






1.pom.xml
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>org.example</groupId>
<artifactId>ls</artifactId>
<version>1.0-SNAPSHOT</version>
<name>ls</name>
<!-- FIXME change it to the project's website -->
<url>http://www.example.com</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<maven.compiler.source>1.8</maven.compiler.source>
<maven.compiler.target>1.8</maven.compiler.target>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-hdfs</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-client</artifactId>
<version>2.6.0</version>
</dependency>
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-mapreduce-client-core</artifactId>
<version>2.6.0</version>
</dependency>
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
<version>2.3.2</version>
<configuration>
<source>1.8</source>
<target>1.8</target>
</configuration>
</plugin>
<plugin>
<artifactId>maven-assembly-plugin</artifactId>
<configuration>
<descriptorRefs>
<descriptorRef>jar-with-dependencies</descriptorRef>
</descriptorRefs>
<archive>
<manifest>
<!--<mainClass>com.aaa.App</mainClass>-->
</manifest>
</archive>
</configuration>
<executions>
<execution>
<id>make-assembly</id>
<phase>package</phase>
<goals>
<goal>single</goal>
</goals>
</execution>
</executions>
</plugin>
</plugins>
</build>
</project>
2.WCMapper
package org.example.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import java.io.IOException;
/**
* KEYIN:输入的key类型
* VALUEIN:输入的value类型
* KEYOUT:输出的key类型
* VALUEOUT:输出的value类型
*
*/
public class WCMapper extends Mapper<IntWritable, Text,Text, IntWritable> {
Text k = new Text();
IntWritable v = new IntWritable(1);
@Override
protected void map(IntWritable key, Text value, Context context) throws IOException, InterruptedException {
//1、将文本转化成string
String line = value.toString();
//2、将字符串切割
// \\s+是空格
String[] words = line.split("\\s+");
//3、将每一个单词写出去
for (String word : words){
k.set(word);
context.write(k,v);
}
}
}
3.WCReducer
package org.example.mr.wc;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import java.io.IOException;
/**
* KEYIN:reduce端输入的key类型,即map端输出的key类型
* VALUEIN:reduce端输入的value类型,即map端输出的value类型
* KEYOUT:reduce端输出的key类型
* VALUEOUT:reduce端输出的value类型
*/
public class WCReducer extends Reducer<Text, IntWritable, Text,IntWritable> {
int sum;
IntWritable v = new IntWritable();
@Override
protected void reduce(Text key, Iterable<IntWritable> values, Context context) throws IOException, InterruptedException {
//reduce接收到的类型大概是这样的 (wish,(1,1,1,1,1,1,1))
sum=0;
//遍历迭代器
for (IntWritable count : values) {
//对迭代器进行累加求和
sum+=count.get();
}
//将key和value进行写出
v.set(sum);
context.write(key,v);
}
}
4.WCDriver
package org.example.mr.wc;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import java.io.IOException;
public class WCDriver {
public static void main(String[] args) throws IOException, ClassNotFoundException, InterruptedException {
//1、创建配置文件,创建Job
Configuration conf = new Configuration();
Job job = Job.getInstance(conf, "wordcount");
//2、设置jar的位置
job.setJarByClass(WCDriver.class);
//3、设置Map和Reduce的位置
job.setMapperClass(WCMapper.class);
job.setReducerClass(WCReducer.class);
//4、设置Map输出的key,value类型
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(IntWritable.class);
//5、设置Reduce输出的key,value类型
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
//6、设置输入输出路径
FileInputFormat.setInputPaths(job,new Path(args[0]));
FileOutputFormat.setOutputPath(job,new Path(args[1]));
//7、提交程序运行
boolean result = job.waitForCompletion(true);
System.exit(result?0:1);
}
}
5.写完之后,clean 然后 package


6.将胖包直接通过xftp放入虚拟机中

7.start-all.sh启动hadoop各节点并通过jps确认是否启动成功
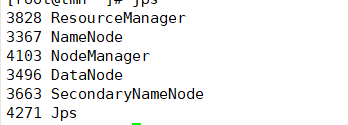
8.hdfs dfs -mkdir /input
在hdfs上创建文件夹input
9.hdfs dfs -put /opt/1.txt /input/1.txt
将文件放入hdfs上的input文件夹下
10.[root@tmh opt]# hadoop jar ls-1.0-SNAPSHOT-jar-with-dependencies.jar org.example.mr.wc.WCDriver /input /output

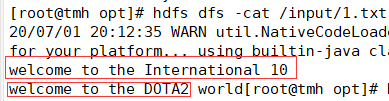
11.hdfs dfs -cat /input/1.txt查看原文件内容
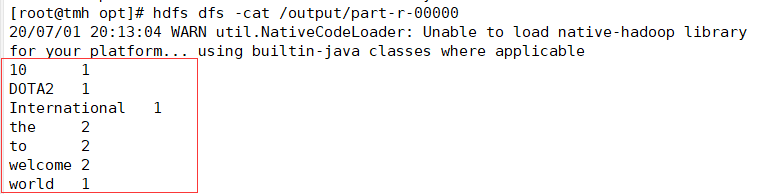
12.hdfs dfs -cat /output/1.txt查看wordcount后的文件内容是否符合















 313
313











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









