2.在写入磁盘之前,线程首先根据reduce任务的数目将数据划分为相同数目的分区,也就是一个reduce任务对应一个分区的数据。这样做是为了避免有些reduce任务分配到大量数据,而有些reduce任务却分到很少数据,甚至没有分到数据的尴尬局面。其实分区就是对数据进行hash的过程。然后对每个分区中的数据进行排序,如果此时设置了Combiner,将排序后的结果进行Combia操作,这样做的目的是让尽可能少的数据写入到磁盘。
3.当map任务输出最后一个记录时,可能会有很多的溢出文件,这时需要将这些文件合并。合并的过程中会不断地进行排序和combia操作,目的有两个:1.尽量减少每次写入磁盘的数据量;2.尽量减少下一复制阶段网络传输的数据量。最后合并成了一个已分区且已排序的文件。为了减少网络传输的数据量,这里可以将数据压缩,只要将mapred.compress.map.out设置为true就可以了。
4.将分区中的数据拷贝给相对应的reduce任务。有人可能会问:分区中的数据怎么知道它对应的reduce是哪个呢?其实map任务一直和其父TaskTracker保持联系,而TaskTracker又一直和JobTracker保持心跳。所以JobTracker中保存了整个集群中的宏观信息。只要reduce任务向JobTracker获取对应的map输出位置就ok了哦。
到这里,map端就分析完了。那到底什么是Shuffle呢?Shuffle的中文意思是“洗牌”,如果我们这样看:一个map产生的数据,结果通过hash过程分区却分配给了不同的reduce任务,是不是一个对数据洗牌的过程呢?呵呵。
Reduce端:
1.Reduce会接收到不同map任务传来的数据,并且每个map传来的数据都是有序的。如果reduce端接受的数据量相当小,则直接存储在内存中(缓冲区大小由mapred.job.shuffle.input.buffer.percent属性控制,表示用作此用途的堆空间的百分比),如果数据量超过了该缓冲区大小的一定比例(由mapred.job.shuffle.merge.percent决定),则对数据合并后溢写到磁盘中。
2.随着溢写文件的增多,后台线程会将它们合并成一个更大的有序的文件,这样做是为了给后面的合并节省时间。其实不管在map端还是reduce端,MapReduce都是反复地执行排序,合并操作,现在终于明白了有些人为什么会说:排序是hadoop的灵魂。
3.合并的过程中会产生许多的中间文件(写入磁盘了),但MapReduce会让写入磁盘的数据尽可能地少,并且最后一次合并的结果并没有写入磁盘,而是直接输入到reduce函数。















 7311
7311











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









