







此类是一个工具类,所以源码学习主要是介绍这个这个类可以进行哪些操作,而不是对具体的实现过程进行分析。例如这个类中有关于排序的部分,用到了一些排序算法,但是本博客并不会深入去讲解这些排序算法的实现,关于具体算法部分的细节在后面的博文中会慢慢推出。
首先看此类的构造器,java.util.Arrays类提供了一个私有的构造器,所以此类无法实例化,正因为如此,此类中暴露给用户的方法都是用static修饰的,所以使用的时候直接用类名调用就行了。
首先来看看此类中主要的方法
从这几张图中可以大致了解本类可以进行哪些操作,大致可以分为以下几类:
二分查找
- 数组复制
- 数组比较
- 求哈希码
- 排序
- 二分查找
- 数组和List转化
- 数组的流操作
- 若干toString方法
- 针对多处理器情况下的一些优化操作
因为方法较多而且很多方法实现差不多,所以就选取对其中一种类型的操作为例进行说明。
数组复制
数组复制的思路是先根据原数组的类型和传入的长度新创建一个数组,然后调用System.arrayCopy将原数组指定范围的部分复制到新数组,但是需要注意的是System.arrayCopy的复制是浅复制,所以如果复制的数组的基类型是非基本类型,那么复制前后两个数组的元素就指向了同一个元素,对任意一个数组元素的修改都会影响另一个数组。以下是其实现:
public static int[] copyOf(int[] original, int newLength) {
int[] copy = new int[newLength];
System.arraycopy(original, 0, copy, 0,
Math.min(original.length, newLength));
return copy;
}数组的复制还可以指定复制的范围,实现原理和copyOf方法一样
public static int[] copyOfRange(int[] original, int from, int to) {
int newLength = to - from;
if (newLength < 0)
throw new IllegalArgumentException(from + " > " + to);
int[] copy = new int[newLength];
System.arraycopy(original, from, copy, 0,
Math.min(original.length - from, newLength));
return copy;
}数组比较
对于基本类型最终是用==进行比较,而对于非基本类型,最终会调用其基类型的equals方法进行比较
public static boolean equals(Object[] a, Object[] a2) {
if (a==a2)
return true;
if (a==null || a2==null)
return false;
int length = a.length;
if (a2.length != length)
return false;
for (int i=0; i<length; i++) {
Object o1 = a[i];
Object o2 = a2[i];
if (!(o1==null ? o2==null : o1.equals(o2)))
return false;
}
return true;
}jdk中还提供了另外一个deepEquals方法用来对数组进行深度比较。
所谓深度比较:比如String[][],使用deepEquals方法最终会每一个数据项(即String类型)的equals方法。和equals方法不同的是,equals方法只会在一维数组的层次上进行比较(即String[]),但是由于默认继承的是Object类的equals方法,所以比较的是对象的地址。所以对于基本类型的数组比较用这两个方法都可以,而如果进行比较的数组是一维以上的,就要用deepEquals方法进行比较了。以下是其实现:
public static boolean deepEquals(Object[] a1, Object[] a2) {
if (a1 == a2)
return true;
if (a1 == null || a2==null)
return false;
int length = a1.length;
if (a2.length != length)
return false;
for (int i = 0; i < length; i++) {
Object e1 = a1[i];
Object e2 = a2[i];
if (e1 == e2)
continue;
if (e1 == null)
return false;
// Figure out whether the two elements are equal
boolean eq = deepEquals0(e1, e2);
if (!eq)
return false;
}
return true;
} static boolean deepEquals0(Object e1, Object e2) {
assert e1 != null;
boolean eq;
if (e1 instanceof Object[] && e2 instanceof Object[])
eq = deepEquals ((Object[]) e1, (Object[]) e2);
else if (e1 instanceof byte[] && e2 instanceof byte[])
eq = equals((byte[]) e1, (byte[]) e2);
else if (e1 instanceof short[] && e2 instanceof short[])
eq = equals((short[]) e1, (short[]) e2);
else if (e1 instanceof int[] && e2 instanceof int[])
eq = equals((int[]) e1, (int[]) e2);
else if (e1 instanceof long[] && e2 instanceof long[])
eq = equals((long[]) e1, (long[]) e2);
else if (e1 instanceof char[] && e2 instanceof char[])
eq = equals((char[]) e1, (char[]) e2);
else if (e1 instanceof float[] && e2 instanceof float[])
eq = equals((float[]) e1, (float[]) e2);
else if (e1 instanceof double[] && e2 instanceof double[])
eq = equals((double[]) e1, (double[]) e2);
else if (e1 instanceof boolean[] && e2 instanceof boolean[])
eq = equals((boolean[]) e1, (boolean[]) e2);
else
eq = e1.equals(e2);
return eq;
}求哈希码
同前面的方法一样,对数组求hashcode的操作也提供了不同的版本。用来对普通数组操作的hashcode方法和对高维数组操作的deepHashcode方法
public static int hashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a)
result = 31 * result + (element == null ? 0 : element.hashCode());
return result;
}public static int deepHashCode(Object a[]) {
if (a == null)
return 0;
int result = 1;
for (Object element : a) {
int elementHash = 0;
if (element instanceof Object[])
elementHash = deepHashCode((Object[]) element);
else if (element instanceof byte[])
elementHash = hashCode((byte[]) element);
else if (element instanceof short[])
elementHash = hashCode((short[]) element);
else if (element instanceof int[])
elementHash = hashCode((int[]) element);
else if (element instanceof long[])
elementHash = hashCode((long[]) element);
else if (element instanceof char[])
elementHash = hashCode((char[]) element);
else if (element instanceof float[])
elementHash = hashCode((float[]) element);
else if (element instanceof double[])
elementHash = hashCode((double[]) element);
else if (element instanceof boolean[])
elementHash = hashCode((boolean[]) element);
else if (element != null)
elementHash = element.hashCode();
result = 31 * result + elementHash;
}
return result;
}排序
public static void sort(int[] a) {
DualPivotQuicksort.sort(a, 0, a.length - 1, null, 0, 0);
}
public static void sort(int[] a, int fromIndex, int toIndex) {
rangeCheck(a.length, fromIndex, toIndex);
DualPivotQuicksort.sort(a, fromIndex, toIndex - 1, null, 0, 0);
}对数组的排序用到了快排算法,该类将会在其他博客中专门分析 ,这里不做分析。
二分查找
public static int binarySearch(int[] a, int key) {
return binarySearch0(a, 0, a.length, key);
}
public static int binarySearch(int[] a, int fromIndex, int toIndex,
int key) {
rangeCheck(a.length, fromIndex, toIndex);
return binarySearch0(a, fromIndex, toIndex, key);
}二分查找最终是调用binarySearch0这个方法,实现如下:
private static int binarySearch0(int[] a, int fromIndex, int toIndex,
int key) {
int low = fromIndex;
int high = toIndex - 1;
while (low <= high) {
int mid = (low + high) >>> 1;
int midVal = a[mid];
if (midVal < key)
low = mid + 1;
else if (midVal > key)
high = mid - 1;
else
return mid; // key found
}
return -(low + 1); // key not found.
}数组和List的转化
调用Arrays.asList方法可以将数组转化为list,方法实现如下:
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}这里返回不是java.util.ArrayList,而是Arrays类的内部类
下面是该内部类的结构图
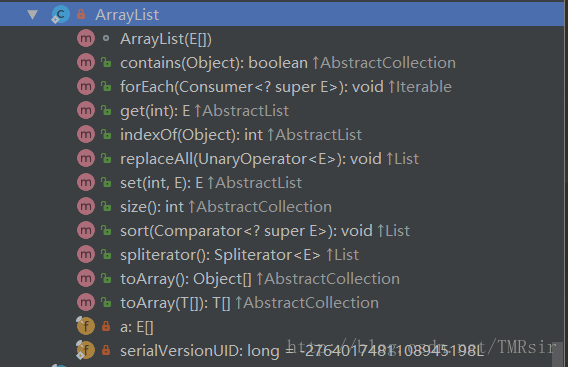
以下是这个内部类的实现
private static class ArrayList<E> extends AbstractList<E>
implements RandomAccess, java.io.Serializable
{
private static final long serialVersionUID = -2764017481108945198L;
private final E[] a;
ArrayList(E[] array) {
a = Objects.requireNonNull(array);
}因为和java.util.ArrayList类一样都继承了AbstractList抽象类,所以可以相互转化。观察它的构造器可知,这个类直接将传入的数组的引用赋值给内部的数组,所以对返回列表的更改操作会“直接反应”到参数数组上面。
而从其结构图可知这个类并没有重写父类的add和remove方法,所以默认使用的AbstractList的add和remove方法,下面来看看其父类的这两个方法:
public boolean add(E e) {
add(size(), e);
return true;
}
public void add(int index, E element) {
throw new UnsupportedOperationException();
} public E remove(int index) {
throw new UnsupportedOperationException();
}所以对这个ArrayLIst进行add或者remove操作会抛出UnsupportedOperationException
流操作
public static IntStream stream(int[] array) {
return stream(array, 0, array.length);
}
public static IntStream stream(int[] array, int startInclusive, int endExclusive) {
return StreamSupport.intStream(spliterator(array, startInclusive, endExclusive), false);
}这里就是提供一种获取流对象的一种通用方法,关于流对象的工作方式可参考:
http://www.importnew.com/16545.html
toString方法
对于这个系列方法的作用想必已经耳熟能详了,所以这里就不就行描述了,直接上代码:
public static String toString(int[] a) {
if (a == null)
return "null";
int iMax = a.length - 1;
if (iMax == -1)
return "[]";
StringBuilder b = new StringBuilder();
b.append('[');
for (int i = 0; ; i++) {
b.append(a[i]);
if (i == iMax)
return b.append(']').toString();
b.append(", ");
}
}
针对多处理器情况下的一些优化操作
这一系列的方法以parallel开头,他们提供了一种并行处理的思路,在任务可以分开执行的情况下,将一个任务分成多个子任务,这样就可以交给不同的线程进行处理,从而提高了处理的速度。这些方法的处理涉及到Fork/Join框架,将在后面的博客中分析,下面先将代码贴出来:
public static void parallelSort(byte[] a) {
int n = a.length, p, g;
if (n <= MIN_ARRAY_SORT_GRAN ||
(p = ForkJoinPool.getCommonPoolParallelism()) == 1)
DualPivotQuicksort.sort(a, 0, n - 1);
else
new ArraysParallelSortHelpers.FJByte.Sorter
(null, a, new byte[n], 0, n, 0,
((g = n / (p << 2)) <= MIN_ARRAY_SORT_GRAN) ?
MIN_ARRAY_SORT_GRAN : g).invoke();
}好了,关于这个工具类已经说得差不多了,前面说了,既然作为一个工具类,我们只要知道它能进行什么操作就行了,至于这个工具类中涉及到的算法和其他的一些知识,将在后面的博客中深入分析。














 3401
3401











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









