









关于Oracle数据库字符集的选择及乱码情况
背景: 在项目上,开发人员在安装Oracle数据库时采用的默认的编码集,导致后期正式运行时出现某些生僻字和中文符号. 出现乱码。出现的情况就是某些生僻字或中文符号点一经保存,数据库里面就直接变成了问号
(1)查看数据库字符集设置
select * from nls_database_parameters where parameter ='NLS_CHARACTERSET';
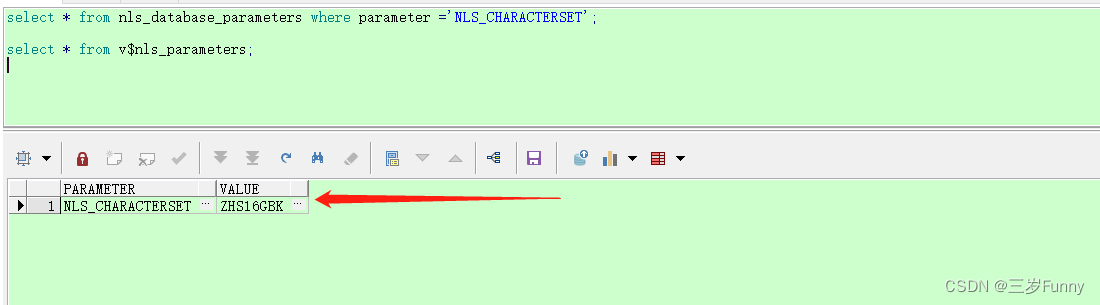
现数据库字符集设置的是 ZHS16GBK。经过尝试,把数据库字符集设置为utf8,生僻字是不再出现乱码的情况,但是中文点. 却依旧出现乱码。查询资料并验证后发现AL32UTF8 , 这种字符集可以正常显示 。这里需要注意,切记不可直接贸然去修改已经有数据的数据库的字符集,否则,新写进去的数据是没问题了。但是以前的数据就全部都乱码了。因此需要先将数据导出来,然后再进行数据的迁移(源数据库(ZHS16GBK) -----> 目标数据库(AL32UTF8))
如果不迁移数据库情况:
有2种解决方案:1、生僻字乱码要换字段类型,换成Nvarchar;
2、把生僻字存成unicode字符,然后读取的时候转换成字符串;
notes:Nvarchar的存储效率,存储空间都会比varchar大得多
(2)ORACLE数据库的字符集
AL32UTF8是什么?为什么不是UTF8? 环境变量里设置的SIMPLIFIED
CHINESE_CHINA.ZHS16GBK是什么?为什么不直接设GBK? 在数据库里的各个视图里查到的字符集究竟是客户端的还是数据库的?
I.字符集代码
ORACLE中的字符集代码,并不等于目前通用的字符集名称。先来看看官方提供的
ORACLE字符集与通用字符集对照表
其实根据这个表格中的"Description"可以了解到,目前这些通用的字符集名称都太长了,且毫无规则,不能作为代码使用;并且还存在一些特殊情况,比如"JA16EUCTILDE"和"JA16EUC"两种字符集,实际上都是"EUC 24-bit Japanese",只有波浪线不一样,就分成了两个字符集。
所以oracle必须自己再对这些字符集进行一次统一命名,因此有了"AL32UTF8"以及"ZHS16GBK"这样的字符集代码
II.NLS_LANG
在系统环境变量(或注册表)"NLS_LANG"中,经常会配置类似下面这样的值
SIMPLIFIED CHINESE_CHINA.ZHS16GBK
AMERICAN_AMERICA.AL32UTF8
其实这个环境变量由3个部分组成
<Language<territory<character
即
语言_地区.字符集
只有最后一截才是真正表示字符集
所以"SIMPLIFIED CHINESE_CHINA.ZHS16GBK"表示:“简体中文”_“中国地区”.“16位GBK简体中文”
同理,"AMERICAN_AMERICA.AL32UTF8"表示:“美式英语”_“美国地区”.“Unicode12.1通用字符集UTF-8编码方案”。
当然,在环境变量中,这3个并非全部必填,你甚至可以用 "_.AL32UTF8"表示使用数据库默认的语言和地区,但客户端使用你指定的字符集;用 "_AMERICA."只指定客户端地区,语言使用该地区的默认语言,字符集使用该地区默认语言对应的字符集。















 8523
8523











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









