







01. 简介
RabbitMQ 是一个由 Erlang 语言开发的 AMQP 的开源实现。最初起源于金融系统,用于在分布式系统中存储转发消息。AMQP 主要由 Cisco、RedHat 等联合制定,RabbitMQ 由 RabbitMQ Technologies Ltd 公司开发并提供商业支持。
AMQP 0-9-1:Advanced Message Queue Protocol,高级消息队列协议,一种消息传递协议。它是应用层协议的一个开放标准,为面向消息的中间件设计,符合标准的客户端与消息传递中间件代理可进行通信。
02. AMQP
2-1. AMQP模型

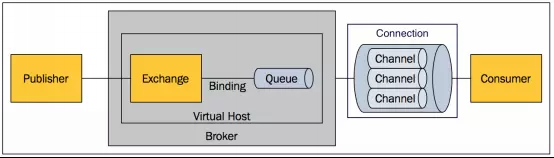
2-2. 概念描述
-
Message:消息,由消息头(Header)和消息体(Body)组成。Header 是由生产者添加的各种属性的集合,包括:Message 是否被持久化、优先级是多少、由哪个 Message Queue 接收等,简略概括:routing-key(路由键)、priority(优先级)、delivery-mode(持久存储)。消息体是不透明的,是真正需要发送的数据内容。Header 就像信封,Body 则是信纸。
-
Publisher:生产者,即消息的生产者,向 Exchange 发布消息的应用程序。
-
Consumer:消费者,即接收生产者发来的消息的客户端应用。
-
Broker:消息队列代理服务器,接收来自发布者(发布它们的应用程序,也称生产者)的消息,并将消息路由到使用者(处理它们的应用程序,也称消费者)。形象比喻:邮局。
-
Virtual Host:虚拟主机,相当于命名空间,类似权限控制组,一个 Virtaul Host 里面可以有若干个 Exchange 和 Queue,当多个不同权限的用户使用同一个 Broker 提供的服务时,可划分出多个 vhost,每个用户在自己的 vhost 中创建 Exchange/Queue 等。多个 vhost 是隔离的,vhost 之间无法通讯,不用担心命名冲突(队列和交换器和绑定)。就像 Tomcat 中 webapps 路径下部署多个 web 项目。RabbitMQ 默认的 vhost是“/”。
-
Exchange:交换器,Message 到达 Broker 的第一站,根据 Binding 规则,匹配查询表中的 Routing Key,分发消息到 Queue 中去,如同邮递员。
-
ExchangeType:交换器类型,决定了路由消息行为。
-
Routing Key:生产者在将消息发送给 Exchange 的时候,一般会指定一个 Routing Key,作为这个消息的路由规则,而这个 Routing Key 需要与 Exchange Type 及 Binding Key 联合使用才能最终生效。在 Exchange Type 与 Binding Key 固定的情况下(在正常使用时一般这些内容都是固定配置好的),我们的生产者就可以在发送消息给 Exchange 时,通过指定 Routing Key 来决定消息流向哪里。
-
Binding:将 Exchange 与 Queue 关联起来,将消息放到指定的 Queue。
-
Binding Key:Exchange 在与多个 Queue 发生 Binding 后会生成一张路由表,路由表中存储着 Queue 所需消息的限制条件即 Binding Key。当 Exchange 收到 Message 时会解析其 Header 得到 Routing Key,Exchange 根据 Routing Key 与 Exchange Type 将 Message 路由到 Queue。Binding Key 由 Consumer 在 Binding Exchange 与 Queue 时指定,而 Routing Key 由 Producer 发送 Message 时指定,两者的匹配方式由 Exchange Type 决定,就好比于邮件上面的地址。
-
Queue:也叫 Message Queue,消息队列,用来保存还没被消费者消费的消息。好比邮箱。一个消息可以进入一个或多个队列,除非消费者来取走,否则它会一直在消息队列中。
-
Connection:Publisher/Consumer 和 Broker 之间的 TCP 连接。断开连接的操作只会在 Client 端进行,Broker 不会断开连接,除非网络故障或 Broker 服务出现问题。
-
Channel:信道,多路复用、独立的双向数据传输通道。仅仅创建了客户端到 Broker 之间的连接后,客户端还是不能发送消息的。需要为每一个 Connection 创建 Channel,AMQP 协议规定只有通过 Channel才能执行 AMQP 的命令。一个 Connection 可以包含多个 Channel。TCP 连接的建立和释放都是十分昂贵的,如果一个客户端每一个线程都与 Broker 建立一个 TCP 连接,就算不考虑 TCP 连接是否浪费,操作系统也无法承受。无论是发布消息、订阅队列、接收消息都是通过信道来完成。复用信道是为了降低系统资源的消耗。
03. 使用指南


https://i2.wp.com/img-blog.csdn.net/20180812231313584
https://www.mgchen.com/uploads/ued_php/image/20180713/1531475104414925.png
下面是在 Java 客户端中如何使用 RabbitMQ:
RabbitMQ Java 客户端使用 com.rabbitmq.client 作为顶级依赖包,其中关键类和接口是:
- com.rabbitmq.client.Channel:表示一个AMQP 0-9-1通道,并提供大部分操作(协议方法)。
- com.rabbitmq.client.Connection:表示一个 AMQP 0-9-1 连接。
- ConnectionFactory:构造 Connection 实例。
- Consumer:消费者。
- DefaultConsumer:消费者常用的基类。
- BasicProperties:消息属性(元数据)。
- BasicProperties.Builder:BasicProperties 生成器。
通过 Channel 接口进行协议操作,Connection 接口用于打开通道、注册连接生命周期事件处理程序、关闭不再需要的连接。 通过 ConnectionFactory 实例化连接,配置各种连接设置(例如虚拟主机或用户名)。
3-1. 创建连接和通道
使用给定参数连接到RabbitMQ节点:
ConnectionFactory factory = new ConnectionFactory();
factory.setUsername(userName);
factory.setPassword(password);
factory.setVirtualHost(virtualHost);
factory.setHost(hostName);
factory.setPort(portNumber);
Connection conn = factory.newConnection();
在默认情况下,用户 guest 只能从本地主机连接。这是为了限制生产系统中众所周知的凭据的使用。user guest can only connect from localhost
或者也可以使用 URI 形式:
ConnectionFactory factory = new ConnectionFactory();
factory.setUri("amqp://userName:password@hostName:portNumber/virtualHost");
Connection conn = factory.newConnection();
如果在创建连接之前未分配属性,则将使用默认值:
| Property | Default Value |
|---|---|
| Username | “guest” |
| Password | “guest” |
| Virtual host | “/” |
| Hostname | “localhost” |
| port | 5672 for regular connections, 5671 for connections that use TLS |
打开、关闭通道,关闭连接:
Channel channel = conn.createChannel();
channel.close(); //关闭通道可能被认为是一种良好的实践,但并不是必需的,当底层连接关闭时,它将自动完成。
conn.close();
3-2. 声明交换器和队列
客户端应用程序与 Exchange 和 Queue(协议的高级构建块)一起使用。 在使用它们之前必须先声明它们。声明任何一种类型的对象都只是确保其中一个名称存在,并在必要时创建它。
// 声明direct类型的、持久的、非自动删除的交换器
channel.exchangeDeclare(exchangeName, "direct", true);
// 获取一个名称随机的,非持久、独占的、自动删除的队列
String queueName = channel.queueDeclare().getQueue();
// 使用给定的路由键绑定交换器和队列
channel.queueBind(queueName, exchangeName, routingKey);
注意,这是当只有一个客户端要使用队列时,声明队列的一种典型方法,如果多个客户端要共享一个队列,则需要一个共同的队列名称,使用以下代码:
channel.exchangeDeclare(exchangeName, "direct", true);
//「名称,是否持久化,是否独占模式,是否自动删除,消息其他参数」
channel.queueDeclare(queueName, isDurable, isExclusive, isAutoDelete, args);
channel.queueBind(queueName, exchangeName, routingKey);
被动声明
队列和交换器可以被动地进行声明,用于检查指定名称的实体是否存在:
- 若存在,声明操作是一个 no-op。
- 对于队列,成功的被动声明将返回与非被动声明相同的信息,即队列中处于就绪状态的消费者和消息的数量。
- 对于交换器,返回值不包含有用的信息,若没有通道异常发生,意味着该交换器确实存在。
- 若不存在,则操作失败,会出现通道级异常。通道在那之后不能再使用,故通常使用一次性(临时)通道进行被动声明。
使用 Channel#queueDeclarePassive 和 Channel#exchangeDeclarePassive 方法被动声明:
Queue.DeclareOk response = channel.queueDeclarePassive("queue-name");
// returns the number of messages in Ready state in the queue
response.getMessageCount();
// returns the number of consumers the queue has
response.getConsumerCount();
一些常见的操作还有一个 “no wait” 版本,它不会等待服务器响应。例如,若要声明队列并指示服务器不发送任何响应,请使用:
channel.queueDeclareNoWait(queueName, true, false, false, null);“no wait” 版本效率更高,但提供的安全保障更低。例如,它们更依赖于检测失败操作的心跳机制。“no wait” 版本只在拓扑(队列、绑定)频繁变化的场景中需要。
3-3. 删除实体和消息
// 1.显示地删除队列
channel.queueDelete("queue-name")
// 2.仅当队列为空时删除它
channel.queueDelete("queue-name", false, true)
// 3.仅当队列没有任何消费者时删除它
channel.queueDelete("queue-name", true, false)
// 清除队列(删除其所有消息)
channel.queuePurge("queue-name")
3-4. 发布消息
AMQP 0-9-1 协议预定义了消息附带的 14 个属性集,比如:
- deliveryMode:将消息的传递模式标记为持久性(值为2)或瞬态(任何其他值)。
- contentType:用于描述编码的 mime 类型。 例如 application/json。
- replyTo:通常用于命名回调队列。
- relatedId:用于关联 RPC 的响应与请求。
下面是如何发布:
byte[] messageBodyBytes = "Hello, world!".getBytes();
// 1.普通发布
channel.basicPublish(exchangeName, routingKey, null, messageBodyBytes);
// 2.指定强制性标志,或发送具有预设属性的消息
channel.basicPublish(exchangeName, routingKey, mandatory,
MessageProperties.PERSISTENT_TEXT_PLAIN,
messageBodyBytes);
// 3.使用Builder类构建具有所需属性的BasicProperties对象:内容类型为文本,传递模式为2(持久),优先级为1,用户Id为"bob"
channel.basicPublish(exchangeName, routingKey,
new AMQP.BasicProperties.Builder()
.contentType("text/plain")
.deliveryMode(2)
.priority(1)
.userId("bob")
.build(),
messageBodyBytes);
发布具有用户自定义 Header 属性的消息:
Map<String, Object> headers = new HashMap<String, Object>();
headers.put("latitude", 51.5252949);
headers.put("longitude", -0.0905493);
channel.basicPublish(exchangeName, routingKey,
new AMQP.BasicProperties.Builder()
.headers(headers)
.build(),
messageBodyBytes);
发布具有过期属性的消息:
channel.basicPublish(exchangeName, routingKey,
new AMQP.BasicProperties.Builder()
.expiration("60000")
.build(),
messageBodyBytes);
3-5. 消息订阅
Push API,接收消息的最有效方法是使用 Consumer 接口设置订阅,消息将自动发送给消费者,而不必显式请求。
在调用 Consumer 的API方法时,单个订阅始终由其消费者标签所引用,消费者标签是一个消费者标识符,它可以是客户端生成的,也可以是服务器生成的,消费者标签可用于取消消费者。
channel.basicCancel(consumerTag);
不同的消费者必须具有不同的标签,强烈建议不要在连接上使用重复的消费者标签,这可能导致自动连接恢复和消费者监视数据混乱的问题。
实现 Consumer 的最简单方法是子类化 DefaultConsumer,可以在 basicConsume 方法调用上传递此子类的对象以建立订阅:
boolean autoAck = false;
channel.basicConsume(queueName, autoAck, "myConsumerTag",
new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag,
Envelope envelope,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
String routingKey = envelope.getRoutingKey();
String contentType = properties.getContentType();
long deliveryTag = envelope.getDeliveryTag();
// (process the message components here ...)
channel.basicAck(deliveryTag, false); //确认消息
}
});
3-6. 消息拉取
Pull API,使用 Channel#basicGet 方法显式地拉取单条消息,返回 GetResponse 实例,可以从中提取消息的 Header 和 Body。
boolean autoAck = false;
GetResponse response = channel.basicGet(queueName, autoAck);
if (response == null) {
// No message retrieved.
} else {
AMQP.BasicProperties props = response.getProps();
byte[] body = response.getBody();
long deliveryTag = response.getEnvelope().getDeliveryTag();
// ...
channel.basicAck(method.deliveryTag, false);
}
3-7. 返回监听器
如果发布的消息设置了 “mandatory” 标志,但无法进行路由,代理会将其返回给发布客户端(通过 AMQP.Basic.Return 命令)。
要收到返回的通知,发布客户端可以实现 ReturnListener 接口,调用 Channel#addReturnListener 方法。如果客户端没有为特定的通道配置一个返回监听器,那么相关的返回消息将被静默删除。
channel.addReturnListener(new ReturnListener() {
public void handleReturn(int replyCode,
String replyText,
String exchange,
String routingKey,
AMQP.BasicProperties properties,
byte[] body) throws IOException {
// ...
}
});
3-8. 连接监听器
AMQP 0-9-1 的连接和通道具有以下生命周期状态:
- open:对象处于可用状态。
- closing:对象已经被显式地通知在本地关闭,并且已经向任何支持的下层对象发出了关闭请求,并正在等待它们的关闭过程完成。
- closed:该对象已收到所有下层对象的关闭完成通知,自身已关闭。
对象总是以关闭状态结束,不管关闭的原因是什么,比如应用程序请求、内部客户端库故障、远程网络请求或网络故障。
为连接对象添加关闭监听器:
connection.addShutdownListener(new ShutdownListener() {
public void shutdownCompleted(ShutdownSignalException cause) {
if (cause.isHardError()) { // 是否为连接或通道错误
Connection conn = (Connection)cause.getReference();
if (!cause.isInitiatedByApplication()) {
Method reason = cause.getReason();
// ...
}
// ...
} else {
Channel ch = (Channel)cause.getReference();
// ...
}
}
});
移除关闭监听器:connection.removeShutdownListener(ShutdownListener listener),注意,向已经关闭的连接对象添加一个 ShutdownListener 将立即触发该监听器。
调查对象关闭的原因:connection.getCloseReason()。
显式通知连接对象关闭:connect.close(int closeCode, String closeMessage)。
测试连接对象是否处于打开状态:connection.isOpen()。
对于生产代码,不建议使用通道和连接对象的 isOpen() 方法,因为在调用该方法后,状态可能改变。
public void brokenMethod(Channel channel) {
if (channel.isOpen()) {
// 若此时状态改变,则下面的代码会出错
channel.basicQos(1);
}
}
我们通常不应该进行这种检查,而只是尝试所需的操作。如果在执行代码期间,连接的通道关闭,则会抛出一个 ShutdownSignalException,指示对象处于无效状态。我们还应该捕捉 SocketException (当代理意外关闭连接时)或 ShutdownSignalException(当代理启动清理关闭时)等 IOException。
public void validMethod(Channel channel) {
try {
// ...
channel.basicQos(1);
} catch (ShutdownSignalException sse) {
// 检查通道是否已经关闭,以及关闭的原因
} catch (IOException ioe) {
// 检查连接为何关闭
}
}
3-9. 高级连接选项
默认情况下,消费者线程会自动分配到新的 ExecutorService 线程池中,如果需要更大的控制权,可在 newConnection() 方法上提供一个 ExecutorService:
ExecutorService es = Executors.newFixedThreadPool(20);
Connection conn = factory.newConnection(es);
当连接关闭时,默认的 ExecutorService 将被关闭,但是用户提供的 ExecutorService 不会被关闭。提供自定义 ExecutorService 的客户端必须调用其 shutdown() 方法关闭,否则可能会阻止 JVM 的终止。
相同的 executor 服务可以在多个连接之间共享,也可以在重新连接时串行地重复使用,但在关闭之后不能再使用。
仅当有证据表明在处理 Consumer 回调存在严重瓶颈时,才应考虑使用此功能。如果没有执行消费者回调,或者很少执行,那么默认分配就足够了。
3-10. 自动恢复
RabbitMQ Java 客户端支持自动恢复连接和拓扑,默认启用。如果因异常而导致恢复失败(例如,仍然无法到达RabbitMQ节点),将在固定时间间隔(默认为5秒)后重试,间隔可以配置。
ConnectionFactory factory = new ConnectionFactory();
factory.setAutomaticRecoveryEnabled(true); //显示开启自动恢复
factory.setTopologyRecoveryEnabled(false); //显示关闭拓扑恢复
factory.setNetworkRecoveryInterval(10000); //设置重试间隔时间
Connection conn = factory.newConnection();
自动恢复遵循以下步骤:
-
重新连接。
-
还原连接监听器。
-
重新打开通道
-
恢复通道监听器。
-
恢复通道
basic.qos设置、发布者确认和事务设置。
拓扑恢复包括对每个通道执行的以下操作:
- 重新声明交换器(预定义的除外)
- 重新声明队列
- 恢复所有绑定
- 恢复所有消费者
自动连接恢复将由以下事件触发:
- 连接的I / O循环中引发了 IOException。
- Socket 读取操作超时。
- 检测到了服务器心跳丢失。
- 连接的I / O循环中引发的任何其他意外的异常。
当应用程序通过 Connection.Close 方法关闭连接时,将不会触发连接恢复。
通道级异常不会触发任何类型的恢复,因为它们通常表示应用程序中的语义问题(例如,尝试从不存在的队列中使用)。
当然,如果与 RabbitMQ 节点的初始连接就失败了,自动连接恢复将无法进行。开发人员需负责重试此类连接,记录失败的尝试,限制重试次数等等。
ConnectionFactory factory = new ConnectionFactory();
// configure various connection settings
try {
Connection conn = factory.newConnection();
} catch (java.net.ConnectException e) {
Thread.sleep(5000);
// apply retry logic
}
连接断开后(或处于恢复状态时),使用
Channel.basicPublish发布的消息将丢失,恢复连接后,客户端不会将它们重新排入队列。为了确保已发布的消息到达 RabbitMQ 应用程序,需要使用发布者确认并解决连接失败的问题。
拓扑恢复依赖于实体(队列、交换器、绑定、消费者)的每个连接的缓存。例如,在连接上声明队列时,它将被添加到缓存中,当它被删除或计划删除时(例如自动删除队列),缓存将被删除。
某些 RabbitMQ 特性使客户端无法观察到一些拓扑变化(例如,当队列因 TTL 过期而被删除时)。在最常见的情况下,RabbitMQ Java 客户端会尝试使缓存 entry 无效化:
-
队列被删除。
-
交换器被删除。
-
绑定被删除。
-
消费者在自动删除队列上被取消。
-
队列或交换器与自动删除交换器解除绑定。
故依赖于自动删除队列,或交换器、队列 TTL(注意不是消息TTL),并使用自动连接恢复的应用程序,应显式地删除那些已知未使用或已删除的实体,以清除客户端拓扑缓存,使用以下方法:Channel#queueDelete,Channel#exchangeDelete,Channel#queueUnbind,Channel#exchangeUnbind ,它们在 RabbitMQ 3.3.x 中是幂等的(删除不存在的内容不会导致异常)。
当使用手动确认模式时,在消息传递和确认之间,到 RabbitMQ 节点的网络连接可能失败,连接恢复后,RabbitMQ 将重置所有通道上的交付标签。
这意味着带有旧交付标签的
basic.ack、basic.nack、basic.reject将导致通道异常。为了避免这种情况,RabbitMQ Java 客户端会跟踪并更新交付标签,以使它们在恢复期间单调增长。带有旧交付标签的确认将不会被发送,使用手动确认模式和自动恢复的应用程序,必须有能力处理重新交付。
3-11. 心跳检测
操作系统检测到TCP连接中断需要花费相当长的时间(例如,在Linux上为默认配置,大约需要11分钟)。 AMQP 0-9-1 提供了心跳检测功能,以确保应用程序层迅速发现中断的连接。
心跳超时值(heartbeat timeout)定义了在什么时间段之后,RabbitMQ 和客户端应认为 TCP 连接是不可到达的(关闭)。超时时间以秒为单位,默认值为 60。默认情况下,代理和客户端将尝试协商心跳。当两个值都大于 0 时,将使用请求值中较低的那个。
超时值为 0 表示禁用心跳。也可以在两端使用很高的超时值(例如1800秒),以有效禁用心跳,因为帧传送太少了,不会产生实际的差别。当然,不建议禁用心跳,除非用 TCP keepalives(见下) 来代替。
ConnectionFactory factory = new ConnectionFactory();
factory.setRequestedHeartbeat(60);
//注意,如果RabbitMQ服务器配置了非零心跳超时(这是从3.6.x开始的版本中的默认值),则客户端只能降低该值,而不能增加该值。
注意,将心跳超时值设置得过低可能会导致误报(peer被认为不可用,而实际情况并非如此),原因包括临时网络拥塞、短期服务器流控制等。根据有效反馈,小于 5 秒的值可能会导致误报,小于或等于 1 秒的值极可能会导致误报。 对于大多数环境,5 到 20 秒范围内的值是最佳的。
心跳帧大约每 2 秒钟发送一次,该值有时被称为心跳间隔(heartbeat interval)。在错过两次心跳后,对等方被认为是不可达的。不同的客户端对此有不同的表现,但是TCP连接将被关闭。当客户端根据心跳检测到无法访问RabbitMQ 节点时,它需要重新进行连接。
RabbitMQ 节点和客户端将记录由于错过心跳而关闭的连接,为排除故障提供有效信息。
不要将超时值与间隔值混淆,RabbitMQ 和官方客户端可以配置超时值,但某些客户端可能允许配置间隔值。
任何流量(例如协议操作、发布的消息、确认)都可计入有效心跳。客户端可以选择发送心跳帧,不管连接上是否有其他流量,但有些心跳帧仅在必要时才发送。
TCP 包含一个机制(也就是keepalive),其目的类似于上述消息协议和网络超时中的心跳。由于缺省值不充分,因此不能假定 TCP keepalives 适合于消息传递协议。但是,通过适当的调优,在应用程序不能支持心跳或使用合理值的环境中,它们可以作为一种额外的防御机制。
TCP keepalives 将覆盖主机上的所有 TCP 连接,包括入站和出站连接。
3-12. 更多连接设置
-
与连接,通道,恢复和消费者生命周期相关的未处理异常,将被委托给异常处理程序。异常处理程序是实现 ExceptionHandler 接口的任何对象。默认情况下,使用 DefaultExceptionHandler 实例,它将异常详细信息打印到标准输出。可以自定义异常处理程序。「异常处理程序应该用于异常日志记录。」
ConnectionFactory factory = new ConnectionFactory(); factory.setExceptionHandler(customHandler); -
客户端收集活跃连接的运行时指标,是一个可选特性,在 ConnectionFactory 级别,使用
setMetricsCollector(metricsCollector)方法,MetricsCollector 实例在客户端代码的多个地方调用。指标包括:- 打开的连接数
- 打开的通道数
- 已发布的消息数
- 已消费的消息数
- 已确认的消息数
- 已拒绝的消息数
指标收集不支持事务。例如,如果在一个事务中发送了一个确认,然后该事务被回滚,那么该确认将被计算在客户端指标中(但显然不是由代理来计算)。请注意,确认实际上被发送到代理,然后被事务回滚取消,因此就发送的确认而言,客户端指标是正确的。总之,不要将客户端指标用于关键业务逻辑,它们不能保证完全准确。它们被用来简化关于运行系统的推理,并使操作更加高效。
-
可以使用 TLS 加密客户端和代理之间的通信。 还支持客户端和服务器身份验证(也称为对等验证)。 下面在 Java 客户端上使用加密的最简单的方法:
ConnectionFactory factory = new ConnectionFactory(); factory.useSslProtocol();注意,在上面的示例中,客户端没有强制执行任何服务器身份验证(对等证书链验证),默认情况下使用“信任所有证书”信任管理器。这对于本地开发很方便,但是容易受到中间人攻击,因此不推荐用于生产。🔗 TLS guide
04. 工作流程
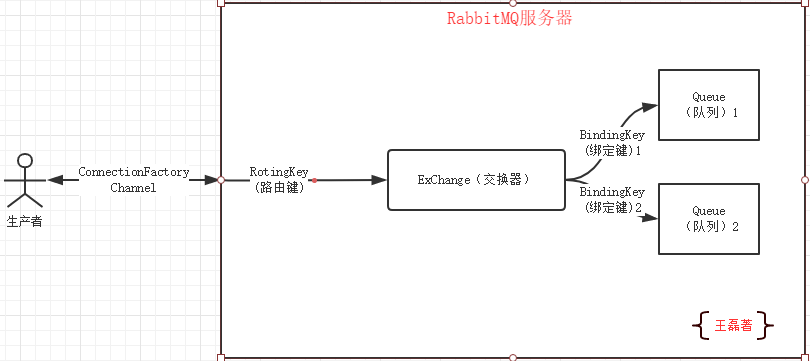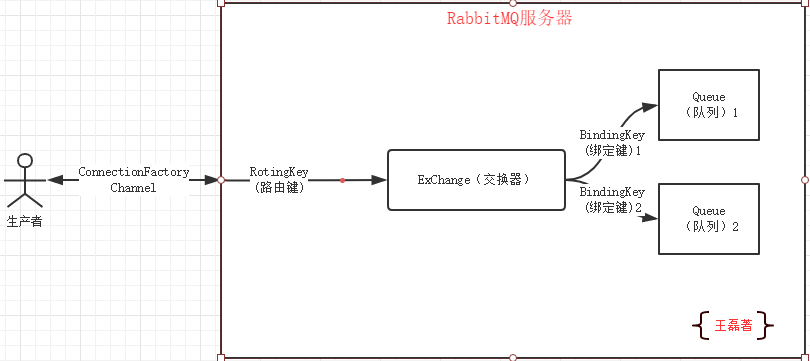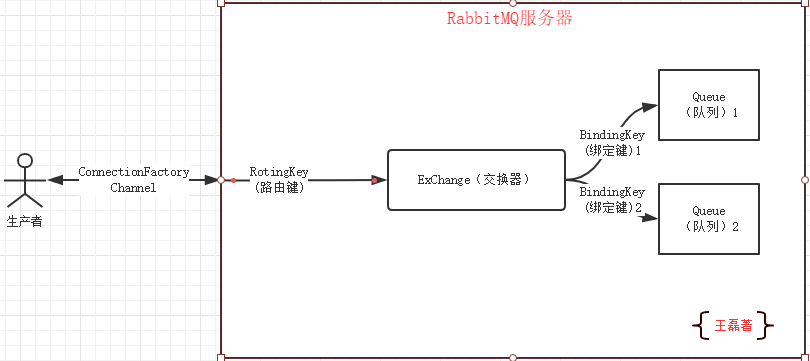
RabbitMQ 工作流程:
1)生产者跟 RabbitMQ 建立连接(Channel)。
2)将想要发布的消息发送到交换器(Exchange)。
3)交换器根据特定规则,将消息路由到某个队列(Queue),不符合任何规则的消息将被丢弃。
4)RabbitMQ 监控该队列,一旦发现有消费者订阅了该队列,就将消息发送给消费者进行处理,消息被成功消费后将该消息从队列中删除。
🔗 Exchange to Exchange Bindings
05. 通道
🔗 Channel
有些应用程序需要多个与代理的逻辑连接,但同时打开许多 TCP 连接是不可取的,这样做会浪费系统资源,并使配置防火墙更加困难。AMQP 0-9-1 连接通过多个通道进行复用,这些通道可以被认为是“共享单个TCP连接的轻量级连接”。
客户端执行的每个协议操作都在通道上发生。 通道上的通信与另一通道上的通信是独立的,因此每种协议方法还带有一个通道 ID(又称通道号),是代理和客户端都用来确定该方法用于哪个通道的整数。
ConnectionFactory cf = new ConnectionFactory();
// cf.setRequestedChannelMax(32); // 可以为连接设置最大通道数
Connection conn = cf.createConnection();
Channel channel = conn.createChannel();
// do some work
channel.close();
对于使用多个线程/进程进行处理的应用程序,常见操作是为每个线程/进程打开一个新通道,而不在它们之间共享通道。Channel 不是线程安全的。
可以使用通道池来避免在共享通道上并发发布:一旦一个线程完成了一个通道的使用,它将返回到池中,从而使该通道可用于另一个线程。可以将通道池视为一种特定的同步解决方案。建议使用现有池库代替本地解决方案,例如 Spring AMQP。
就像连接一样,通道也是长期存在的。由于每次打开通道都是网络往返,因此无需为每个操作都打开一个通道,这样做的效率非常低。
通道只存在于连接的上下文中,从不单独存在。当一个连接关闭时,它上面的所有通道都关闭了。
通道还可能由于协议异常而被关闭,某些情况被假定为协议中的可恢复(软)错误,它们使通道关闭后,应用程序可以打开另一个通道,然后尝试恢复或重试许多次。 常见的有:
- 使用不匹配的属性重新声明现有队列或交换器,会出现
406 PRECONDITION_FAILED错误。- 访问不允许用户访问的资源,会出现
403 ACCESS_REFUSED错误。- 绑定不存在的队列或交换器,会出现
404 NOT_FOUND错误。- 消费不存在的队列,或发布到不存在的交换器,会出现
404 NOT_FOUND错误。- 从声明独占队列之外的连接访问该独占队列,会出现
405 RESOURCE_LOCKED错误。
当 RabbitMQ 关闭通道时,它会使用异步协议方法通知客户端。换句话说,导致通道异常的操作不会立即失败,但是通道关闭事件处理程序将在稍后触发。
06. 队列
🔗 Queue
队列有以下属性:
-
Name。
-
Durable,持久的(队列在 Broker 重新启动后仍然存在)。
-
Exclusive,排他的(仅由一个连接使用,且该连接关闭时队列将被删除)。
-
Auto-delete,自动删除(当最后一个消费者取消订阅时,队列将被删除)。
-
Arguments (可选的、用于插件和特定 Broker 的特性,如消息TTL、队列长度限制等)。
必须先声明队列,然后才能使用它。 声明队列时,若队列尚不存在将创建,若队列已存在并且其属性与声明中的相同,则该声明无效,当现有队列属性与声明中的属性不同时,将导致代码为 406(PRECONDITION_FAILED)的通道级异常。
应用程序可以自定义队列名称,也可以要求代理为其随机生成一个名称。队列名称是最多可以有 255 个字节的 UTF-8 字符。
要使用随机生成功能,需传递一个空字符串作为队列名称参数,生成的名称将与队列声明响应一起返回给客户机。同一通道中的后续方法,在需要队列名称的地方使用空字符串,可以获得相同的生成名称,因为通道会记住最后一个服务器生成的队列名。
以 “amq.” 开头的队列名称保留给代理内部使用,若用违反此规则的名称声明队列,将导致代码为 403(ACCESS_REFUSED)的通道级异常。
如果需要优先级队列,建议使用1到10,使用更多优先级会消耗更多资源(Erlang进程)。
RabbitMQ 中,队列可以设定为持久(Durable)、瞬态(transient)。
6-1. 持久队列
持久队列被持久化到磁盘,从而在 Broker 重启时存活下来。
Producer:
channel.basicPublish("", "task_queue", MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes());
Consumer:
boolean durable = true;
channel.queueDeclare("task_queue", durable, false, false, null);
队列的持久性不会使路由到该队列的消息持久。如果代理被关闭,然后恢复,持久队列将在代理重启期间重新声明,但这期间的消息,只有被持久化的会恢复。
关于消息持久性:
简单地将消息发布到持久性交换器或路由到持久性队列,并不能使消息持久化,消息持久性取决于消息本身的属性。
另外,将消息标记为持久并不能完全保证不会丢失消息。接受消息和将其保存,这之间仍然有一段很短的时间差。 另外,RabbitMQ 不会对每条消息都执行 fsync(2),它可能只是保存到缓存中,而没有真正写入磁盘。 持久性保证并不强,但是对于我们的简单任务队列而言已经绰绰有余了。 如果需要更强有力的保证,可以使用发布者确认机制。
消息被表示为持久化的,但是它还必须被发布到持久化的交换器中并到达持久化的队列中才行。如果不是这样的话,则包含持久化消息的队列(或者交换器)会在Rabbit 崩溃重启后不复存在,导致消息成为孤儿。
6-2. 临时队列
对于某些工作负载,队列应该是短暂(transient)的。尽管客户端可以在断开连接之前删除声明的队列,但这并不总是很方便。最重要的是,客户端连接可能会失败,从而可能留下未使用的资源(队列)。
通过声明队列时的参数设置:
channel.queueDeclare(queueName, isDurable, isExclusive, isAutoDelete, args);
6-2-1. Exclusive
独占队列只能通过其声明的连接来操作(从声明连接中使用、清除、删除等)。尝试使用来自不同连接的独占队列,将导致 RESOURCE_LOCKED 通道级异常,表示无法获得对锁定队列的独占访问权。通常,以服务器名称命名独占队列。
6-2-2. Time-To-Live
首先明确,队列和消息都可以设置 TTL,当同时指定队列和消息 TTL 时,将选择两者之间较小的值。
6-2-2-1. 消息 TTL
TTL 参数或策略的值必须是一个非负整数(0 <= n),以毫秒为单位描述 TTL 周期。
服务器将尝试在消息到期时或到期后不久删除消息。
// 使用策略设置所有队列中的消息TTL。
rabbitmqctl set_policy TTL ".*" '{"message-ttl":60000}' --apply-to queues
// 设置指定队列中所有消息的 TTL
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-message-ttl", 60000);
channel.queueDeclare("myqueue", false, false, false, args);
// 通过在 basic.publish 时设置 expiration 字段,可以为每条消息指定 TTL,仅接受数字的字符串表示。
String message = "Hello, world!";
AMQP.BasicProperties properties = new AMQP.BasicProperties.Builder().expiration("60000").build();
channel.basicPublish("my-exchange", "routing-key", properties, message.getBytes());
存在时间超过配置的 TTL 的消息被认为已死。注意,路由到多个队列的消息,在其所在的每个队列中可能在不同的时间死亡,或者根本不会死亡。一个队列中消息的死亡不会影响其他队列中同一消息的寿命。
如果消息被重新入队,它的原始到期时间将被保留。(比如使用了具有重新排队参数的AMQP方法,或者通道关闭。)
将 TTL 设置为 0 会导致消息在到达队列时过期,除非可以立即将其传递给使用者。因此,这为 RabbitMQ 服务器不支持的即时发布标志提供了一种替代方法,但与该标志不同,不会发出basic.return,并且如果设置了死信交换器,则消息将是死信。
在默认情况,如果消息在投递到交换机时,交换机发现此消息没有匹配的队列,则这个消息将被悄悄丢弃。为了解决这个问题,RabbitMQ 中有一种特殊交换机叫死信交换机。当消费者不能处理接收到的消息时,通过 Dead Letter Exchange 将这个消息发到死信队列中,等待重试或者人工干预。
6-2-2-2. 队列 TTL
队列只有在不使用时(例如没有消费者),才会在一段时间后过期。此功能可以与自动删除队列属性一起使用。服务器保证未使用的队列在过期后被删除,但不保证如何被迅速删除。当服务器重新启动时,持久队列的租约将重新签订。
通过设置过期策略,或者给 queue.declare 设置 x-expires 参数,来为指定队列设置过期时间。这控制了队列在自动删除之前可以闲置多长时间。闲置意味着该队列没有消费者、队列最近没有被重新声明租约、在到期时间前未调用 basic.get。
x-expires 参数或 expires 策略的值以毫秒为单位描述过期时间,它必须是一个正整数(不像消息 TTL,它不能是0)。
// 设置队列的TTL
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-expires", 1800000);
channel.queueDeclare("myqueue", false, false, false, args);
注意,队列过期不会使其中的消息变成死信。
可以将消息 TTL 策略追溯性地应用到已经包含消息的队列中,但这涉及到一些注意事项:
- 当过期的消息到达队列的头部时,它们才会被真正丢弃(或者成为死信)。消费者不会收到过期的信息,但在消息过期和消费者交付之间可能存在自然的竞态条件,例如,消息可能在写入套接字之后但到达消费者之前过期。
- 设置每条消息的 TTL 时,过期消息可以在未过期消息后面排队,直到未过期的消息被使用或过期。故这些过期消息将占用资源,并被计入队列统计(例如,队列中的消息数量)。
- 当追溯性地应用每条消息的 TTL 策略时,建议让消费者在线,以确保消息被更快地丢弃。
- 当需要删除消息以释放资源时,应改为使用队列 TTL(或清除队列,或删除队列)。
6-2-3. Auto-delete
当最后一个使用者被取消(例如在 AMQP 0-9-1 中使用 basic.cancel)或消失(通道或连接关闭,或者与服务器的 TCP 连接丢失)时,将被删除。
如果一个队列从来没有任何消费者,比如当所有的消费都使用 basic.get (“pull” API)时,它不会被自动删除。对于这种情况,请使用独占队列或设置队列 TTL 。
// 当不向 queueDeclare() 方法提供任何参数时,将创建一个非持久的、排他的、自动删除的队列,返回的队列名称是随机的,🌰:amq.gen-JzTY20BRgKO-HjmUJj0wLg。
String queueName = channel.queueDeclare().getQueue();
07. 交换器
交换器是发送消息的 AMQP 0-9-1 实体。 交换器接收一条消息并将其路由到零个或多个队列中。 使用的路由算法取决于交换类型和称为绑定的规则。
交换器本质上可以看作是一张查询表,里面包括了交换器名称和队列的绑定关系,当消息被发布到交换器中,实际上是所在信道将消息的路由键与交换器的绑定关系列表进行匹配,然后将消息路由出去。
AMQP 0-9-1 代理提供四种交换类型:
| Exchange Type | Default pre-declared names |
|---|---|
| Direct exchange | (Empty string) and amq.direct |
| Fanout exchange | amq.fanout |
| Topic exchange | amq.topic |
| Headers exchange | amq.match (and amq.headers in RabbitMQ) |
此外交换器还有其他属性可供声明:
- Name。
- Durability,持久性(交换器在 Broker 重新启动后仍然存在)。
- Auto-delete,当最后一个队列与其解除绑定时,交换器将被删除。
- Arguments,可选的、由插件和特定 Broker 的特性所使用。
RabbitMQ 中有四种 Exchange 类型:direct(默认)、fanout、topic、headers。

https://upload-images.jianshu.io/upload_images/15423847-0c9b03fc31e8ac5a.jpg-itluobo
7-1. direct
路由到 Binding Key 与消息的 Routing Key 完全匹配的 Queue 中。
默认交换器是 Broker 预先声明的、不带名称(空字符串)的 direct Exchange。 它具有一个特殊的属性,使其对于简单的应用程序非常有用:每个创建的 Queue 都使用与队列名称相同的 Routing Key 自动绑定到该队列。换句话说,看起来是直接向队列传递消息,尽管从技术上来说并不是这样。
Producer:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(config.QueueName, false, false, false, null);
String message = String.format("当前时间:%s", new Date().getTime());
// 消息发布
channel.basicPublish("", config.QueueName, null, message.getBytes("UTF-8")); // ""表示使用默认交换器
声明队列是幂等的,我们可以多次创建该队列,而且最终只会创建一个。
Consumer,获取单条消息:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明队列
channel.queueDeclare(config.QueueName, false, false, false, null);
GetResponse resp = channel.basicGet(config.QueueName, false); //单条
String message = new String(resp.getBody(), "UTF-8"); // 消息正文
// 手动确认消息
channel.basicAck(resp.getEnvelope().getDeliveryTag(), false);
我们 C 端也声明了队列,因为我们可能会在 P 端之前启动 C 端,所以我们希望在消费消息之前确保队列存在。
Consumer,获取持续消息:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(config.QueueName, false, false, false, null);
Consumer defaultConsumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "utf-8");
System.out.println("收到消息 => " + message);
channel.basicAck(envelope.getDeliveryTag(), false);
}
};
channel.basicConsume(config.QueueName, false, "", defaultConsumer); //持续
公平调度
如果一个队列有多个消费者进行订阅,direct 交换器采用轮询的方式将消息发送给某个消费者(消费者消息确认正常),每条消息只发送给一个消费者。
所以要理解:在 AMQP 0-9-1 中,消息是在消费者之间负载均衡的,而不是在队列之间负载均衡的。
发后既忘:是指接收者不知道消息的来源,如果想要知道消息的发送者,需要包含在发送内容里面,这点就像我们在信件里面注明自己的姓名一样。
使用相同的 Binding Key 绑定多个 Queue 是完全合法的。在这种情况下,direct 将像 fanout 一样工作,把消息广播到所有匹配的 Queue 中。
7-2. fanout
扇出,扇形展开。发布订阅模式,把发送到 Exchange 的消息,路由到所有与它绑定的 Queue 中,可理解为广播。
Producer:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
String message = "当前时间:" + new Date().getTime();
// 交换器名称
String exchangeName = "fanoutec";
// 声明fanout交换器
channel.exchangeDeclare(exchangeName, "fanout");
// 发布消息(不需指定 RoutingKey)
channel.basicPublish(exchangeName, "", null, message.getBytes("UTF-8"));
Consumer:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
String exchangeName = "fanoutec";
// 声明fanout交换器
channel.exchangeDeclare(exchangeName, "fanout");
// 生成随机队列名称,一旦消费者断开连接,该队列会被自动删除
String queueName = channel.queueDeclare().getQueue();
// 将队列和交换器绑定(不需指定 BindingKey)
channel.queueBind(queueName, exchangeName, "");
// 创建消费者
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
}
};
// 持续消费
channel.basicConsume(queueName, true, consumer);
对于 fanout 交换器来说 Binding Key 是无效的,这个参数是被忽略的。
7-3. topic
匹配订阅模式。使用特定 Routing Key 发送的消息将被传递到所有 Binding Key 匹配的 Queue 中。
RabbitMQ 限制 Routing Key 的长度为 255 字节,用 ‘.’ 作为分隔符进行分段。(Binding Key 也是相同的格式。)
-
通配符 ‘*’ 用于匹配任何单个分段。
-
通配符 ‘#’ 用于匹配任何零个或多个分段。
如果想要订阅所有消息,就使用 “#” 进行匹配,此时相当于 fanout 类型。
如果不使用任何通配符,相当于 direct 类型。
例如发布了一个路由键为 “com.mq.rabbit.error” 的消息。
能匹配上的绑定键:
- cn.mq.rabbit.*
- cn.mq.rabbit.#
- #.error
- cn.mq.#
- #
不能匹配上的绑定键:
- cn.mq.*
- *.error
Producer:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
String message = "当前时间:" + new Date().getTime();
String routingKey = "com.mq.rabbit.error";
// 声明topic交换器
channel.exchangeDeclare(exchangeName, "topic");
channel.basicPublish(exchangeName, routingKey, null, message.getBytes("UTF-8"));
Consumer:
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
// 声明topic交换器
channel.exchangeDeclare(ExchangeName, "topic");
// 绑定队列
String queueName = channel.queueDeclare().getQueue();
String routingKey = "#.error";
channel.queueBind(queueName, exchangeName, routingKey);
Consumer consumer = new DefaultConsumer(channel) {
@Override
public void handleDelivery(String consumerTag, Envelope envelope, AMQP.BasicProperties properties, byte[] body) throws IOException {
String message = new String(body, "UTF-8");
System.out.println(routingKey + "|接收消息 => " + message);
}
};
channel.basicConsume(queueName, true, consumer);
fanout、topic交换器是没有历史数据的,也就是说对于中途创建的队列,获取不到之前的消息。
7-4. headers
匹配消息的 Header 属性而非 Routing Key,除此之外 headers 交换器和 direct 交换器完全一致,性能差,一般不使用。
根据参数 x-match,可以使用多个 Header 进行匹配:
-
当 x-match 为 any 时,Header 的任意一个值被匹配就可以满足条件。
-
当 x-match 为 all 时,需要 Header 的所有值都匹配成功。
以字符串 “x-” 开头的 Header 将不用于评估匹配项。
7-5. DLX
死信交换器(Dead Letter Exchange),是一个普通的交换器,可被声明为 4 种类型中的任意一种。
当出现以下情况时,消息变为死信:
- 消息被消费者用
basic.reject、basic.nack方法否定确认,且 requeue 参数为 false。 - 设置了 TTL 的消息过期了。
- 超过了队列长度限制时,被丢弃的消息。
对于任何给定的队列,客户端可以使用队列的参数定义 DLX,也可以使用策略在服务器中定义 DLX。 在策略和参数都指定 DLX 的情况下,参数中指定的将覆盖策略中指定的。
建议使用策略进行配置,因为它允许不涉及应用程序重新部署的 DLX 进行重新配置。类似地,可以通过向策略添加关键字 “dead-letter-routing-key” 来指定显式的路由键。
rabbitmqctl set_policy DLX ".*" '{"dead-letter-exchange":"my-dlx"}' --apply-to queues
在声明队列时,使用可选参数 x-dead-letter-exchange 来为队列设置死信交换器。
channel.exchangeDeclare("some.exchange.name", "direct");
Map<String, Object> args = new HashMap<String, Object>();
args.put("x-dead-letter-exchange", "some.exchange.name");
channel.queueDeclare("myqueue", false, false, false, args);
注意,在声明队列时不必声明死信交换器,但在需要对消息进行死信处理时,交换器应该已存在,否则消息将被静默丢弃。
还可以指定消息在变为死信时使用的路由键,如果未设置,则将使用消息自己的路由键。
「当指定了死信交换器时,除了对声明队列的通常配置权限之外,用户需要对该队列具有读权限,对死信交换器具有写权限。权限在队列声明时验证。」
args.put("x-dead-letter-routing-key", "some-routing-key");
🌰:将消息发布到路由键为 “foo” 的交换器中,并且该消息被标为死信,则它将被发布到路由键为 “foo” 的死信交换器中。 如果已将消息最初到达队列的 x-dead-letter-routing-key 参数设置为 “bar”,则该消息将通过路由键 “bar” 发布到其死信交换器中。
在打开发布者确认功能的情况下,死信会被重新发布,因此,消息最终到达的死信队列,必须在消息从原始队列删除前进行确认。换句话说,“发布”(消息过期的那个)队列不会在死信队列确认接收消息之前删除消息。请注意,在 Broker 未干净地关闭的情况下,消息可能会在原始队列和死信队列上重复。
当一个队列将未指定死信路由键的死信,发送到默认的死信交换器时,可能会形成一个死信循环。如果在整个循环中没有否定确认,则处于这种循环中的消息(即两次到达同一队列的死信)将被丢弃。
死信处理对消息的影响
当消息变为死信时,它的 Header 属性会被修改:
-
交换器名称被替换为最新的死信交换器的名称。
-
路由键被替换为执行死信操作的队列指定的路由键。
-
CC、BCCHeader 也将被移除。🔗 Sender-selected distribution
死信过程将一个名为 x-death 的数组添加到每个死信消息的 Header 上,该数组包含每个死信事件的条目,由一对 {queue,reason} 标识,每个 entry 都是一个包含以下字段的表:
| field | description |
|---|---|
| queue | 消息被死信处理之前所在的队列的名称 |
| reason | reason for dead lettering, see below |
| time | 消息变为死信的日期和时间,64 位 AMQP 0-9-1 时间戳 |
| exchange | 消息曾经被发布到的交换器(注意,如果消息重复变为死信,那么这将是一个死信交换器) |
| routing-keys | 消息曾经发布时使用的路由键(包括CC键,但不包括BCC键) |
| count | 由于这个原因,此消息在此队列中被死信处理的次数 |
| original-expiration | 如果消息因 TTL 过期变为死信,将 expiration 属性从死信消息中移除,以防止它在被路由到的任何队列中再次过期。 |
新的 entry 将放置到 x-death 数组的头部, 如果数组中已包含了具有相同的队列和死信原因的 entry,则其 count 字段将增加,并将该 entry 移至数组头部。注意,数组是按最近优先排序的。
其中,reason 字段包括以下内容之一:
| name | description |
|---|---|
| rejected | 消息被否定确认,且 requeue 参数为 false |
| expired | 消息的 TTL 过期 |
| maxlen | 超过了队列的长度限制 |
另外,当消息第一次变成死信时,还会被添加 3 个 top-level 的 Header:x-first-death-reason、x-first-death-queue、x-first-death-exchange。它们与原始死信事件的 reason、queue和 exchange 字段具有相同的值,一旦添加,这些 Header 永远不会被修改。
08. 消息确认机制
网络是不可靠的,消费者可能无法处理消息,因此 AMQP 0-9-1 模型有消息确认的概念:当消息传递给消费者时,消费者向代理进行确认,代理仅在接收到该消息(或消息组)的通知时才会从队列中完全删除消息。
在某些情况下,比如当无法路由消息时,消息可能会返回给发布者、被丢弃、(如果代理实现了扩展)会将消息放入“死信队列”中。 发布者通过使用某些参数来选择如何处理这种情况。
消息状态:
- Ready:等待消费状态。
- Unacked:等待被确认状态,当前消息已经被发送到了客户端。当客户端端断开后,如果这条消息没有被确认,这条消息重新进入 Ready 状态。
- Ack:已被确认状态。
8-1. 确认模式
-
手动确认模式:在收到显式的客户端确认时成功传递。手动发送的确认可以是肯定的或否定的,并使用以下协议方法之一:
- basic.ack 用于肯定确认。
- basic.nack 用于否定确认(注意,这是 RabbitMQ 对 AMQP 0-9-1 的扩展)。
- basic.reject 用于否定确认,但与 basic.nack 相比有一个限制。
basic.ack 指示 RabbitMQ 将消息记录为已发送,可以丢弃。basic.reject 与其的区别主要在语义上,肯定的确认表示消息已成功处理,而否定的确认表示消息未被处理,但仍应删除。
-
自动确认模式:消息在发送出去(写入TCP套接字)后立即变为成功传递。
消息被视为在发送后立即成功传递,即发即弃。此模式降低了交付和消费者处理的安全性,以获得较高的吞吐量(只要消费者可以跟上)。如果在成功处理之前关闭使用者的 TCP 连接或通道,服务器发送的消息将丢失。因此,自动模式被认为是不安全的,并且不适合所有工作负载。
使用自动模式时要考虑的另一件事是消费者过载。手动模式通常与有界通道预取值一起使用,该预取值限制了通道上未完成(进行中)交付的数量。但自动确认从定义上讲,没有这种限制。因此,消费者可能会被交付的速度搞得不知所措,导致内存溢出,或导致它们的进程被操作系统终止。某些客户端将施加TCP反压(停止从套接字读取,直到未处理的消息积压量下降到某个限度)。因此,仅建议自动确认模式用于可以高效、稳定地处理消息的消费者。
示例:🔗 rabbitmq自动及手动ACK
8-2. Channel Prefetch
See 🔗 Consumer Prefetch for details.
QoS(Quality of Service,服务质量):指一个网络能够利用各种基础技术,为指定的网络通信提供更好的服务能力,是网络的一种安全机制,是用来解决网络延迟和阻塞等问题的一种技术。
因为消息是异步发送(推送)给客户端的,所以在任何时刻,在一个信道上通常有不止一条消息在传输中,此外,客户端的手动确认本质上也是异步的。所以有一个未确认的消息交付的滑动窗口。开发人员通常倾向于限制这个窗口的大小,以避免消费者端的缓冲区问题。这是通过使用 basic.qos 方法设置预取计数值(PrefetchCount)来实现的。该值定义了通道上允许的未确认交货的最大数量。一旦数量达到配置的计数值,除非至少有一个未完成的消息被确认,否则 RabbitMQ 将停止在信道上传递更多的消息。
例如,假设在通道 Ch 上有未确认的交付标签 5、6、7、8,并且通道 Ch 的预取计数设置为 4,RabbitMQ 将不会在 Ch 上推送任何更多的交付,除非至少有一个未确认的交付被确认。当确认帧到达该通道并将传递标记设置为 5(或6、7、8)时,RabbitMQ 将注意到并传递另一条消息。一次确认多个消息将使多个消息可用于传递。
值得重申的是,交付流程和手动客户端确认是完全异步的。因此,如果预取值在已经有消息传递在进行的情况下发生变化,就会出现自然竞争情况,在一个通道上可能会暂时有超过预取计数的未确认消息。
预取值设置对使用 basic.get 方法(Pull API)获取的消息没有影响。
确认模式和 QoS 预取值对消费者的吞吐量有显著影响。一般来说,增加预取值会提高向消费者传递消息的速度,自动确认模式可产生最佳的传送速度。但是,在这两种情况下,已发送但尚未处理的消息数量也会增加,从而增加了消费者的内存消耗。
应谨慎使用具有无限预取功能的自动确认模式或手动确认模式。消费大量消息而未确认的消费者将导致他们所连接的节点上的内存消耗增加。需要通过反复试验找到合适的预取值,并且会因工作负载而异。100到300范围内的值通常可提供最佳吞吐量,并且不会有压倒消费者的重大风险。
更好地公平分发(Fair dispatch)
你可能已经注意到,即使是轮询,消息分发仍然不完全像我们想要的那样公平。例如,在有两个工人的情况下,当所有的奇数消息都很重(需要较长处理时间)而偶数消息很轻时,一个工人会一直很忙,而另一个工人很闲。RabbitMQ 对此一无所知,仍然会平均地给两个工人发送消息。
这是因为 RabbitMQ 在消息进入队列时才调度消息。它不会查看消费者的未确认消息数。它只是盲目地将第 n 条消息发送给第 n 个使用者。
解决方案:可以将 prefetchCount 设置为 1。告诉 RabbitMQ 一次不要给工人发送一条以上的消息。 换句话说,在处理并确认上一条消息之前,不要将新的消息发送给该工人,而是分派给尚不忙碌的下一个工人。需要注意的是,如果所有工人都很忙,一直无法接收下一条消息,队列可能就满了。需要增加更多的工人,或者有一些其他的策略。
int prefetchCount = 1;
channel.basicQos(prefetchCount);
8-3. 肯定确认
两种方式:
-
在订阅队列时将 auto_ack 参数设置为 true。
需要注意的是,如果设置了 auto_ack 为 true,那么一旦消费者接收到了消息,RabbitMQ 就认为确认了消息,从而将消息从队列中删除。但是消费者接收到消息并不等同于成功处理了消息,如果在成功处理该条消息之前出现问题或者程序崩溃,由于此时 RabbitMQ 已经将消息从队列中删除了,那么就意味着这条消息丢失了。 -
Java 使用
Channel#basicAck(deliveryTag, multiple)方法执行 basic.ack 方法。
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(config.QueueName, false, false, false, null);
GetResponse resp = channel.basicGet(config.QueueName, false);
String message = new String(resp.getBody(), "UTF-8");
channel.basicAck(resp.getEnvelope().getDeliveryTag(), false);
可以分批手动确认以减少网络流量,这是通过将确认方法的 multiple 字段设置为true来完成的。
当 multiple 字段设置为 true 时,RabbitMQ 将确认所有未完成的交付标签,直到并包括确认中指定的标签。像其他所有与确认有关的内容一样,这也是按 Channel 划分的。 例如,假设在通道 Ch 上有未确认的交付标签 5、6、7、8,当某个 delivery_tag 设置为 8、multiple 字段设置为 true 的确认帧到达该通道时,则将确认从 5 到 8 的所有标签。如果将 multiple 设置为 false,则只确认 8 而无法确认 5、6、7。
未接收到确认时,消息在队列的状态为 Unacked,确认后再转为 Ack 状态。如图:

没有任何消息超时,即使处理一条消息需要非常非常长的时间,也没关系。
可以利用这一点,让程序延迟确认该消息,直到程序处理完相应的业务逻辑,这样可以有效的防止因接收过多的消息导致程序崩溃。
Ack 必须在接收消息的同一个 Channel 上进行发送,因为交付标签的作用域是每个通道,在不同的通道上确认将导致 “unknown delivery tag” 协议异常并关闭通道。
另外,如果消费者多次确认同一交付标签,或者使用未知交付标签,RabbitMQ 也将抛出通道错误,例如 PRECONDITION_FAILED - unknown delivery tag 100。
交付标签的长度为 64 位,因此最大值为 9223372036854754775807。由于交付标签是按通道划分的范围,因此实际上生产者或消费者不太可能会超过该值。
8-4. 否定确认
Java 分别使用 Channel#basicReject(deliveryTag, requeue) 方法和 Channel#basicNack(deliveryTag, requeue, multiple) 方法执行 basic.reject 方法和 basic.nack 方法。
注意,basic.reject 历来没有 multiple 字段用于分批确认,这就是 RabbitMQ 引入 basic.nack 作为协议扩展的原因,使用 basic.nack 方法可以一次拒绝或重新入队多个消息。
Connection connection = factory.newConnection();
Channel channel = connection.createChannel();
channel.queueDeclare(config.QueueName, false, false, false, null);
GetResponse resp = channel.basicGet(config.QueueName, false);
String message = new String(resp.getBody(), "UTF-8");
channel.basicReject(resp.getEnvelope().getDeliveryTag(), true);
否定确认表示消息可以被 Broker 丢弃或重新放入队列,这种行为由 requeue 字段控制:
- true, RabbitMQ 将使用指定的交付标签重新交付(或多次交付)。
- false,RabbitMQ 会把消息发送到“死信”队列,用来存放被拒绝而不重新放入队列的消息。
当消息重新入队时,它将尽可能地被放置在其队列中的原始位置。否则(由于当多个消费者共享一个队列时来自其他消费者的并发消费和确认),消息将被放置到更靠近队列头的位置。
根据消息在队列中的位置,以及活跃消费者的通道所使用的预取值,重新入队的消息可以立即准备好被发送。这意味着,如果所有的消费者都因为无法处理交付而使消息重新入队,将创建一个重新交付循环,就网络带宽和 CPU 资源而言,这样的循环可能代价很高。所以消费者实现最好跟踪重新交付的次数并永久拒绝消息(丢弃消息),或延迟安排重新入队。
8-5. 自动重排
使用手动确认模式时,如果 Consumer 在未发送 ack 的情况下断开了连接(Channel close, Connection close, TCP connection lost, or Channel-Level Protocol Exception),RabbitMQ 就认为消息未完全处理,会将其重新放入 Queue,如果同时有其他 Consumer 在线,它将很快将消息重新分发给另一位 Consumer,确保不会丢失任何消息。
注意,检测客户端不可用需要一定的时间。 🔗 detect an unavailable client
消费者必须准备好处理重新交付,另外在实现时要考虑到幂等性。重新交付的消息将有一个特殊的布尔属性 redeliver,RabbitMQ 将其设置为 true,对于第一次交付,它将被设置为 false。
09. 发布者确认
网络可能出现故障,且检测一些故障需要时间。因此,向套接字写入协议帧或一组帧的客户端不能假定消息已到达服务器并已成功处理。它可能在途中丢失,或者它的交付可能会大大延迟。
为了解决这个问题,引入了发布者确认机制,它模仿了协议中已经存在的消费者确认机制。
发布者确认是 RabbitMQ 对 AMQP 0-9-1 协议的扩展,用于实现可靠的发布。当发布服务器确认在通道上启用时,代理将异步确认客户端发布的消息,这意味着它们在服务器端得到了处理。默认情况下关闭。在通道级别使用 channel#confirmSelect() 方法启用。
分为三种策略:
-
策略一,Publish-and-Wait:单条发布,并同步等待其确认后再继续发布。不建议使用,会对发布者的吞吐量产生严重的负面影响(不超过每秒数百条)。
while (thereAreMessagesToPublish()) { byte[] body = ...; BasicProperties properties = ...; channel.basicPublish(exchange, queue, properties, body); channel.waitForConfirmsOrDie(5_000); }在开头提到代理异步确认发布的消息,但是在这里,代码同步等待,直到消息被确认。客户端实际上异步接收确认并相应地解除 waitForConfirmsOrDie 调用时的阻塞。可以将waitForConfirmsOrDie 看作一个同步助手,它依赖于底层的异步通知。
-
策略二,Batch Publishing:批量发布,并等待整个批处理被确认,重试按批次执行。
- 在 Channel 上启用发布者确认。
- 对于每个已发布的消息批次,等待所有未完成的确认。
- 当所有的确认都是肯定时,发布下一批。
- 如果确认是否定或超时,重新发布整个批次,或仅重新发布相关消息。
Java 中,Channel#waitForConfirms(long) 方法等待所有未完成的确认。
由于涉及同步等待确认,会对发布者的吞吐量产生负面影响,批量越大,影响越小。
「策略一可认为是 size 为 1 的批量发布。」
int batchSize = 100; int outstandingMessageCount = 0; while (thereAreMessagesToPublish()) { byte[] body = ...; BasicProperties properties = ...; channel.basicPublish(exchange, queue, properties, body); outstandingMessageCount++; if (outstandingMessageCount == batchSize) { ch.waitForConfirmsOrDie(5_000); outstandingMessageCount = 0; } } if (outstandingMessageCount > 0) { ch.waitForConfirmsOrDie(5_000); }该策略还有一个缺点是,不容易知道哪些消息无法发送给代理,所以可能需要在内存中保留一整批消息来记录或者重新发布消息。
-
策略三,Asynchronously Confirms:单条发布,并异步确认。(异步API元素:confirm event handlers, futures/promises等)
代理异步地确认发布的消息,只需在客户端上注册一个回调函数,就会收到确认消息的通知。
Channel channel = connection.createChannel(); channel.confirmSelect(); channel.addConfirmListener((sequenceNumber, multiple) -> { // code when message is confirmed }, (sequenceNumber, multiple) -> { // code when message is nack-ed }); // sequenceNumber:标识已确认或未确认消息的序列号。 // multiple:如果为false,则仅确认/拒绝一条消息;如果为true,则确认/拒绝所有小于等于该序列号的消息。序列号可以在发布之前通过 channel#getNextPublishSeqNo() 方法获取。
最简单的处理手法:
-
在 Channel 上启用发布者确认。
-
对于每个发布的消息,添加一个 map entry,将当前序列号映射到消息。
-
当肯定确认到达时,删除 entry。
-
当否定确认到达时,删除 entry 并安排它对应的消息重新发布(或者其他合适的操作)。
Channel channel = connection.createChannel(); channel.confirmSelect(); ConcurrentNavigableMap<Long, String> outstandingConfirms = new ConcurrentSkipListMap<>(); // 定义回调方法 ConfirmCallback cleanOutstandingConfirms = (sequenceNumber, multiple) -> { if (multiple) { ConcurrentNavigableMap<Long, String> confirmed = outstandingConfirms.headMap(sequenceNumber, true); confirmed.clear(); //拒绝所有 } else { outstandingConfirms.remove(sequenceNumber); //拒绝一条 } }; // 注册回调监听 channel.addConfirmListener(cleanOutstandingConfirms, (sequenceNumber, multiple) -> { String body = outstandingConfirms.get(sequenceNumber); System.err.format("Message with body %s has been nack-ed. Sequence number: %d, multiple: %b%n", body, sequenceNumber, multiple); cleanOutstandingConfirms.handle(sequenceNumber, multiple); }); // ... publishing code从相应的回调中重新发布一个否定确认的消息可能很诱人,但是应该避免这种情况,因为确认回调是在 Channel 不应进行操作的I / O线程中调度的。更好的解决方案是将消息放入由发布线程轮询的内存队列中。诸如 ConcurrentLinkedQueue 的类是在确认回调和发布线程之间传输消息的理想选择。
异步确认策略的实现更复杂,但当发布的消息被拒绝时,提供了更好的粒度、更好地控制发布消息时执行的操作。
-
10. 特点
- 可靠性(Reliability)
RabbitMQ 使用一些机制来保证可靠性,如持久化、传输确认、发布确认。 - 灵活的路由(Flexible Routing)
在消息进入队列之前,通过 Exchange 来路由消息的。对于典型的路由功能,RabbitMQ 已经提供了一些内置的 Exchange 来实现。针对更复杂的路由功能,可以将多个 Exchange 绑定在一起,也通过插件机制实现自己的 Exchange 。 - 消息集群(Clustering)
多个 RabbitMQ 服务器可以组成一个集群,形成一个逻辑 Broker 。 - 高可用(Highly Available Queues)
队列可以在集群中的机器上进行镜像,使得在部分节点出问题的情况下队列仍然可用。 - 多种协议(Multi-protocol)
RabbitMQ 支持多种消息队列协议,比如 STOMP、MQTT 等等。 - 多语言客户端(Many Clients)
RabbitMQ 几乎支持所有常用语言,比如 Java、.NET、Ruby 等等。 - 管理界面(Management UI)
RabbitMQ 提供了一个易用的用户界面,使得用户可以监控和管理消息 Broker 的许多方面。 - 跟踪机制(Tracing)
如果消息异常,RabbitMQ 提供了消息跟踪机制,使用者可以找出发生了什么。 - 插件机制(Plugin System)
RabbitMQ 提供了许多插件,来从多方面进行扩展,也可以编写自己的插件。
11. 持久化
11-1. 进程结构

事件驱动模型(或者说反应堆模型),这是一种高性能的非阻塞io线程模型,在Erlang中称为进程模型。
cp_acceptor:负责接受客户端连接,然后为客户端连接创建 rabbit_reader、rabbit_writer、rabbit_channel 进程。rabbit_reader:负责解析客户端 AMQP 帧,然后将请求发送给 rabbit_channel 进程。rabbit_writer:负责向客户端返回数据。rabbit_channel:负责解析 AMQP 方法,以及对消息进行路由,然后发送给对应的队列进程。rabbit_amqqueue_process:rabbit 队列进程,该进程一般在 rabbitmq 启动(恢复 durable 类型队列)或创建队列时被创建,其主要负责消息的接收、投递逻辑。rabbit_msg_store:存储服务进程,主要负责消息的持久化。
- tcp_acceptor 和 rabbit_msg_store 只会有一个。
- rabbit_amqqueue_process 进程的数量和队列数量保持一致。
- 每个客户端连接对应一个 rabbit_reader 和 rabbit_writer 进程。
- 每一个连接的通道对应一个 rabbit_channel 进程。
通常来说,客户端发起一个 connection 的同时,可以打开多条 channel,相对 connection 的 open/close 来说,对 channel 进行 open/close 的操作开销会更小。
最佳实践是一个生产者/消费者进程对应一个 connection,具体发送时,一个线程对应一个 channel。
11-2. 队列内部结构
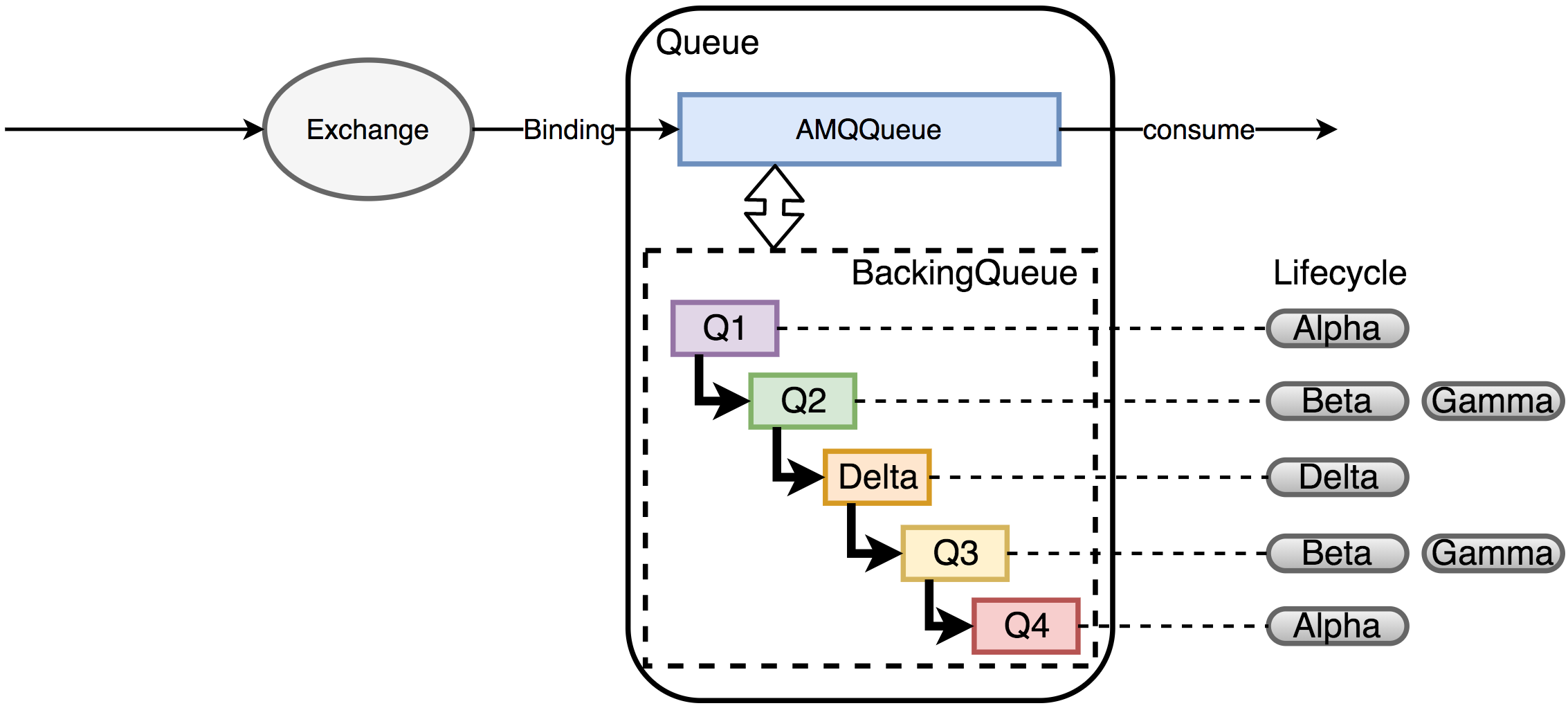
在 RabbitMQ 中,MessageQueue 主要由两部分组成:
AMQPQueue:实现 AMQP 协议的逻辑功能,包括接收消息,投递消息,confirm 消息等;BackingQueue:提供 AMQQueue 调用的接口,完成消息的持久化工作。
队列的存储状态。BackingQueue 由 Q1、Q2、Delta、Q3、Q4 五个子队列构成,在 BackingQueue 中,消息的生命周期有 4 个状态:
alpha: 消息的内容和消息索引都在 RAM 中。(Q1,Q4)beta: 消息的内容保存在 DISK 上,消息索引保存在 RAM 中。(Q2,Q3)gamma: 消息的内容保存在 DISK 上,消息索引在 DISK 和 RAM 上都有。(Q2,Q3)delta: 消息内容和索引都在 DISK 上。(Delta)
| queue | state\store | message itself | message index(message position) |
|---|---|---|---|
| Q1,Q4 | alpha | RAM | RAM |
| Q2,Q3 | beta | DISK | RAM |
| Q2,Q3 | gamma | DISK | RAM&DISK |
| Delta | delta | DISK | DISK |
Delta 队列是消息按序存盘后的一种逻辑队列,只有 delta 状态的消息。所以 Delta 队列并不在内存中,其他 4 个队列则是由 erlang queue 模块实现。
这里以持久化消息为例(非持久化消息的生命周期会简单很多),从 Q1 到 Q4,消息实际经历了一个 RAM->DISK->RAM 的过程。
BackingQueue 的设计有点类似于 Linux 的虚拟内存 Swap 区:
-
当队列负载很高时,通过将部分消息放到磁盘上来节省内存空间。
-
当负载降低时,消息又从磁盘回到内存中,让整个队列有很好的弹性。因此触发消息流动的主要因素是:
- 消息被消费。
- 内存不足。
-
RabbitMQ 会根据消息的传输速度来计算当前内存中允许保存的最大消息数量(Traget_RAM_Count)。
-
当 内存中保存的消息数量 + 等待ACK的消息数量 > Target_RAM_Count 时,RabbitMQ 才会把消息写到磁盘上。
-
所以说虽然理论上消息会按照
Q1->Q2->Delta->Q3->Q4的顺序流动,但是并不是每条消息都会经历所有的子队列以及对应的生命周期。 -
从 RabbitMQ 的 BackingQueue 结构来看,当内存不足时,消息要经历多个生命周期,在 DISK 和 RAM 之间置换,这实际会降低 RabbitMQ 的处理性能(后续的流控就是关联的解决方法)。
-
对于持久化消息,RabbitMQ 先将消息的内容和索引保存在磁盘中,然后才处于上面的某种状态(即只可能处于 alpha、gamma、delta 三种状态之一)。
The term
gammaseldom appears. (gamma 状态很少出现。)
11-3. 流控
又称信用机制(Credit)。
当 RabbitMQ 内存(默认是0.4)或者磁盘资源达到阈值时,会触发流控机制:阻塞 Producer 的连接,让生产者不能继续发送消息,直到更多的内存或者磁盘资源得到释放。
Erlang 进程之间并不共享内存(binaries 类型除外),而是通过消息传递来通信,每个进程都有自己的进程邮箱。Erlang 默认没有对进程邮箱大小设限制,所以当有大量消息持续发往某个进程时,会导致该进程邮箱过大,最终内存溢出并崩溃。
在 RabbitMQ 中,生产者持续高速发送,而消费者消费速度较低时,如果没有流控,很快就会使内部进程邮箱大小达到内存阈值,阻塞生产者(得益于 block 机制,并不会崩溃)。然后 RabbitMQ 会进行 page 操作,将内存中的数据持久化到磁盘中。
因此,要保证各个进程占用的内容在一个合理的范围,RabbitMQ 的流控采用了一种信用机制(Credit),为每个进程维护了 4 类键值对:
-
{credit_from,From}:该值表示当前消息发送进程还能向消息接收进程 From 发送多少条消息。 -
{credit_to,To}:表示当前消息接收进程再接收多少条消息,就要向消息发送进程增加 credit 数量。 -
credit_blocked:表示当前消息发送进程被哪些进程 block 了。比如:进程 A 向进程 B 发送消息,当 A 的进程字典中 {credit_from,B} 的值为 0 时,进程 A 的 credit_blocked 值为 [B],表示 A 进程还能向 B 进程发送的消息数为 0,A 进程被 B 进程阻塞了。
-
credit_deferred:消息接收进程向消息发送进程增加 credit 的消息列表。当进程被 block 时会记录消息信息,unblock 后依次发送这些消息。
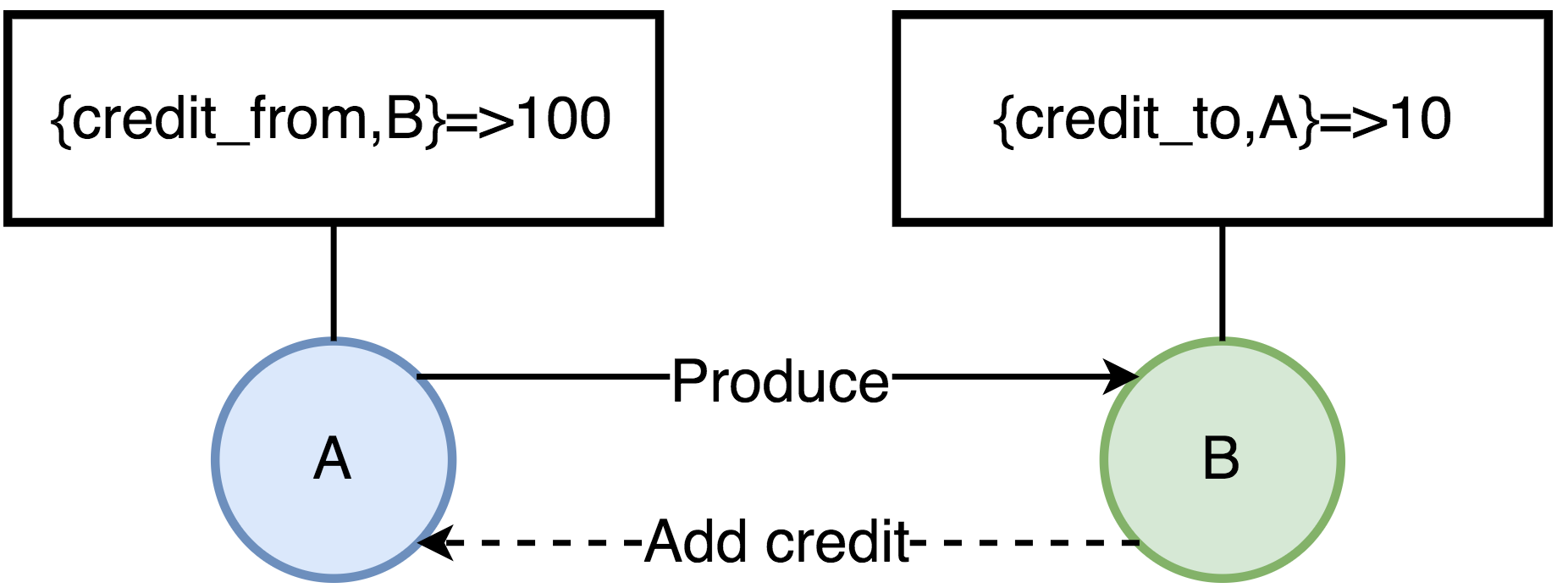
如图所示:
- A 进程当前可以发送给 B 进程的消息为 100 条,每发一次,值减 1,直到为 0,A 会被阻塞。
- B 进程消费消息后,会给 A 进程增加 credit,这样 A 进程才能持续发送消息。
这里只画了两个进程,多进程串联的情况下,这种影响也是从底向上传递的。
11-4. 消息存储
消息什么时候需要持久化?根据 官方博文 的介绍,RabbitMQ 在两种情况下会将消息写入磁盘:
- 消息本身在发布的时候就要求消息写入磁盘。
- 内存紧张,需要将部分内存中的消息转移到磁盘。
RabbitMQ 的消息持久化实际包括两部分:
- 队列索引进程(rabbit_queue_index)。负责维护队列中落盘消息的信息,包括消息的存储地点、是否已经被交付给消费者、是否已被消费者 ack 等,每个队列都有一个与之对应的 rabbit_queue_index。
- 消息存储进程(rabbit_msg_store)。以键值对的形式存储消息,每个节点有且只有一个,所有队列共享。rabbit_msg_store 又可以分为:
- msg_store_persistent 负责持久化消息的存储,不会丢失。
- msg_store_transient 负责非持久化消息的存储,重启后消息会丢失。
通过配置环境变量
RABBITMQ_MNESIA_BASE可以指定存储目录,一般配置 RABBITMQ_MNESIA_BASE=/srv/rabbitmq。
$ ls -hl /var/lib/rabbitmq/mnesia/rabbit65 | grep msg_store
drwxr-xr-x. 2 rabbitmq rabbitmq 21 Sep 9 21:26 msg_store_persistent
drwxr-xr-x 2 rabbitmq rabbitmq 19 Jul 19 21:25 msg_store_transient
其中 msg_store_transient 和 msg_store_persistent 就是实际的消息存储目录。
11-4-1. 消息存储进程
- RabbitMQ 通过配置 queue_index_embed_msgs_below 可以指定消息存储位置。
- 默认 queue_index_embed_msgs_below 是
4096字节(包含消息体、属性及 headers),小于该值的消息存在rabbit_queue_index中。
sudo ls -hl /var/lib/rabbitmq/mnesia/rabbit65/msg_store_persistent
-rw-r--r-- 1 rabbitmq rabbitmq 2.5M Sep 10 19:16 356.rdq
sudo ls -hl /var/lib/rabbitmq/mnesia/rabbit65/msg_store_transient
-rw-r--r-- 1 rabbitmq rabbitmq 0 Jul 19 21:25 0.rdq
- 经过 rabbit_msg_store 进程处理的消息都会以追加的方式写入到文件中,文件名从 0 开始累加,后缀是
.rdq。 - 当一个文件的大小超过指定的限制
file_size_limit后,一般是 16M(16777216),关闭这个文件再创建一个新的文件存储。
.rdq文件消息格式:<<Size:64, MsgId:16/binary, MsgBody>>。
- MsgId 为 RabbitMQ 通过 rabbit_guid:gen() 为每一个消息生成的 GUID。
- MsgBody 会包含消息对应的交换器、路由键、消息内容、消息协议版本、消息内容格式(二进制还是其它)等等。
- 消息存储时,RabbitMQ 会在
ETS(Erlang Term Storge)表中记录消息在文件中的位置映射和文件的相关信息。 - 消息读取时,先根据消息的 MsgId 找到对应的文件,如果文件存在且未被锁住则直接打开文件,如果文件不存在或者锁住了则发请求到
rabbit_msg_store进程处理。
11-4-2. 队列索引进程
查看索引信息:
ls -hl /var/lib/rabbitmq/mnesia/rabbit65/queues/9ETDQOQ2E4JS49H80ILRO1YHA
total 24K
-rw-r--r-- 1 rabbitmq rabbitmq 21K Aug 14 20:19 1.idx
-rw-r--r-- 1 rabbitmq rabbitmq 0 Aug 14 20:19 journal.jif
rabbit_queue_index进程顺序存储段文件,文件编号从 0 开始,后缀.idx。- 每个段文件包含固定
SEGMENT_ENTRY_COUNT条记录。 SEGMENT_ENTRY_COUNT默认是 16384,每个rabbit_queue_index进程从磁盘读取消息的时候至少读取一个段文件。
11-5. 消息读写过程

- rabbit_channel 进程确定了消息将要投递的目标队列。
- rabbit_amqqueue_process 是队列进程,每个队列对应一个,实际上 rabbit_amqqueue_process 进程只是提供了逻辑上对队列的相关操作,它真正的操作是通过指定的 backing_queue 模块提供的相关接口实现的。
- 默认情况该 backing_queue 的实现模块为 rabbit_variable_queue。
11-5-1. 消息发布
rabbit_amqqueue_process 进程对消息的主要处理逻辑位于 deliver_or_enqueue 方法,将消息直接传递给消费者,或者将消息存储到队列中。
整体处理逻辑如下:
-
首先处理消息的
mandory标志和confirm属性。- mandatory 标志告诉服务器至少将该消息路由到一个队列中,否则将消息返还给生产者。
- confirm 则是消息的发布确认。
-
然后判断队列中是否有消费者正在等待,如果有则直接调用 backing_queue 模块的接口给消费者发送消息。
-
如果队列上没有消费者,根据当前相关设置判断消息是否需要丢弃,不需要丢弃的情况下调用 backing_queue 模块的接口将消息入队。
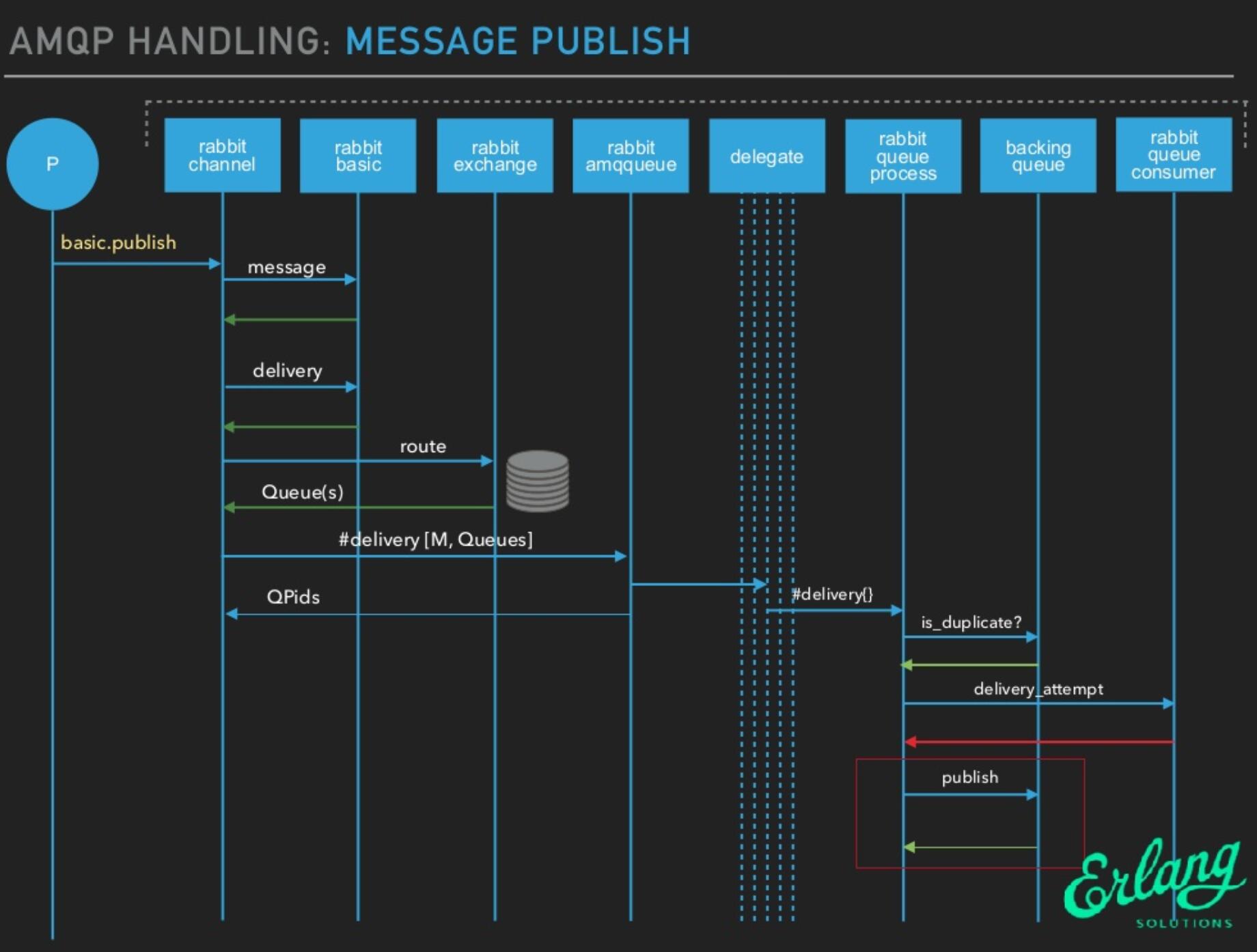
- 如果调用
deliver_or_enqueue方法的 BQ:publish 则说明当前队列没有消费者正在等待,消息将进入到队列。backing_queue 模块实现了消息的存储,它会尽力将 durable=true 的消息做持久化。 - 初始默认情况下,非持久化消息直接进入内存队列,此时效率最高,当内存占用逐渐达到阈值时,消息和消息索引逐渐往磁盘中移动,随着消费者的不断消费,内存占用减少,消息逐渐又从磁盘中被转到内存队列中。
- 消息在这些队列中传递的“一般”过程是
Q1->Q2->Delta->Q3->Q4,一般负载较轻时消息不需要走完每个子队列,大部分都可以跳过。 - 每次消息入队后,判断 RabbitMQ 系统中占用的内存是否过多,此操作是尝试将内存中的队列数据写入到磁盘中。
- 内存中的消息数量(RamMsgCount)及内存中的等待 ack 的消息数量(RamAckIndex)的和大于允许的内存消息数量(TargetRamCount)时,多余数量的消息内容会被写到磁盘中。
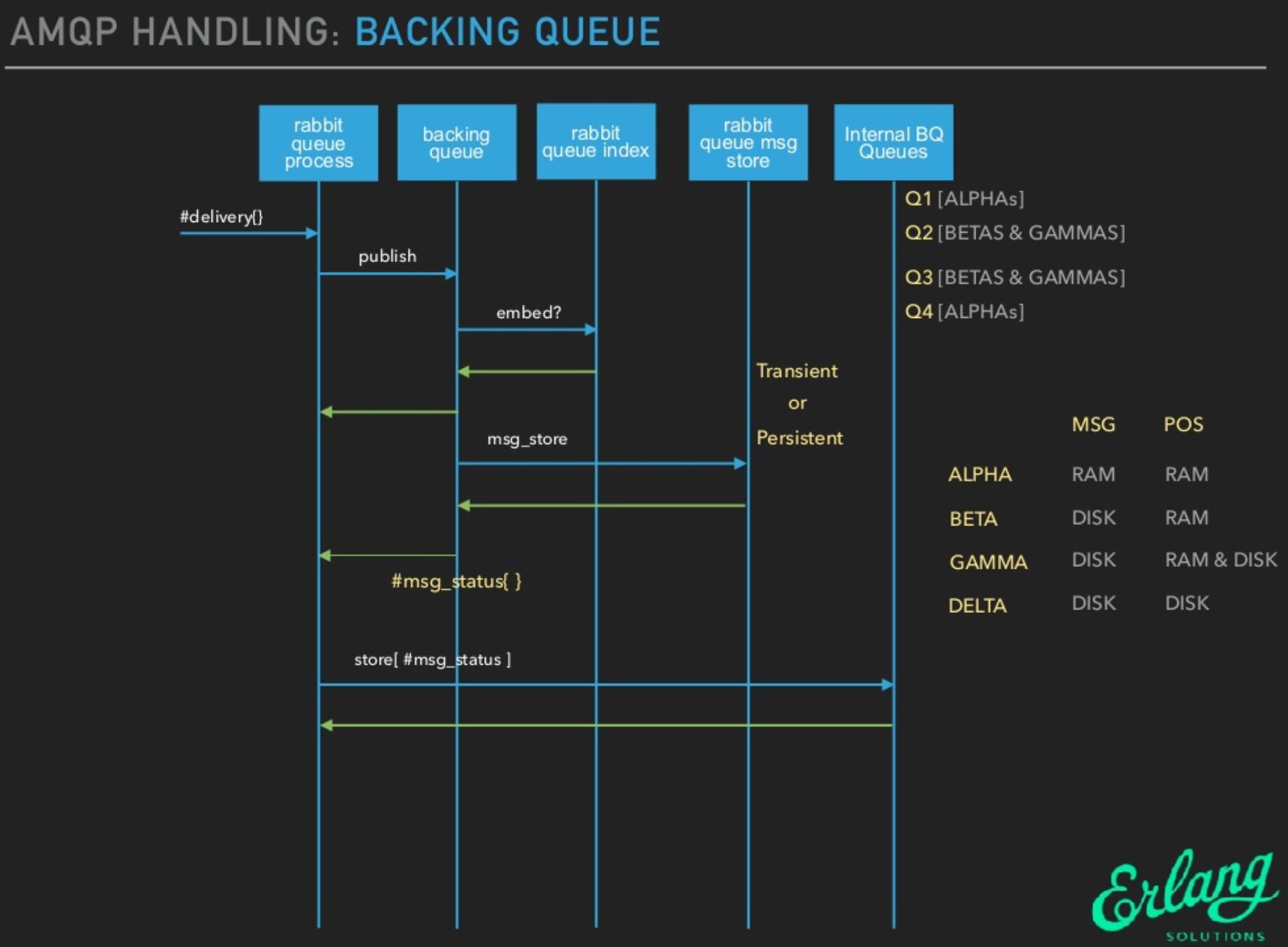
消息什么时候会刷到磁盘?
- 写入文件前会有一个
Buffer,大小为 1M(1048576),数据在写入时,首先会写入到这个 Buffer,如果Buffer 已满,则会将数据写入到文件(未必刷到磁盘)。 - 有个固定的刷盘时间:
25ms,也就是不管 Buffer 满不满,每隔 25ms,Buffer 里的数据及未刷新到磁盘的文件内容必定会刷到磁盘。 - 每次消息写入后,如果没有后续写入请求,则会直接将已写入的消息刷到磁盘。使用 Erlang 的
receive x after 0来实现,只要进程邮箱里没有消息,则产生一个 timeout 消息,触发刷盘操作。
11-5-2. 消息消费
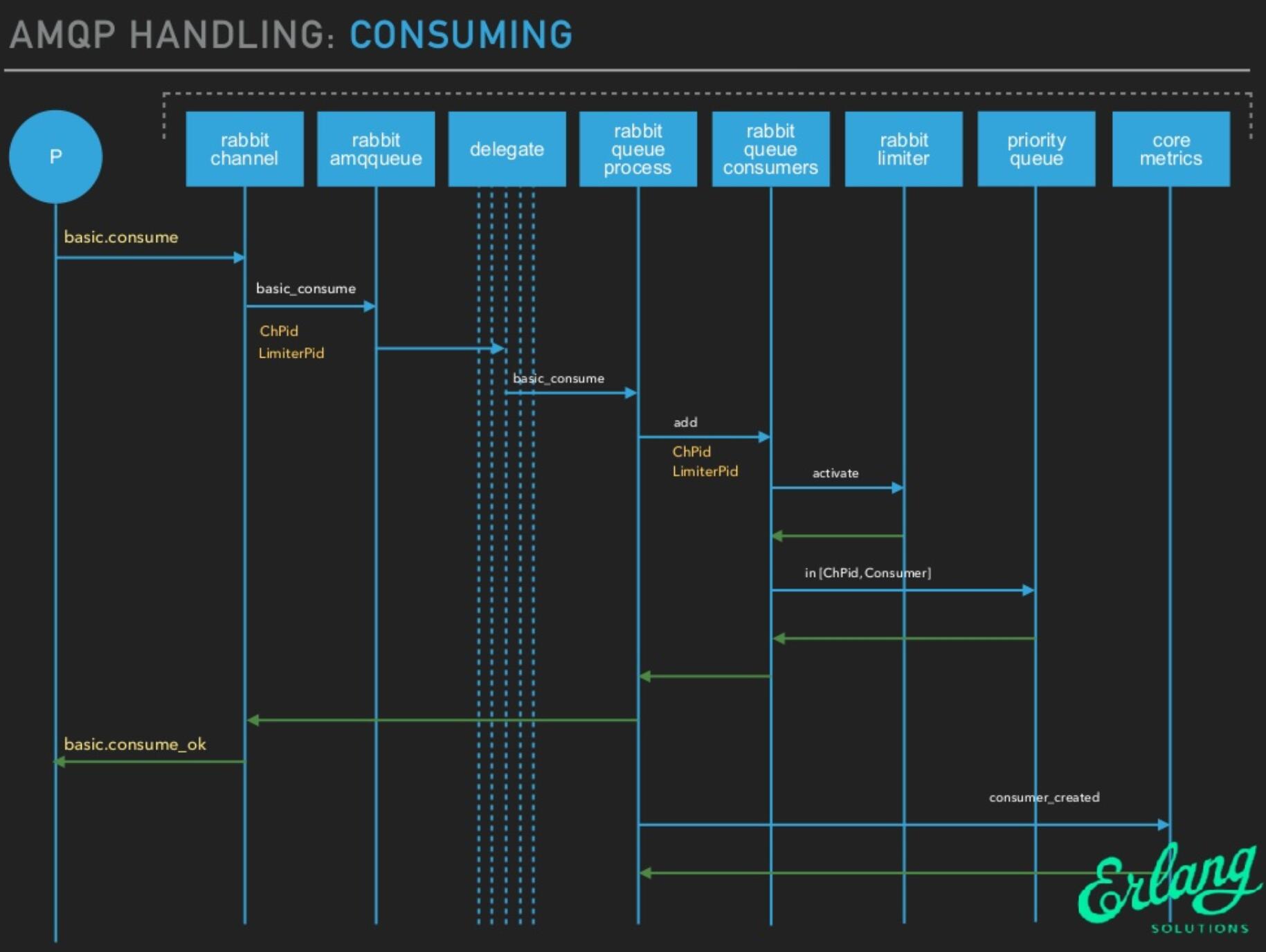
获取消息:
- 尝试从 Q4 队列中获取一条消息,成功则返回获取到的消息,失败则尝试通过试用 fetch_from_q3/1 从 Q3 队列获取消息,成功则返回,为空则返回空。
- 注意 fetch_from_q3 从 Q3 获取消息,如果 Q3 为空,则说明整个队列都是空的,消费者等待即可。
取出消息后:
- 如果 Q4 不为空,取出消息后直接返回。
- 如果 Q4 为空,Q3 不为空,从 Q3 取出消息后,判断 Q3 是否为空,如果 Q3 为空,Delta 不为空,则将 Delta 中的消息转移到 Q3 中,下次直接从 Q3 消费。
- 如果 Q3 和 Delta 都是空的,则可以认为 Delta 和 Q2 的消息都是空的,此时将 Q1的消息转移到 Q4,下次直接从 Q4 消费。
11-5-3. 消息删除
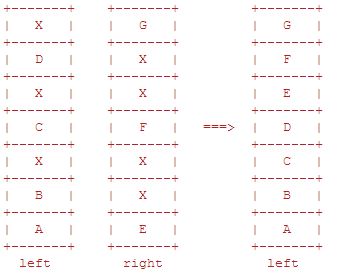
publish 消息时写入内容,ack 消息时删除内容(更新该文件的有用数据大小),当一个文件的有用数据等于 0 时,删除该文件。
消息的删除只是从 ETS(Erlang Term Storge) 表删除执行消息的相关信息,同时更新对应的存储文件的相关信息,并不立即对文件中的消息进行删除,后续会有专门的 垃圾回收进程 负责合并待回收消息文件。
标记删除,类似 habse/cassandra 里面的
tombstone。
当所有文件中的垃圾消息(被删除的消息)比例大于阈值 GARBAGE_FRACTION = 0.5 即 50% ,并且至少有三个及以上的文件时,会触发文件合并操作,以提高磁盘利用率。
类似 hbase 中的
minor/major compaction。
根据 #file_summary{} 中 left、right 找到逻辑上相邻的两个文件,并且两个文件的有效数据可在一个文件中存储,执行合并时首先锁定这两个文件,并对左边文件中的有效数据进行整理,再将右边文件的有效数据写入到左边的文件,同时更新 ETS 表中的记录,最后删除右边的文件。
12. 集群
🔗 RabbitMQ
🔗 详解RabbitMQ的4种集群架构–主备、远程、镜像模式、多活模式
RabbitMQ 集群的设计目标:
- 高可用(HA)。在 RabbitMQ 节点崩溃的情况下,继续为消费者和生产者提供服务。
- 线性扩容。能过通过添加节点来线性提升消息吞吐量。
12-1. 物理架构
-
架构 1:普通架构
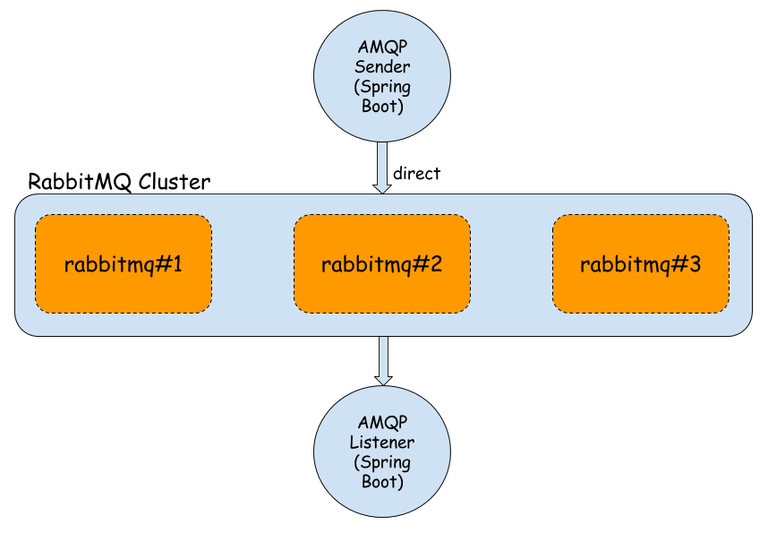
第一个节点 rabbit#1 是集群的 master 节点,其他两个节点将作为从节点加入它。
使用容器管理为每个节点启用 UI 管理控制台。每个节点都有默认的连接和控制台端口。
重点的是将 rabbit#2 和 rabbit#3 容器链接到 rabbit#1:
rabbit1 --name rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcluster' -p 30000:5672 -p 30001:15672 rabbitmq:management rabbit2 --name rabbit2 --link rabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcluster' -p 30002:5672 -p 30003:15672 rabbitmq:management rabbit3 --name rabbit3 --link rabbit1:rabbit1 -e RABBITMQ_ERLANG_COOKIE='rabbitcluster' -p 30004:5672 -p 30005:15672 rabbitmq:management -
架构 2:加入集群权限管理和节点自注册
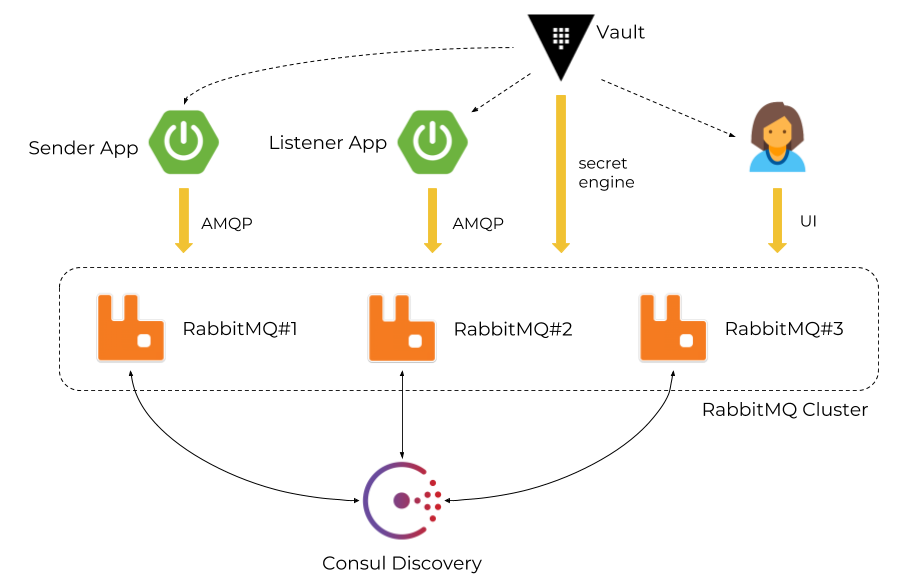
当应用程序试图通过 RabbitMQ 节点进行身份验证或用户试图登录到 RabbitMQ 管理控制台时,我们将 Vault 作为凭证管理器。
每个 RabbitMQ 节点启动后都会在 Consul 中进行注册,并检索集群中运行的节点列表。
Vault 使用专门的加密引擎与 RabbitMQ 集成。
12-2. 节点类型
RabbitMQ 节点类型有 2 种:
RAM node(内存节点):将所有的交换机、队列、绑定、用户、权限和 vhost 的元数据定义存储在内存中,好处是可以使得操作更加的快速,比如交换机和队列声明等。Disk node(磁盘节点):将元数据存储在磁盘中,单节点系统只允许磁盘类型的节点,防止重启 RabbitMQ的时候,丢失系统的配置信息。
RabbitMQ 要求在集群中至少有一个磁盘节点,所有其他节点可以是内存节点,当节点加入或者离开集群时,必须要将该变更通知到至少一个磁盘节点。
问题说明:如果集群中唯一的一个磁盘节点崩溃的话,集群仍然可以保持运行,但是无法进行其他操作(增删改查),直到节点恢复。
解决方案:设置两个磁盘节点,至少有一个是可用的,可以保存元数据的更改。
12-3. 集群模式
-
普通模式
- 默认的集群模式,对于 Queue 来说,集群上的所有节点都有相同的元数据,即交换器、队列、绑定等结构,但消息实体只存在于其中一个节点。
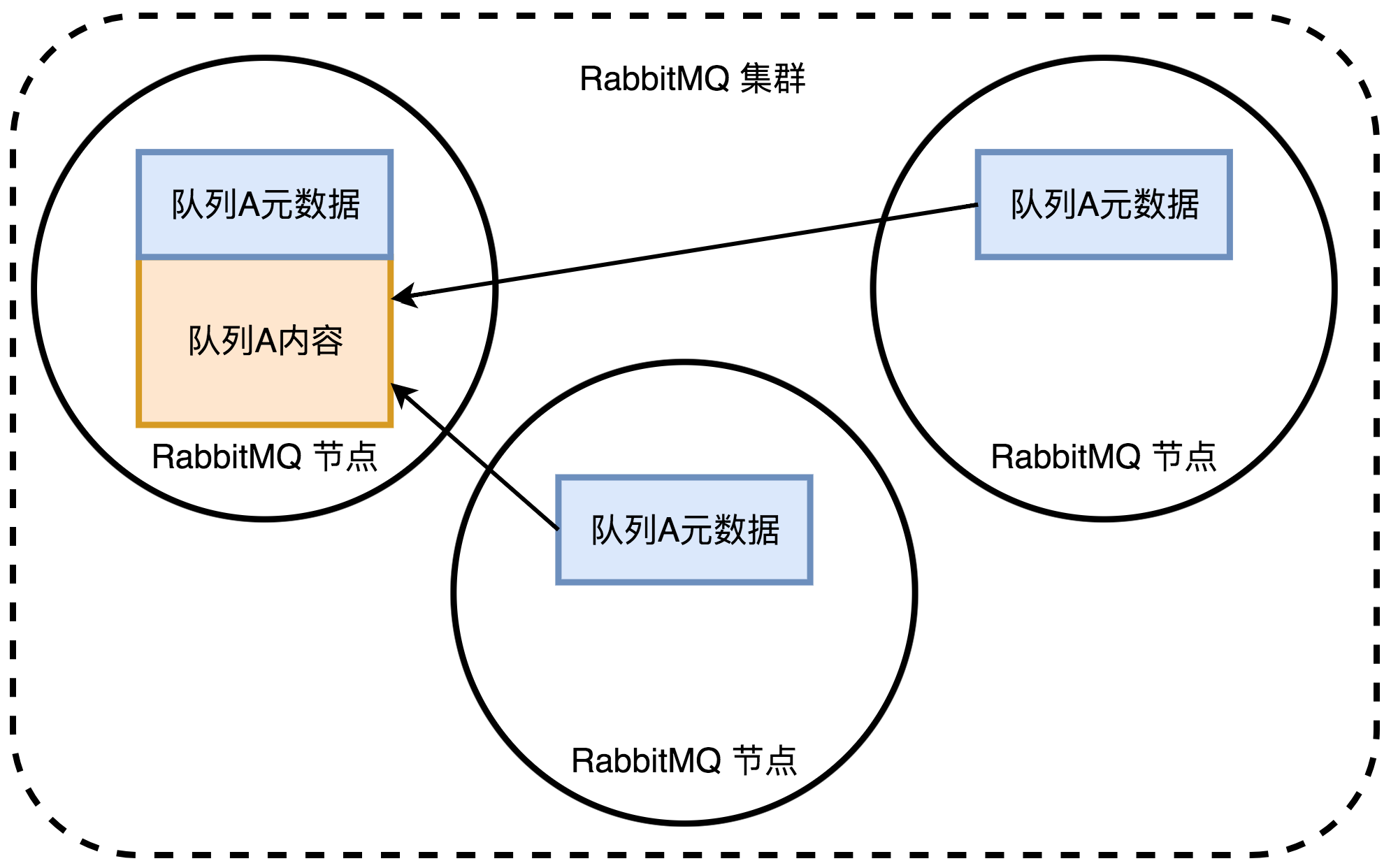
- 当消息进入集群中某个节点的队列中,但消费者连接另外一个节点消费时,比如 node1、node2 两个节点,RabbitMQ 会临时在 node1、node2 间进行消息传输,把 node1 中的消息实体取出并经过 node2 发送给消费者。
- 所以消费者应尽量连接每一个节点取消息。即对于同一个逻辑队列,要在多个节点建立相应的物理队列。否则无论消费者连接 node1 还是 node2,若出口总在 node1,就会产生瓶颈。
- 当 node1 节点故障,node2 节点就无法取到 node1 节点中还未消费的消息实体。如果做了消息持久化,那么得等 node1 节点恢复后才可被消费;如果没有做持久化,消息就会丢失。
-
镜像模式
RabbitMQ 自己也考虑到了单节点长时间故障无法恢复的问题,所以 2.6.0 版本后它支持了镜像队列,换个说法也就是主备模式。
具体实现策略:
all:镜像队列将会在整个集群中复制。每一个新节点加入后都会复制一份。exactly(count):镜像队列将会在集群上复制 count 份。如果集群中队列数量小于 count 值,会复制到所有节点上;如果队列数量大于 count 值,当某一个节点 crash 后,新进入的节点不会做新的镜像。nodes(node name): 镜像队列会在 node name 中复制。如果这个名称的队列不在集群中,也不会触发错误。如果这个 node list 中没有一个节点在线,那么该队列会被声明在 client 连接的那个节点中。
一般大厂都会构建这种镜像集群模式。实际生产环境中,一般客户端是通过 HAProxy 这类负载均衡代理对 MQ 进行访问。
需要消费的队列,作为镜像队列存在多个于节点(一般至少3个)中,消息实体会主动在镜像队列之间同步,而不是像普通模式那样,在消费者消费数据时临时读取。缺点是集群内部的同步通讯会占用大量的网络带宽。
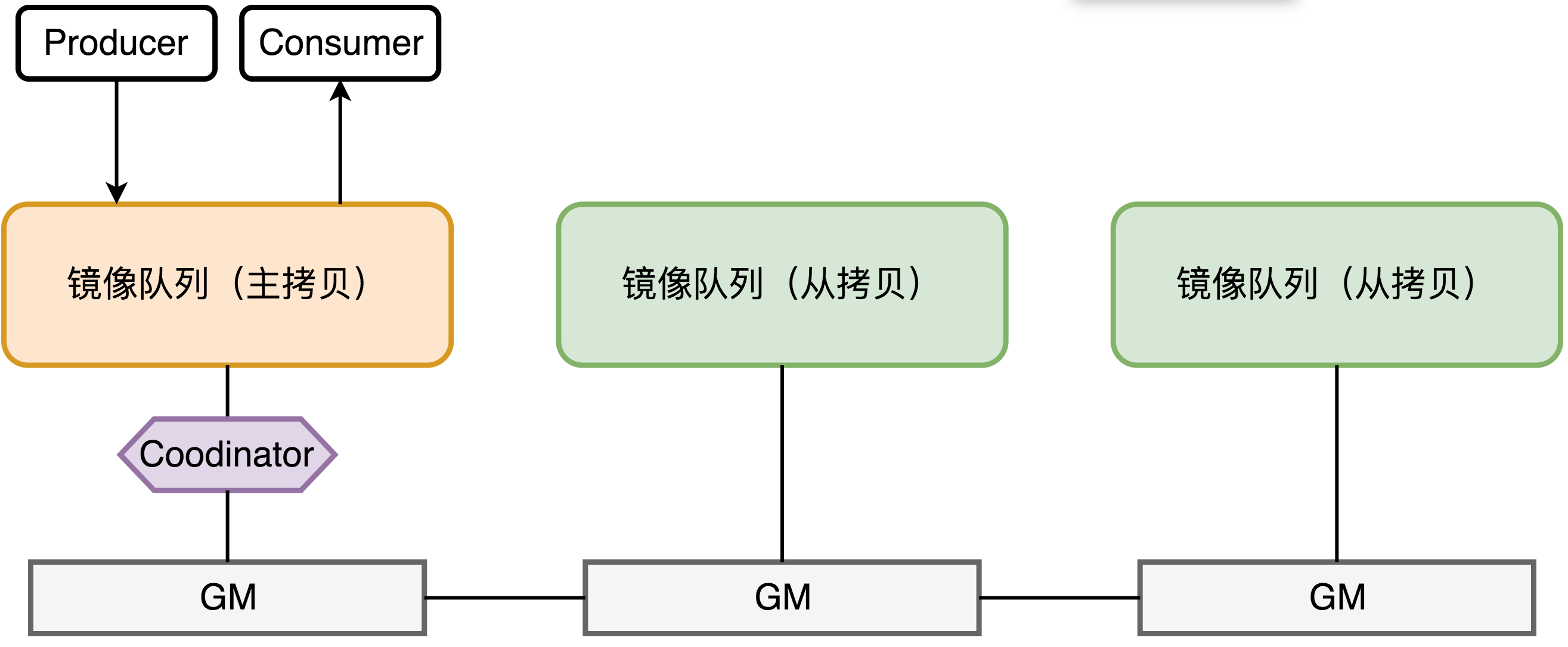
所有对镜像队列主拷贝的操作,都会通过 Guarented Multicasting(GM) 同步到各个 Salve 节点,Coodinator 负责组播结果的确认。GM 是一种可靠的组播通信协议,保证组内的存活节点都收到消息。
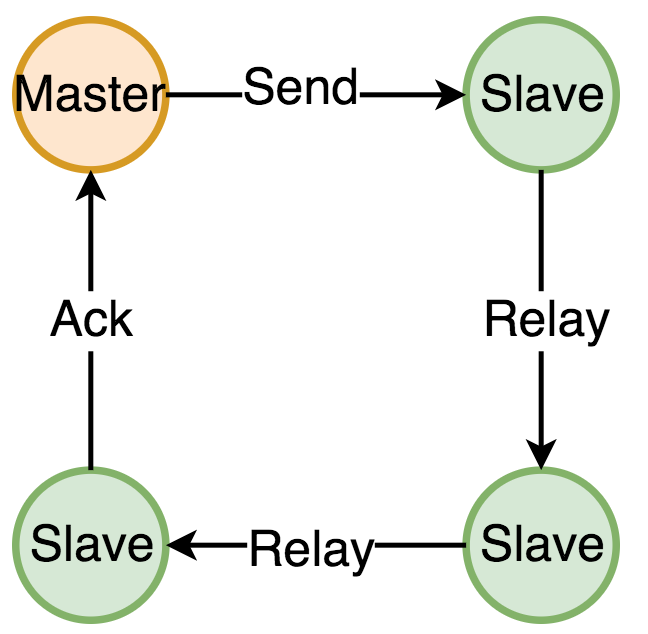
GM 的组播并不是由 Master 节点来负责通知所有 Slave 的(为了避免 Master 压力过大,同时避免 Master 失效导致消息无法最终 Ack),RabbitMQ 把一个镜像队列的所有节点组成一个链表,由主拷贝发起,由主拷贝最终确认通知到了所有的 Slave,中间由 Slave 接力的方式进行消息传播。
从这个结构来看,消息完成整个镜像队列的同步耗时理论上是不低的,但是由于 RabbitMQ 消息的消息确认本身是异步的模式,所以整体的吞吐量并不会受到太大影响。
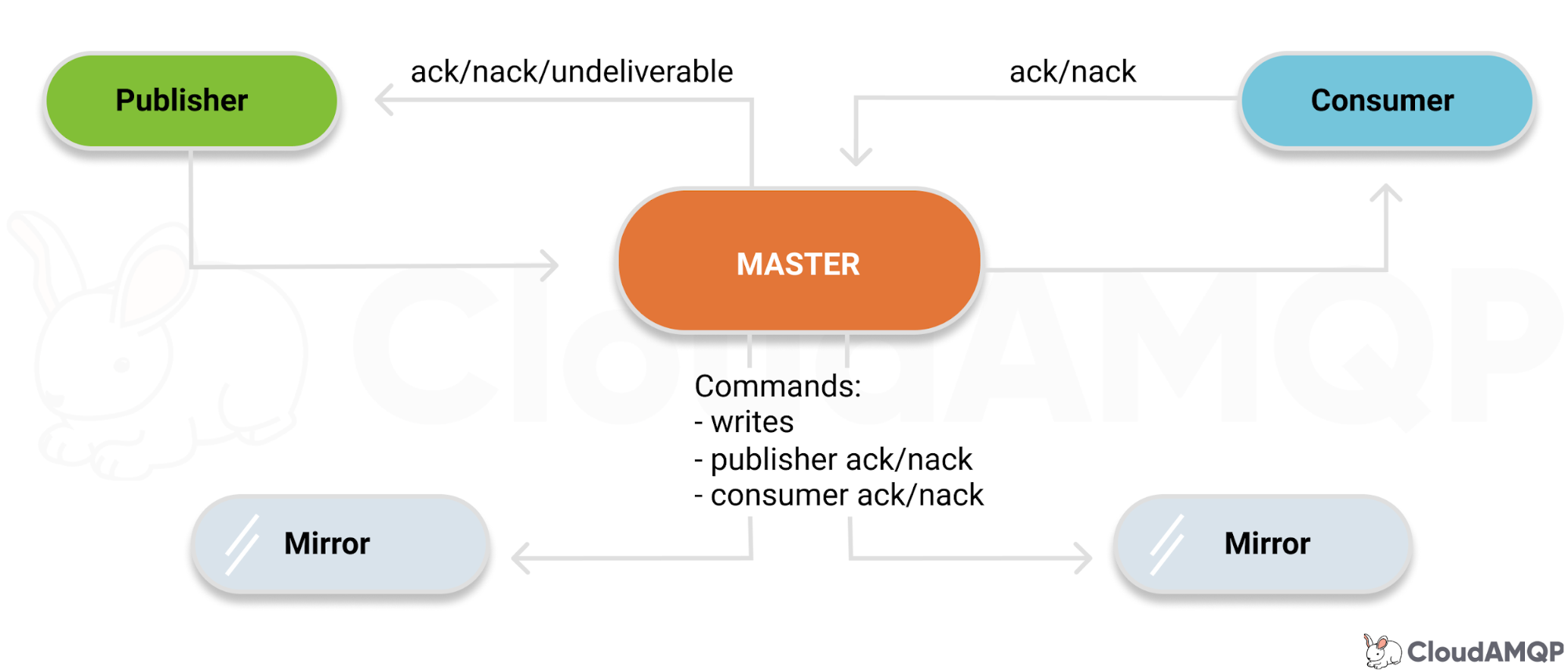
除了发送消息,所有的操作实际都在主拷贝上,从拷贝实际只是个冷备(默认的情况下所有 RabbitMQ 节点都会有镜像队列的拷贝),如果使用消息确认模式,RabbitMQ 会在主拷贝和从拷贝都安全的接受到消息时才通知生产者。
如果从拷贝的节点挂了,不会有任何影响,如果主拷贝挂了,会有一个重新选主的过程,除非所有节点都挂了,才可能导致消息丢失。重新选主后,RabbitMQ 会给消费者一个取消通知(Consumer Cancellation),让消费者重连新的主拷贝。
-
双活模式
异地集群都是采用
双活或者多活模式来实现的。这种模式需要依赖 RabbitMQ 的 federation 插件,可以实现持续的、可靠的 AMQP 数据通信,多活模式的实际配置与应用非常简单。若 RabbitMQ 部署架构想采用双中心(多中心)模式,在两个(或多个)数据中心各部署一套 RabbitMQ 集群,各中心除了要为业务提供正常的消息服务外,还需要实现部分队列消息共享。

federation 插件是一个不需要构建集群 ,而在 broker 之间传输消息的高性能插件,federation 插件可以在 broker 或者 cluster 之间传输消息,连接的双方可以使用不同的 users 和 virtual hosts,双方也可以使用不同版本的 rabbitMQ 和 erlang。federation 插件使用 AMQP 协议通信,可以接受不连续的传输。federation 不是建立在集群上的,而是建立在单个节点上的,如图上黄色的 rabbit node 3 可以与绿色的 node1、node2、node3 中的任意一个利用 federation 插件进行数据同步。
13. 事务
使用 AMQP 0-9-1 标准,保证消息不丢失的唯一方法是使用事务,为每条消息或每组消息进行发布、提交。但事务是很繁重的,吞吐量会极大地降低。「故 RabbitMQ 最好使用发布者确认机制来保证。」
事务的实现主要是对信道(Channel)的设置,主要的方法有三个:
- channel.txSelect() 声明启动事务模式。
- channel.txComment() 提交事务。
- channel.txRollback() 回滚事务。
ConnectionFactory factory = new ConnectionFactory();
Connection conn = factory.newConnection();
Channel channel = conn.createChannel();
channel.queueDeclare(_queueName, true, false, false, null);
String message = String.format("时间 => %s", new Date().getTime());
try {
channel.txSelect(); // 声明事务
channel.basicPublish("", _queueName, MessageProperties.PERSISTENT_TEXT_PLAIN, message.getBytes("UTF-8"));
channel.txCommit(); // 提交事务
} catch (Exception e) {
channel.txRollback(); // 回滚事务
} finally {
channel.close();
conn.close();
}
客户端和 RabbitMQ 之间的通讯流程:
- 客户端发送给服务器端 Tx.Select 开启事务模式。
- 服务器端返回 Tx.Select-Ok。
- 推送消息。
- 客户端发送给服务器端提交事务 Tx.Commit。
- 服务器端返回 Tx.Commit-Ok。
以上就完成了事务的交互流程,如果其中任意一个环节出现问题,就会抛出 IOException 异常,这样用户就可以拦截异常进行事务回滚,或决定要不要重发消息。















 1998
1998











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









